一个算法“拿下”两个榜单!爱奇艺ICCV 2021论文提出人手三维重建新方法
Posted AI科技大本营
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一个算法“拿下”两个榜单!爱奇艺ICCV 2021论文提出人手三维重建新方法相关的知识,希望对你有一定的参考价值。


作者:不用手柄也能玩VR
来源:爱奇艺技术产品团队
2016年,Facebook正式发售Oculus Rift头戴式VR设备,大大革新了人们对于VR技术的认知,这一年也因此被称为VR元年。5年过去,现在VR技术发展到哪了?从原生VR游戏《半条命:爱莉克斯》来看,在这类游戏场景下,人们与虚拟世界的交互已经非常成熟。

《半条命:爱莉克斯》
但庞大的头显设备,仍是阻碍VR应用普及的重要原因。还以《半条命:爱莉克斯》为例,这部游戏的精华是在于手部交互,而实现捡东西、扔东西、扣动扳机等等复杂的虚拟交互,则需要一部VR头盔和一部VR手柄才能完成。
近日,计算机视觉领域国际顶会 ICCV 2021 收录了一篇题为“I2UV-HandNet: Image-to-UV Prediction Network for Accurate and High-fidelity 3D Hand Mesh Modeling”论文,论文由爱奇艺深度学习云算法团队联合慕尼黑工业大学学者完成,他们在论文中提出一套名为I2UV-HandNet高精度手部重建系统,通过“看”单目RGB人手图片,就能实现高精度三维重建。

论文地址:
https://arxiv.org/abs/2102.03725
言外之意,如果将这项技术“适配”到带有摄像功能的眼镜或者头盔中,那么使用者即使不用手柄,也能实现与虚拟世界的高质量对话。
重建效果如何?该论文在已经在颇受认可的HO3D在线测评榜上,力压群雄,持续数月排名第一。在Freihand 在线测评榜上,截至论文编写时仍排名第一。
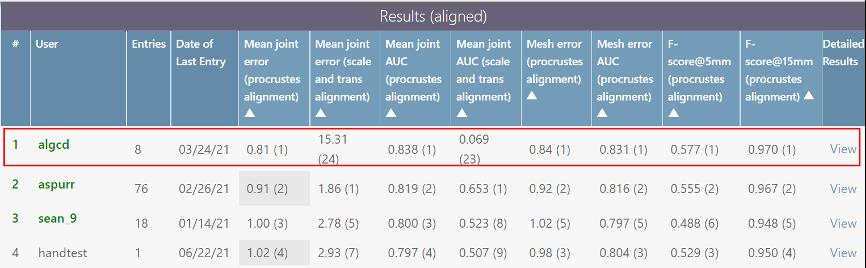
HO3D 榜单排行结果,红框处为爱奇艺
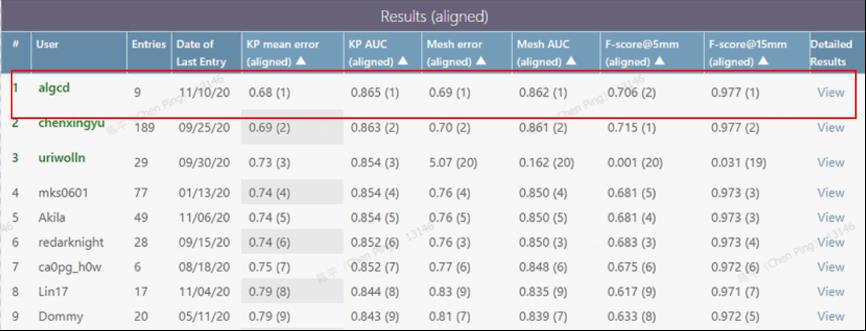
论文编写时Freihand榜单排行结果,红框处为爱奇艺
目前,研究员们正在尝试将该技术应用到爱奇艺下一代VR设备中,从而减少对手柄依赖,打造出更轻、更快、更舒适的VR设备。同时手势重建、交互技术目前也同步在爱奇艺其他业务场景和硬件终端进行落地探索,相信不久后会相继和用户见面

划
重
点


I2UV-HandNet:业界首创的手部三维重建技术
在人机交互和虚拟现实的应用中,高精度的人手三维重建技术发挥着重要作用。但由于手势多变以及严重的遮挡,现有的重建方法在准确性和精度方面仍差些火候。
一方面,目前学术界在进行手部三维重建评测,如在Freihand数据集上进行评测主要是突出算法的精度优势,不需要考虑算力、延迟等,所以可以采用计算复杂度非常高(如transformer等)的一些算法。
另一方面在工业界,特别是VR等移动端设备,在算力、功耗、电池的续航及发热等各方面有严格限制,在应用上必须采用计算复杂度偏低的算法。
而VR等设备的摄像头因为移动端硬件的功耗、续航限制必须降低清晰度而不是采用高清晰度的摄像头,采集到的图像清晰度相对偏低,这对于算法的识别就存在一定挑战性。
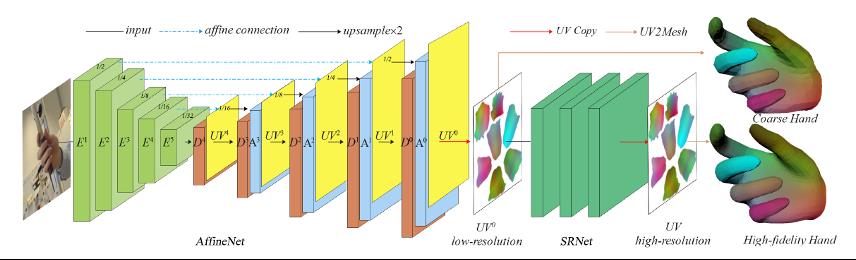
I2UV-HandNet框架图,由AffineNet和SRNet组成
爱奇艺这篇论文中提出的I2UV-HandNet,独创性地将UV映射表征引入到三维手势和形状估计中,其设计的UV重建模块AffineNet能够从单目图像中预测手部网络(hand mesh),从而完成由粗到精的人手3D模型重建。
这一设计意味着对于三维重建中所需的空间中的景深信息,不用再通过昂贵的硬件完成侦测,在普通RGB摄像头拍摄的图片中就可以完成景深信息获取。
I2UV-HandNet另一个组成部分是SRNet网络,其作用是对已有人手三维模型进行更高精度的重建。SRNet网络以研究团队独创的“将点的超分转化为图像超分的思想”为原则,实现在不增加过多计算量的情况下,进行上万点云的超分重建。
此外,由于缺乏高保真的手部数据来训练SRNet,研究团队构建了一个名为SuperHandScan的扫描数据集训练SRNet。由于SRNet的输入是基于UV的“粗糙”手部网格。因此SRNet的应用范围很广,换句话说,一个“训练有素”的SRNet可以对任何粗手部网格进行超分辨率重建。
据介绍,SRNet和AffineNet组成的I2UV-HandNet系统,未做任何优化情况下,能够在nvidia v100达到46fps;而经过工程优化后版本能够在骁龙865CPU+DSP下达到实时。
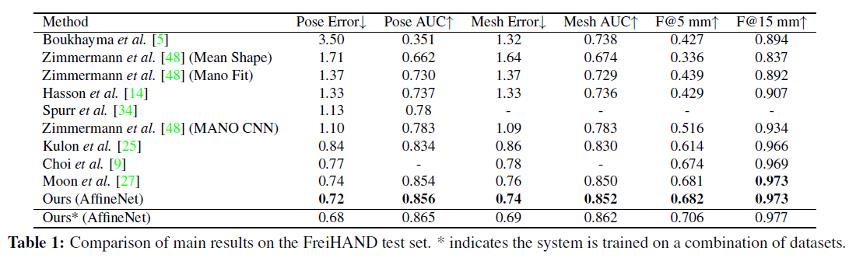
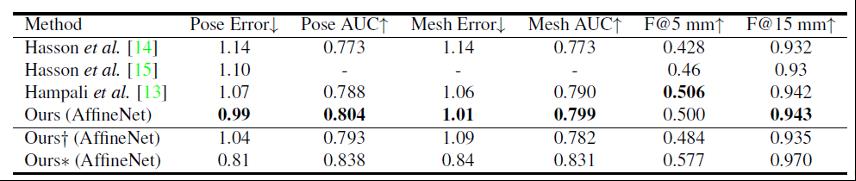
在FreiHAND上进行真实场景下多姿态的人手3D重建对比,↓表示越低越好,↑表示越高越好。
为了验证I2UV-HandNet方法对姿态的鲁棒性,研究团队选用了包含大量姿态的真实人手数据集FreiHAND作为测试集,并通过FreiHAND Competition在线测评与相关SOTA工作进行对比,结果如上表所示,证明了该UV重建方法的有效性。
在HO3D上进行真实场景下具有遮挡的人手3D重建实验对比,↓表示越低越好,↑表示越高越好。
同时为了验证在各种遮挡场景下的重建性能,研究团队选取包含大量遮挡样本的HO3D数据集进行测评,结果如上表所示,各项指标也都达到了SOTA。
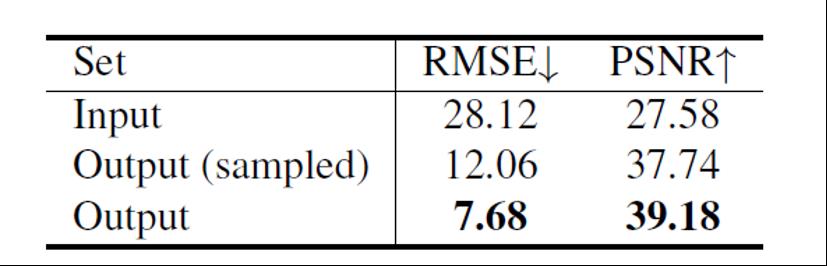
↓表示越低越好,↑表示越高越好
为了定量评价SRNet,研究团队还在HIC数据集上进行了实验。如上所示,SRNet的输出(表中的“OUTPUT”)得到了优于原始深度图的结果。

模型介绍:AffineNet+SRNet=I2UV-HandNet
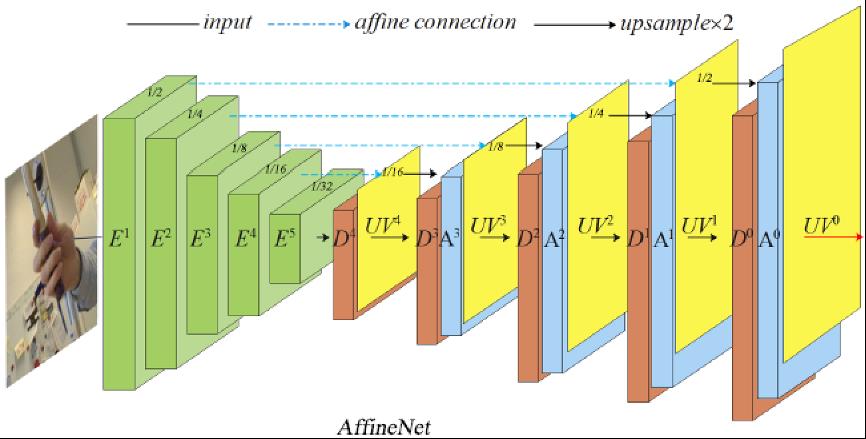
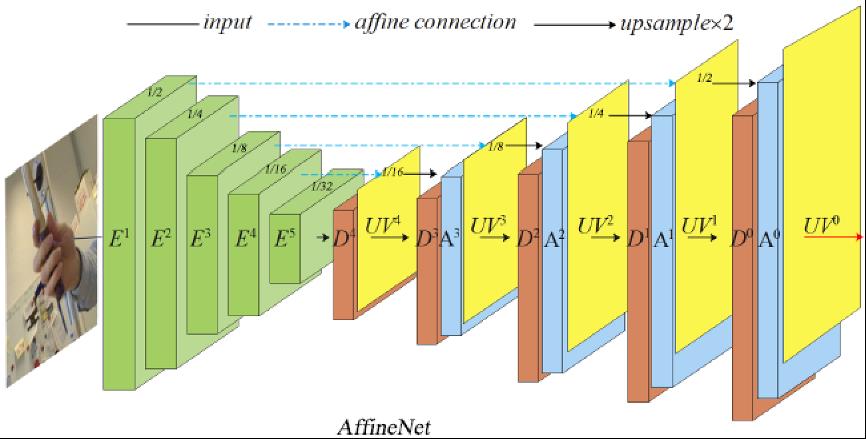
AffineNet网络框架图,AffineNet由编码网络和解码网络组成,在解码时通过Affine Conection和多stage完成由粗到精的UV学习
如上图所示,AffineNet由编解码网络组成,编码骨干网络ResNet-50,解码时采用由粗到精的层级结构,其中Affine Connection是指通过当前层级预测的UV用仿射变换(类似STN)的方式实现编码特征向UV图的对齐,即:
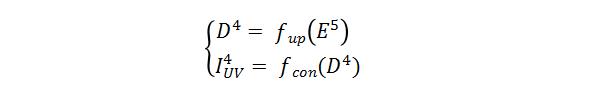
同时有:
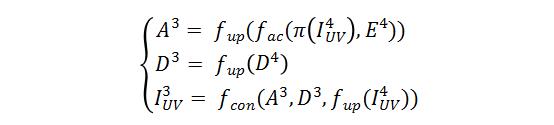
以及:
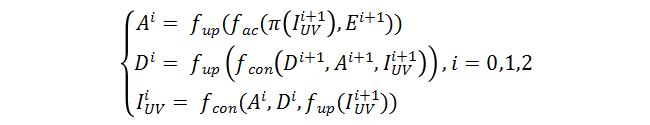
其中 表示 分辨率下的编码特征图, (x)表示将x放大2倍,π表示根据稠密的 在固定投影矩阵的投影坐标, 表示Affine Connection操作, 表示通过仿射变换后与UV对齐后的特征图,相对于 ,其包含更多与手相关的特征。 表示 分辨率下的解码特征图, 表示表示卷积操作。通过上面两个公式看出,解码过程本质上就是一套低分辨率UVmap到高分辨率UVmap重建的过程,同时也是3D点云重建由粗到精的过程。
AffineNet的损失函数分为3项:
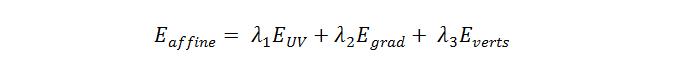
其中,使用L1作为UV的重建Loss:
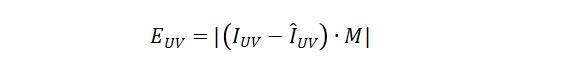
为真实UV图, 为重建结果,M为UV的3D手有效映射掩码。
UV图本质上可以看成将3D模型上每个三角面不重叠地映射到二维平面,所以在UV图上对应的三角片区域的值应该是连续的,因此引入Grad loss:
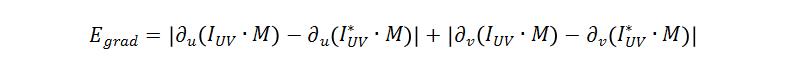
其中 和 分别表示在UV图的U轴和V轴方向求梯度。
在训练阶段对分辨率最大的4个stage(即i=0,1,2,3)重建的UV进行 优化,其中 λ = λ = λ =1,投影矩阵选用正投影矩阵,每个stage间的loss比例都为1。

SRNet每层的设置
SRNet的网络结构类似于超分辨率卷积神经网络(SRCNN),但输入和输出是UV图而非RGB图像。
研究团队巧妙地通过UV图的方式将点的超分转换为图像的超分,将伪高精度UV图作为输入,高精度UV图作为标签,通过伪高精度3D模型生成的UV图到高精度3D模型生成的UV图的超分学习,完成1538个面到6152个面,778个点到3093个点的超分学习,超分Loss设计如下:
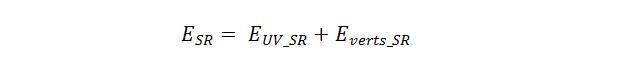
在测试阶段只需要将AffineNet重建的UV图作为输入,便可得到经过超分重建后的高精度UV图,从而实现人手的高精度3D重建。
将AffineNet和SRNet结合成I2UV-HandNet系统便可完成High-fidelity的人手3D重建。为了快速验证将点的超分转化为图像的超分的可行性,研究团队将SRCNN网络结构用于SRNet中,并选取SHS数据集进行训练。
Batch size设置为512,输入UV图的大小为256*256,初始学习率为1e-3,优化器Adam,并采用cosine lr下降方式,并在scale、旋转等方面进行数据增广。
同时为了网络模型具有更好的泛化性,也随机对高精度UV图进行高斯平缓处理,并将结果作为网络的输入。在测试时,将AffineNet输出的UV图作为SRNet的输入实现I2UV-HandNet系统的high-fidelity3D人手重建。

在HO-3D数据集(左)和FreiHAND数据集(右)上的重建结果。从左到右依次为:输入、AffineNet的重建结果、SRNet输出的超分结果(high-fidelity)
上图显示I2UV-HandNet在各种姿态和遮挡条件下基于单目RGB图的人手的High-fidelity的3D重建结果。通过上图的Coarse Mesh和High-fidelity meshes对比可以看出,通过UV图超分输出的包含3093个点/6152个面的3D模型(High-fidelity)明显要比AffineNet输出的包含778个点/1538个面的MANO模型(Coarse Mesh)更加精细,具体表现在折痕细节和皮肤鼓胀等。
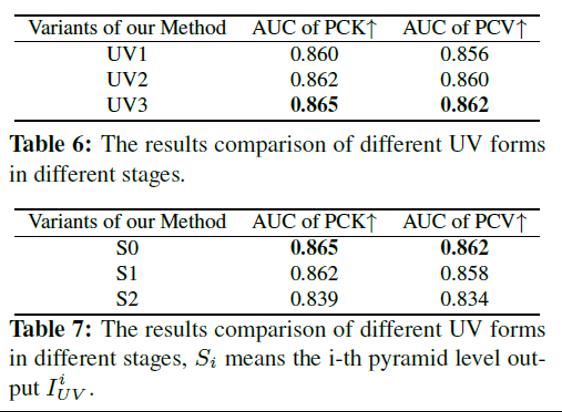
在论文中,研究团队还在FreiHAND测试集上进行了Loss分析、Affine Connection存在性、UV展开方式以及由粗到精的方式多项属性消融的实验分析,分析结果依次见表4到表7。
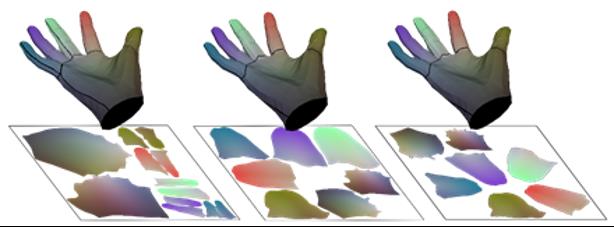
不同的UV展开形式
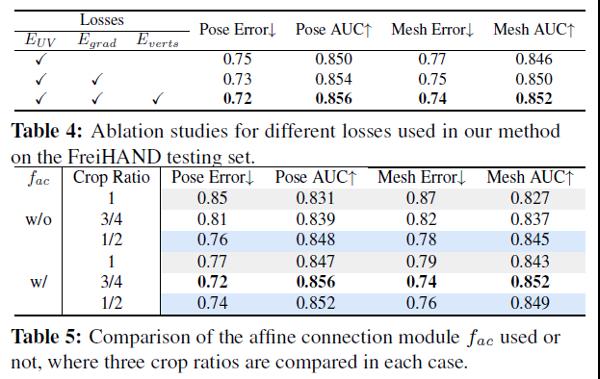
通过实验分析进一步证明本算法在各方面都具有较好的鲁棒性,尤其是对背景具有强抗干扰性,非常适合应用于实际产品中。
AffineNet网络框架图,AffineNet由编码网络和解码网络组成,在解码时通过Affine Conection和多stage完成由粗到精的UV学习
如上图所示,AffineNet由编解码网络组成,编码骨干网络ResNet-50,解码时采用由粗到精的层级结构,其中Affine Connection是指通过当前层级预测的UV用仿射变换(类似STN)的方式实现编码特征向UV图的对齐,即:
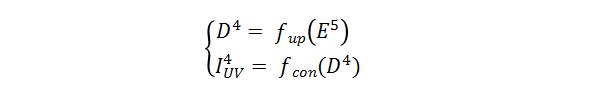
同时有:
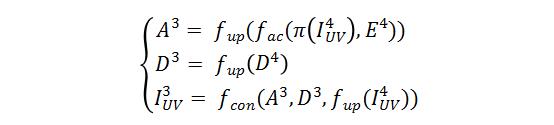
以及:
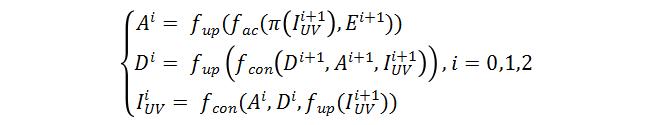
其中 表示 分辨率下的编码特征图, (x)表示将x放大2倍,π表示根据稠密的 在固定投影矩阵的投影坐标,
碰壁五次!我闭关28天啃完这些书,再战拿下腾讯,爱奇艺,小红书,快手等10家大厂!化身offer收割机!