[MNIST03]GPU加速和过程参数保存
Posted AIplusX
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[MNIST03]GPU加速和过程参数保存相关的知识,希望对你有一定的参考价值。
写在前面
因为之前在DSW上训练的,每个epoch大概要24s左右,时间太长了,因此今天我就想要用GPU跑,但是DSW上没有GPU了,所以我选择转战colab,而且今天我还选择了训练过程中参数保存的方法,那就是将中间过程的参数保存成.csv文件,然后再通过.csv文件读出从而可以接下去训练。
昨天遗留
1:今天成功用GPU训练了模型,成功将每个epoch的时间从24s下降到了12s;


2:今天还没有来得及进行子集的区分操作,明天再议;
3:成功将训练的过程参数取出并保存成文件,并且成功从文件中读取出数据;
今日工作
首先是用GPU训练,因为我是用colab做的训练,所以我直接就放出我的命令,无脑复制粘贴上去即可运行,有问题可私信我:
这个是最基础的挂载命令:
from google.colab import drive
drive.mount('/content/gdrive')
%cd ./gdrive/MyDrive/BPnet/
这个是下载conda,conda作为开发管理包非常的好用,可以帮助我们省下很多开发的时间:
%%bash
MINICONDA_INSTALLER_SCRIPT=Miniconda3-4.5.4-Linux-x86_64.sh
MINICONDA_PREFIX=/usr/local
wget https://repo.continuum.io/miniconda/$MINICONDA_INSTALLER_SCRIPT
chmod +x $MINICONDA_INSTALLER_SCRIPT
./$MINICONDA_INSTALLER_SCRIPT -b -f -p $MINICONDA_PREFIX
import sys
_ = (sys.path
.append("/usr/local/lib/python3.6/site-packages"))
下载好conda之后,我们就可以通过conda来下载numba库了,这个是调用GPU的库,一句命令,简简单单。
!conda install numba
from numba import cuda
最后在我们的函数前面加上@jit即可:
@jit
def sigmoid(x):
s = 1 / (1 + np.exp(-x))
# print("sig:", s)
return s
@jit
def dsigmoid(x):
s = sigmoid(x) * (1 - sigmoid(x))
return s
@jit
def ReLU(x):
if x > 0:
s = x
else:
s = 0
return s
@jit
def dReLU(x):
if x > 0:
s = 1
else:
s = 0
return s
@jit
def normalization(x):
max = float(0)
min = float(999)
for i in range(0, total_x):
if (x[i] > max):
max = x[i]
elif (x[i] < min):
min = x[i]
for i in range(0, total_x):
x[i] = (x[i] - min) / (max - min)
# print(x)
return x
这样即可很大程度上加速我们程序的执行速度。
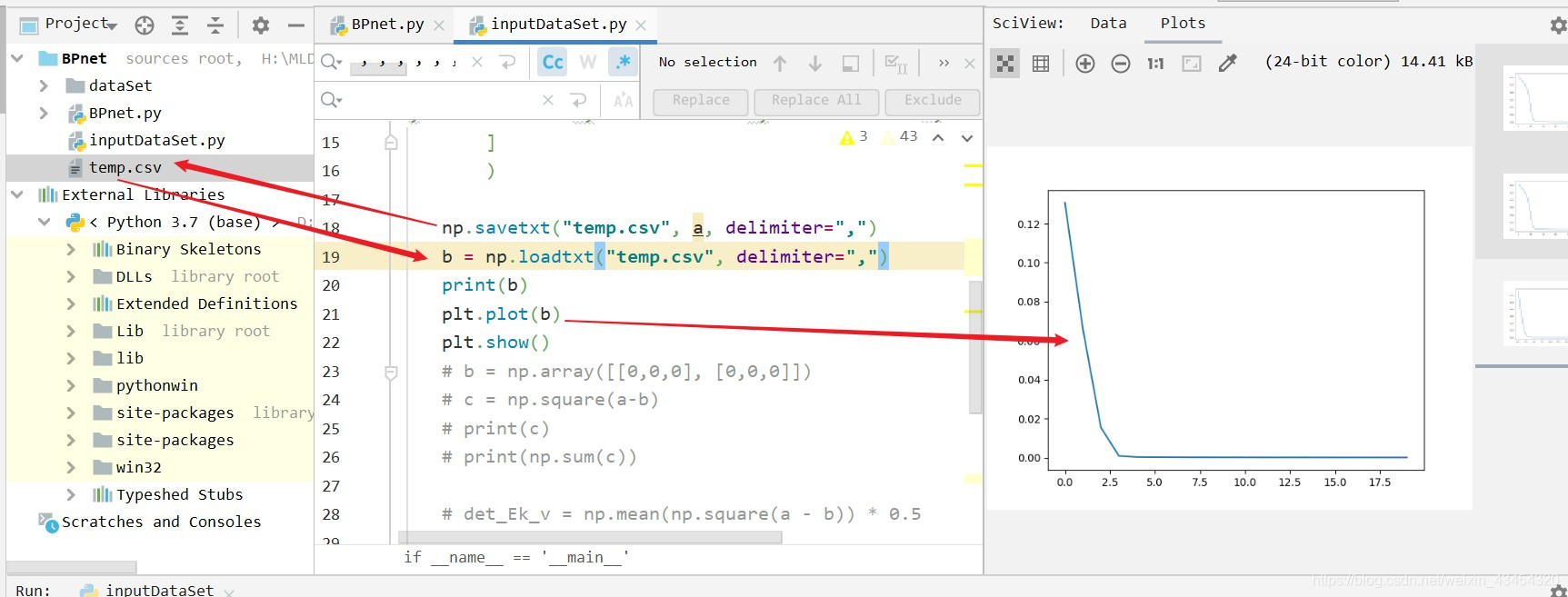
接下来就是参数的保存了,这个就比较简单了,我直接放程序:
a = np.array(
[
0.12311294 ,0.11853857 ,0.11386475 ,0.10877328 ,0.10276829 ,0.09466594
,0.08185167 ,0.05986984 ,0.02847239 ,0.00826174 ,0.00344742 ,0.00201678
,0.00138123 ,0.00103175 ,0.00081404 ,0.00066687 ,0.00056148 ,0.0004827
,0.00042183 ,0.00037354
]
)
np.savetxt("temp.csv", a, delimiter=",")
b = np.loadtxt("temp.csv", delimiter=",")
print(b)
plt.plot(b)
plt.show()
保存下来的.csv文件如下所示:
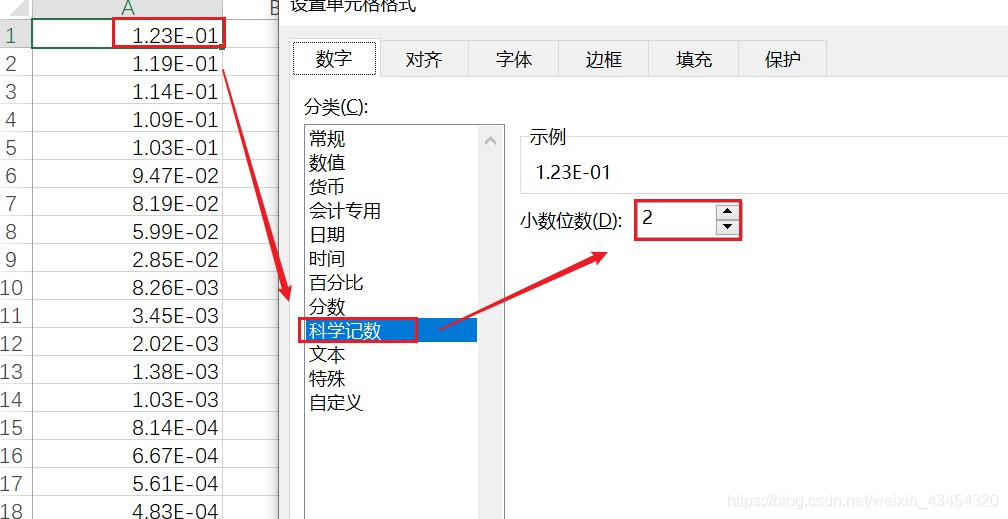
可以看到保存下来的数据格式也是正确的。
明天问题
1:将48000张训练集分成若干个子集,将模型先在子集上进行训练,再求参数的均值,从而得到一个的模型参数;
2:探究学习率对于模型学习的影响;

以上是关于[MNIST03]GPU加速和过程参数保存的主要内容,如果未能解决你的问题,请参考以下文章