MongoDB操作
Posted 临风而眠
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MongoDB操作相关的知识,希望对你有一定的参考价值。
MongoDB操作(3)
学习资料:B站 传智最新python课程-python就业班
文章目录
一.数据备份与恢复
1.备份
备份的语法:
mongodump -h dbhost -d dbname -o dbdirectory
-
-h:服务器地址,也可以指定端口号
备份本机上的数据库不用写-h
-
-d:需要备份的数据库名称
-
-o︰备份的数据存放位置,此目录中存放着备份出来的数据
如:mongodump -h 192.168.196.128:27017 -d test1 -o ~/Desktop/test1bak
需要重新开终端写此命令,不是在mongo命令行下面输入此命令!
我在桌面上新建一个tmp文件夹,尝试保存本机数据库到那个文件夹

此时,tmp文件夹:
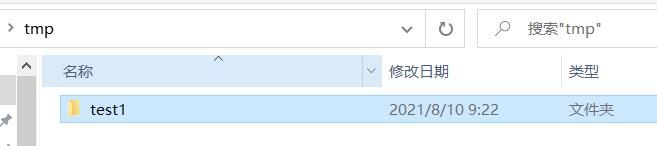

bson和json结合到一起才表示一个数据
2.恢复
恢复语法:
mongorestore -h dbhost -d dbname --dir dbdirectory
- -h:服务器地址
- -d:需要恢复的数据库实例
- –dir:备份数据所在位置
如:
mongorestore -h 192.168.196.128:27017 -d test2 --dir ~/Desktop/test1bak/test1

test1_res是我命名的新的数据库的名字用于恢复备份数据
–dir 后面的路径要到test1文件夹
二.MongoDB的聚合命令
聚合
聚合(aggregate)是基于数据处理的聚合管道
每个文档通过一个由多个阶段(stage)组成的管道,可以对每个阶段的管道进行分组、过滤等功能,然后经过一系列的处理,输出相应的结果。
命令:db.集合名称.aggregate({管道:{表达式}})
1.三个常用管道命令
在mongodb中,文档处理完毕后,通过管道进行下一次处理常用管道如下:
$group:将集合中的文档分组,可用于统计结果
$match:过滤数据,只输出符合条件的文档
$project:修改输入文档的结构,如重命名、增加、删除字段、创建计算结果
$sort:将输入文档排序后输出
$limit:限制聚合管道返回的文档数
$skip:跳过指定数量的文档,并返回余下的文档
$unwind:将数组类型的字段进行拆分
表达式
处理输入文档并输出
语法:表达式:'$列名'常用表达式:
$sum:计算总和,$sum:1表示以一倍计数
$avg:计算平均值
$min:获取最小值
$max:获取最大值
$push:在结果文档中插入值到一个数组中
$first:根据资源文档的排序获取第一个文档数据
$last:根据资源文档的排序获取最后一个文档数据
①$group
- 将集合中的文档分组,可用于统计结果
- _id表示分组的依据,使用某个字段的格式为
$字段
下面先在数据库中插入一个stu集合为例子来实践:
{ "_id" : ObjectId("6111de05d6ae04464f01be3a"), "name" : "小A", "hometown" : "i山", "age" : 20, "gender" : true }
{ "_id" : ObjectId("6111de29d6ae04464f01be3b"), "name" : "小B", "hometown" : "o山", "age" : 18, "gender" : false }
{ "_id" : ObjectId("6111de33d6ae04464f01be3c"), "name" : "小C", "hometown" : "p山", "age" : 18, "gender" : false }
{ "_id" : ObjectId("6111df4ba872f03ec709df14"), "name" : "小D", "hometown" : "q山", "age" : 40, "gender" : true }
{ "_id" : ObjectId("6111e2cda872f03ec709df15"), "name" : "小E", "hometown" : "w山", "age" : 16, "gender" : true }
{ "_id" : ObjectId("6111e2dda872f03ec709df16"), "name" : "小F", "hometown" : "e山", "age" : 45, "gender" : true }
{ "_id" : ObjectId("6111e2eda872f03ec709df17"), "name" : "小G", "hometown" : "r山", "age" : 18, "gender" : true }
比如,按照性别(gender)进行分组:
按照性别分组,获取数据个数和平均年龄
db.stu.aggregate(
{$group:{_id:"$gender"}}
)
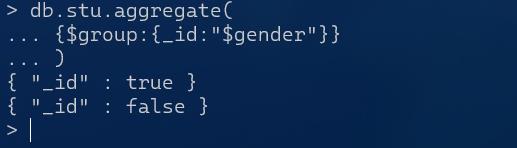
group中给出的键是"_id",所以返回的结果的键是
"_id"
如果想要统计个数:
db.stu.aggregate(
{$group:{_id:"$gender",count:{$sum:1}}}
)
把每条数据作为1,那加起来就是数据的个数
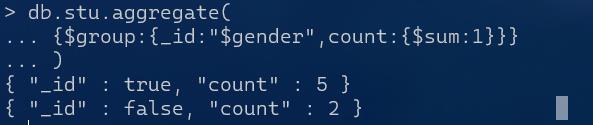
count这种键的名称是自己定的
若想获得不同性别的学生的年龄的平均数:
db.stu.aggregate(
{
$group:{_id:"$gender",count:{$sum:1},avg_age:{$avg:"$age"}}
}
)
注意必须要写 a g e 才 能 取 到 年 龄 , 不 能 漏 掉 ‘ age才能取到年龄,不能漏掉` age才能取到年龄,不能漏掉‘`

集合中所有文档分为一组:Group by null
例:求学生总人数、平均年龄
db.stu.aggregate(
{$group:
{
_id:null,
count:{$sum:1},
mean_Age:{$avg:"$age"}
}
}
)
将此命令复制到终端
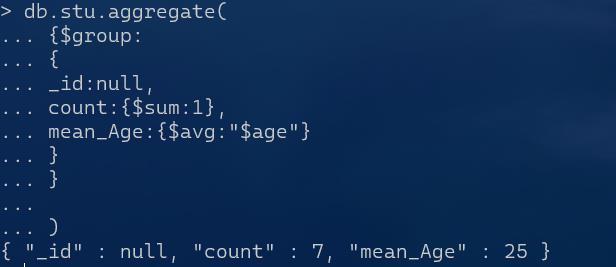
$group注意点:
$group对应的字典中有几个键,结果里就有几个键- 分组依据需要放在
_id后面 - 取不同的字段的值需要使用
$
②$project
- 修改输入文档的结构,如重命名、增加、删除字段、创建计算结果
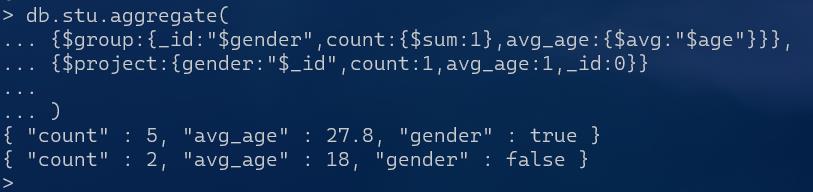
db.stu.aggregate(
{$group:{_id:"$gender",count:{$sum:1},avg_age:{$avg:"$age"}}},
{$project:{gender:"$_id",count:1,avg_age:1,_id:0}}
)
需要的就写1,不需要的写0
$_id管道命令用前面的输出结果作为当前命令参数
这里gender的值就用$取了_id的值
③$match
- 用于过滤数据,只输出符合条件的文档
- 用MongoDB的标准查询操作
find也可以过滤数据,然而match是管道命令,能将结果交给后一个管道,但是find不可以
按年龄过滤数据
db.stu.aggregate(
{$match:{age:{$gt:20}}},
{$group:{_id:"$gender",count:{$sum:1}}},
{$project:{_id:0,gender:"$_id",count:1}}
)
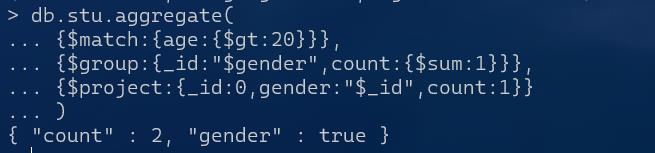
结果说明大于20岁的只有2名男性
改成大于等于18岁:

MongoDB的find那里使用的高级查询在这里也适用
如:查询年龄小于19岁或者家乡在q山、e山的数据
db.stu.aggregate(
{$match:{$or:[{age:{$lt:19}},{hometown:{$in:["q山","e山"]}}]}},
{$group:{_id:"$gender",count:{$sum:1}}},
{$project:{_id:0,gender:"$_id",count:1}}
)

练习:按多个条件分组
将下列json加入数据库
{ "country" : "china", "province" : "sh", "userid" : "a" }
{ "country" : "china", "province" : "sh", "userid" : "b"}
{ "country" : "china", "province" : "sh", "userid" : "a"}
{ "country" : "china", "province" : "sh", "userid" : "c" }
{ "country" : "china", "province" : "j", "userid" : "da" }
{ "country" : "china", "province" : "bj", "userid" : "fa"}
{ "country" : "china", "province" : "bj", "userid" : "ga"}
{ "country" : "usa", "province" : "florida", "userid" :"h"}
统计出每个country/province下的userid的数量(同一个userid只统计一次)

每个userid只统计一次,那么就是要去重
同时按照多个字段进行分组,就可以去重
db.dist.aggregate(
{$group:{_id:{country:"$country",province:"$province"}}}
)
此时就实现了同时对country和province进行分组
把值设为字典,则返回的结果的值也是字典
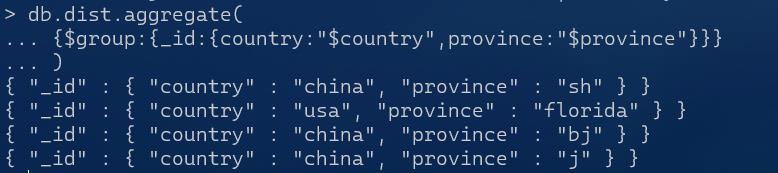
加上userid:
db.dist.aggregate(
{$group:{_id:{country:"$country",province:"$province",userid:"$userid"}}}
)
此时就达到了去重目的

但还没结束,还需要统计数量
db.dist.aggregate(
{$group:{_id:{country:"$country",province:"$province",userid:"$userid"}}},
{$group:{_id:{country:"$_id.country" , province:"$_id.province"},count:{$sum:1}}}
)
注意下面不能直接取出country和province的值,上一个管道到这一个管道,可以直接得到的是_id的值

继续修改输出样式:
db.dist.aggregate(
{$group:{_id:{country:"$country",province:"$province",userid:"$userid"}}},
{$group:{_id:{country:"$_id.country" , province:"$_id.province"},count:{$sum:1}}},
{$project:{country:"$_id.country",province:"$_id.province",count:1,_id:0}}
)
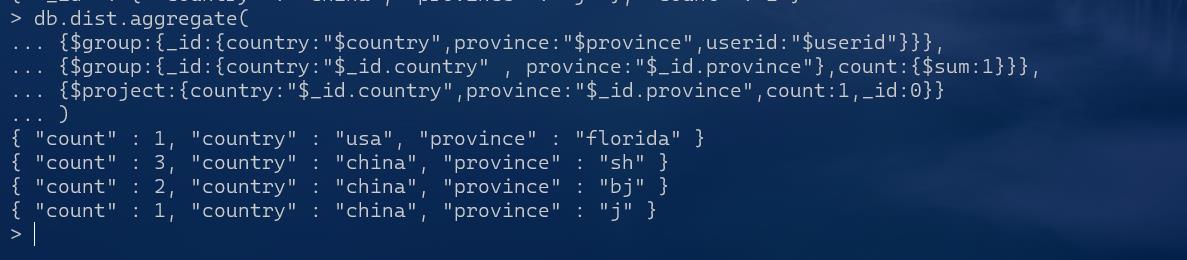
注
1.取字典嵌套字典中的键的时候,要用.
2.能够按照多个键进行分组
每一个管道依次进行处理!
2.其他管道命令
①$sort
- 用于将输入文档排序后输出
- 例:查询学生信息,按年龄升序
db.stu.aggregate({$sort:{age:1}})

降序是 -1

-
例:查询男生、女生人数,按人数降序
首先要分组:
db.stu.aggregate(
{$group:{_id:"$gender",count:{$sum:1}}}
)

得到的结果有两个字段,要对此结果按照count排序
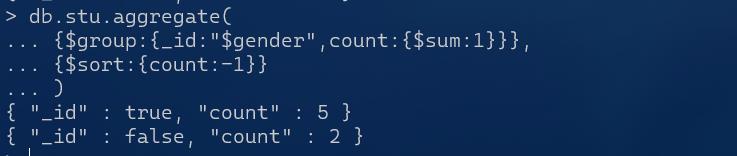
db.stu.aggregate(
{$group:{_id:"$gender",count:{$sum:1}}},
{$sort:{count:-1}}
)
其实和find里面的排序差不多
②$skip、$limit
$limit就是限制聚合管道返回的文档数
db.stu.aggregate({$limit:2})

注意和find那里不同,find那里使用limit和skip不需要加
$,而这里需要
$skip就是跳过指定数量的文档,并返回余下的文档
db.stu.aggregate({$skip:2})

- 注意顺序:先skip,再limit
db.stu.aggregate({$skip:2},{$limit:2})

③$unwind
- 将文档中的某一个数组类型字段拆分成多条,每条包含数组中的一个值
语法:
db.集合名称.aggregate({$unwind:"$字段名称"})
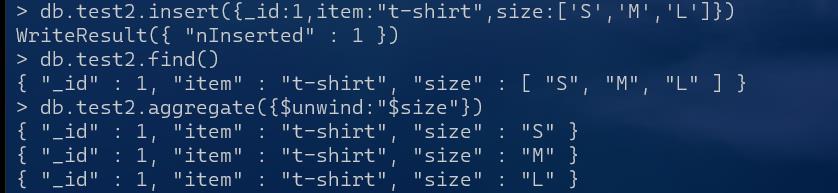
db.test2.insert({_id:1,item:"t-shirt",size:['S','M','L']})
db.test2.aggregate({$unwind:"$size"})
练习
数据库中有一条数据:{“username”:“Alex” ,“tags”: [ ‘C’,‘Java’,‘C++’]},如何获取该tag列表的长度?
插入数据
db.test2.insert({"username":"Alex" ,"tags": [ 'C','Java','C++']})
先匹配到这条数据,再拆分,然后分组,要统计整个的个数,那么就要Group by null
db.test2.aggregate({$match:{username:"Alex"}},{$unwind:"$tags"},{$group:{_id:null,sum:{$sum:1}}})

属性preserveNullAndEmptyArrays
属性值为false表示丢弃属性值为空的文档
属性preserveNullAndEmptyArrays值为true表示保留属性值为空的文档
先在集合test2里面多插入几条数据

此时用$unwind
db.test2.aggregate({$unwind:"$size"})
size为空的没有返回

解决办法:
db.inventory.aggregate({
$unwind : {
path: '$字段名称',
preserveNullAndEmptyArrays :<boolean>#防止数据丢失
}
})
db.test2.aggregate({
$unwind:{
path:'$size',
preserveNullAndEmptyArrays:true
}
})

三.遇到的问题
1.终端中backspace失效

backspace突然失去了删除回退功能,只有左键的功能与此同时 键盘上的左右键失效
backspace还发生一个问题是,回退的时候自动把前一个字符变成)
重新开了一个终端打开mongo,但是这个问题出现的原因还未知
2.前面的练习
最后一步统计userid数量的时候
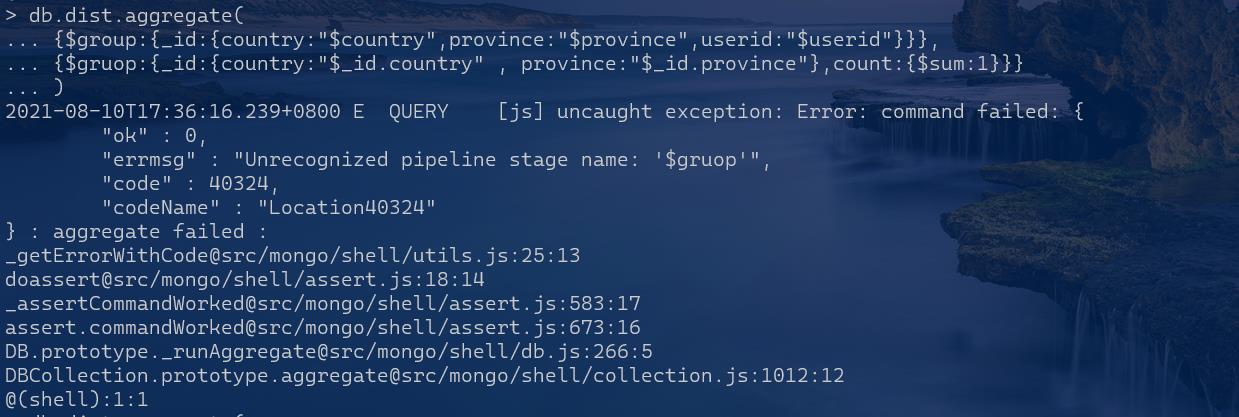
我的这一段命令会报错:
db.dist.aggregate(
{$group:{_id:{country:"$country",province:"$province",userid:"$userid"}}},
{$gruop:{_id:{country:"$_id.country" , province:"$_id.province"},count:{$sum:1}}}
)
我又重新写了一遍:
db.dist.aggregate(
{$group:{_id:{country:"$country",province:"$province",userid:"$userid"}}},
{$group:{_id:{country:"$_id.country" , province:"$_id.province"},count:{$sum:1}}}
)
然而这一段就不报错
可是,这两段内容有啥不同吗?????😐😐😐❓❓
以上是关于MongoDB操作的主要内容,如果未能解决你的问题,请参考以下文章
VSCode自定义代码片段15——git命令操作一个完整流程
VSCode自定义代码片段15——git命令操作一个完整流程
ios - Heroku 和 MongoDb 上的自定义解析服务器错误 3080:JSON 文本没有以数组或对象开头,并且允许未设置片段的选项