C语言提升
Posted xuechanba
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了C语言提升相关的知识,希望对你有一定的参考价值。
链表
链表
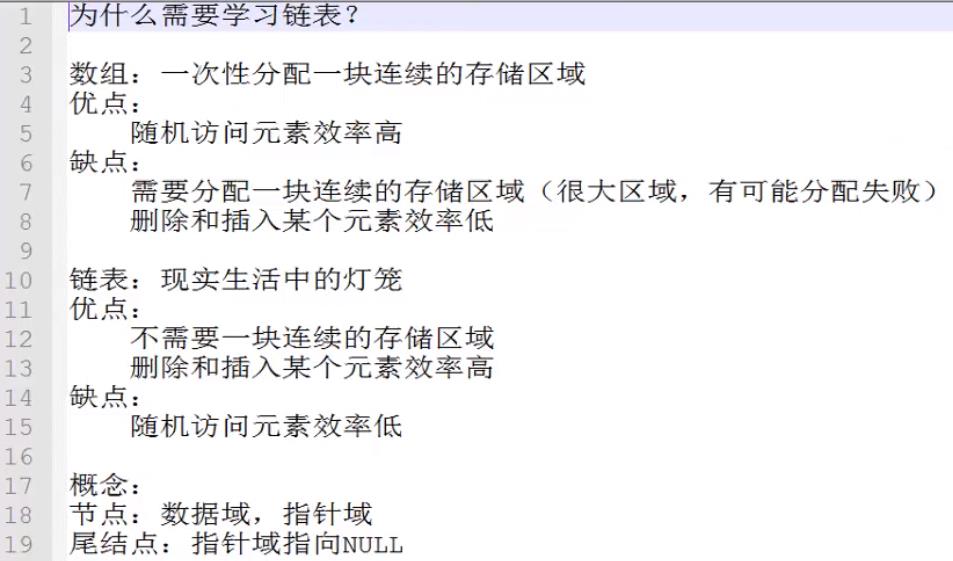
链表和数组的优缺点
链表与函数指针


链表的分类

我们使用的都是动态链表。

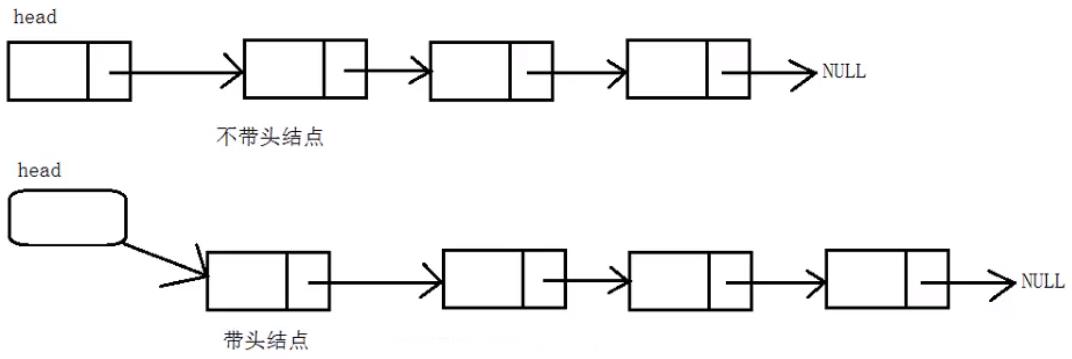
假设后面,想要从不带头链表的头结点这边插入一个结点,它的头结点是可以变化的。

若想要从带头链表的头结点这边插入一个结点,它的头结点是不变的,相当于是一种标志位。
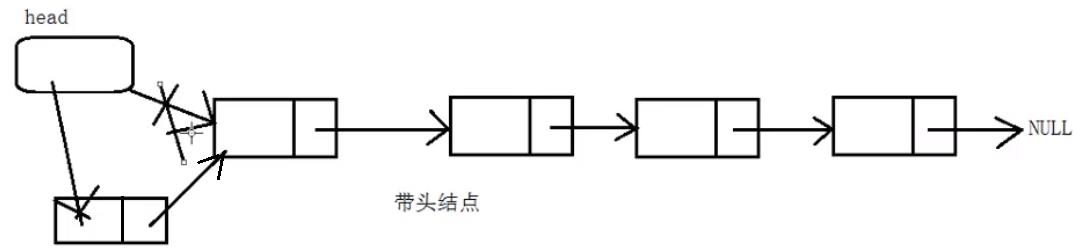
不带头链表的头结点就存放着有效数据,
而带头链表的头结点并不存放有效数据,永远是头结点,第二个结点才是有效数据结点。
带头链表方便一些,我们下面学习的是带头结点。
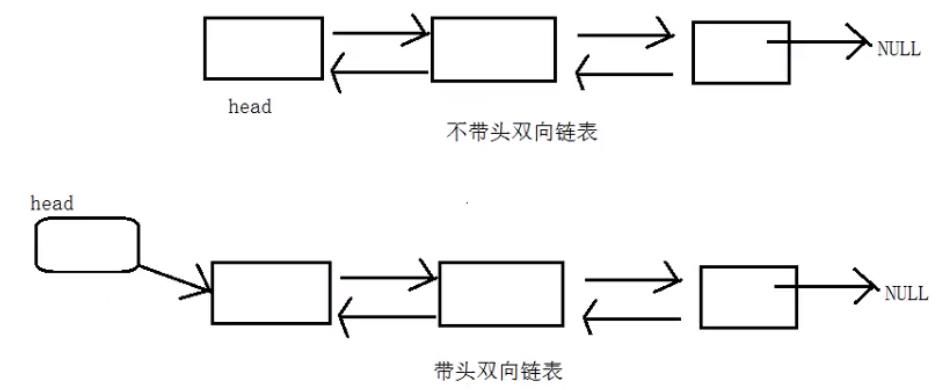
上面介绍的都是单向链表,下面再来画一下双向链表。
结构体套结构体
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
typedef struct A
{
int a;
char* p;
}A;
/*
* 1、结构体可以嵌套另外一个结构体的任何类型变量
*
* 2、结构体嵌套本结构体普通变量是(不可以)的。
因为本结构体的类型大小无法确定。数据类型的本质是:固定大小内存块的别名。
* 3、结构体嵌套本结构体普通变量是(不可以)的。
*/
typedef struct B
{
int a;
A b; //ok
A *p; //ok
//struct B tmp; 错误
struct B* next;//指针类型,结构体指针变量的空间可以确定
//B* next;错误,因为B是在后面才定义的
}B;
int main(int argc,char *argv[])
{
printf("\\n");
system("pause");
return 0;
}
静态链表的使用
创建并遍历三个结点的静态链表
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
typedef struct STU
{
int id;//数据域
char name[10];
struct STU* next;//指针域
}STU;
int main(int argc,char *argv[])
{
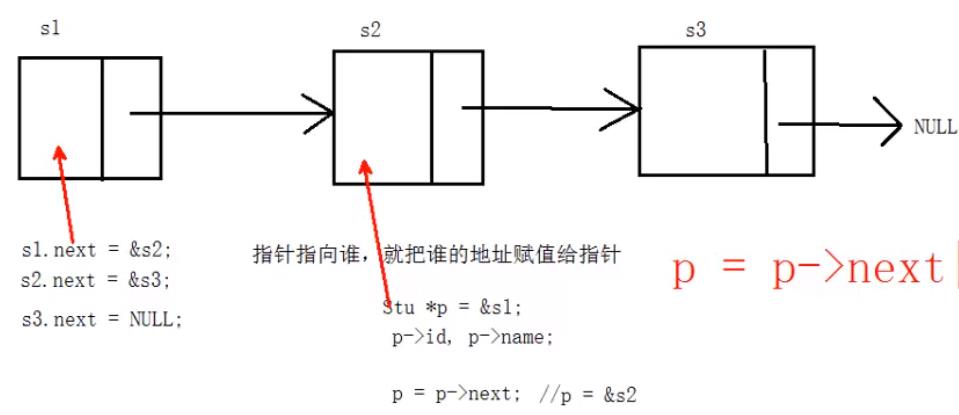
//初始化三个结构体变量
STU stu1 = { 1,"one",NULL };
STU stu2 = { 2,"two",NULL };
STU stu3 = { 3,"three",NULL };
stu1.next = &stu2;//stu1的next指针指向stu2
stu2.next = &stu3;//stu2
stu3.next = NULL;//尾结点
STU* p = &stu1;
while (p != NULL)
{
printf("id = %d,name = %s.\\n",p->id,p->name);
//结点移动到下一个
p = p->next;
}
printf("\\n");
system("pause");
return 0;
}

动态链表
带有头结点的单向链表
1、建立带有头结点的单向链表

#include<stdio.h>
#include<stdlib.h>
#include<string.h>
typedef struct Node
{
int id;
struct Node* next;
}Node;
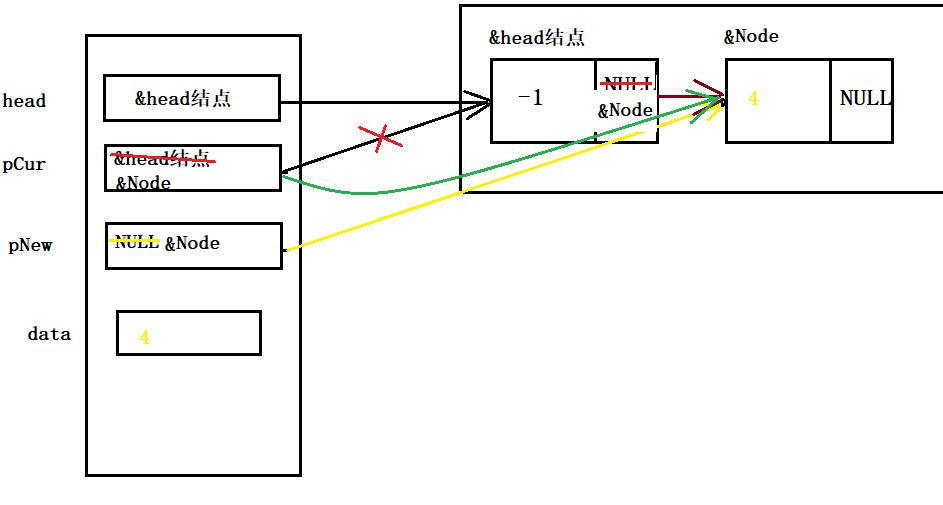
Node* SListCreat()
{
Node* head = NULL;
//头结点作为标志,不存储有效数据
head = (Node*)malloc(sizeof(Node));
if (head == NULL)
{
return NULL;
}
//给head的成员变量赋值
head->id = -1;
head->next = NULL;
Node* pCur = head;
Node* pNew = NULL;
int data;
while (1)
{
printf("请输入数据,输入-1表示退出。\\n");
scanf("%d",&data);
if (data == -1)//输入-1,退出
{
break;
}
//新结点动态分配空间
pNew = (Node*)malloc(sizeof(Node));
if (pNew == NULL)
{
continue;
}
//给pNew成员变量赋值(初始化)
pNew->id = data;
pNew->next = NULL;
//链表建立关系
//当前结点的next指向pNew
pCur->next = pNew;
//pNew的next指向NULL
pNew->next = NULL;
//把pCur移动到pNew,pCur指向pNew
pCur = pNew;
}
return head;
}
//链表的遍历
int SListPrint(Node* head)
{
if (head == NULL)
{
return NULL;
}
//取出第一个有效结点(头结点的next)
Node* pCur = head->next;
printf("head -> ");
while (pCur != NULL)
{
printf("%d -> ",pCur->id);
//当前结点往下移动一位,pCur指定下一个
pCur = pCur->next;
}
printf("NULL\\n");
return 0;
}
void test()
{
Node* head = NULL;
head = SListCreat();//创建头结点
SListPrint(head);
}
int main(int argc,char *argv[])
{
test();
printf("\\n");
system("pause");
return 0;
}
画图分析:
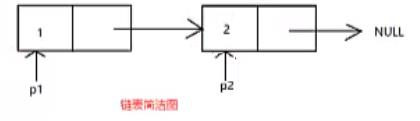
我们很多时候画的链表图都是简洁图。
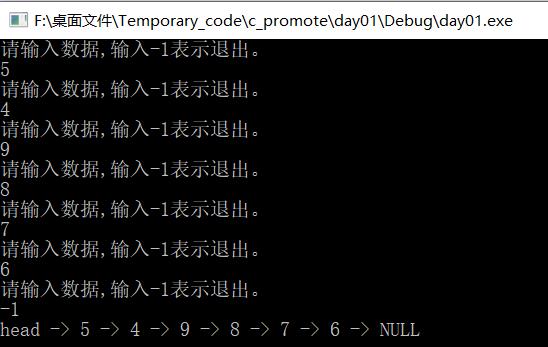
运行:
2、在单向链表中插入结点
在值为x的结点前插入一个值为y的结点,若值为x的结点不存在,则插在表尾。
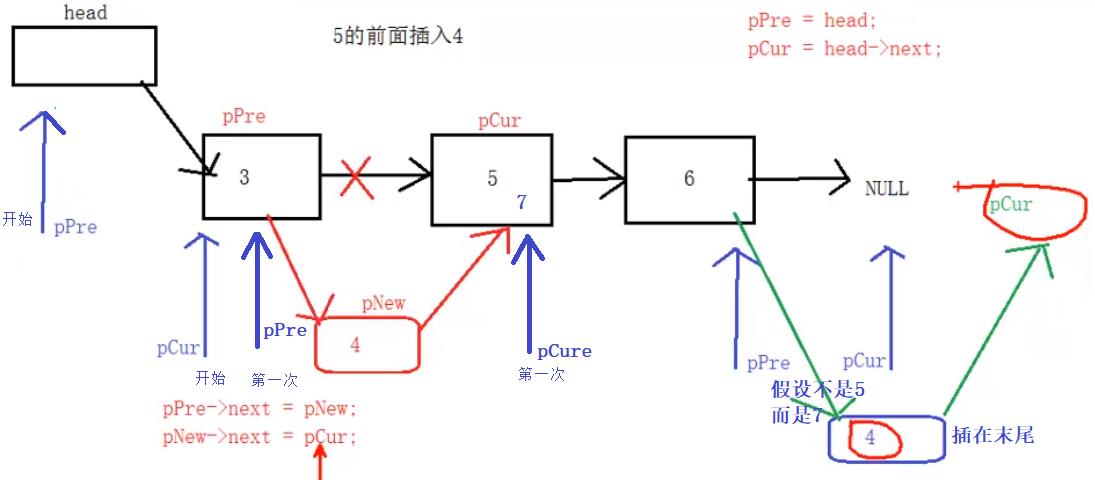
两种情况:
1、找到匹配的结点,pCur为匹配结点,pPre为pCur的上一个结点。
2、没有找到匹配结点,pCur为空结点,pPre为最后一个结点。
两种情况均按下述插入:
pPre->next = pNew;
pNew->next = pCur;
插入结点函数的具体代码如下:
//在值为x的结点前插入一个值为y的结点,若值为x的结点不存在,则插在表尾。
int SListNodeInsert(Node* head, int x, int y)
{
if (head == NULL)
{
return NULL;
}
Node* pNew = NULL;
//新结点动态分配空间
pNew = (Node*)malloc(sizeof(Node));
if (pNew == NULL)
{
return NULL;
}
//给pNew成员变量赋值(初始化)
pNew->id = y;
pNew->next = NULL;
//定义两个辅助变量并设置初始值
Node* pPre = head;
Node* pCur = head->next;
while (pCur!=NULL)
{
if (pCur->id == x)
{
break;
}
pPre = pCur;
pCur = pCur->next;
}
//两种情况
//1、找到匹配的结点,pCur为匹配结点,pPre为pCur的上一个结点。
//2、没有找到匹配结点,pCur为空结点,pPre为最后一个结点。
//两种情况均按下述插入
pPre->next = pNew;
pNew->next = pCur;
return 0;
}
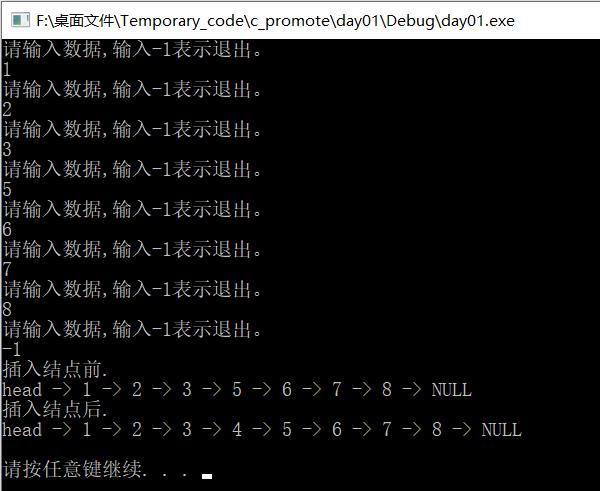
3、在单向链表中删除结点
删除值为x的结点,单次调用删除第一个被遍历到的结点,多次删除,需多次调用。
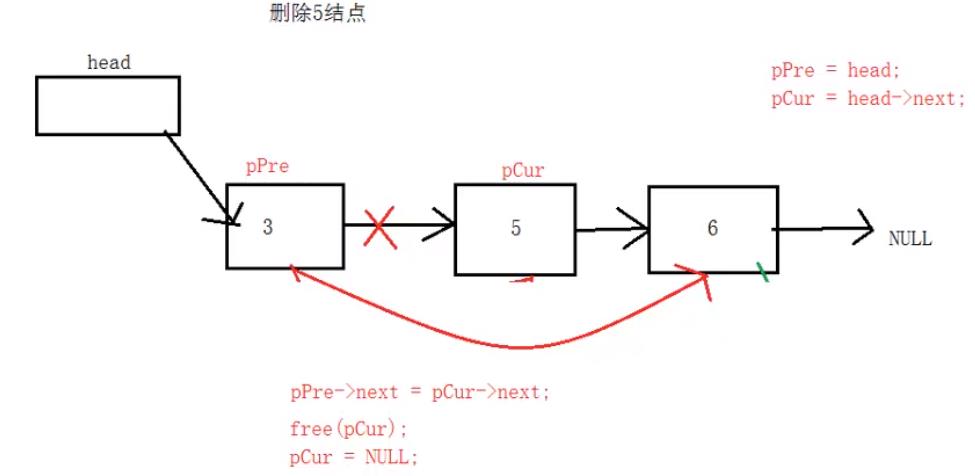
//删除值为x的结点,删除第一个被遍历到的值
int SListNodeDel(Node* head, int x)
{
//定义两个辅助变量并设置初始值
Node* pPre = head;
Node* pCur = head->next;
//标志位:0代表没有找到,1代表找到了。
int flag = 0;
while (pCur != NULL)
{
if (pCur->id == x)
{
//pPre的下一个指向pCur的下一个
pPre->next = pCur->next;
free(pCur);
pCur = NULL;
flag = 1;
break;
}
pPre = pCur;
pCur = pCur->next;
}
if (!flag)
{
printf("no find.\\n");
return -2;
}
return 0;
}
4、清空链表,释放所有结点
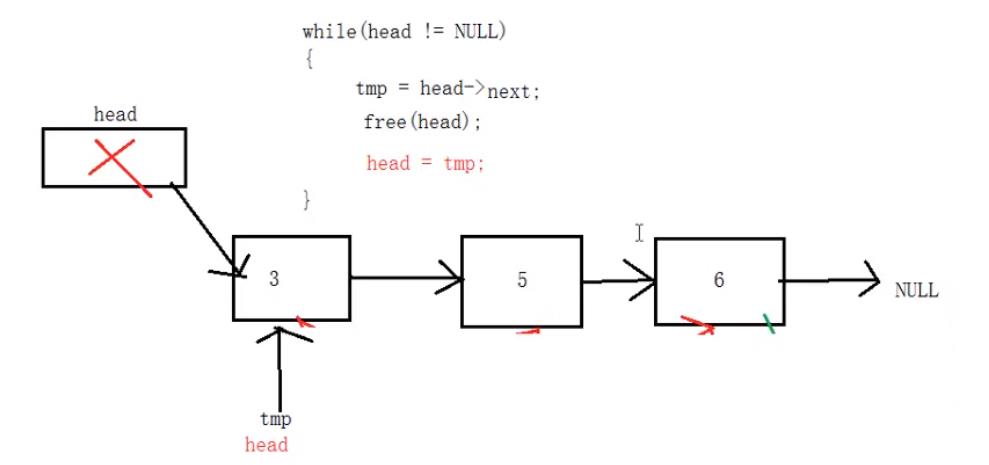
//清空链表,释放所有结点
int SListDestroy(Node* head)
{
if (head == NULL)
{
return -1;
}
//定义临时变量来保存每次的下一个结点的位置
Node* pTmp = NULL;
int i = 0;
while (head != NULL)
{
i++;
pTmp = head->next;
free(head);
head = pTmp;
}
printf("i = %d.\\n",i);
return 0;
}
在测试程序中:释放完所有结点之后,也要将头结点head指向NULL
void test()
{
Node* head = NULL;
head = SListCreat();//创建头结点
SListPrint(head);
SListDestroy(head);
head = NULL;
}
5、在单向链表中删除值为x的所有结点
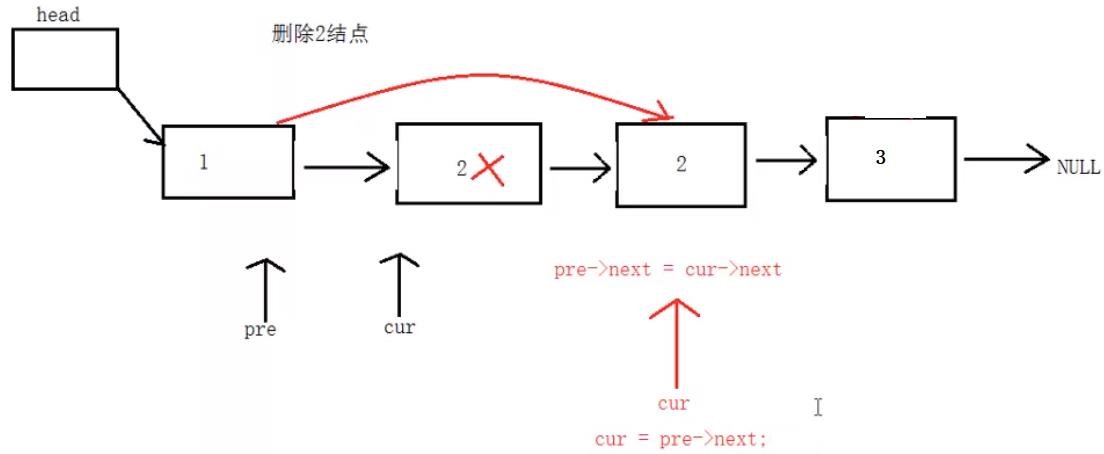
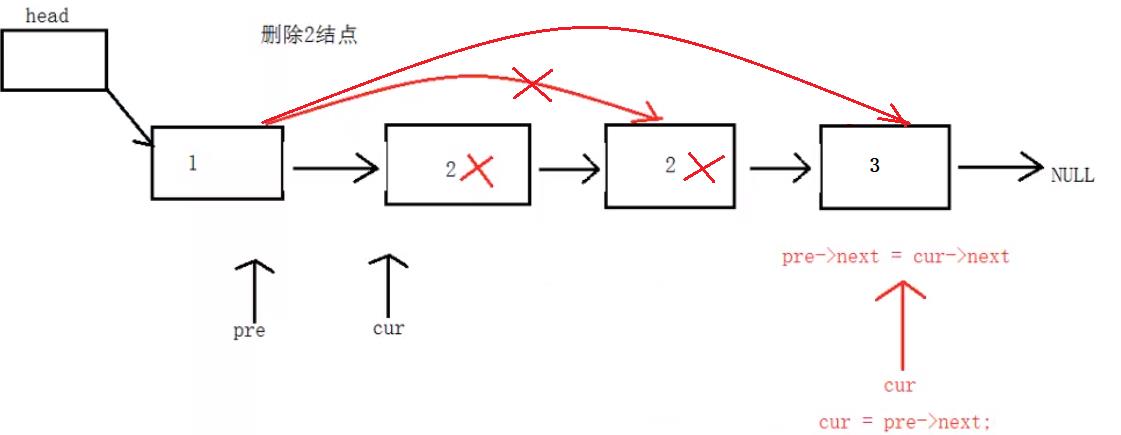
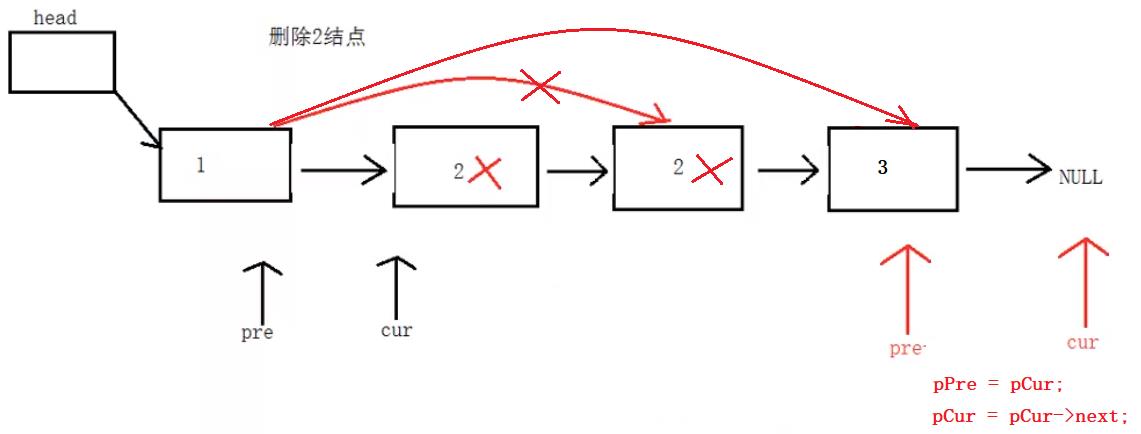
明白 continue 的作用
//删除值为x的所有结点
int SListNodeDelAll(Node * head, int x)
{
//定义两个辅助变量并设置初始值
Node* pPre = head;
Node* pCur = head->next;
//标志位:0代表没有找到,1代表找到了。
int flag = 0;
int count = 0;
while (pCur != NULL)
{
if (pCur->id == x)
{
//pPre的下一个指向pCur的下一个
pPre->next = pCur->next;
free(pCur);
pCur = NULL;
flag = 1;//说明找到了
count++; //找到的次数
pCur = pPre->next;
continue;//必须加上,跳出本次循环,break是直接跳出循环体
}
pPre = pCur;
pCur = pCur->next;
}
if (flag)
{
printf("Node = %d.\\n",count);
}
else
{
printf("no find.\\n");
return -2;
}
return 0;
}
6、单向链表排序
按照链表数据域中的某一成员的大小进行升/降排序
需要区分不同的情况。
1、假设该链表数据域中只有一个成员变量或者只交换这一个成员变量,假设为int类型。
//链表排序
int SListSort(Node* head)
{
if (head == NULL|| head->next == NULL)
{
return -1;
}
Node* pPre = NULL;
Node* pCur = NULL;
int tmp;
for (pPre = head->next; pPre->next != NULL; pPre = pPre->next)
{
for (pCur = pPre->next; pCur != NULL; pCur = pCur->next)
{
if (pPre->id < pCur->id)
{
tmp = pPre->id;
pPre->id = pCur->id;
pCur->id = tmp;
}
}
}
return 0;
}
2、链表数据域中的多个成员都交换
//链表排序
int SListSort(Node* head)
{
if (head == NULL|| head->next == NULL)
{
return -1;
}
Node* pPre = NULL;
Node* pCur = NULL;
Node tmp;
for (pPre = head->next; pPre->next != NULL; pPre = pPre->next)
{
for (pCur = pPre->next; pCur != NULL; pCur = pCur->next)
{
if (pPre->id < pCur->id)
{
//交换数据域
tmp = *pPre;
*pPre = *pCur;
*pCur = tmp;
//交换指针域
tmp.next = pPre->next;
pPre->next = pCur->next;
pCur->next = tmp.next;
}
}
}
return 0;
}
交换完数据域之后,为什么还要交换指针域?
上面代码中的pPre是下图中的p1,pCur是下图中的p2。
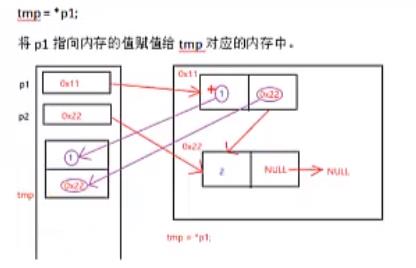
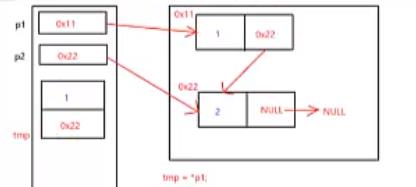
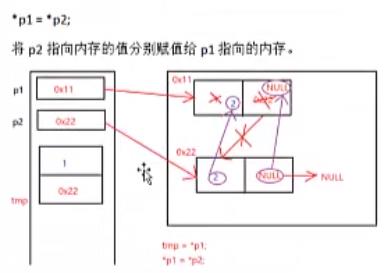
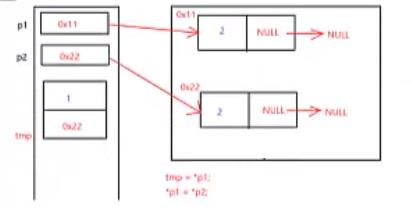
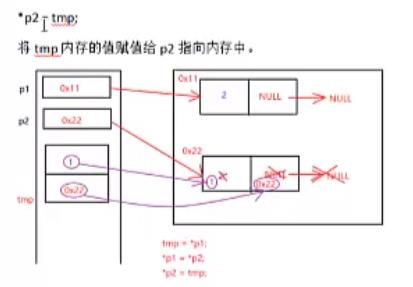
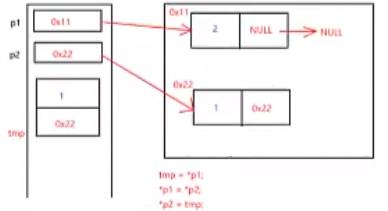
红色的箭头代表指向,而紫色的箭头则代表赋值。


因此,交换完数据域之后,还要交换指针域。
指针函数和函数指针
指针函数
指针函数就是返回值为指针的函数,本质是一个函数。
声明形式:type *func (参数列表)
()比 * 的优先级要高。
函数指针
函数指针就是指向函数的指针,本质是一个指针。
函数名字就是程序的入口地址。
定义函数指针变量有三种方式。
方式一、先定义函数类型,再根据类型定义指针变量
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
int fun(int a)
{
printf("a == %d.\\n",a);
return 0;
}
int main(int argc,char *argv[])
{
//有typedef是类型,没有是变量。
typedef int FUN(int a);//定义FUN函数类型
FUN* p = NULL;//定义函数指针变量
p = fun;//p指向fun函数
fun(5);//传统调用
p(5);//函数指针变量调用方式
printf("\\n");
system("pause");
return 0;
}
方式二、先定义函数指针类型,再根据类型定义指针变量
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
int fun(int a)
{
printf("a == %d.\\n",a);
return 0;
}
int main(int argc,char *argv[])
{
//有typedef是类型,没有是变量。
typedef int (*PFUN)(int a);//PFUN,函数指针类型
PFUN p = fun;//函数指针变量,p指向fun函数。
p(5);
printf("\\n");
system("pause");
return 0;
}
方式三、直接定义函数指针变量
#include<stdio.h>
#include<stdlib.h