从数据库启动日志看PostgreSQL的崩溃恢复
Posted PostgreSQLChina
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了从数据库启动日志看PostgreSQL的崩溃恢复相关的知识,希望对你有一定的参考价值。
作者:吴聪
背景
今天碰到朋友问我个问题,数据库启动时日志中的这个“invalid record length at 3/EAA68B8: wanted 24, got 0”里面的wanted 24是啥意思。
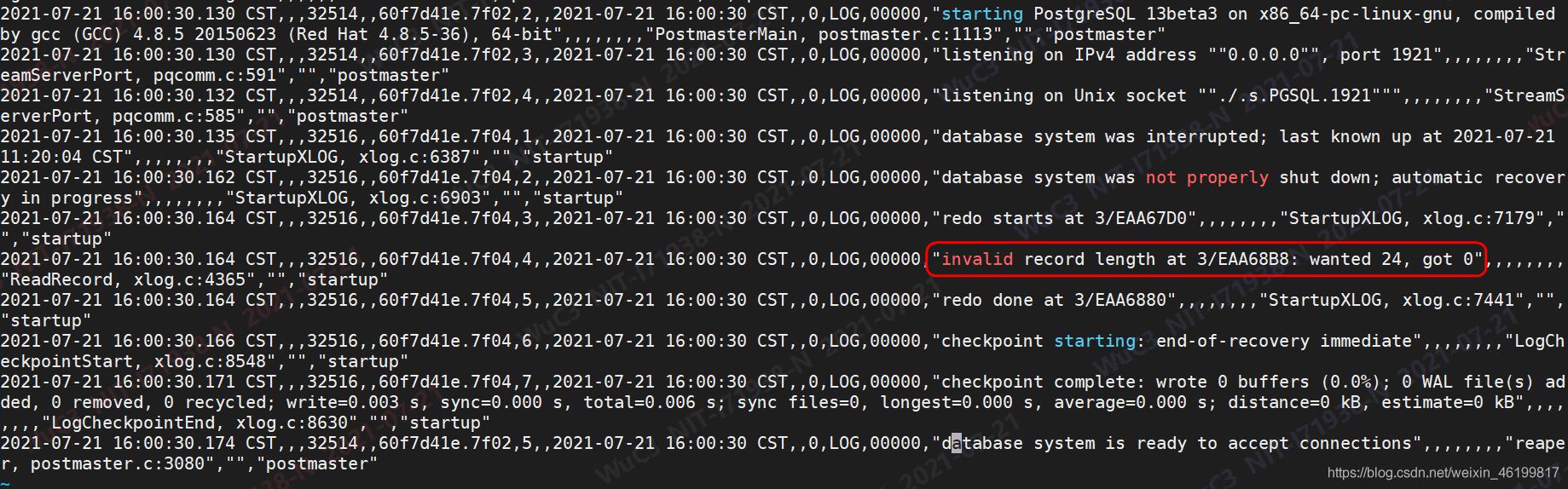
而数据库正常启动时的日志其实并不是上面那样,而是如下图所示:

上图的日志是因为数据库异常关闭后重启导致的,例如进程直接被kill。
为了搞清楚上面日志中的那条记录是啥意思,我们来一起研究下数据库异常关闭后恢复的过程。
崩溃恢复概述
首先我们要清楚数据库异常关闭和正常的停库有啥区别。当数据库异常关闭时,数据库的共享缓冲区中的数据还没有来得及刷到磁盘中,必然是会丢失,这个时候启动数据库便是从不正常的状态去启动,也就是我们要研究的崩溃恢复。
之前我也介绍过checkpoint相关的内容, 当PostgreSQL数据库崩溃恢复时,会以最近的checkpoint为基础,不断应用这之后的XLOG日志。为了更好地理解PostgreSQL数据库从崩溃中恢复的过程,我们需要弄清楚以下几个问题:
- 数据库操作系统如何识别到自己是非正常状态(崩溃状态)
- 数据库如何找到合适的checkpoint作为基础
- 为什么应用XLOG日志可以恢复数据库数据
- 数据库如何应用XLOG日志
数据库状态
在pg中数据库状态分为以下几种(可以通过控制文件查看数据库状态):
typedef enum DBState
{
DB_STARTUP = 0,/*数据库启动*/
DB_SHUTDOWNED,/*数据库正常关闭*/
DB_SHUTDOWNED_IN_RECOVERY,/*数据库在恢复时关闭*/
DB_SHUTDOWNING,/*数据库启动到正常关闭过程中崩溃*/
DB_IN_CRASH_RECOVERY,/*数据库在恢复过程中崩溃*/
DB_IN_ARCHIVE_RECOVERY,/*数据库处于归档恢复*/
DB_IN_PRODUCTION/*数据库处于正常工作状态,等待接受事务处理*/
} DBState;
当数据库正常关闭时,数据库状态便是shut down,如果是异常关闭,可能会如下所示:
Database cluster state: in production
而每次当PostgreSQL数据库启动时,会首先读取控制文件获取数据库的状态,如果为非正常关闭状态,则会执行崩溃恢复逻辑。
chekpoint相关结构
当数据库进行崩溃恢复时,因为需要恢复异常关闭时丢失的共享内存中的数据,所以需要通过checkpoint来作为基础,不断的应用wal日志来恢复。而checkpoint相关的信息在pg中是存放在控制文件中的,由ControlFileData结构体存储:
typedef struct ControlFileData
{
...
XLogRecPtr checkPoint; /*指向最近一次的检查点位置*/
XLogRecPtr prevCheckPoint; /*指向最近一次检查点的前一次检查点的位置*/
CheckPoint checkPointCopy; /*最近一次检查点控制信息的副本*/
XLogRecPtr minRecoveryPoint; /*归档恢复时必须恢复到的最小LSN*/
XLogRecPtr backupStartPoint; /*在线备份时进行的检查点开始LSN*/
XLogRecPtr backupEndPoint; /*在线备份时进行的检查点结束LSN*/
bool backupEndRequired; /* 用于判断是否基于正确的在线备份集恢复*/
TimeLineID minRecoveryPointTLI; /* 必须恢复到的最小时间线 */
...
pg_crc32 crc;
} ControlFileData;
例如下图所示:
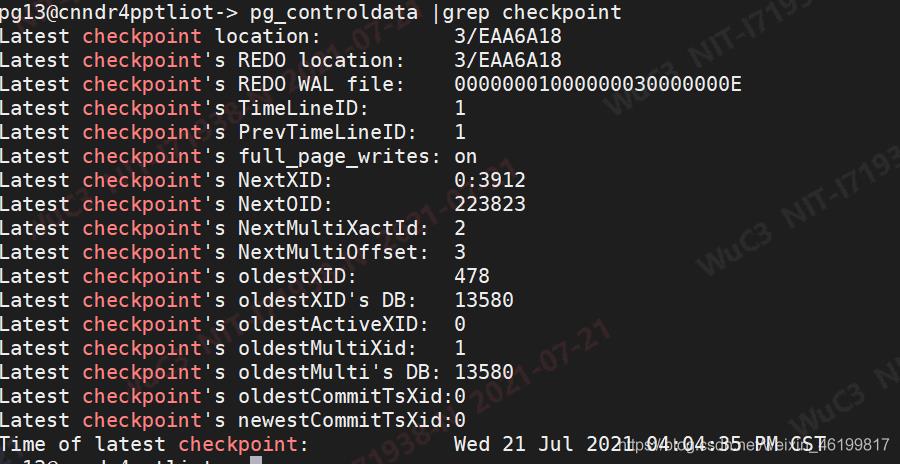
一般来说都会选取最近一次的checkpoint作为恢复点,但是会存在一种情况:在执行最近一次的checkpoint是数据库异常关闭了,那么这个检查点可能是不完整的。因此一般还会多存储一个检查点的位置,即prevCheckPoint。
在数据库崩溃恢复过程中,PostgreSQL规定了三个在启动之前必须恢复到的最小位点:
- minRecoveryPoint:
数据库在归档恢复过程中,minRecoveryPoint被更新为最新被刷新到磁盘的LSN。每次数据库启动时必须已经replay该位置的XLOG日志记录。 - backupStartPoint:
数据库在线备份开始时,会调用pg_start_backup函数执行一次checkpoint,并生成backup_label文件。当使用在线备份集进行恢复时,backupStartPoint就是上述checkpoint记录对应的LSN,当达到了该LSN,该值置为0,在置为0之前,数据库不能启动。该值被记录在
backup_label文件中如下,直到在线备份结束,pg_stop_backup将该文件删除。这样就保证了在备份过程中,数据库崩溃了,可以默认从备份开始时的日志检查点开始恢复。 - backupEndPoint:
当数据库从一个备库做的在线备份集进行恢复时,backupEndPoint表示备份结束的LSN,当达到该LSN,该值置为0,在置为0之前,数据库不能启动。
崩溃恢复具体过程:
每次postmaster进程启动时,都会调用StartupXLOG函数对数据库崩溃进行恢复。
其恢复过程大致为:
- 初始化内存,启动后台进程。
- pg在启动时读取pg_control文件内容。如果state为’in
production’,PostgreSQL将进入恢复模式,因为这意味着数据库没有正常停止;如果为’shutdown’,将进入正常启动模式。 - pg从相应的WAL段文件中读取最新的检查点记录(位于pg_control文件中),并从记录中获取重做点。如果最新的检查点记录无效(invalid),pg将读取前一个检查点的记录。如果两个记录都不可读,将放弃恢复。注意,从11版本开始不会再存储前一个检查点的记录信息。
- 使用合适的资源管理器从重做点开始按顺序读取和重放WAL记录,直到最新WAL文件的最后位置。当遇到备份块时,无论其LSN如何,都会将覆盖相应表的页面。否则仅当此wal记录LSN>相应页面的pd_lsn时,才会重放该WAL记录。
崩溃恢复日志
介绍了这么多,我们再来看看为什么在崩溃恢复时数据库的日志中输出内容是那样的。
因为检测到数据库为异常状态,所以需要从最近一次检查点开始按顺序读取wal日志:
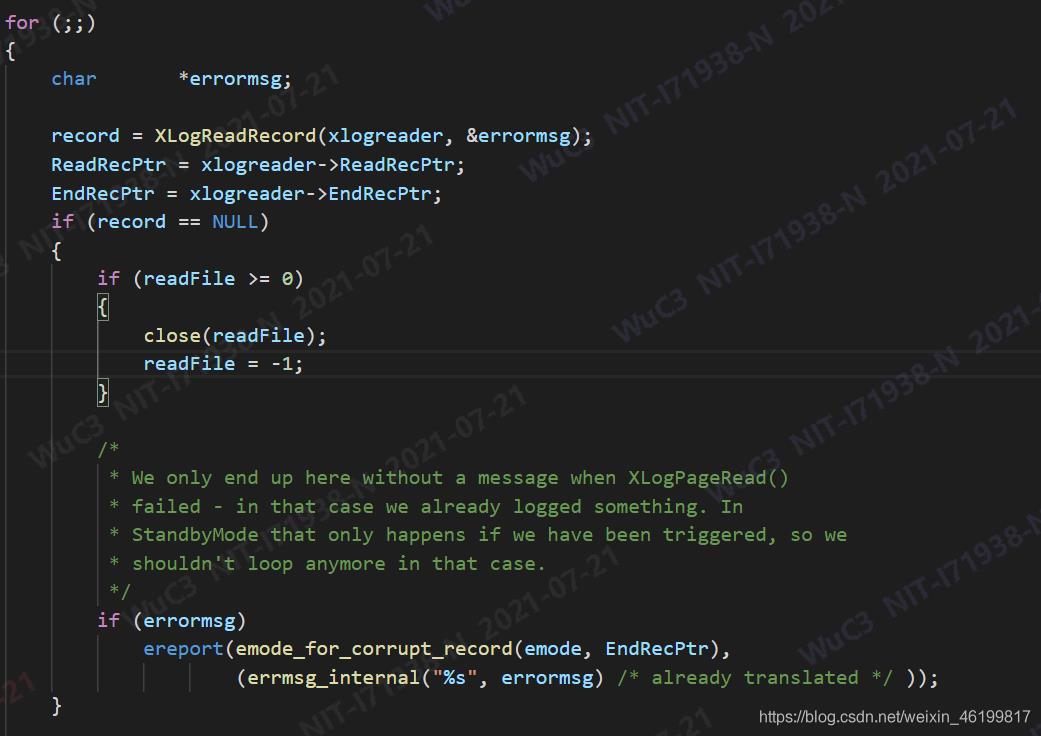
当检测到没有wal日志可以重放时,便会抛出前面的提示:“invalid record length at 3/EAA6580: wanted 24, got 0”。那你可能要问为啥为wanted 24,不是25,26。。。
那我们接着看:
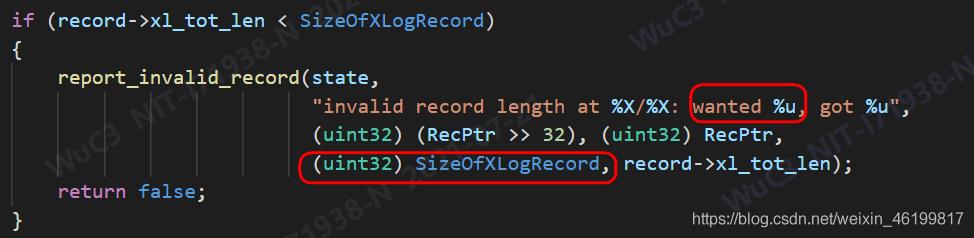
显然这里的24就是SizeOfXLogRecord,其计算方法如下:
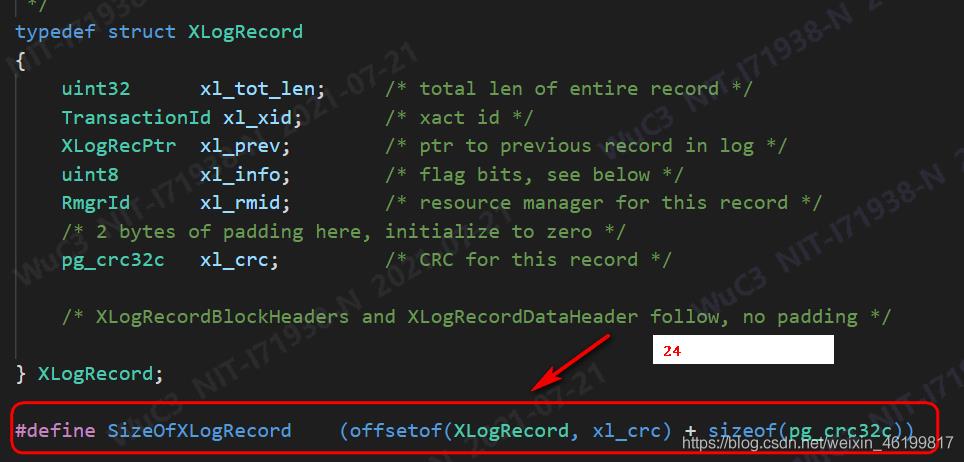
这里需要注意,XLogRecord结构体中有2bytes的填充位。
总结
一个简单的数据库启动日志竟然包含着这么多知识!
参考链接:
https://www.pgcon.org/2012/schedule/attachments/258_212_Internals%20Of%20PostgreSQL%20Wal.pdf
http://mysql.taobao.org/monthly/2017/05/03/
src/backend/access/transam/xlog.c
src/backend/access/transam/xlogreader.c
以上是关于从数据库启动日志看PostgreSQL的崩溃恢复的主要内容,如果未能解决你的问题,请参考以下文章