Spark-Shell的启动与运行
Posted 会编程的李较瘦
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark-Shell的启动与运行相关的知识,希望对你有一定的参考价值。
一、运行spark-shell命令
执行spark-shell命令就可以进入Spark-Shell交互式环境。
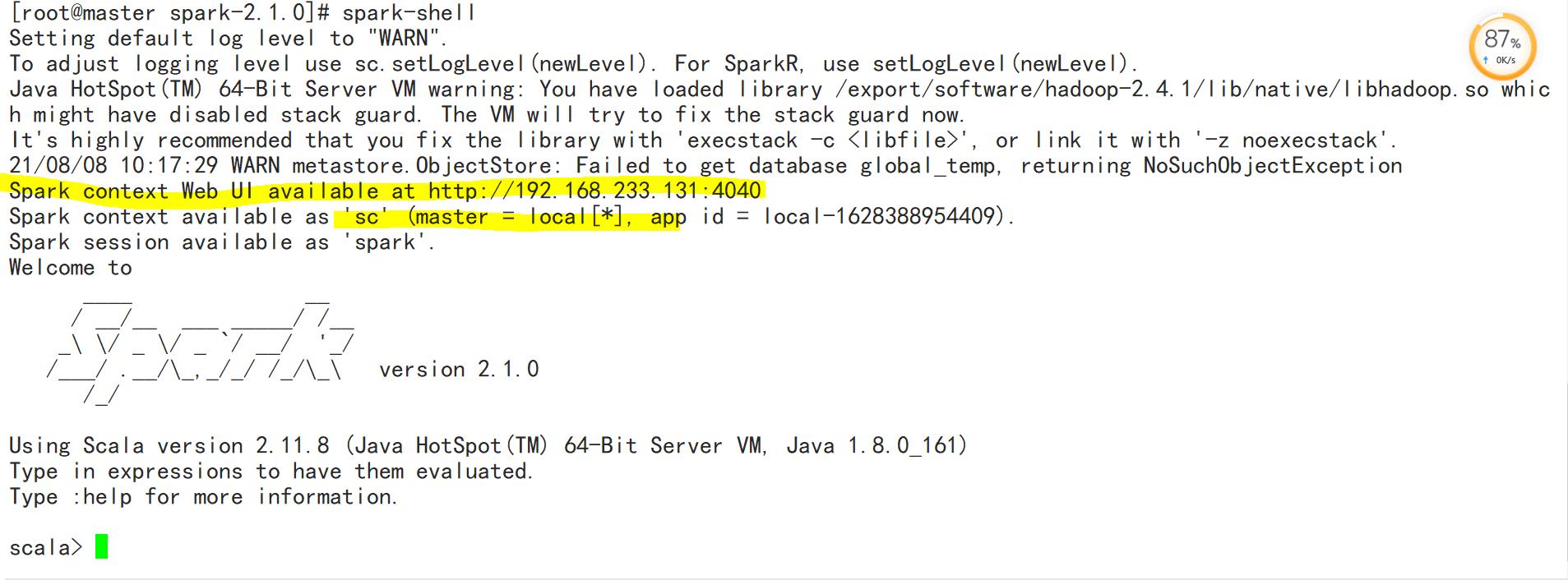
命令如下:
spark-shell --master <master-url>
上述命令中,–master表示指定当前连接的Master节点,master-url用于指定spark的运行模式,可取的参考值如下所示:
| 参数名称 | 功能描述 |
|---|---|
| liocal | 使用一个Worker线程本地化运行Spark |
| liocal[*] | 本地运行spark,其工作线程数量与本机CPU逻辑核心数量相同 |
| liocal[N] | 使用N个Worker线程本地化运行spark |
| spark://host:post | 在Standlone |
| liocal | |
| liocal | |
| liocal |
二、运行spark-shell读取HDFS文件
三、IDEA开发wordcount程序
四、Spark Rdd简单操作
1.从文件系统加载数据创建RDD
(1)从Linux本地文件系统加载数据创建RDD
val rdd = sc.textFile("file:///root/word.txt")
rdd.collect()

(2)从HDFS中加载数据创建RDD
以上是关于Spark-Shell的启动与运行的主要内容,如果未能解决你的问题,请参考以下文章