Python 新手爬虫:网页爬虫取利器Requests
Posted 编程界的小胖子
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python 新手爬虫:网页爬虫取利器Requests相关的知识,希望对你有一定的参考价值。
今天,我们就来介绍一下目前最为流行,也是最为方面的网络爬虫框架之一的Requests 。
为什么要学习Requests
在回答这个问题之前,我们先介绍一下requests:
Requests 允许你发送纯天然,植物饲养的 HTTP/1.1 请求,无需手工劳动。你不需要手动为 URL 添加查询字串,也不需要对 POST 数据进行表单编码。Keep-alive 和 HTTP 连接池的功能是 100% 自动化的,一切动力都来自于根植在 Requests 内部的 urllib3。
这是节选自Requests官方文档的一段话,看上去像是在自卖自夸。事实上,Requests 的确极大地减少了我们的开发和配置工作。其GitHub主页上多达32K的star 也在宣告着它的成功与优秀基因。
为什么要学习Requests呢?对于初学者来说,主要原因是:
- Requests 在互联网上拥有丰富的学习资源。在百度上搜索“requests 爬虫”关键字,一共有16万多条搜索结果。这意味着Requests 的相关技术已经比较成熟。特别对于初学者而言,一个具有丰富学习材料的内容,能够减少学习中的“挖坑”次数和“掉坑”次数;
- Requests 官方提供中文文档。这一点对于新人,尤其是英语能力还不是很好的新人来说,是最好的资源。官网文档提供了详细而且非常准确的函数定义与说明。如果开发过程中出现了问题,百度、google、Stack Overflow......所有的搜索方法都试过,但是都不能解决问题的时候,翻阅官方文档是最稳妥,而且是最快捷的解决方案。
Requests初体验
-
安装Requests
因为Requests 是第三方库,因此我们需要手动安装。在CMD 控制台中输入
pip install requests
当控制台提示安装成功后,我们进入Python 中,导入Requests,验证是否安装成功。
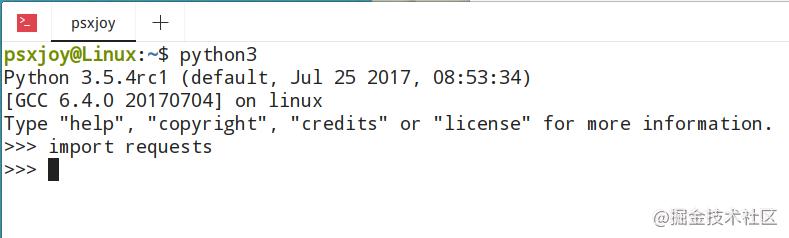
(请原谅我这里的图用的是Linux系统下的截图。当我写到这个部分的时候,我的windows电脑“悲剧”了)
-
重写
urllib的访问页面的代码使用Requests 爬取网页只需要几行代码,复杂程度远远小于
urllib。import requests url = "http://juejin.cn/" web_data = requests.get(url) web_info = web_data.text print(web_info) 复制代码让我们运行这个小程序,打印出运行结果:
...... <p>掘金社区.</p> ...... 复制代码Amazing!Requests自动帮我们检测编码,并且正常的显示了中文!
让我们详细的讲解一下这段代码
import requests url = "http://juejin.cn/" web_data = requests.get(url) 复制代码上述代码很好理解。第一行代码导入了Requests 这个库,第二行代码定义了我们要爬取的URL,第三行,我们直接调用Requests 中的
get()方法,即通过GET访问一个网页web_info = web_data.text 复制代码当我们发出GET请求后,Requests 会基于 HTTP 头部对相应的编码做出有根据的推测,所以当我们的访问web_data.text 之前,Requests 会使用它推测的文本编码进行解析。
-
定制请求头
什么是请求头呢?http请求头,HTTP客户程序(例如浏览器),向服务器发送请求的时候必须指明请求类型(一般是GET或者POST)。如有必要,客户程序还可以选择发送其他的请求头。
还记得我们上一篇文章中提到的“模拟浏览器”的行为吗?没错,浏览器的标志也在请求头中。

上图就是一个典型的请求头。在Request 中,我们可以很方便的构造自己需要的请求头
header = { 'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng, */*;q=0.8',
'Accept-Language':'zh-CN,zh;q=0.9',
'User-Agent':'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'
}
r = requests.get("http://gitbook.cn/", headers=headers)
复制代码-
Cookie的用处
平时上网时都是使用无状态的HTTP协议传输出数据,这意味着客户端与服务端在数据传送完成后就会中断连接。这时我们就需要一个一直保持会话连接的机制。在session出现前,cookie就完全充当了这种角色。也就是,cookie的小量信息能帮助我们跟踪会话。一般该信息记录用户身份。
什么是Cookie?简单的说,就是记录你用户名和密码,让你可以直接进入自己账户空间的一组数据。多说无益,我们来亲自实践一下。
这次我们尝试访问CSDN,首先这是我已经登录之后,显示的个人页面。!
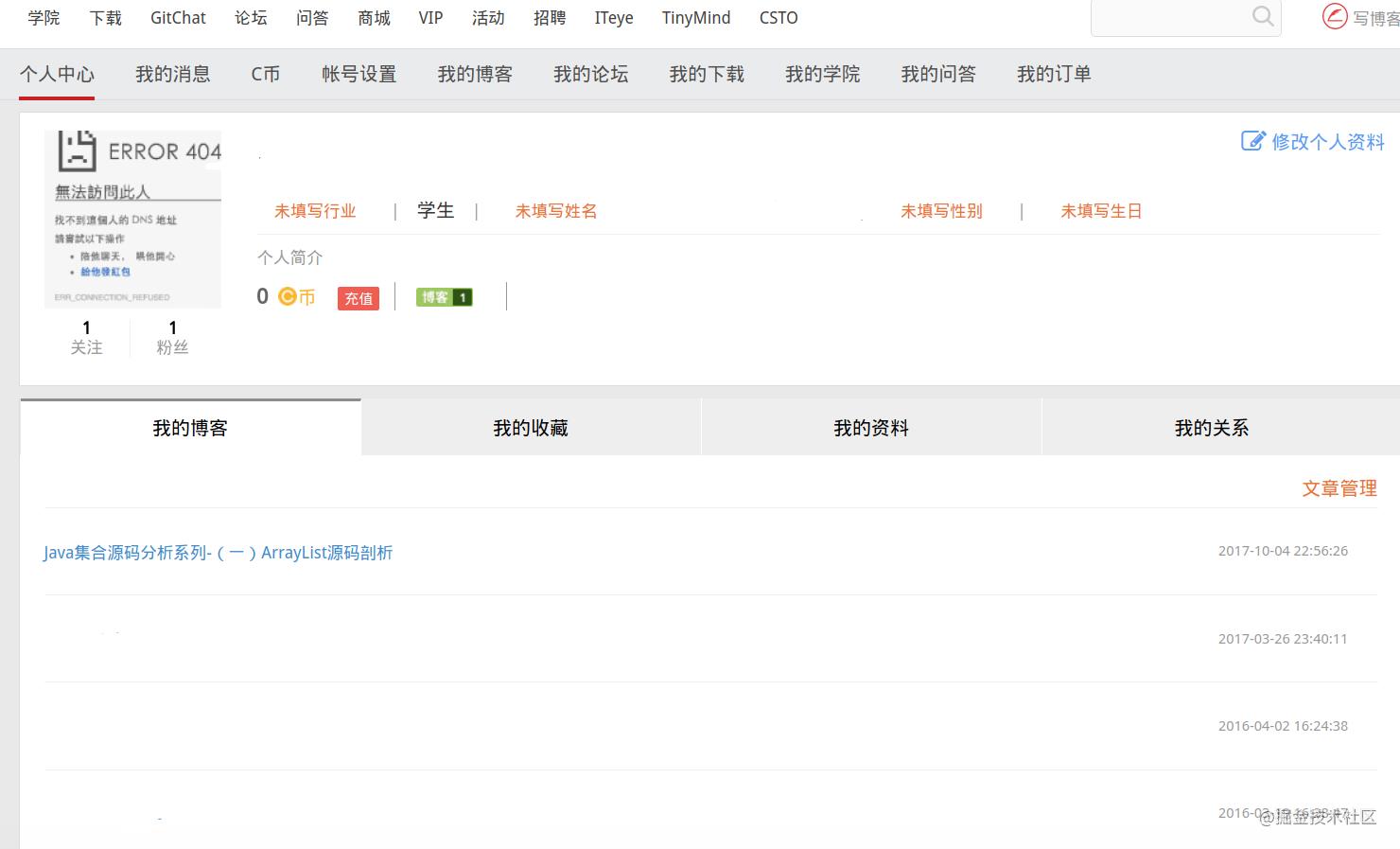
在没有加入Cookie之前,我们尝试访问一下这个页面。
import requests
url = "https://my.csdn.net/"
web_data = requests.get(url)
web_info = web_data.text
print(web_info)
复制代码运行结果为:
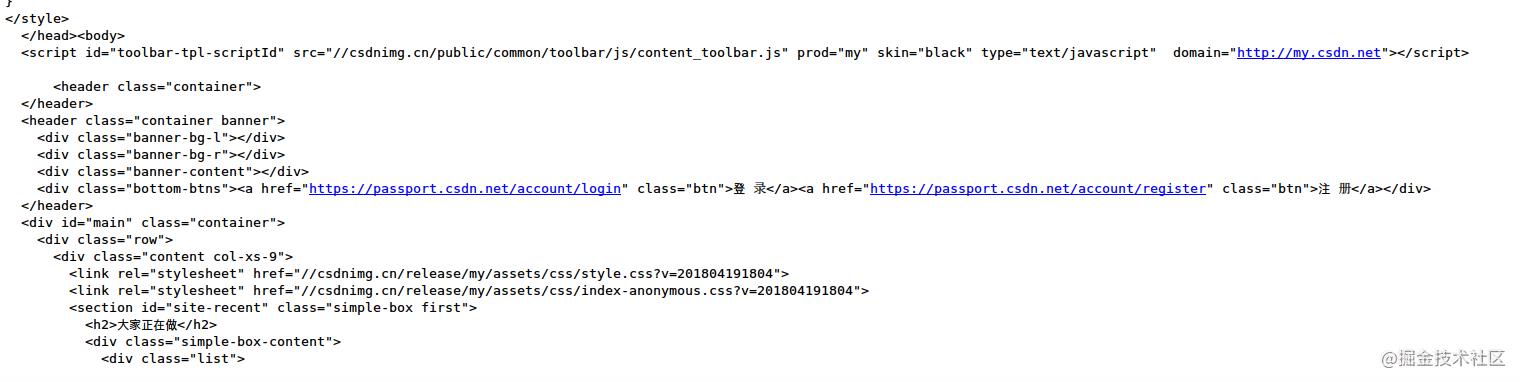
结果显示——你要么登录,要么注册。
那么,如果加入了COokie呢?我们首先获取自己的Cookie,如果你使用的是Chrome 浏览器,只需要右击-查看-network,然后刷新一下页面,就可以看到请求头中相对应的Cookie。
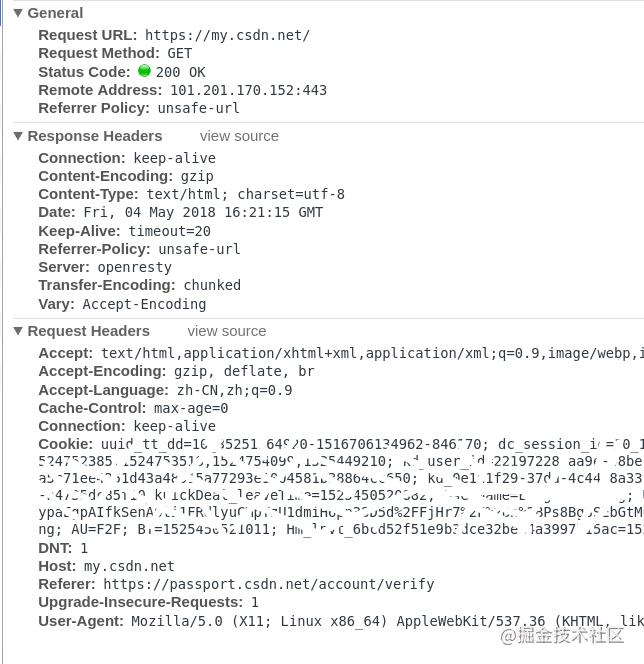
注意!Cookie 数据是十分隐私的个人数据!如果被他人获取到,采用一些常规手段,就可以登录你的相关账号,因此,请不要随意将自己的COokie 信息展示给他人!
让我们再重新修改一下代码
import requests
url = 'https://my.csdn.net/'
header = {
'Cookie':'此处隐藏个人Cookie',
'User-Agent' :'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'
}
web_data = requests.get(url,headers=header)
web_info = web_data.text
print(web_info)
复制代码运行一下,查看结果

我们看到,最终爬取的结果中,已经包含了登录时收藏的相关文章!Cookie设置成功!
新手可以尝试一下哦~
记得关注一下小胖子哦。不然找不到小胖子了哦~

以上是关于Python 新手爬虫:网页爬虫取利器Requests的主要内容,如果未能解决你的问题,请参考以下文章