《Python实例》震惊了,用Python这么简单实现了聊天系统的脏话,广告检测
Posted 香菜聊游戏
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了《Python实例》震惊了,用Python这么简单实现了聊天系统的脏话,广告检测相关的知识,希望对你有一定的参考价值。
目录
点赞在看,养成习惯
在游戏中聊天功能几乎是必备的功能,这样的功能存在一定的问题那就是会导致世界频道很乱,经常会有一些敏感词,或者一些游戏厂商不愿意看到的聊天,之前我们游戏中也有这样的问题,我们公司做了举报和后台监控,今天就来实现下这种监控。
1、需求分析:
因为深度学习用的不咋样,虽然之前写过强化学习,但是看强化学习的结果不是特别满意,所以研究下简单一些的方法实现。
这种分类任务其实有现成的解决方案,比如垃圾邮件的分类是同样的问题,虽然有不同的解法,但是我还是选择了最简单的朴素贝叶斯分类。主要做一些探索,
因为我们的游戏大都是中文,所以我们需要对中文进行分词,比如我是帅哥,要拆分。
2、算法原理:
朴素贝叶斯算法,是一种通过根据新样本的已有特征在数据集中的条件概率来判断新样本所属类别的算法;它假设①每个特征之间相互独立、②每个特征同等重要。也可以理解为根据过往的概率判断当前特征同时满足时的概率。具体的数学公司可以自己百度,数据公式太鸡儿难写了,大概懂得就好。
在恰当的时候使用恰当的算法。
jieba 分词原理 :jieba分词属于概率语言模型分词。概率语言模型分词的任务是:在全切分所得的所有结果中求某个切分方案S,使得P(S)最大。

可以看到jieba 自带了一些词组,在切分时会从这些词组中为基础单位进行拆分。
注:以上两个技术的原理我只是简单的介绍,如果想彻底搞明白又得写一大篇文章,可以百度下,到处都是,找一篇能看懂的就可以了。如果能用就先用起来。
3、技术分析
中文分词的包最出名的分词包是jieba,至于是不是最好的我也不知道,我想火是有火的道理,先做起来。jieba的原理不用深究,优先解决问题,遇到了问题可以再以问题点进行学习,这样的学习模式才是最高效的。
因为最近在做语音相关的东西,有大佬推荐了库nltk,查阅了相关的资料,似乎是做语言处理方向很出名的库,很强大,功能很强大,我这里主要选择了他的分类算法,这样我就不用关注具体的实现,也不用重复造轮子了,况且还不如别人造的好,拿来用之就好。
python 是真不错,各种包,各种轮子。
安装命令:
pip install jieba
pip install nltk分别输入以上两句代码,等运行完毕后,包就安装成功了,可以开心的测试了
"""
#Author: 香菜
@time: 2021/8/5 0005 下午 10:26
"""
import jieba
if __name__ == '__main__':
result = " | ".join(jieba.cut("我爱北京天安门,very happy"))
print(result)看下分词结果,可以说非常好,果然专业就是专业。

4、源码
简单的测试做了,可以发现我们要完成的基本上都有了,现在开始直接搞代码。
1、加载初始的文本资源。
2、去除文本中的标点符号
3、对文本进行特征提取
4、训练数据集,训练出模型(也就是预测的模型)
5、开始测试新输入的词语
#!/usr/bin/env python
# encoding: utf-8
import re
import jieba
from nltk.classify import NaiveBayesClassifier
"""
#Author: 香菜
@time: 2021/8/5 0005 下午 9:29
"""
rule = re.compile(r"[^a-zA-Z0-9\\u4e00-\\u9fa5]")
def delComa(text):
text = rule.sub('', text)
return text
def loadData(fileName):
text1 = open(fileName, "r", encoding='utf-8').read()
text1 = delComa(text1)
list1 = jieba.cut(text1)
return " ".join(list1)
# 特征提取
def word_feats(words):
return dict([(word, True) for word in words])
if __name__ == '__main__':
adResult = loadData(r"ad.txt")
yellowResult = loadData(r"yellow.txt")
ad_features = [(word_feats(lb), 'ad') for lb in adResult]
yellow_features = [(word_feats(df), 'ye') for df in yellowResult]
train_set = ad_features + yellow_features
# 训练决策
classifier = NaiveBayesClassifier.train(train_set)
# 分析测试
sentence = input("请输入一句话:")
sentence = delComa(sentence)
print("\\n")
seg_list = jieba.cut(sentence)
result1 = " ".join(seg_list)
words = result1.split(" ")
print(words)
# 统计结果
ad = 0
yellow = 0
for word in words:
classResult = classifier.classify(word_feats(word))
if classResult == 'ad':
ad = ad + 1
if classResult == 'ye':
yellow = yellow + 1
# 呈现比例
x = float(str(float(ad) / len(words)))
y = float(str(float(yellow) / len(words)))
print('广告的可能性:%.2f%%' % (x * 100))
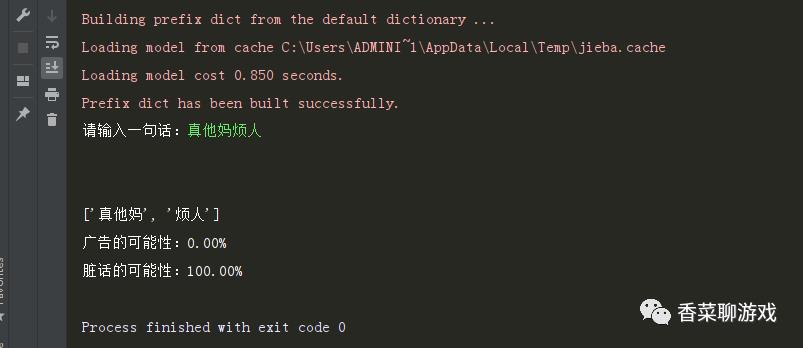
print('脏话的可能性:%.2f%%' % (y * 100))看下运行的结果
所有资源下载地址:https://download.csdn.net/download/perfect2011/20914548
5、扩展
1、数据源可以修改,可以用已经监控的数据存储到数据库中进行加载
2、可以多一些数据分类,方便客服进行处理,比如分为广告,脏话,对官方的建议等等,根据业务需求进行定义
3、可以对概率比较高的数据衔接其他系统进行自动处理,提高处理问题的处理速度
4、可以使用玩家的举报,增加数据的积累
5、可以将这个思想用作敏感词的处理,提供敏感词字典,然后进行匹配,检测
6、可以做成web服务,进行回调游戏
7、可以把模型做成边学习边预测,比如有些案例需要客服手动处理,标记好之后直接加入到数据集中,这样数据模型可以一直学习s
6、遇到的问题
1、遇到的问题,标点符号问题,标点符号如果不去除会导致匹配的时候标点符号也算作匹配,不合理。
2、编码的问题,读出来的是二进制,搞了半天才解决
3、技术选型问题,在最初的时候想用深度学习解决,也看了一些解决方案,奈何自己的电脑训练实在太慢,先选择这样方式练习下
4、代码很简单,但是阐述技术很难,代码早都写好了,但是这篇文章还是过了一个周末才写好
7、总结:
遇到问题就去找技术方案,如果知道方案就去实现,遇到bug就去查,念念不忘必有回响,你的任何一次尝试都是学习的好机会。
原创不易,求个点赞转发,支持一下。
以上是关于《Python实例》震惊了,用Python这么简单实现了聊天系统的脏话,广告检测的主要内容,如果未能解决你的问题,请参考以下文章
震惊!为了欣赏后宫的3000佳丽,我竟然用Python做出了一面墙?