[Python从零到壹] 十六.文本挖掘之词云热点与LDA主题分布分析万字详解
Posted Eastmount
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[Python从零到壹] 十六.文本挖掘之词云热点与LDA主题分布分析万字详解相关的知识,希望对你有一定的参考价值。
欢迎大家来到“Python从零到壹”,在这里我将分享约200篇Python系列文章,带大家一起去学习和玩耍,看看Python这个有趣的世界。所有文章都将结合案例、代码和作者的经验讲解,真心想把自己近十年的编程经验分享给大家,希望对您有所帮助,文章中不足之处也请海涵。Python系列整体框架包括基础语法10篇、网络爬虫30篇、可视化分析10篇、机器学习20篇、大数据分析20篇、图像识别30篇、人工智能40篇、Python安全20篇、其他技巧10篇。您的关注、点赞和转发就是对秀璋最大的支持,知识无价人有情,希望我们都能在人生路上开心快乐、共同成长。
前一篇文章讲述了数据预处理、Jieba分词和文本聚类知识,这篇文章可以说是文本挖掘和自然语言处理的入门文章。本文将详细讲解文本挖掘领域的词云热点分析和LDA主题分布分析。两万字基础文章,希望对您有所帮助。
近年来,词云热点技术和文档主题分布分析被更广泛地应用于数据分析中,通过词云热点技术形成类似云的彩色图片来聚集关键词,从视觉上呈现文档的热点关键词;通过文档主题分布识别文档库或知识语料中潜藏的主题信息,计算作者感兴趣的文档主题和每篇文档所涵盖的主题比例。本文主要介绍WordCloud技术的词云热点分布和LDA模型的主题分布,并结合真实的数据集进行讲解。
文章目录
下载地址:
前文赏析:
第一部分 基础语法
- [Python从零到壹] 一.为什么我们要学Python及基础语法详解
- [Python从零到壹] 二.语法基础之条件语句、循环语句和函数
- [Python从零到壹] 三.语法基础之文件操作、CSV文件读写及面向对象
第二部分 网络爬虫
- [Python从零到壹] 四.网络爬虫之入门基础及正则表达式抓取博客案例
- [Python从零到壹] 五.网络爬虫之BeautifulSoup基础语法万字详解
- [Python从零到壹] 六.网络爬虫之BeautifulSoup爬取豆瓣TOP250电影详解
- [Python从零到壹] 七.网络爬虫之Requests爬取豆瓣电影TOP250及CSV存储
- [Python从零到壹] 八.数据库之MySQL基础知识及操作万字详解
- [Python从零到壹] 九.网络爬虫之Selenium基础技术万字详解(定位元素、常用方法、键盘鼠标操作)
- [Python从零到壹] 十.网络爬虫之Selenium爬取在线百科知识万字详解(NLP语料构造必备技能)
第三部分 数据分析和机器学习
- [Python从零到壹] 十一.数据分析之Numpy、Pandas、Matplotlib和Sklearn入门知识万字详解(1)
- [Python从零到壹] 十二.机器学习之回归分析万字总结全网首发(线性回归、多项式回归、逻辑回归)
- [Python从零到壹] 十三.机器学习之聚类分析万字总结全网首发(K-Means、BIRCH、层次聚类、树状聚类)
- [Python从零到壹] 十四.机器学习之分类算法三万字总结全网首发(决策树、KNN、SVM、分类算法对比)
- [Python从零到壹] 十五.文本挖掘之数据预处理、Jieba工具和文本聚类万字详解
- [Python从零到壹] 十六.文本挖掘之词云热点与LDA主题分布分析万字详解
作者新开的“娜璋AI安全之家”将专注于Python和安全技术,主要分享Web渗透、系统安全、人工智能、大数据分析、图像识别、恶意代码检测、CVE复现、威胁情报分析等文章。虽然作者是一名技术小白,但会保证每一篇文章都会很用心地撰写,希望这些基础性文章对你有所帮助,在Python和安全路上与大家一起进步。
一.词云技术
首先,读者可能会疑问什么是词云呢?词云又叫文字云,是对文本数据中出现频率较高的关键词在视觉上的突出呈现,出现频率越高的词显示得越大或越鲜艳,从而将关键词渲染成类似云一样的彩色图片,感知文本数据的主要主题及核心思想。
1.词云
“词云”就是对网络文本中出现频率较高的关键词,予以视觉上的突出,使浏览网页者只要一眼扫过文本就可以领略文本的主旨,主要利用文本挖掘和可视化技术。个性化词云既是研究分析内容的一种表现方式,又是广告传媒的一种“艺术品”。在Python中,通过安装WordCloud词云扩展包可以形成快速便捷的词云图片。词云可以使关键词可视化展现,更加直观、艺术。

图1是关于文学文章的词云分析结果。首先对一些文章进行词频统计,然后绘制对应的图形,其中“文学”、“小说”、“中国”、“历史”等字体显示较大,表示这类文章的出现频率较高;而“金融”、“绘画”、“悬疑”字体较小,表示它们出现的频率较小。图2是对某些编程技术文章的词云分析结果图,从图中词云分析可以看出这些技术文章的热点话题有图形学、算法、计算机、编译器等,热点技术有android、Python、ReactOS、SQL等,同时该图呈现了一定的形状。

前面讲述了词云的效果图,由于其炫酷的效果,很多广告公司、传媒海报都利用该技术进行宣传。下面将讲解Python调用WordCloud库进行词云分析,图3是词云分析的算法流程,包括读取文件、中文分词、词云库导入、词云热点分析和可视化分析。
2.安装WordCloud
安装WordCloud词云扩展包主要利用前文常见的pip工具包,同时Python处理中文语料需要调用Jieba结巴分词库进行中文分词处理,则需要安装Jieba扩展包。
pip install WordCloud
pip install jieba
安装过程如图所示。
注意:在安装WordCloud过程中,你可能遇到的一个错误“error: Microsoft Visual C++ 9.0 is required. Get it from http://asa.ms/vcpython27”,这时需要下载VCForPython27可执行文件并进行安装,在微软官网有相关软件(Microsoft Visual C++ Compiler for Python 2.7)供下载。
在Python开发过程中,可能会遇到各种各样的问题,希望读者都能养成通过谷歌或百度等搜索引擎独立解决的习惯,这是非常宝贵的一种能力,并且将终生受益。
二.WordCloud基本用法
1.快速入门
当WordCloud词云扩展包和Jieba分词工具安装完成以后,下面开始快速入门。假设存在下面test.txt的中文语料,这是前一篇文章讲解数据预处理的自定义语料,内容如下:
贵州省 位于 中国 西南地区 简称 黔 贵
走遍 神州大地 醉美 多彩 贵州
贵阳市 贵州省 省会 林城 美誉
数据分析 数学 计算机科学 相结合 产物
回归 聚类 分类 算法 广泛应用 数据分析
数据 爬取 数据 存储 数据分析 紧密 相关 过程
甜美 爱情 苦涩 爱情
一只 鸡蛋 可以 画 无数次 一场 爱情 能
真 爱 往往 珍藏 平凡 普通 生活
接下来执行文件,它将调用WordCloud扩展包绘制test.txt中文语料对应的词云,完整代码如下所示:
# -*- coding: utf-8 -*-
#coding=utf-8
#By:Eastmount CSDN
import jieba
import sys
import matplotlib.pyplot as plt
from wordcloud import WordCloud
text = open('test.txt').read()
print(type(text))
wordlist = jieba.cut(text, cut_all = True)
wl_space_split = " ".join(wordlist)
print(wl_space_split)
my_wordcloud = WordCloud().generate(wl_space_split)
plt.imshow(my_wordcloud)
plt.axis("off")
plt.show()
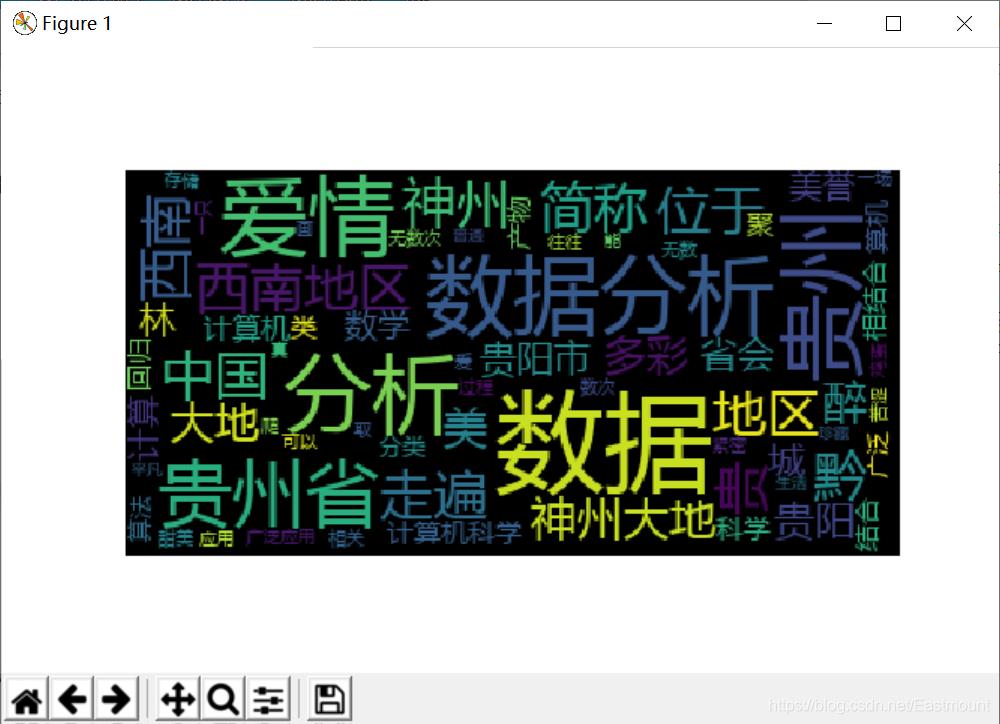
输出结果如图所示,其中出现比较频繁的贵州省、数据、爱情显示较大。
代码详解如下:
(1) 导入Python扩展包
首先需要调用import和from import导入相关的函数包,Python的词云分析主要调用WordCloud包进行,调用jieba扩展包进行分词,调用matplotlib扩展包绘制图形。
import jieba
import sys
import matplotlib.pyplot as plt
from wordcloud import WordCloud
(2) 调用jieba工具分词处理
接下来调用open()函数读取爬取的语料“test.txt”文件,再调用jieba扩展包进行分词处理。核心代码如下:
text = open('test.txt').read()
wordlist = jieba.cut(text, cut_all = True)
wl_space_split = " ".join(wordlist)
print(wl_space_split)
其中,结巴分词调用函数jieba.cut(text, cut_all = True),参数“cut_all=True”表示设置为全模型。结巴中文分词支持的三种分词模式包括:
- 精确模式:该模式将句子最精确地切开,适合做文本分析。
- 全模式:将句子中所有可以成词的词语都扫描出来, 速度非常快,缺点是不能解决歧义问题。
- 搜索引擎模式:在精确模式基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。
代码示例如下:
#coding=utf-8
#By:Eastmount CSDN
import jieba
#全模式
text = "我来到北京清华大学"
seg_list = jieba.cut(text, cut_all=True)
print("[全模式]: ", "/ ".join(seg_list))
#[全模式]: 我 / 来到 / 北京 / 清华 / 清华大学 / 华大 /大学
#精确模式
seg_list = jieba.cut(text, cut_all=False)
print("[精确模式]: ", "/ ".join(seg_list))
#[精确模式]: 我 / 来到 / 北京 / 清华大学
#默认是精确模式
seg_list = jieba.cut(text)
print("[默认模式]: ", "/ ".join(seg_list))
#[默认模式]: 我 / 来到 / 北京 / 清华大学
#搜索引擎模式
seg_list = jieba.cut_for_search(text)
print("[搜索引擎模式]: ", "/ ".join(seg_list))
#[搜索引擎模式]: 我 / 来到 / 北京 / 清华 / 华大 / 大学 / 清华大学
代码wl_space_split = " ".join(wordlist)表示将中文分词的词序列按照空格连接,并生成分词后的字符串,赋值给wl_space_split变量。
(3) 调用WordCloud函数生成词云热点词频
调用WordCloud()函数生成词云,其中该函数核心参数包括设置背景颜色、设置背景图片、最大实现词数、字体最大值、颜色种类数。借用Python强大的第三方扩展包对该语料进行词云分析,其中核心代码如下:
# 读取mask/color图片
d = path.dirname(__file__)
nana_coloring = imread(path.join(d, "1.jpg"))
# 对分词后的文本生成词云
my_wordcloud = WordCloud( background_color = 'white', #背景颜色
mask = nana_coloring, #设置背景图片
max_words = 2000, #设置最大现实的字数
stopwords = STOPWORDS, #设置停用词
max_font_size = 200, #设置字体最大值
random_state = 30, #设置有多少种随机生成状态,即有多少种配色方案
)
# generate word cloud
my_wordcloud.generate(wl_space_split)
上述示例代码主要使用WordCloud()函数,并省略了参数。
- my_wordcloud = WordCloud().generate(wl_space_split)
(4) 调用imshow扩展包进行可视化分析
接下来调用plt.imshow(my_wordcloud)代码显示语料的词云,词频变量为my_wordcloud;调用plt.axis(“off”)代码是否显示x轴、y轴下标,最后通过plt.show()代码展示词云。
plt.imshow(my_wordcloud)
plt.axis("off")
plt.show()
总之,词云分析可以广泛的应用于词频分析,可以直观的给出文章的主题词等内容,接下来讲解的CSDN技术论坛分析实例很好地利用了该技术。
2.中文编码问题
如果语料是中文,在词云分析中可能出现中文乱码的情况,如图所示,在绘制的词云中,其中文关键词均错误的显示为方框,而英文字母组成的关键词能够显示。
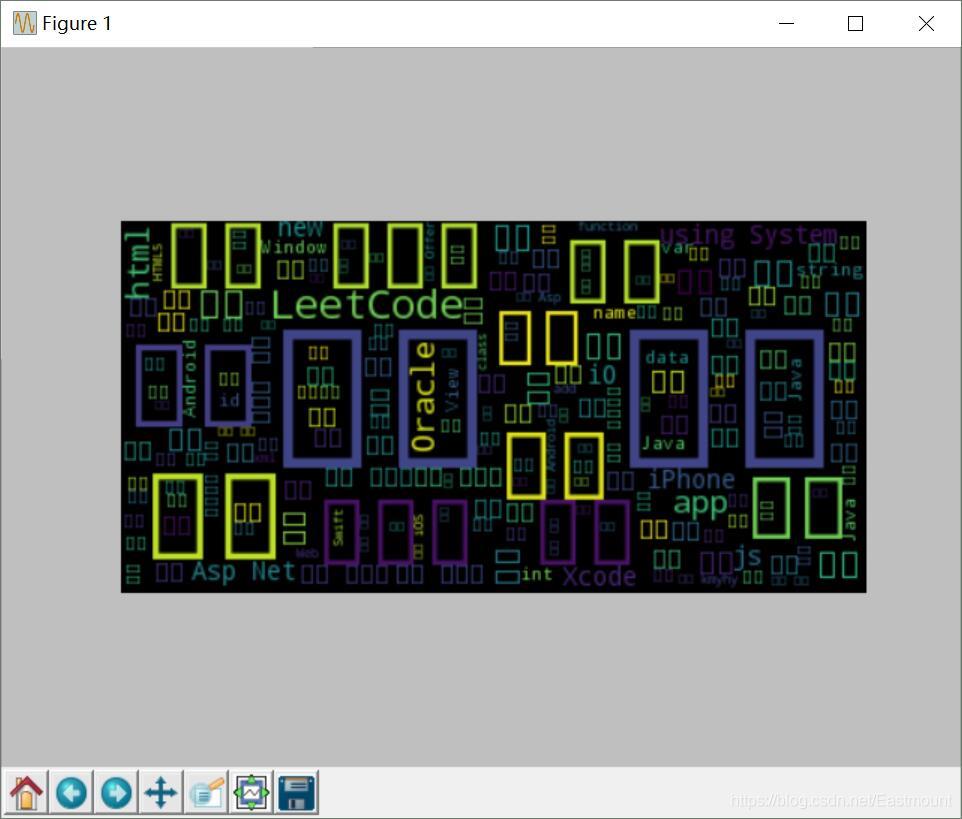
其解决方法是在WordCloud安装的目录下找到wordcloud.py文件,对该文件中的源码进行修改,下图为wordcloud.py源文件。
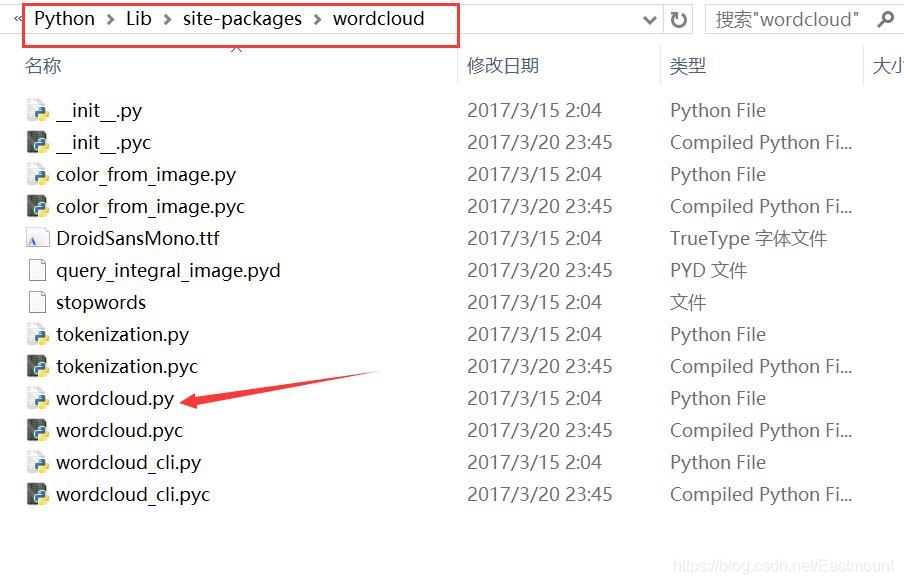
编辑wordcloud.py,找到FONT_PATH,将DroidSansMono.ttf修改成msyh.ttf。这个msyh.ttf表示微软雅黑中文字体。

注意,此时运行代码还是报错,因为需要在同一个目录下放置msyh.ttf字体文件供程序调用,如图所示,这是原来的字体DroidSansMono.ttf文件。
此时的运行结果如下所示,这是分析CSDN多篇博客所得到的词云,其中“阅读”和“评论”出现的比较多,因为每篇文章都有对应的阅读数和评论数,所以该关键字显示较为突出。下图通过词云图形清晰地显示了热点词汇。

同时,也可以通过另一种方法解决中文乱码的错误,在py文件中增加一行代码。
- wordcloud = WordCloud(font_path = ‘MSYH.TTF’).fit_words(word)
3.词云形状化
前面我们看到的词云图形都是有形状的,比如下面关于R语言描述语料形成的词云,整个形状也是呈“R”的,同时“统计”、“数据分析”、“大数据”是相关词汇。

那么,怎么形式这种词云呢?
调用Python扩展包scipy.misc的imread()函数可以绘制指定图形的词云,下图是分析作者和女朋友近期微信聊天记录的词云图,完整代码如下所示:
#coding=utf-8
#By:Eastmount CSDN
from os import path
from scipy.misc import imread
import jieba
import sys
import matplotlib.pyplot as plt
from wordcloud import WordCloud, STOPWORDS, ImageColorGenerator
# 打开本体TXT文件
text = open('data-fenci.txt').read()
# 结巴分词 cut_all=True 设置为全模式
wordlist = jieba.cut(text) #cut_all = True
# 使用空格连接 进行中文分词
wl_space_split = " ".join(wordlist)
print(wl_space_split)
# 读取mask/color图片
d = path.dirname(__file__)
nana_coloring = imread(path.join(d, "pic.png"))
# 对分词后的文本生成词云
my_wordcloud = WordCloud( background_color = 'white',
mask = nana_coloring,
max_words = 2000,
stopwords = STOPWORDS,
max_font_size = 50,
random_state = 30,
)
# generate word cloud
my_wordcloud.generate(wl_space_split)
# create coloring from image
image_colors = ImageColorGenerator(nana_coloring)
# recolor wordcloud and show
my_wordcloud.recolor(color_func=image_colors)
plt.imshow(my_wordcloud) # 显示词云图
plt.axis("off") # 是否显示x轴、y轴下标
plt.show()
# save img
my_wordcloud.to_file(path.join(d, "cloudimg.png"))
输出的词云如图所示,右边的词云图是根据左边的图形形状生成的,其中“宝宝”、“我们”、“哈哈哈”等关键词比较突出。

同样可以输出作者近十年的博客词云图。

三.文档主题模型
文档主题生成模型(Latent Dirichlet Allocation,简称LDA)通常由包含词、主题和文档三层结构组成。LDA模型属于无监督学习技术,它是将一篇文档的每个词都以一定概率分布在某个主题上,并从这个主题中选择某个词语。文档到主题的过程是服从多项分布的,主题到词的过程也是服从多项分布的。本小节将介绍LDA主题模型、安装过程、基本用法,并通过一个实例来讲解文档主题分布。
1.LDA主题模型
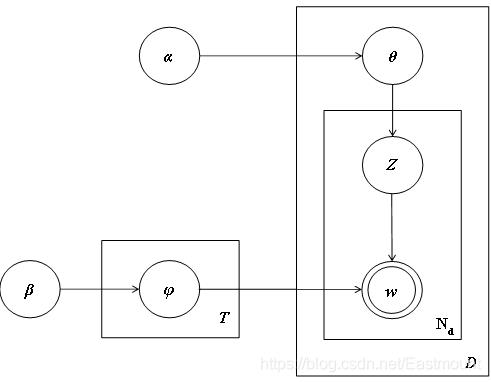
文档主题生成模型(Latent Dirichlet Allocation,简称LDA)又称为盘子表示法(Plate Notation),图22.14是模型的标示图,其中双圆圈表示可测变量,单圆圈表示潜在变量,箭头表示两个变量之间的依赖关系,矩形框表示重复抽样,对应的重复次数在矩形框的右下角显示。LDA模型的具体实现步骤如下:
- 从每篇网页D对应的多项分布θ中抽取每个单词对应的一个主题z。
- 从主题z对应的多项分布φ中抽取一个单词w。
重复步骤(1)(2),共计Nd次,直至遍历网页中每一个单词。
\\
现在假设存在一个数据集DS,数据集中每篇语料记为D,整个数据集共T个主题,数据集的特征词表称为词汇表,所包含的单词总数记为V。LDA模型对其描述的内容是:数据集DS中每个实篇语料D都与这T个主题的多项分布相对应,记为多项分布θ;每个主题都与词汇表中V个单词的多项分布相对应,记为多项分布φ。其中θ和φ分别存在一个带超参数的α和β的狄利克雷先验分布,后面将结合具体实例深入讲解。
2.LDA安装过程
读者可以从gensim中下载ldamodel扩展包安装,也可以使用Sklearn机器学习包的LDA子扩展包,亦可从github中下载开源的LDA工具。下载地址如下所示。
- gensim:https://radimrehurek.com/gensim/models/ldamodel.html
- scikit-learn:利用pip install sklearn命令安装扩展包,LatentDirichletAllocation函数即为LDA原型
- github:https://github.com/ariddell/lda
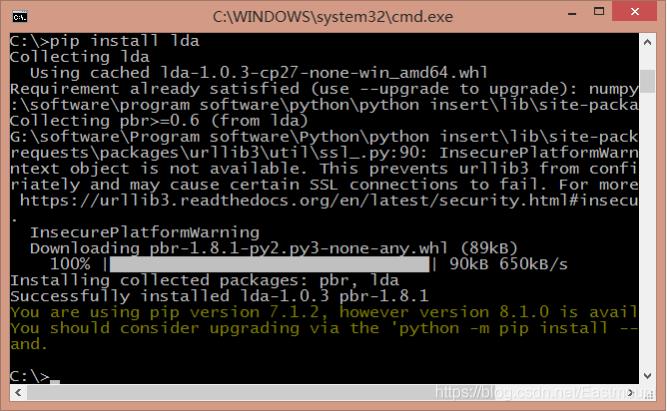
作者最后使用的是通过“pip install lda”安装的官方LDA模型。
- pip install lda
在命令框CMD中输入该命令令安装LDA模型,安装过程如下图所示,安装成功显示“Successfully installed lda-1.0.3 pbr-1.8.1”。
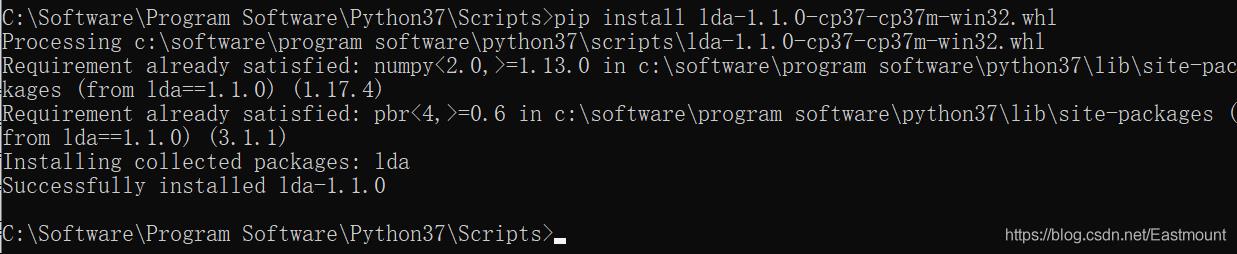
作者更推荐大家使用“pip install lda”语句安装的官方LDA扩展包,该方法简洁方便,更值得大家学习和使用。
四.LDA基本用法及实例
Python的LDA主题模型分布可以进行多种操作,常见的包括:输出每个数据集的高频词TOP-N;输出文章中每个词对应的权重及文章所属的主题;输出文章与主题的分布概率,文本一行表示一篇文章,概率表示文章属于该类主题的概率;输出特征词与主题的分布概率,这是一个K*M的矩阵,K为设置分类的个数,M为所有文章词的总数。下面让我们结合实例开始学习LDA模型的用法吧!
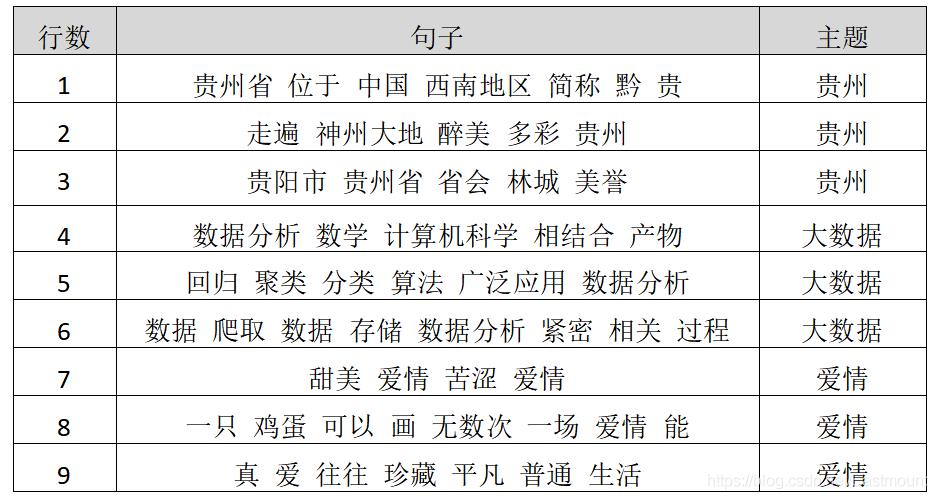
这里使用的数据集为上一篇文章讲解数据预处理,对其进行数据分词、清洗、过滤后的数据集,如表所示,共9行语料,涉及贵州、大数据、爱情三个主题。
1.初始化操作
(1) 生成词频矩阵
首先,需要读取语料test.txt,载入数据并将文本中的词语转换为词频矩阵。调用 sklearn.feature_extraction.text 中的 CountVectorizer 类实现,代码如下:
#coding=utf-8
#By:Eastmount CSDN
# coding:utf-8
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfTransformer
#读取语料
corpus = []
for line in open('test.txt', 'r').readlines():
corpus.append(line.strip())
#将文本中的词语转换为词频矩阵
vectorizer = CountVectorizer()
#计算个词语出现的次数
X = vectorizer.fit_transform(corpus)
#获取词袋中所有文本关键词
word = vectorizer.get_feature_names()
print('特征个数:', len(word))
for n in range(len(word)):
print(word[n],end=" ")
print('')
#查看词频结果
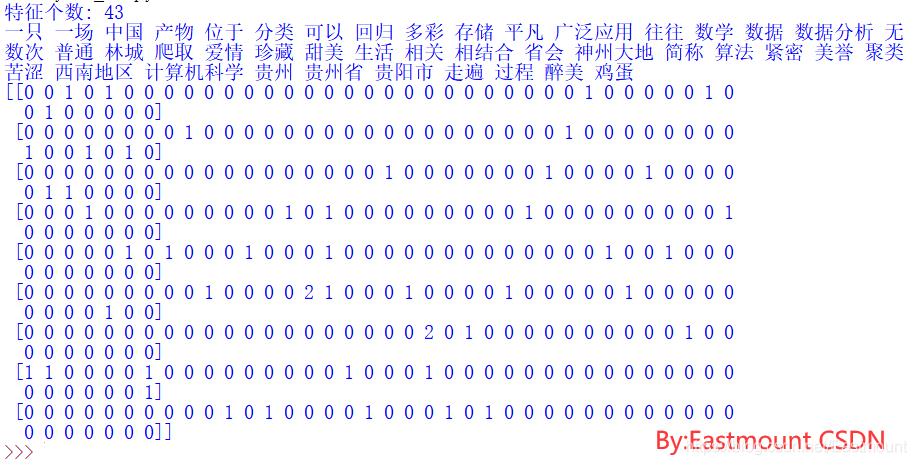
print(X.toarray())
其中输出的X为词频矩阵,共9行数据,43个特征或单词,即9*43,它主要用于计算每行文档单词出现的词频或次数。输出如下图所示,其中第0行矩阵表示第一行语料“贵州省 位于 中国 西南地区 简称 黔 贵”出现的频率。同时调用 vectorizer.get_feature_names() 函数计算所有的特征或单词。
(2) 计算TF-IDF值
接下来调用TfidfTransformer类计算词频矩阵对应的TF-IDF值,它是一种用于数据分析的经典权重,其值能过滤出现频率高且不影响文章主题的词语,尽可能的用文档主题词汇表示这篇文档的主题。
#coding=utf-8
#By:Eastmount CSDN
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfTransformer
#读取语料
corpus = []
for line in open('test.txt', 'r').readlines():
corpus.append(line.strip())
#将文本中的词语转换为词频矩阵
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(corpus) #计算个词语出现的次数
word = vectorizer.get_feature_names() #获取词袋中所有文本关键词
print('特征个数:', len(word))
for n in range(len(word)):
print(word[n],end=" ")
print('')
print(X.toarray()) #查看词频结果
#计算TF-IDF值
transformer = TfidfTransformer()
print(transformer)
tfidf = transformer.fit_transform(X) #将词频矩阵X统计成TF-IDF值
#查看数据结构 输出tf-idf权重
print(tfidf.toarray())
weight = tfidf.toarray()
输出如图所示,它也是9*43的矩阵,只是矩阵中的值已经计算为TF-IDF值了。

(3) 调用LDA模型
得到TF-IDF值之后,可以进行各种算法的数据分析了,这里则调用lda.LDA()函数训练LDA主题模型,其中参数n_topics表示设置3个主题(贵州、数据分析、爱情),n_iter表示设置迭代次数500次,并调用fit(X)或fit_transform(X)函数填充训练数据,具体代码如下:
model = lda.LDA(n_topics=3, n_iter=500, random_state=1)
model.fit(X)
#model.fit_transform(X)
运行过程如图所示。

读者也可以import lda.datasets导入官方数据集,然后调用lda.datasets.load_reuters()函数载入数据集进行分析,这里作者则直接对下表实例数据集进行LDA分析。
2.计算文档主题分布
该语料共包括9行文本,每一行文本对应一个主题,其中1-3为贵州主题,4-6为数据分析主题,7-9为爱情主题,现在使用LDA文档主题模型预测各个文档的主体分布情况,即计算文档-主题(Document-Topic)分布,输出9篇文章最可能的主题代码如下。
#coding=utf-8
#By:Eastmount CSDN
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfTransformer
import lda
import numpy as np
#生成词频矩阵
corpus = []
for line in open('test.txt', 'r').readlines():
corpus.append(line.strip())
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(corpus)
word = vectorizer.get_feature_names()
#LDA分布
model = lda.LDA(n_topics=3, n_iter=500, random_state=1)
model.fit(X)
#文档-主题(Document-Topic)分布
doc_topic = model.doc_topic_
print("shape: {}".format(doc_topic.shape))
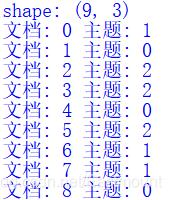
for n in range(9):
topic_most_pr = doc_topic[n].argmax()
print(u"文档: {} 主题: {}".format(n,topic_most_pr))
输出结果如图所示,可以看到LDA算法将第1、7、8篇文档归纳为一个主题,第2、5、9篇文档归纳为一个主题,第3、4、6篇文档归纳为一个主题。而真实的主题是第1-3篇文档为贵州主题,第4-6篇文档为数据分析主题,第7-9篇文档为爱情主题,所以数据分析预测的结果会存在一定的误差,这是由于每篇文档的单词较少,影响了实验结果。
同时,在进行数据分析时,通常需要采用准确率、召回率或F特征值来评估一个算法的好坏,研究者也会不断的优化模型或替换为更好的算法。
3.主题关键词的Top-N
下面讲解计算各个主题下包括哪些常见的单词,即计算主题-词语(Topic-Word)分布。下面代码用于计各主题5的词频最高的五个单词,即Top-5,比如爱情主题下最常见的五个单词是“爱情 鸡蛋 苦涩 一场 中国”。
代码如下所示,首先分别计算各个主题下的关键词语。
#主题-单词(Topic-Word)分布
word = vectorizer.get_feature_names()
topic_word = model.topic_word_
for w in word:
print(w,end=" ")
print('')
n = 5
for i, topic_dist in enumerate(topic_word):
topic_words = np.array(word)[np.argsort(topic_dist)][:-(n+1):-1]
print(u'*Topic {}\\n- {}'.format(i, ' '.join(topic_words)))
在上述代码中,vectorizer.get_feature_names()函数用于列举出各个特征或词语, model.topic_word_函数是存储各个主题单词的权重。首先输出所有的单词,再输出三个主题中包含的前5个单词,输出如下:
一只 一场 中国 产物 位于 分类 可以 回归 多彩 存储 平凡 广泛应用 往往 数学 数据 数据分析 无数次 普通 林城 爬取 爱情 珍藏 甜美 生活 相关 相结合 省会 神州大地 简称 算法 紧密 美誉 聚类 苦涩 西南地区 计算机科学 贵州 贵州省 贵阳市 走遍 过程 醉美 鸡蛋
*Topic 0
- 珍藏 多彩 林城 醉美 生活
*Topic 1
- 爱情 鸡蛋 苦涩 一场 中国
*Topic 2
- 数据分析 数据 聚类 数学 爬取
接着通过通过代码计算各个主题通过LDA主题模型分析之后的权重分布,代码如下:
#主题-单词(Topic-Word)分布
print("shape: {}".format(topic_word.shape))
print(topic_word[:, :3])
for n in range(3):
sum_pr = sum(topic_word[n,:])
print("topic: {} sum: {}".format(n, sum_pr))
首先计算topic_word矩阵的形状,即shape: (3L, 43L),它表示3个主题、43个特在词。topic_word[:, :3]输出三个主题的前三个词语对应的权重,最后计算每行语料所有特征词的权重和,求和值均为1。
shape: (3L, 43L)
[[ 0.00060864 0.00060864 0.00060864]
[ 0.06999307 0.06999307 0.06999307]
[ 0.00051467 0.00051467 0.00051467]]
topic: 0 sum以上是关于[Python从零到壹] 十六.文本挖掘之词云热点与LDA主题分布分析万字详解的主要内容,如果未能解决你的问题,请参考以下文章
[Python从零到壹] 四十六.图像增强及运算篇之图像阈值化处理
[Python从零到壹] 三十六.图像处理基础篇之图像算术与逻辑运算详解