ElasticSearch探索之路权重计算与文本分析:布尔模型TF/IDF向量空间模型分析与分析器
Posted 凌桓丶
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ElasticSearch探索之路权重计算与文本分析:布尔模型TF/IDF向量空间模型分析与分析器相关的知识,希望对你有一定的参考价值。
权重计算原理
在Elasticsearch中,每个文档都有相关性评分,用一个正浮点数字段 _score 来表示 。 _score 的评分越高,相关性越高。为了保证搜索到的结果相关度更高,在默认情况下返回结果会按照相关度降序排序。
Elasticsearch使用布尔模型查找匹配文档,并用一个名为实用评分函数的公式来计算相关度。这个公式借鉴了词频/逆向文档频率和向量空间模型,同时也加入了一些现代的新特性,如协调因子,字段长度归一化,以及词或查询语句权重提升。
布尔模型
布尔模型(Boolean Model) 适用于在查询中使用 AND 、 OR 和 NOT (与、或、非)这样的条件来查找匹配的文档,如以下查询:
full AND text AND search AND (elasticsearch OR lucene)
会将所有包括词 full 、 text 和 search ,以及 elasticsearch 或 lucene 的文档作为结果集。
这个过程简单且快速,它将所有可能不匹配的文档排除在外。
词频/逆向文档频率(TF/IDF)
Elasticsearch的相似度算法被定义为检索词频率/反向文档频率(TF/IDF),主要依赖以下内容
-
检索词频率
-
检索词在该字段出现的频率。出现频率越高,相关性也越高。5次提到同一词的字段比只提到1次的更相关。
-
词频的计算方式如下:
tf(t in d) = √frequency词
t在文档d的词频(tf)是该词在文档中出现次数的平方根。
-
-
逆向文档频率
-
每个检索词在索引中出现的频率。频率越高,相关性越低。检索词出现在多数文档中会比出现在少数文档中的权重更低。
-
逆向文档频率的计算公式如下:
idf(t) = 1 + log ( numDocs / (docFreq + 1))词
t的逆向文档频率(idf)是:索引中文档数量除以所有包含该词的文档数,然后求其对数。
-
-
字段长度归一值
-
字段的长度。长度越长,相关性越低。 检索词出现在一个短的 title 要比同样的词出现在一个长的 content 字段权重更大。
-
字段长度的归一值公式如下:
norm(d) = 1 / √numTerms字段长度归一值(
norm)是字段中词数平方根的倒数。
-
以上三个因素是在索引时计算并存储的。最后将它们结合在一起计算单个词在特定文档中的权重 。
向量空间模型
当然,查询通常不止一个词,所以需要一种合并多词权重的方式——向量空间模型(vector space model)。
向量空间模型(vector space model)提供一种比较多词查询的方式,单个评分代表文档与查询的匹配程度,为了做到这点,这个模型将文档和查询都以 向量(vectors) 的形式表示,而向量实际上就是包含多个数的一维数组,例如:
[1,2,5,22,3,8]
在向量空间模型里,向量空间模型里的每个数字都代表一个词的权重 ,与词频/逆向文档频率计算方式类似,下面举一个例子。
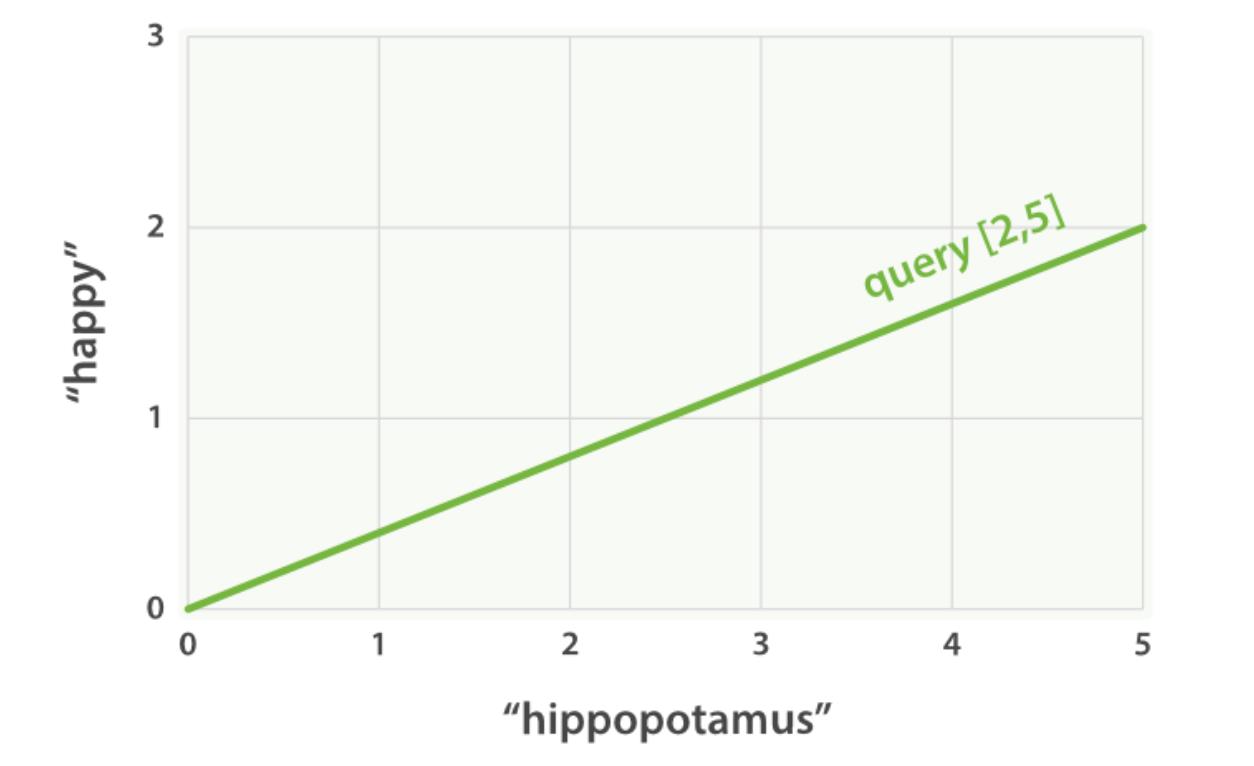
设想如果查询 “happy hippopotamus” ,常见词 happy 的权重较低,不常见词 hippopotamus 权重较高,假设 happy 的权重是 2 , hippopotamus 的权重是 5 ,可以将这个二维向量—— [2,5] ——在坐标系下作条直线,线的起点是 (0,0) 终点是 (2,5) ,如下图
现在,设想我们有三个文档:
- I am happy in summer 。
- After Christmas I’m a hippopotamus 。
- The happy hippopotamus helped Harry 。
三篇文档的命中词如下
- 文档 1:
(happy,____________)——[2,0] - 文档 2:
( ___ ,hippopotamus)——[0,5] - 文档 3:
(happy,hippopotamus)——[2,5]
可以为每个文档都创建包括每个查询词—— happy 和 hippopotamus ——权重的向量,然后将这些向量置入同一个坐标系中,如下图
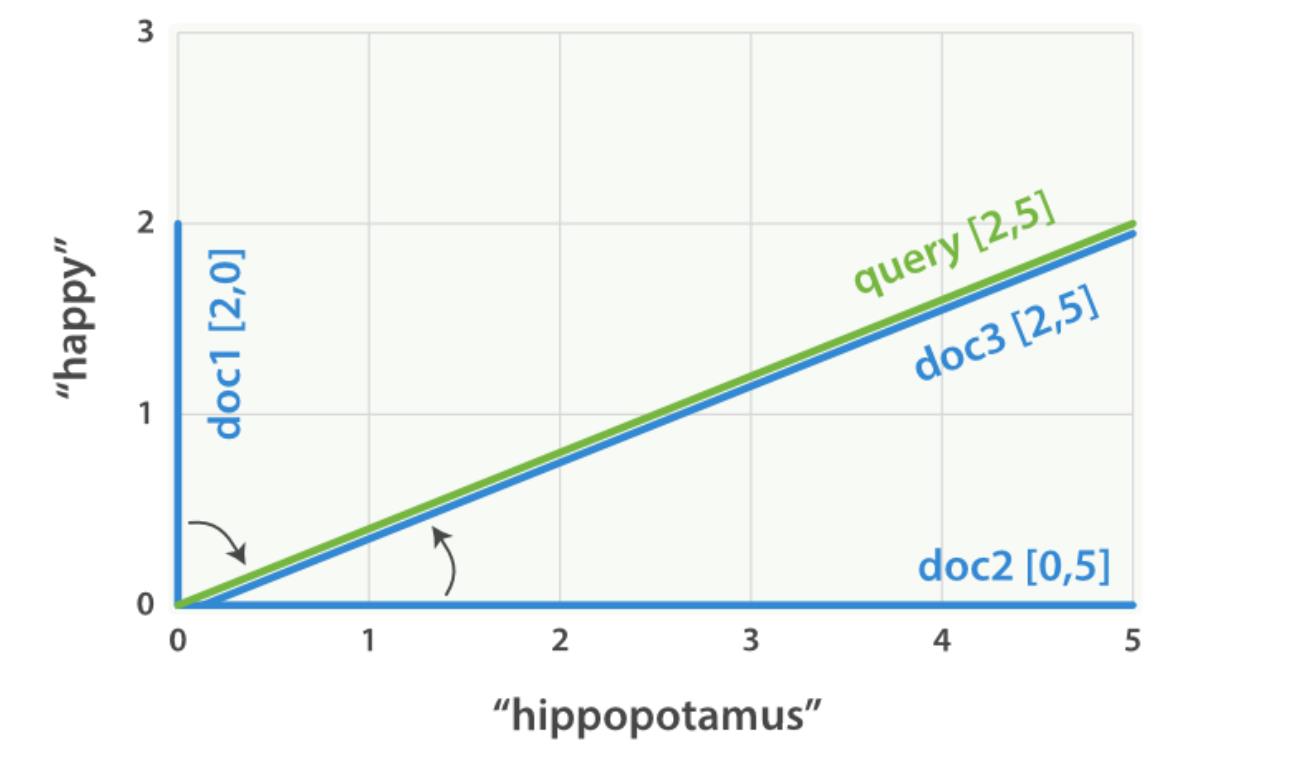
向量之间是可以比较的,只要测量查询向量和文档向量之间的角度就可以得到每个文档的相关度,文档 1 与查询之间的角度最大,所以相关度低;文档 2 与查询间的角度较小,所以更相关;文档 3 与查询的角度正好吻合,完全匹配。
在实际中,只有二维向量(两个词的查询)可以在平面上表示,幸运的是, 线性代数为我们提供了计算两个多维向量间角度工具,这意味着可以使用如上同样的方式来解释多个词的查询。
文本分析
分析与分析器
分析包含以下两个流程:
- 将一块文本分成适合于倒排索引的独立的词条
- 将这些词条统一化为标准格式以提高它们的可搜索性,或者recall
分析器执行上面的工作。 分析器实际上是将三个功能封装到了一个包里:
- 字符过滤器:字符串按顺序通过每个字符过滤器 。他们的任务是在分词前整理字符串。一个字符过滤器可以用来去掉html,或者将
&转化成and。 - 分词器:字符串被分词器拆分为单个的词条。一个简单的分词器遇到空格和标点的时候,可能会将文本拆分成词条。
- 分词过滤器:词条按顺序通过每个分词过滤器。这个过程可能会改变词条(例如,小写化
Quick),删除词条(例如, 像a,and,the等停用词),或者增加词条(例如,像jump和leap这种同义词)。
分析流程如下图所示:

内置分析器
Elasticsearch还附带了可以直接使用的预包装的分析器。接下来我们会列出最重要的分析器。为了证明它们的差异,我们看看每个分析器会从下面的字符串得到哪些词条:
"Set the shape to semi-transparent by calling set_trans(5)"
-
标准分析器
-
标准分析器是Elasticsearch默认使用的分析器。它是分析各种语言文本最常用的选择。它根据Unicode联盟定义的单词边界划分文本、删除绝大部分标点。最后,将词条小写。
-
处理结果: set, the, shape, to, semi, transparent, by, calling, set_trans, 5
-
-
简单分析器
-
简单分析器在任何不是字母的地方分隔文本,将词条小写。
-
处理结果: set, the, shape, to, semi, transparent, by, calling, set, trans
-
-
空格分析器
-
空格分析器在空格的地方划分文本。
-
处理结果: Set, the, shape, to, semi-transparent, by, calling, set_trans(5)
-
-
语言分析器
-
特定语言分析器会结合指定语言的特点来进行分词。例如,英语分析器附带了一组英语无用词(常用单词,例如
and或者the,它们对相关性没有多少影响),它们会被删除。 由于理解英语语法的规则,这个分词器可以提取英语单词的 词干 。 -
处理结果: set, shape, semi, transpar, call, set_tran, 5 // transparent、 calling 和 set_trans 已经变为词根格式。
-
自定义分析器
虽然Elasticsearch带有一些现成的分析器,然而在分析器上Elasticsearch真正的强大之处在于,你可以通过在一个适合你的特定数据的设置之中组合字符过滤器、分词器、词汇单元过滤器来创建自定义的分析器。
我们可以在analysis下的相应位置设置字符过滤器、分词器和分词过滤器:
PUT /my_index
{
"settings": {
"analysis": {
"char_filter": { ... custom character filters ... },
"tokenizer": { ... custom tokenizers ... },
"filter": { ... custom token filters ... },
"analyzer": { ... custom analyzers ... }
}
}
}
下面给出一个例子,实现一个简单的分析器
PUT /my_index
{
"settings": {
"analysis": {
"char_filter": {
"&_to_and": {
"type": "mapping",
"mappings": [ "&=> and "]
}},
"filter": {
"my_stopwords": {
"type": "stop",
"stopwords": [ "the", "a" ]
}},
"analyzer": {
"my_analyzer": {
"type": "custom",
"char_filter": [ "html_strip", "&_to_and" ],
"tokenizer": "standard",
"filter": [ "lowercase", "my_stopwords" ]
}}
}}}
/*
从上往下以此实现了自定义的字符过滤器、分词过滤器、分析器
字符过滤器&_to_and:将&转换为and
分词过滤器my_stopwords:去掉停用词the, a
分析器my_analyzer:组合字符过滤器和分词过滤器
*/
以上是关于ElasticSearch探索之路权重计算与文本分析:布尔模型TF/IDF向量空间模型分析与分析器的主要内容,如果未能解决你的问题,请参考以下文章