对抗软件系统复杂性③:恰当分层,不多不少
Posted OneFlow深度学习框架
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了对抗软件系统复杂性③:恰当分层,不多不少相关的知识,希望对你有一定的参考价值。

作者 | 袁进辉
在之前的文章里,我们探讨了诸如“如无必要,勿增实体”,“全局一致的概念(隐喻)"这些用来对抗软件系统复杂性的手段,强调了要较”克制“地使用抽象手段,即尽量用最少的概念解决最多的问题。
当然,抽象(abstraction)是克服复杂性必须借助的手段,无论是模块化(modularity),还是分层虚拟化(virtualization),都是通过抽象实现”隔离“和”隐藏“信息的目的,去伪存真,去粗存精,删繁就简。本文我们以分布式深度学习框架中网络数据传输模块的设计为例,讨论如何做恰到好处的分层抽象。
1
分层抽象的好处
在”再谈去虚拟化对深度学习系统的必要性”里,我们提过David Wheeler那句名言:
All problems in computer science can be solved by another level of indirection, except for the problem of too many layers of indirection.
除非引入超出需求的抽象层次,分层抽象总会带来很多好处:引入一层新的抽象,可以把与上层应用无关的细节隐藏掉,有选择的给上层用户暴露一些功能供其使用,也称底层细节对用户透明,既不损害上层应用的功能,又能享受“关注点分离”(separation of concerns)的好处,增加易用性。
针对网络互联需求,最知名的分层抽象的案例莫过于OSI七层概念模型和TCP/IP协议栈的四层实现了,每一层抽象解决一个问题,让上一层实现更简单且不需要关注更下一层的实现细节。
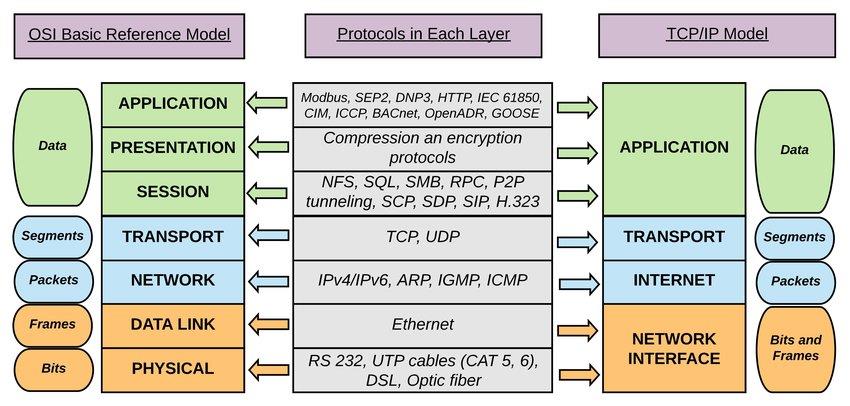
OSI七层模型与TCP/IP协议栈的逻辑对应关系
本文讨论深度学习框架的网络传输抽象,不过不涉及OSI或TCP/IP这么底层实现,只关注从传输层到应用层的问题。
2
控制平面与数据平面
分布式深度学习框架在系统设计和实现层面都需要处理各种网络传输需求,从功能上分,有两类基本需求:
控制平面(control plane),处理分布式系统经常包含的协议层面的需求,包括系统启动时机器之间的握手,运行结束时优雅退出,计算图和执行计划的传递,心跳协议等等。此类通信需求传输量一般不大,传输频率也不高,编程易用性比传输效率更重要。
数据平面(data plane),分布式深度学习的计算过程需要的传输,包括原始数据传输,中间激活值或反向计算差分结果,权重及梯度等数据的传输。此类通信需求传输量可能比较大,传输频率也非常高,传输效率比编程易用性更重要。
3
分布式深度学习框架的网络传输需求概览
我们可以把深度学习框架中与网络通信相关的模块按下图展示的层次来归类。
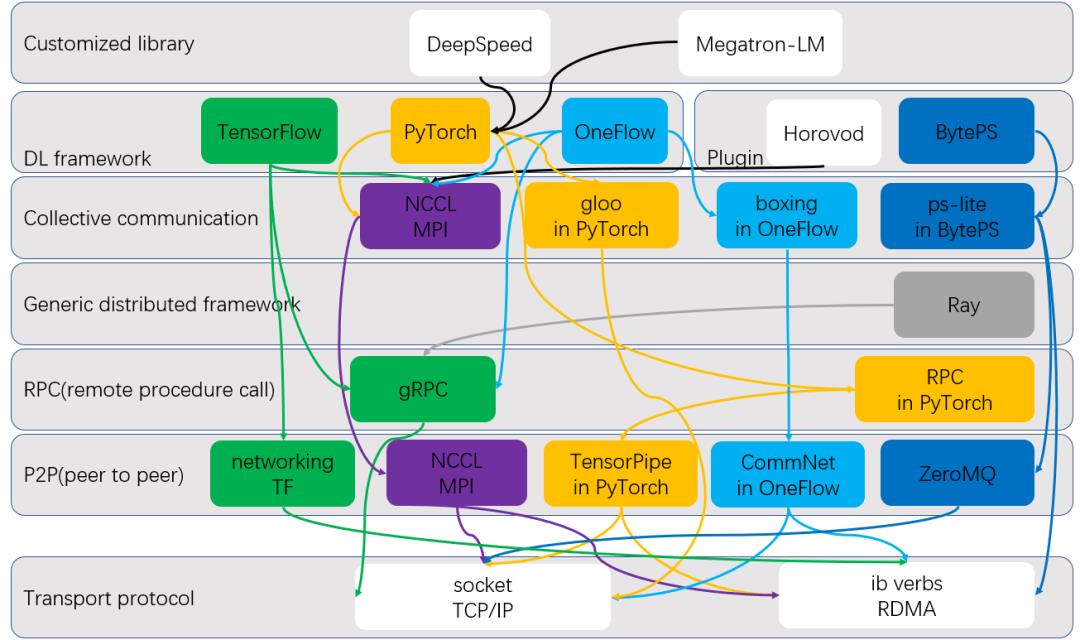
分布式深度学习框架网络传输的抽象层次
最底层的通信协议可以是最常见的TCP/IP,也就是基于套接字(socket)来编程。深度学习负载对传输带宽和延迟的要求非常高,一般深度学习集群都支持RDMA协议,基于IB verbs来编程。无论上层使用了多少层封装,所有深度学习框架的通信功能最终都依赖于socket或者IB verbs。
理论上任何传输需求都可以直接基于底层协议来编程,这样会带来最大的效率收益,但直接基于底层API编程的复杂度太高,而且socket和IB verbs的编程接口也不一致,为了降低网络编程的难度,一般需要对底层网络接口进行封装。
首先引入一层点对点(peer to peer, P2P)传输的抽象,譬如ZeroMQ隐藏了socket编程的复杂性,只向上暴露基于消息和管道的抽象。P2P抽象可以隐藏掉socket和IB verbs的差别,向上层暴露一致的编程接口,譬如NCCL,PyTorch TensorPipe和OneFlow CommNet模块都为这个目的而生。
P2P的编程接口的使用门槛可以进一步降低,那就是把P2P的管道封装成远程过程调用(Remote procedure call, RPC)。RPC是一种client-server架构,可以让一台机器上的程序像调用本地函数一样使用其它机器上的服务。控制平面对易用性的需求高于传输效率,无一例外,所有深度学习框架在控制平面都借助远程过程调用(RPC)抽象来实现。
RPC有各种各样的实现,譬如Google研发的gRPC,百度的bRPC,PyTorch基于自研后端TensorPipe实现的RPC库等。不过,RPC抽象会对数据传输引入额外的开销,如序列化和反序列化等操作,影响传输效率。特别是,大部分RPC实现(如gRPC,bRPC)不支持RDMA,无法享受高性能网络的优点(当然,PyTroch基于TensorPipe开发的RPC例外,TensorPipe支持RDMA)。
因此,数据平面的传输需求不建议基于RPC开发。TensorFlow数据平面的点对点传输都基于RPC来实现,这一度成为TensorFlow的性能瓶颈。不过,社区为TensorFlow开发了一个TensorFlow networking的插件,可以帮助TensorFlow在点对点传输时使用RDMA。
分布式计算中的通信模式可以分成“规则的”和“不规则的”,其中规则传输模式是指和高性能中MPI类似的需求,包括all-reduce, all-gather, reduce-scatter等集群通信原语;集群通信原语之外的传输模式都可以称为不规则传输模式。
规则传输模式的例子包括NVIDIA专门为GPU集群开发了集群通信库NCCL,以及深度学习框架自研的集群通信功能,包括PyTorch gloo, OneFlow boxing功能,以及参数服务器ps-lite(这里以字节跳动版为例,它支持RDMA)。但一般来说框架自研的集群通信功能无法超越NCCL,因此所有深度学习框架都会集成并默认调用NCCL。
这里把Ray作为一个用于实现非规则的传输模式的例子,灵活度最高,可以实现任何分布式功能,当然也包括那些规则的传输模式,但不足之处在于,一方面,Ray基于gRPC实现,不支持高性能网络RDMA协议,另一方面,深度学习里主要是规则的通信模式,基于Ray这种通用分布式系统实现的集群通信的效率比不上专门为规则传输模式开发的集群通信库。因此,我认为在深度学习的市场里没有Ray的地位。
无论是规则传输还是非规则传输都可以基于点对点传输功能实现。但是,当一个功能变得特别重要时,就值得专门为它设计和实现一套代码。
为弥补TensorFlow, PyTorch等深度学习框架早期版本对最简单的数据并行都支持不好的问题,出现了专门用于加速数据并行的插件Horovod, BytePS,不过当深度学习框架自身解决这些问题之后,此类插件的需求就没有那么强了。
为弥补原有深度学习框架无法支持训练大模型需要的数据并行、流水并行等技术,出现了DeepSpeed,Megatron-LM等定制库,不过,这些功能理应是通用深度学习框架应该支持的,当深度学习框架自身具备这些功能之后,此类定制库的需求也就没有那么强了。
对于Ray这种通用分布式计算框架,TensorFlow, PyTorch, OneFlow等深度学习框架,以及Horovod, BytePS等插件,以及DeepSpeed, Megatron-LM等定制库,更多需要考虑的是向上层用户暴露什么样的编程接口,本文暂不讨论,以后再专门写文章讨论。
4
最佳实践
通过以上分析,我们可以大约得到一些最佳实践:
1、底层传输协议要同时支持socket和IB verbs;
2、控制平面最好通过RPC抽象实现;
3、数据平面的点对点传输可以直接基于P2P封装实现,而不必再经过RPC封装;
4、数据平面的规则通信模式应使用NCCL,不规则通信模式都可以借助点对点传输来实现。
可以看出来,RPC、点到点传输、集群通信原语这些抽象是必不可少的,应该在合适的场景用合适的抽象,特别是不要基于RPC去实现点对点传输和集群通信传输,这得不偿失。不过,在原有主流框架里出现了一些反面例子。
TensorFlow的最初设计里,无论是控制平面还是数据平面都基于gRPC实现,这显然是未经深思熟虑的做法,具有严重的性能问题,当这个问题暴露出来之后,曾出现过几个修补的办法,譬如把gRPC扩展成使用RDMA进行传输,不过这个项目后来夭折了;废弃基于gRPC实现的参数服务器(parameter server),而是使用NCCL实现集群通信功能,这个办法很奏效,也是所有其它框架的共识;研发TensorFlow networking,令TensorFlow点对点传输可借助RDMA,不过这个功能是一个插件,默认情况还是通过gRPC。
TensorFlow还基于gRPC的P2P语义实现了一套集群通信的功能,这个也是多余的、不实用的。总结下来就是:
(1)没有基于底层传输协议打造P2P传输组件,而是跨越了P2P传输组件直接基于gRPC来实现点对点传输需求,这么做固然降低了实现难度,但丧失了使用RDMA的机会,也引入了gRPC自身的开销;
(2)不仅基于gRPC来满足点对点传输需求,也借助gRPC实现了集群通信的功能,这么做从完备性上没有问题,但从实用性上看就很糟糕,集群通信功能是深度学习频繁使用和高度依赖的模块,完全值得针对需求做高度优化的定制开发(其实就是NCCL),基于gRPC的集群通信功能应该极少被用到。
PyTorch专门为点对点传输功能实现了TensorPipe,并基于TensorPipe实现了RPC库,不过在点对点传输的场合原本可以直接调用TensorPipe,但PyTorch坚持使用RPC封装后的TensorPipe,个人认为这层RPC封装是多此一举,浪费(白瞎)了设计和实现都很精良的TensorPipe。
以OneFlow为例,当基于上述最佳实践去实现分布式深度学习框架,并去掉可能处于过渡状态的插件之后,且数据并行、模型并行、流水并行作为框架原生的功能,一个合适的抽象层次可能长这个样:
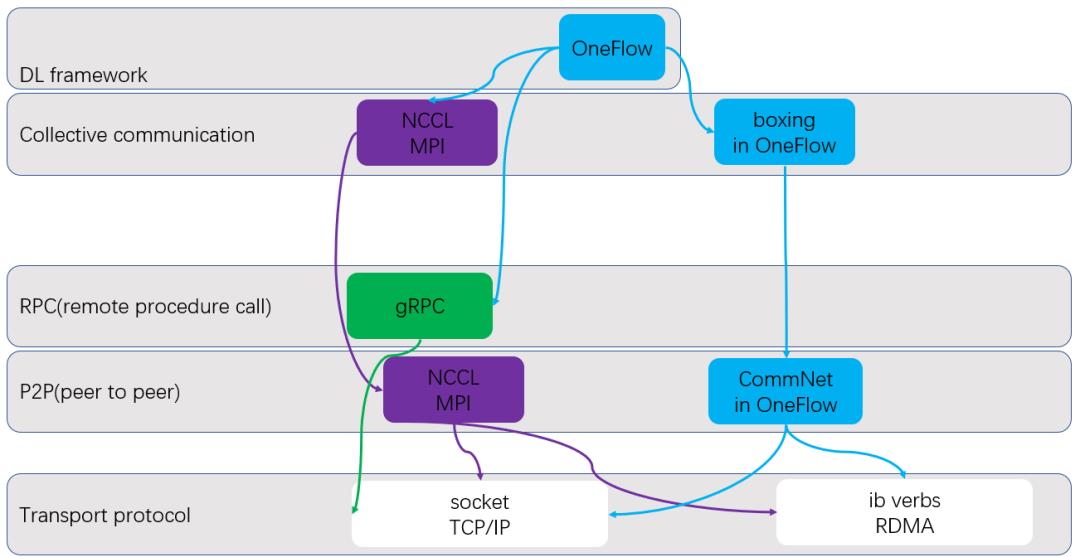
上图一个显著的特征是集群通信是跳过了RPC直接基于点到点通信库构建。当然,这仍不是最理想的设计,我觉得更好的状态是:
1,基于CommNet实现一个简单的RPC库,去掉对臃肿的gRPC的依赖,OneFlow只需要最简单的RPC功能就够了,基于CommNet实现一套RPC并不复杂;
2,boxing已经可以支持通用的集群通信功能,从而可以用于各种除NVIDIA GPGPU之外的加速器上,不过在GPU集群上的性能比不过NCCL,如果能超过NCCL就可以完全去掉对NCCL的依赖,但做出来比NCCL还强的集群通信库难度很大。
集群通信的接口不需要设计,与MPI对齐即可,实现出能挑战NCCL的集群通信库是未来需要解决的一个非常有趣的难题,充分发挥流水线功能,最大程度重叠传输和计算是关键中的关键,希望以后OneFlow可以实现这个目标。
5
小结
分层可以实现信息隐藏和关注点分离,让底层实现的细节对上层用户透明,令上层应用面向接口而不是面向实现编程。
分布式深度学习框架里的网络传输需求可以分成控制平面和数据平面,二者的需求不一样。
控制平面更需要易用性,因此控制平面一般需要RPC抽象。数据平面更需要效率,因此数据平面不鼓励中间层抽象,且至少支持TCP/IP和RDMA两种协议;数据平面的传输分点到点传输和集群通信库,二者都分别有高度优化的实现。
Ray等通用分布式计算框架擅长于处理非规则通信模式,但深度学习场景的主流是规则的通信模式,因此可供Ray发挥之处有限。
本文重点探讨了分布式深度学习框架内部的设计原则,在后续文章中,我们将讨论分布式深度学习框架面向上层开发者的接口应如何设计。
注:题图源自Pixabay
其他人都在看
点击“阅读原文”,欢迎下载体验OneFlow新一代开源深度学习框架


以上是关于对抗软件系统复杂性③:恰当分层,不多不少的主要内容,如果未能解决你的问题,请参考以下文章