mysql之innodb索引结构
Posted 鱼翔空
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了mysql之innodb索引结构相关的知识,希望对你有一定的参考价值。
前一篇,mysql之innodb存储结构我们了解了mysql的innodb的存储结构。这次我们再来了解innodb的索引结构;
在上一篇中我们说到record_type 有4种属性,其中1表示目录项记录,这次我们重点讲的就是这个。
存储结构
上一篇讲解的时候只是在强调InnoDB的数据页。在页之上有段,段之上有区,之前在讲undo log的时候也强调过这个概念。
借用一张图 
表空间(table space)
表空间(Tablespace)是一个逻辑容器,表空间存储的对象是段,在一个表空间中可以有一个或多个段,但是一个段只能属于一个表空间。数据库由一个或多个表空间组成,表空间从管理上可以划分为系统表空间、用户表空间、撤销表空间、临时表空间等。
在 InnoDB 中存在两种表空间的类型:共享表空间和独立表空间。如果是共享表空间就意味着多张表共用一个表空间。如果是独立表空间,就意味着每张表有一个独立的表空间,也就是数据和索引信息都会保存在自己的表空间中。独立的表空间可以在不同的数据库之间进行迁移。可通过命令
mysql > show variables like 'innodb_file_per_table';
查看当前系统启用的表空间类型。目前最新版本已经默认启用独立表空间。
InnoDB把数据保存在表空间内,表空间可以看作是InnoDB存储引擎逻辑结构的最高层。本质上是一个由一个或多个磁盘文件组成的虚拟文件系统。InnoDB用表空间并不只是存储表和索引,还保存了回滚段、双写缓冲区等。
段(segment)
段(Segment)由一个或多个区组成,区在文件系统是一个连续分配的空间(在 InnoDB中是连续的64 个页),不过在段中不要求区与区之间是相邻的。段是数据库中的分配单位,不同类型的数据库对象以不同的段形式存在。当我们创建数据表、索引的时候,就会相应创建对应的段,比如创建一张表时会创建一个表段,创建一个索引时会创建一个索引段。
区(extent)
在InnoDB存储引擎中,一个区会分配64个连续的页。因为 InnoDB 中的页大小默认是 16KB,所以一个区的大小是 64*16KB=1MB。在任何情况下每个区大小都为1MB,为了保证页的连续性,InnoDB存储引擎每次从磁盘一次申请4-5个区。默认情况下,InnoDB存储引擎的页大小为16KB,即一个区中有64个连续的页。
页(Page)
页是InnoDB存储引擎磁盘管理的最小单位,每个页默认16KB;InnoDB存储引擎从1.2.x版本开始,可以通过参数innodb_page_size将页的大小设置为4K、8K、16K。若设置完成,则所有表中页的大小都为innodb_page_size,不可以再次对其进行修改,除非通过mysqldump导入和导出操作来产生新的库
这块我们分析下为什么连续?
-
mysql的操作都是以页为单位;
-
连续的空间可以省掉磁盘磁头寻址的时间;
-
连续的空间也方便零拷贝操作;
-
cpu的高速缓存在查找时效率更高(连续的空间能查找的范围更大)
我们再根据连续索引结构来分析下:
-
假设我们主键为bigint,占用8字节的存储空间
-
我们根据存储结构讲的时候的一个公式 132+n(8+27)<16*1024 约460个索引
-
假设我们一个索引对应一个数据页
-
假设我们的索引一共2层,第一层就一个数据页 460*460一共有21万数据页
-
最坏情况下,我们一页存储100条数据,就接近2000万的数据了
-
那我们在检索的过程通过二分查找,一层最多8次,最多也就16次定位到了对应的数据页,再通过有序链表查,最多116次就能定位到数据;
-
我们在看下索引的大小 16k(460+1)= 7mb多点
-
如果这些都在内存中,查询效率可想而知
在之前分享过一篇 记一次生产慢sql查询的解决我们把对应的图拿过来。 
-
聚簇索引直接使用的主键
-
可以通过主键直接定位到数据
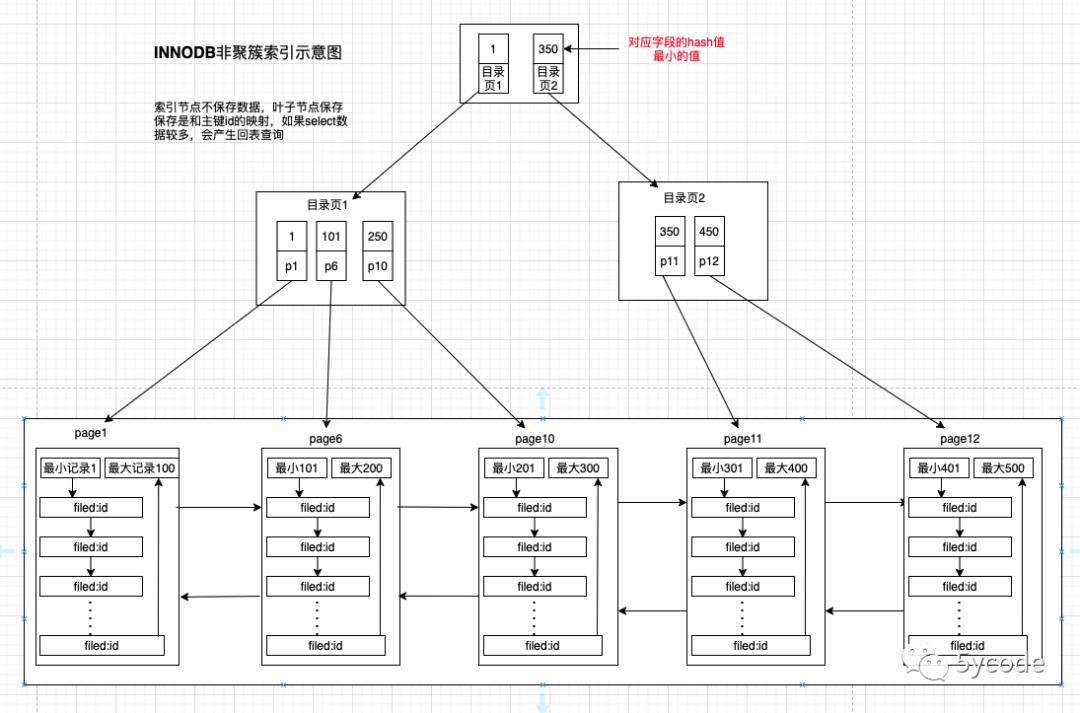
-
非聚簇索引使用的非主键作为索引
-
通过索引值和主键的映射最终找到数据
-
通过主键再去聚簇索引中定位数据,叫回表
大家思考下:
我们怎么去建索引更高效?
为什么字段类型不匹配的时候索引失效?
为什么不建议在查询时使用mysql的函数去过滤列?
部分参考
https://blog.haohtml.com/archives/19232
如果觉得对你有帮助,请关注公众号:5ycode,后续会不断更新哦

以上是关于mysql之innodb索引结构的主要内容,如果未能解决你的问题,请参考以下文章