Day3:数据结构之带头双链表
Posted 雨轩(小宇)
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Day3:数据结构之带头双链表相关的知识,希望对你有一定的参考价值。
带头双链表
| 目录 | 目录 |
|---|---|
| 顺序表 | 单链表(不带附加头结点) |
| 双链表(带附加头结点) |
今天给大家讲的是双链表
前言
- 上一节,我们说到单链表,知道了单链表的一些缺点和注意事项,这一节我们来学习双链表,看看双链表是否能完美解决单链表的一些问题。
1、双链表的基本概念
-
在双链表中有两个指针域和一个数据域,prev表示前驱指针(左指针),next表示后继指针(右指针),data数据域。所以双链表至少有三个域:
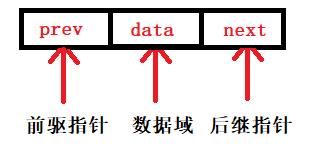
-
由于双链表通常采用带附加头结点的循环链表方式,所以双链表带有一个附加头结点,它的data域可以不放数据,也可以存放一个特殊要求的数据。
空表:head->prev = head; head->next = head
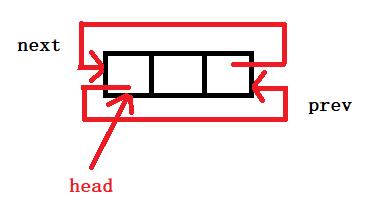
非空表:
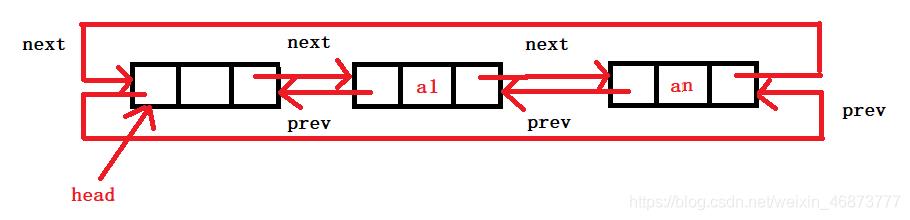
2、双链表的好处
- 双链表可以访问前驱元素,也可以访问后继元素,时间开销只有o(1)
- 插入删除一个结点时,不用在去找他的前驱结点,有前驱指针,直接将指向更改一下即可
3、双链表的基本操作
头文件定义
#include<stdio.h>
#include<stdlib.h>
#include<assert.h>
// 带头+双向+循环链表增删查改实现
typedef int LTDataType;//type的人重命名int为LTDataType
typedef struct ListNode
{
LTDataType data;//数据域
struct ListNode* next;//后继指针
struct ListNode* prev;//前驱指针
}ListNode;
1. 初始化
- 这里可以封装成BuyListNode函数去创建一个结点,也可以自己在初始化函数里面创建结点。
ListNode* ListCreate()
{
//ListNode* phead = (ListNode*)malloc(sizeof(ListNode));
ListNode* phead = BuyListNode(0);
/*if (phead == NULL)
{
perror("ListCreate:");
exit(-1);
}*/
phead->next = phead;//看上面画的空表图,指向自己即为空
phead->prev = phead;//同上
return phead;
}
2. 创建一个新结点
- 封装成一个函数,为创建结点提供方便。
ListNode* BuyListNode(LTDataType x)
{
ListNode* newnode = (ListNode*)malloc(sizeof(ListNode));
if (newnode == NULL)//检查内存是否分配成功
{
perror("ListCreate:");
exit(-1);
}
newnode->next = NULL;//后继指针置空
newnode->prev = NULL;//前驱指针置空
newnode->data = x;//值为x
return newnode;
}
3. 打印
- 双链表打印,定义 cur为第一个结点,注意结束条件不是 cur != NULL,而是 cur != head,到head才表示遍历完一次!!!
void ListPrint(ListNode* pHead)
{
assert(pHead);
ListNode* head = pHead;
ListNode* cur = head->next;//第一个结点
while (cur != head)//等于头指针,才表示一次遍历完
{
printf("%d ", cur->data);
cur = cur->next;
}
printf("NULL\\n");
}
4. 头插
- 创建新结点,设置第一个结点,将头指针和第一个结点的指向变化。
- 学了双链表,我们应该看得出来,头插可以调用插入的算法。
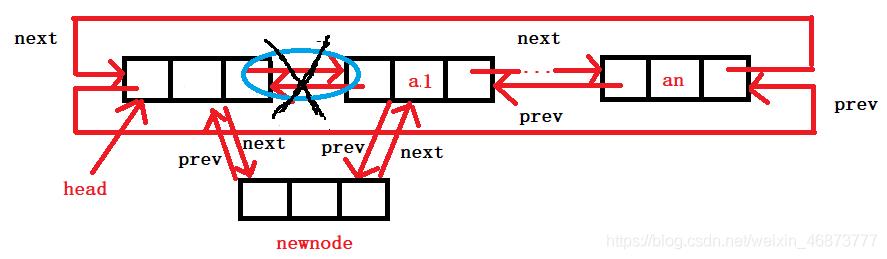
void ListPushFront(ListNode* pHead, LTDataType x)
{
assert(pHead);
//ListInsert(pHead->next, x);//因为是在pos结点之前插入,这里可以复用插入算法
ListNode* head = pHead;
ListNode* cur = head->next;//第一个结点
ListNode* newnode = BuyListNode(x);//创建新结点
head->next = newnode;//设置新结点为头指针的下一个结点
newnode->prev = head;//新结点的前驱指针为头指针
newnode->next = cur;//新结点的下一个结点为原来的第一个结点
cur->prev = newnode;//原来的第一个结点的前驱指针为新结点
}
5. 头删
- 头删就比较简单,直接将头指针的后继指针指向第二个结点,第二个结点的前驱指针指向头指针即可,这里用第一个结点作为中间结点。
- 头删可以复用删除算法。
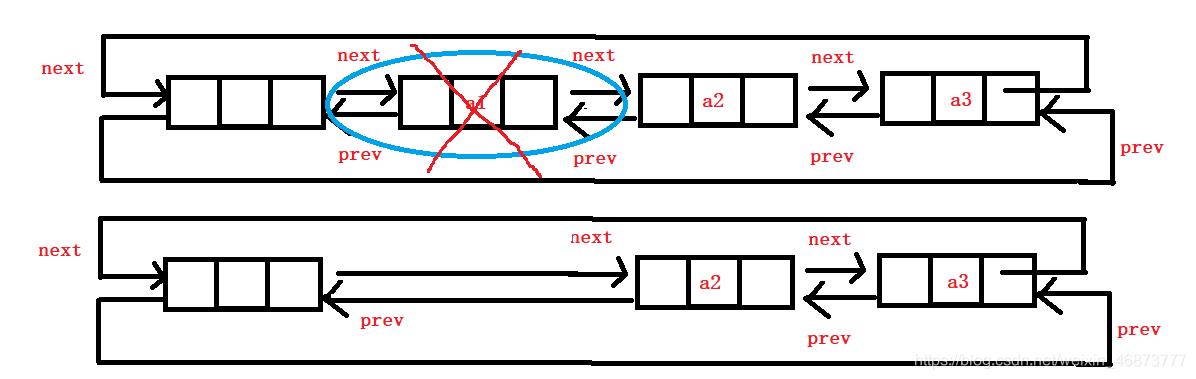
void ListPopFront(ListNode* pHead)
{
assert(pHead);
assert(!(pHead->next == pHead));//还需要检查是否为空,为空删除失败
//ListErase(pHead->next);//可以复用删除算法
ListNode* head = pHead;//head为头指针
ListNode* cur = head->next;//需要删除的头结点
ListNode* next = cur->next;//第二个结点
free(cur);//释放第一个结点
cur = NULL;//置空,防止变成野指针
head->next = next;//头指针的后继指针指向第二个结点
next->prev = head;//第二个结点的前驱指针指向头指针
}
6. 尾插
- 将头指针和尾结点的前驱指针和后继指针的指向变化即可。
- 尾插可以复用插入算法。
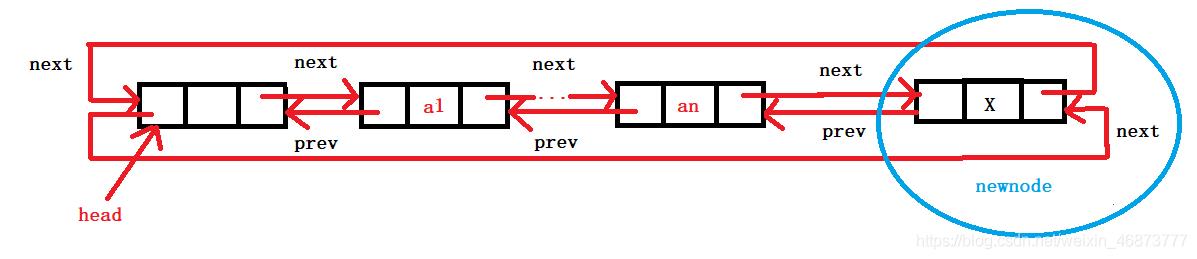
void ListPushBack(ListNode* pHead, LTDataType x)
{
assert(pHead);
//ListInsert(pHead, x);//可以复用插入算法
ListNode* head = pHead;//头指针
ListNode* newnode = BuyListNode(x);//创建新结点
ListNode* cur = head->prev;//尾结点
cur->next = newnode;//尾结点指向新结点
newnode->prev = cur;//尾结点的前驱指针指向尾结点
head->prev = newnode;//头指针的前驱指针指向新结点
newnode->next = head;//新结作为尾结点指向头指针
}
7. 尾删
- 将头指针指向倒数第二个结点接口。
- 尾删可以复用删除算法。
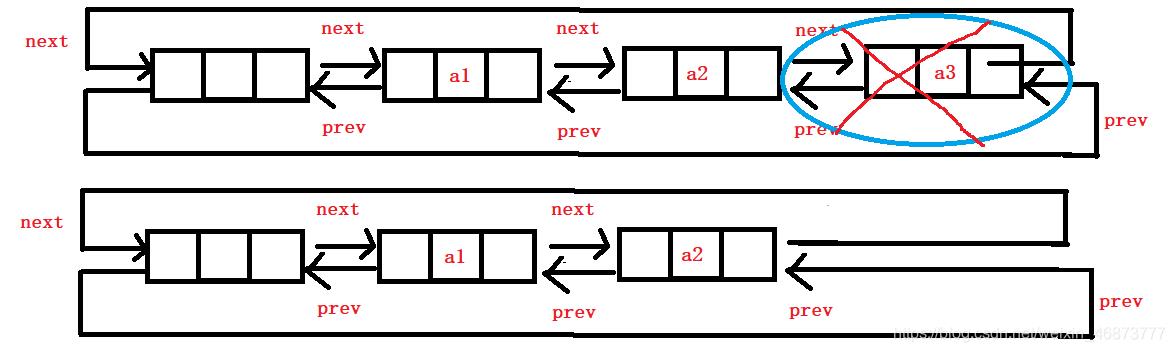
void ListPopBack(ListNode* pHead)
{
assert(pHead);
assert(!(pHead->next==pHead));//还需要检查是否为空,为空删除失败
//ListErase(pHead->prev);//可以复用删除算法
ListNode* head = pHead;//头指针
ListNode* tail = head->prev;//尾结点
ListNode* newtail = tail->prev;//倒数第二个结点
free(tail);//这里记住还要释放,防止内存泄漏
tail = NULL;//置空,防止变成野指针
newtail->next = head;//倒数第二个结点指向头指针,成为尾结点
head->prev = newtail;//头指针指向倒数第二个结点
}
8. 查找
- 查找跟单链表的查找方法是一样的,找到返回该结点,未找到返回NULL
ListNode* ListFind(ListNode* pHead, LTDataType x)
{
assert(pHead);
ListNode* head = pHead;//头指针
ListNode* cur = head->next;//第一个结点
while (cur != head)//条件是不等于头指针
{
if (cur->data == x)//找到返回该结点
return cur;
cur = cur->next;//迭代
}
return NULL;//未找到返回NULL
}
9. 插入
- 插入有三种插入的点,头插,尾插,还有在中间结点插入
- 算法是一样的,自己注意前驱指针和后继指针的变化即可
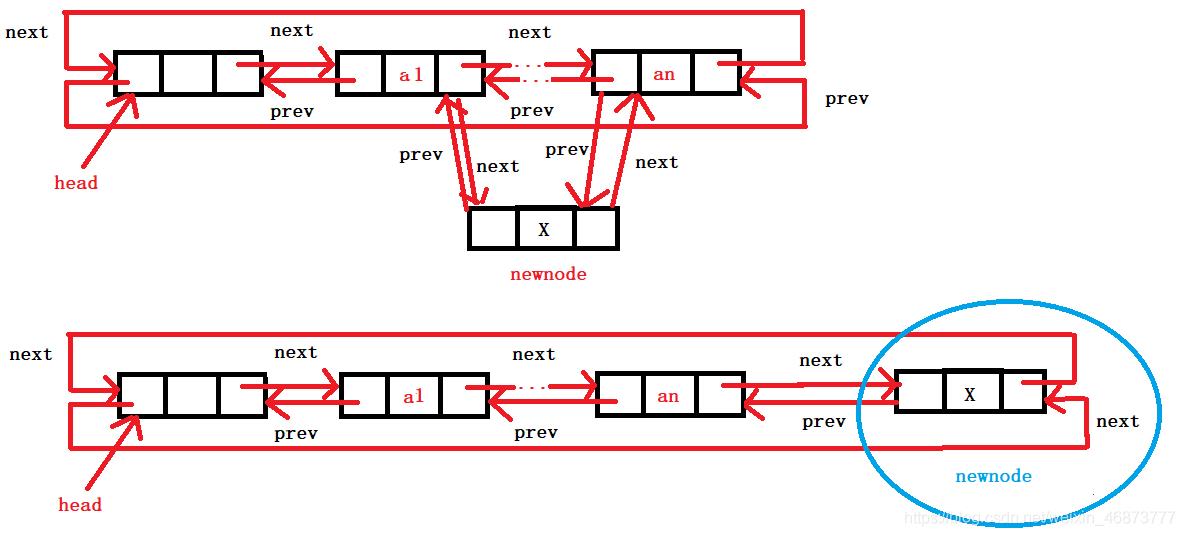
void ListInsert(ListNode* pos, LTDataType x)
{
assert(pos);
ListNode* cur = pos;//在pos结点前插入
ListNode* prev = cur->prev;//pos的前一个结点
ListNode* newnode = BuyListNode(x);//创建新结点
newnode->prev= prev;//新结点的前驱指针指向pos的前一个结点
prev->next = newnode;//pos的前一个结点指向新结点
newnode->next = cur;//新结点指向pos结点
cur->prev = newnode;//pos结点的前驱指针指向新结点
}
10. 删除
- 删除跟插入是一样的,也有头删,尾删,删除中间结点
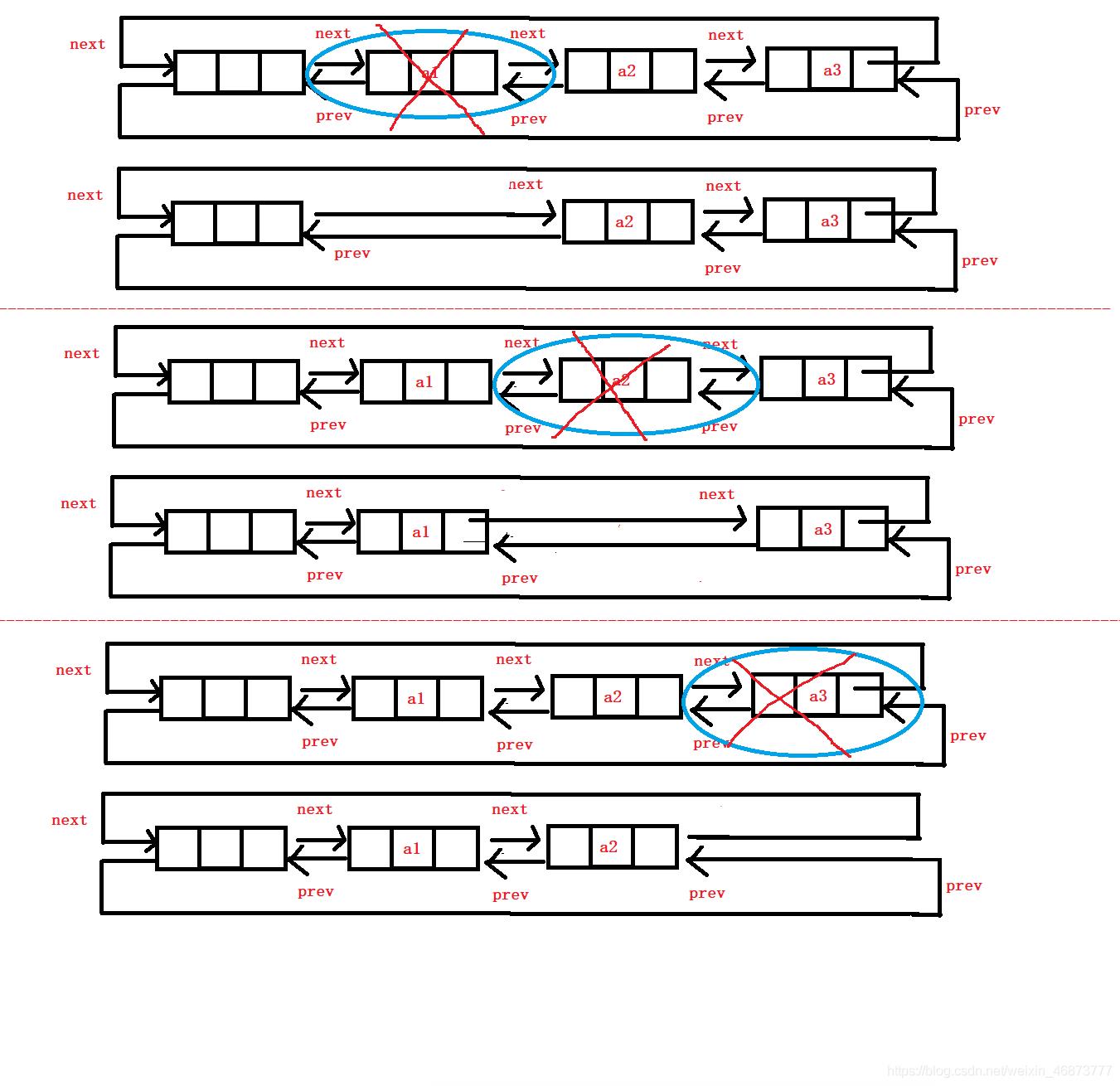
```c
void ListErase(ListNode* pos)
{
assert(pos);
ListNode* cur = pos;//查找的结点
ListNode* prev = cur->prev;//pos的前一个结点
ListNode* next = cur->next;//pos的后一个结点
free(cur);//释放,防止内存泄漏
cur = NULL;//置空,防止变成野指针
prev->next = next;//pos的前一个结点指向pos的后一个结点
next->prev = prev;//pos的后一个结点指向pos的前一个结点
}
11. 销毁
- 让cur作为第一个结点,迭代一个一个删除即可,记得释放内存,防止内存泄漏
void ListDestory(ListNode* pHead)
{
assert(pHead);
ListNode* cur = pHead->next;//第一个结点
while (cur != pHead)//不等于头指针,才进行循环
{
ListNode* next = cur->next;//迭代结点
free(cur);//释放,防止内存泄漏
cur = next;//迭代
}
free(pHead);//防止内存泄漏
pHead = NULL;//置空,防止变成野指针
}
总结
- 细心的小伙伴可以发现,头插、头删、尾插、尾删,都可以复用插入、删除算法。
- 正式因为有了前驱指针,整个算法才比较容易,所以利用双链表去查找,插入,删除某个结点是非常容易的,但是也要注意指针的指向,不要误用!!!
还有其他的点需要读者自己去看书领悟,作者在这里就不多解释了,只有自己敲得多,题做的多才会慢慢领悟!!!

创作不易,记得三连!!!
以上是关于Day3:数据结构之带头双链表的主要内容,如果未能解决你的问题,请参考以下文章