TKE 1.20.6搭建Kube-Prometheus(prometheus-oprator)
Posted saynaihe
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了TKE 1.20.6搭建Kube-Prometheus(prometheus-oprator)相关的知识,希望对你有一定的参考价值。
背景:
线上开通了tke1.20.6的集群。嗯腾讯云有个原生的Prometheus的监控,开通了使用了一下。不过我没有怎么玩明白。文档也不全。还是想了下自己手动搭建一个Prometheus-oprator吧!
基本过程基本参照:Kubernetes 1.20.5 安装Prometheus-Oprator。下面讲一下不一样的和需要注意的
过程以及基本注意的:
1.前提重复操作
1.1-1.4操作基本保留都没有问题!
2. 添加 kubeControllerManager kubeScheduler监控
访问了一下Prometheus页面和前几个版本一样依然木有kube-scheduler 和 kube-controller-manager 的监控。但是没有搞明白 为什么kube-apiserver只有两个呢?两个apiserver 169开头的ip方式也有些让我诧异…
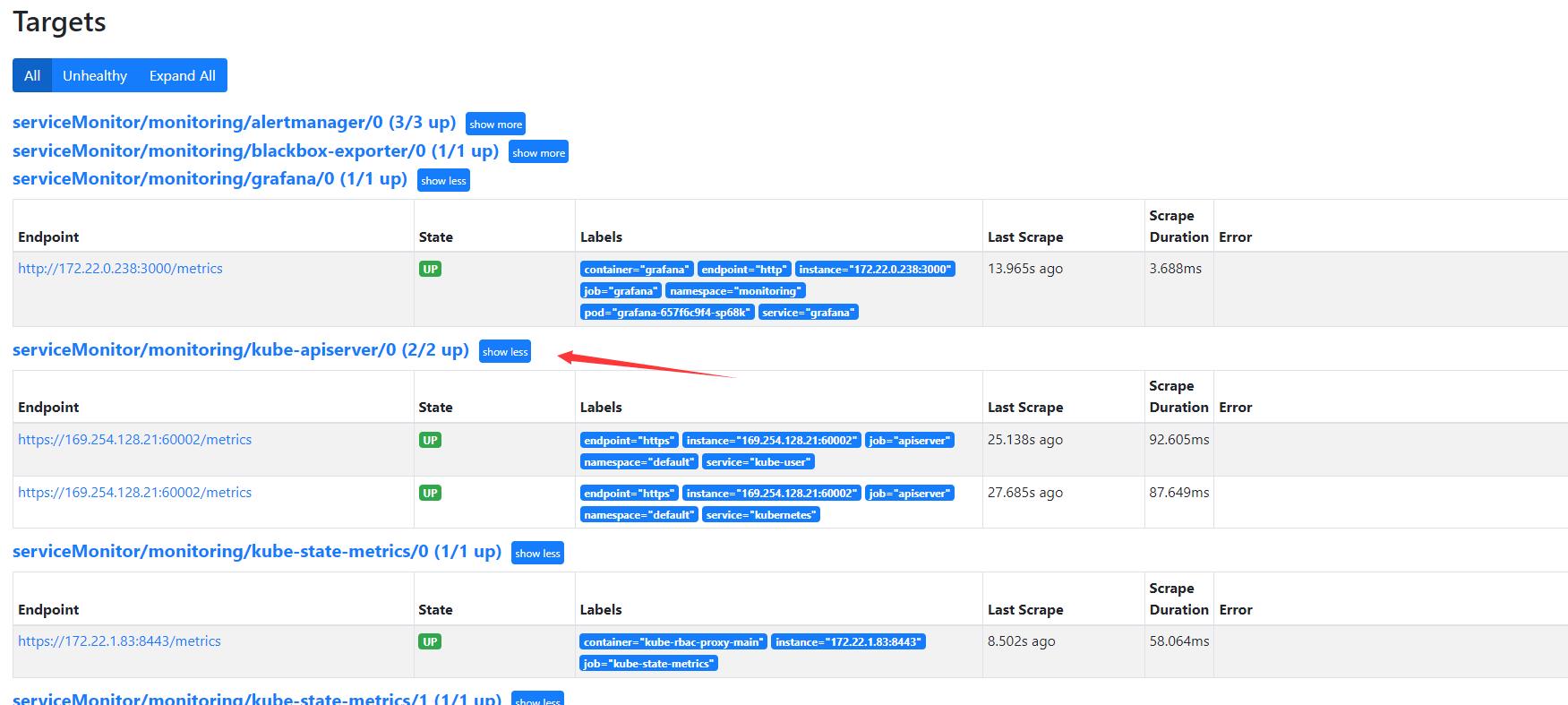
先再master节点执行了下netstat命令发现tke原生监控的都是ipv6的地址不是127.0.0.1的,我也就忽略了修改control-manager和scheduler配置文件了!
netstat -ntlp

这里没有修改kube-controller-manager.yaml kube-scheduler.yaml的配置文件,顺便看了一眼/etc/kubernetes/manifests目录,what?还有cilium的包? tke 1.20.6是不是也是用了cilium?

部署一下control-manager和scheduler的service服务:
cat <<EOF > kube-controller-manager-scheduler.yml
apiVersion: v1
kind: Service
metadata:
namespace: kube-system
name: kube-controller-manager
labels:
app.kubernetes.io/name: kube-controller-manager
spec:
selector:
component: kube-controller-manager
type: ClusterIP
clusterIP: None
ports:
- name: https-metrics
port: 10257
targetPort: 10257
protocol: TCP
---
apiVersion: v1
kind: Service
metadata:
namespace: kube-system
name: kube-scheduler
labels:
app.kubernetes.io/name: kube-scheduler
spec:
selector:
component: kube-scheduler
type: ClusterIP
clusterIP: None
ports:
- name: https-metrics
port: 10259
targetPort: 10259
protocol: TCP
EOF
kubectl apply -f kube-controller-manager-scheduler.yml
kubectl get svc -n kube-system

开启一下endpoints:
cat <<EOF > kube-ep.yml
apiVersion: v1
kind: Endpoints
metadata:
labels:
k8s-app: kube-controller-manager
name: kube-controller-manager
namespace: kube-system
subsets:
- addresses:
- ip: 10.0.4.25
- ip: 10.0.4.24
- ip: 10.0.4.38
ports:
- name: https-metrics
port: 10257
protocol: TCP
---
apiVersion: v1
kind: Endpoints
metadata:
labels:
k8s-app: kube-scheduler
name: kube-scheduler
namespace: kube-system
subsets:
- addresses:
- ip: 10.0.4.25
- ip: 10.0.4.24
- ip: 10.0.4.38
ports:
- name: https-metrics
port: 10259
protocol: TCP
EOF
kubectl apply -f kube-ep.yml
kubectl get ep -n kube-system
登陆Prometheus验证:

why?control-manager都起来了 kube-schedulerj监控状态都是是down啊?
开始排查一下:
在manifests目录下(这一步一点要仔细看下新版的matchLabels发生了改变)
grep -A2 -B2 selector kubernetes-serviceMonitor*
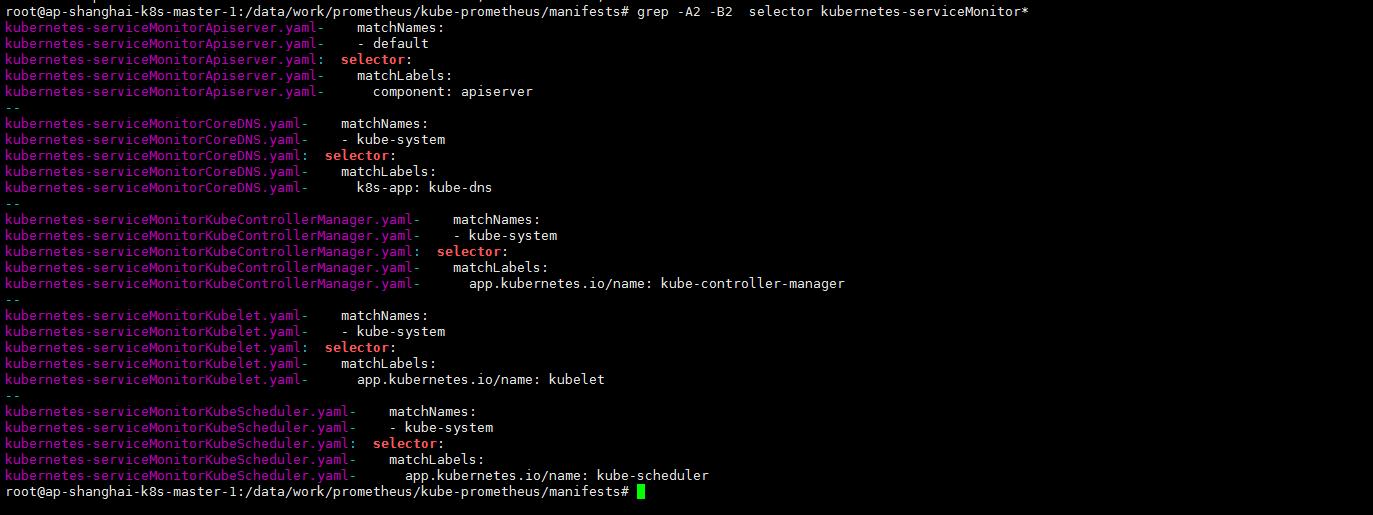
看一眼kube-system下pod的标签:
kubectl get pods -n kube-system --show-labels

不知道为什么,tke kubernetes基本组件的labels都没有?特意看了一眼我自己搭建的集群,以scheduler为例:
kubectl get pods -n kube-schduler-k8s-master-01 -n kube-system --show-labels

特别想知道都喊云原生,标签这些东西能不能保持一下?否则让一般小白用户拍错真的是很难!标签没有我是不是可以手动添加一下?
kubectl label pod kube-scheduler-ap-shanghai-k8s-master-1 kube-scheduler-ap-shanghai-k8s-master-2 kube-scheduler-ap-shanghai-k8s-master-3 -n kube-system app.kubernetes.io/name=kube-scheduler
kubectl label pod kube-scheduler-ap-shanghai-k8s-master-1 kube-scheduler-ap-shanghai-k8s-master-2 kube-scheduler-ap-shanghai-k8s-master-3 -n kube-system component=kube-scheduler
kubectl label pod kube-scheduler-ap-shanghai-k8s-master-1 kube-scheduler-ap-shanghai-k8s-master-2 kube-scheduler-ap-shanghai-k8s-master-3 -n kube-system k8s-app=kube-scheduler


Prometheus页面依然如此:

扎心了!这个时候看到netstat页面:

嗯? 它默认开启了非安全端口?10251?那我改一下10251试试?(虽然忘了官方从1.17还是哪个版本就默认值开通10259了吧?也不知道tke这里还保留开通这个端口的原因是什么)
重新生成一下scheduler的service endpoint服务:
cat <<EOF > kube-scheduler.yaml
apiVersion: v1
kind: Service
metadata:
namespace: kube-system
name: kube-scheduler
labels:
app.kubernetes.io/name: kube-scheduler
spec:
selector:
app.kubernetes.io/name: kube-scheduler
type: ClusterIP
clusterIP: None
ports:
- name: http-metrics
port: 10251
targetPort: 10251
protocol: TCP
---
apiVersion: v1
kind: Endpoints
metadata:
labels:
k8s-app: kube-scheduler
name: kube-scheduler
namespace: kube-system
subsets:
- addresses:
- ip: 10.0.4.25
- ip: 10.0.4.24
- ip: 10.0.4.38
ports:
- name: http-metrics
port: 10251
protocol: TCP
---
EOF
kubectl apply -f kube-scheduler.yaml
重新整一下scheduler的serviceMonitorKubeScheduler:
cat <<EOF > kubernetes-serviceMonitorKubeScheduler.yaml
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
labels:
app.kubernetes.io/name: kube-scheduler
name: kube-scheduler
namespace: monitoring
spec:
endpoints:
- bearerTokenFile: /var/run/secrets/kubernetes.io/serviceaccount/token
interval: 30s
port: http-metrics
scheme: http
tlsConfig:
insecureSkipVerify: true
jobLabel: app.kubernetes.io/name
namespaceSelector:
matchNames:
- kube-system
selector:
matchLabels:
app.kubernetes.io/name: kube-scheduler
EOF
kubectl apply -f kubernetes-serviceMonitorKubeScheduler.yaml

算是曲线救国吧…先糊弄过去吧…
3. ECTD的监控
tke的证书跟原生集群的位置名字是不一样的,如下:
root@ap-shanghai-k8s-master-1:/etc/etcd/certs# ls /etc/etcd/certs
etcd-cluster.crt etcd-node.crt etcd-node.key
root@ap-shanghai-k8s-master-1:/etc/etcd/certs# kubectl -n monitoring create secret generic etcd-certs --from-file=/etc/etcd/certs/etcd-node.crt --from-file=/etc/etcd/certs/etcd-node.key --from-file=/etc/etcd/certs/etcd-cluster.crt

修改Prometheus-Prometheus.yaml添加secrets
secrets
- etcd-certs

kubectl apply -f prometheus-prometheus.yaml
kubectl exec -it prometheus-k8s-0 /bin/sh -n monitoring
ls /etc/prometheus/secrets/etcd/certs/

cat <<EOF > kube-ep-etcd.yml
apiVersion: v1
kind: Service
metadata:
name: etcd-k8s
namespace: kube-system
labels:
k8s-app: etcd
spec:
type: ClusterIP
clusterIP: None
ports:
- name: etcd
port: 2379
protocol: TCP
---
apiVersion: v1
kind: Endpoints
metadata:
labels:
k8s-app: etcd
name: etcd-k8s
namespace: kube-system
subsets:
- addresses:
- ip: 10.0.4.25
- ip: 10.0.4.24
- ip: 10.0.4.38
ports:
- name: etcd
port: 2379
protocol: TCP
---
EOF
kubectl apply -f kube-ep-etcd.yml
cat <<EOF > prometheus-serviceMonitorEtcd.yaml
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: etcd-k8s
namespace: monitoring
labels:
k8s-app: etcd
spec:
jobLabel: k8s-app
endpoints:
- port: etcd
interval: 30s
scheme: https
tlsConfig:
caFile: /etc/prometheus/secrets/etcd-certs/etcd-cluster.crt
certFile: /etc/prometheus/secrets/etcd-certs/etcd-node.crt
keyFile: /etc/prometheus/secrets/etcd-certs/etcd-node.key
insecureSkipVerify: true
selector:
matchLabels:
k8s-app: etcd
namespaceSelector:
matchNames:
- kube-system
EOF
kubectl apply -f prometheus-serviceMonitorEtcd.yaml

prometheus web验证:

etcd的监控就也算做好了
4. prometheus配置文件修改为正式
1. 添加自动发现配置
网上随便抄 了一个:
cat <<EOF > prometheus-additional.yaml
- job_name: 'kubernetes-endpoints'
kubernetes_sd_configs:
- role: endpoints
relabel_configs:
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape]
action: keep
regex: true
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scheme]
action: replace
target_label: __scheme__
regex: (https?)
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
- source_labels: [__address__, __meta_kubernetes_service_annotation_prometheus_io_port]
action: replace
target_label: __address__
regex: ([^:]+)(?::\\d+)?;(\\d+)
replacement: $1:$2
- action: labelmap
regex: __meta_kubernetes_service_label_(.+)
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_service_name]
action: replace
target_label: kubernetes_name
- source_labels: [__meta_kubernetes_pod_name]
action: replace
target_label: kubernetes_pod_name
EOF
注意:cat <后replacement: $1:$2 会变成replacement: : 记得自己手动更改一下!
kubectl create secret generic additional-configs --from-file=prometheus-additional.yaml -n monitoring
2. 增加存储 保留时间 etcd secret
cat <<EOF > prometheus-prometheus.yaml
apiVersion: monitoring.coreos.com/v1
kind: Prometheus
metadata:
labels:
app.kubernetes.io/component: prometheus
app.kubernetes.io/name: prometheus
app.kubernetes.io/part-of: kube-prometheus
app.kubernetes.io/version: 2.28.1
prometheus: k8s
name: k8s
namespace: monitoring
spec:
alerting:
alertmanagers:
- apiVersion: v2
name: alertmanager-main
namespace: monitoring
port: web
enableFeatures: []
externalLabels: {}
image: quay.io/prometheus/prometheus:v2.28.1
nodeSelector:
kubernetes.io/os: linux
podMetadata:
labels:
app.kubernetes.io/component: prometheus
app.kubernetes.io/name: prometheus
app.kubernetes.io/part-of: kube-prometheus
app.kubernetes.io/version: 2.28.1
podMonitorNamespaceSelector: {}
podMonitorSelector: {}
probeNamespaceSelector: {}
probeSelector: {}
replicas: 2
resources:
requests:
memory: 400Mi
secrets:
- etcd-certs
ruleNamespaceSelector: {}
ruleSelector:
matchLabels:
prometheus: k8s
role: alert-rules
securityContext:
fsGroup: 2000
runAsNonRoot: true
runAsUser: 1000
additionalScrapeConfigs:
name: additional-configs
key: prometheus-additional.yaml
serviceAccountName: prometheus-k8s
retention: 60d
serviceMonitorNamespaceSelector: {}
serviceMonitorSelector: {}
version: 2.28.1
storage:
volumeClaimTemplate:
spec:
storageClassName: cbs
resources:
requests:
storage: 50Gi
EOF
kubectl apply -f prometheus-prometheus.yaml
3. clusterrole还的说一下
kubectl logs -f prometheus-k8s-0 prometheus -n monitoring

依然是clusterrole的问题:
cat <<EOF > prometheus-prometheus.yaml
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
labels:
app.kubernetes.io/component: prometheus
app.kubernetes.io/name: prometheus
app.kubernetes.io/part-of: kube-prometheus
app.kubernetes.io/version: 2.28.1
name: prometheus-k8s
rules:
- apiGroups:
- ""
resources:
- nodes
- services
- endpoints
- pods
- nodes/proxy
- nodes/metrics
verbs:
- get
- list
- watch
- apiGroups:
- ""
resources:
- configmaps
- nodes/metrics
verbs:
- get
- nonResourceURLs:
- /metrics
verbs:
- get
EOF
kubectl apply -f prometheus-prometheus.yaml
5. grafana添加持久化存储
注:其实grafana我都可以不安装的我想用Kubernetes 1.20.5 安装Prometheus-Oprator中搭建的grafana做汇总。而且两个集群是在一个vpc的!总比搭建一个thanos好多了…至于thanos我还要有时间了研究一下。这两个集群规模现在都是十几台这样压力应该还是不大的!
cat <<EOF > grafana-pv.yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: grafana
namespace: monitoring
spec:
storageClassName: cbs
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 20Gi
EOF
kubectl apply -f grafana-pv.yaml
修改manifests目录下grafana-deployment.yaml存储
volumes:
- name: grafana-storage
persistentVolumeClaim:
claimName: grafana

kubectl apply -f grafana-deployment.yaml
其他部分基本就同Kubernetes 1.20.5 安装Prometheus-Oprator了总算是跑了起来!
嗯 tke集群的domain 默认就是cluster.local所以这个地方是不用修改的!
6. 另外一个集群的grafana添加本集群的Prometheus
使用Kubernetes 1.20.5 安装Prometheus-Oprator中的grafana添加本Prometheus集群的数据源:

测试通过ok!
注:当然了本来内网是通的 我可以不将Prometheus等服务对外的,可以直接修改prometheus-k8s的service?试一下!


验证一下:
kubectl get svc -n monitoring

打开grafana-configration-data sources 修改Prometheus-1配置url,等待验证通过保存:

save保存一下修改后的DataSource!

打开grafana默认kubernetes模板DataSource选项发现有两个数据源了。可以切换并查看相关的监控图表!

看一下tke的kube-system监控:

个人搭建的kubeadm 1.21+cilium集群:

至于监控报警就都跟Kubernetes 1.20.5 安装Prometheus-Oprator一样了。我这里就只是简单的想让grafana添加两个数据源…thanos有时间了再体验一下了!
以上是关于TKE 1.20.6搭建Kube-Prometheus(prometheus-oprator)的主要内容,如果未能解决你的问题,请参考以下文章