Flume 从0到高手一站式养成记
Posted Amo Xiang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Flume 从0到高手一站式养成记相关的知识,希望对你有一定的参考价值。
文章目录
一、学前必备知识
- 2021年 全网最细大数据学习笔记(一):初识 Hadoop
- 2021年 全网最细大数据学习笔记(二):Hadoop 伪分布式安装
- 2021年 全网最细大数据学习笔记(三):Hadoop 集群的搭建与配置
- 2021年 全网最细大数据学习笔记(四):Hadoop 之 HDFS的基本使用
- 2021年 全网最细大数据学习笔记(五):Zookeeper 集群
- 2021年 全网最细大数据学习笔记(六):Hadoop 之 HDFS 进程详解
二、极速入门 Flume
什么是 Flume? Flume 是一个分布式的、高可靠的、高可用的,将大批量的不同数据源的日志数据收集、聚合、移动到 数据中心(HDFS) 进行存储的系统,即是 日志采集和汇总的工具。
使用 Flume 采集数据不需要写一行代码,注意是一行代码都不需要,只需要在配置文件中随便写几行配置 Flume 就会死心塌地的给你干活了,是不是很香? 它是目前大数据领域数据采集最常用的一个框架。
Flume 的版本变化。 Flume 最初始的发行版本被称为 Flume OG(original generation),属于 Cloudera 公司。但随着 Flume 功能的扩展,Flume OG 代码量臃肿、核心组件设计不合理、核心配置不标准等缺点都暴露了出来,尤其是 Flume OG 的最后一个发行版本 0.9.4 中,日志传输不稳定的现象尤为严重。为了解决这些问题,2011年10月22号,Cloudera 进行了 Flume 新版本的发布,对 Flume 进行了里程碑式的改动:重构核心组件、核心配置以及代码架构,重构后的版本统称为 Flume NG(Next Generation);改名的另一原因是 Flume 纳入了 Apache 公司旗下,Cloudera Flume 改名为 Apache Flume。综上所述,Flume 在 1.x 之前的版本称为 Flume OG,在 1.x 之后的版本称为 Flume NG,这两个版本之间有着较大的架构调整,本章主要介绍的是 Flume NG。
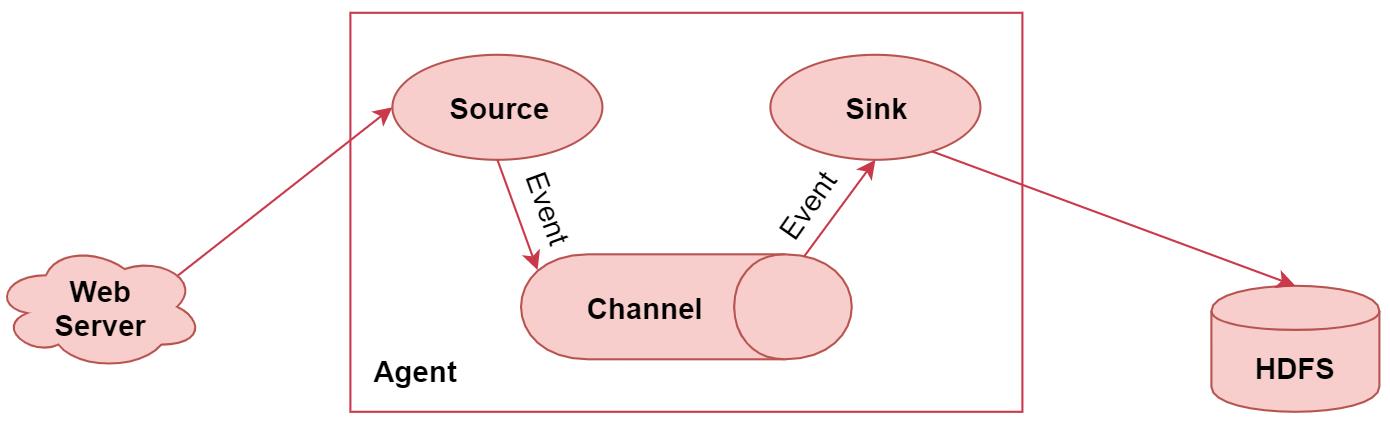
Flume 最基本的结构。 Agent 是 Flume 的运行核心,外部数据进入到 Agent 中,通过 Agent 数据流向另外的地方,下图所示就是一个 Flume 的最基本的结构,只有一个 Agent。
Flume 中概念解析:
(1) Web Server:外部的原始数据,可以是不同渠道的日志数据。
(2) Event:事件,是流经 Flume 的一个数据单元,由消息头、消息体和消息信息组成,其中消息信息就是 Flume 收集到的日志记录,因为原始数据不方便统一处理,所以需要将原始数据转换成事件。在文本文件中,通常一行记录就是一个 Event,Event 由 Header 和 Body 两部分组成,Header 用来存放该 Event 的一些属性,为 K-V 结构,Body 用来存放该条数据,形式为字节数组:

即我们可以在 Source 中给每一条数据的 header 中增加 key-value,在 Channel 和 Sink 中使用 header 中的值了。
(3) Agent:代理,是一个进程承载从外部源事件流到下一个目的地的过程,即一个独立的 Flume 进程,管理 Event 从一个外部源流向外部目标的各组件,组件包含 Source、Channel、Sink。Agent 是 Flume 系统的核心角色,Agent 本身是一个 Java 进程,一般运行在日志收集节点。
(4) Source:数据收集组件,消耗外部传递给它的数据。从外部数据源处收集数据,将接收的数据以 Flume 的 Event 格式传递给一个或者多个 Channel。Flume 提供了各种 Source 的实现,包括 Avro Source、Exce Source、Spooling Directory Source、NetCat Source、Syslog Source、Syslog TCP Source、Syslog UDP Source、HTTP Source、HDFS Source、Kafka Source 等。如果内置的 Source 无法满足需要, Flume 还支持自定义 Source。
Exec Source:实现文件监控,可以实时监控文件中的新增内容,类似于 linux 中的 tail -f 效果。tail -F 和 tail -f 的区别如下:
- tail -F。等同于 -follow=name --retry,根据文件名进行追踪,并保持重试,即该文件被删除或改名后,如果再次创建相同的文件名,会继续追踪。
- tail -f。等同于 -follow=descriptor,根据文件描述符进行追踪,当文件改名或被删除,追踪停止。在实际工作中我们的日志数据一般都会通过 log4j 记录,log4j 产生的日志文件名称是固定的,每天定时给文件重命名。假设默认 log4j 会向 access.log 文件中写日志,每当凌晨0点的时候,log4j 都会对文件进行重命名,在 access 后面添加昨天的日期,然后再创建新的 access.log 记录当天的新增日志数据。这个时候如果想要一直监控 access.log 文件中的新增日志数据的话,就需要使用 tail -F。
NetCat TCP/UDP Source:采集指定端口(tcp、udp)的数据,可以读取流经端口的每一行数据。
Spooling Directory Source:采集文件夹里新增的文件。
Kafka Source:从 Kafka 消息队列中采集数据。
Exec Source 和 Kafka Source 在实际工作中是最常见的,可以满足大部分的数据采集需求。
(5) Channel:数据通道,是中转事件的一个临时存储,保存由 Source 组件传递过来的事件,直到被一个 Sink 消耗。Channel 在 Source 和 Sink 之间连接,起到桥梁的作用。Flume 对于 Channel,则提供了 Memory Channel、JDBC Chanel、File Channel 等技术。
- Memory Channel:可以实现高速的吞吐(效率高、不涉及磁盘IO),但是无法保证数据的完整性,也会存在内存不够用的情况,Memory Channel 在官方文档上已经建议使用 FileChannel 来替换。非常适合需要高吞吐量但一旦失败会丢失数据的场景。
- JDBC Channel:事件被持久存储在可靠的数据库中,如果可恢复性非常的重要可以使用这种方式。
- File Channel:保证数据的完整性与一致性。建议 File Channel 设置的目录和程序日志文件保存的目录设成不同的磁盘,以便提高效率。一般性能会比较低(但是并没有我们想象中的那么慢),但即使程序出错数据也不会丢失。
- Spillable Memory Channel:使用内存和文件作为数据存储,即先把数据存到内存中,如果内存中数据达到阈值再 flush 到文件中。解决了内存不够用的问题,但还是存在数据丢失的风险。
(6) Sink:数据汇聚,代表外部数据存放位置。从 Channel 中读取并移除事件,将事件发送到指定的外部目标(如另一个 Source,也可能是 Hbase、HDFS、Kafka)。Sink 在设置存储数据时,可以向文件系统、数据库、 Hadoop 中储数据。在日志数据较少时,可以将数据存储在文件系中,并且设定一定的时间间隔保存数据。在日志数据较多时,可以将相应的日志数据存储到 Hadoop 中,便于日后进行相应的数据分析。Flume 也提供了各种 Sink 的实现,包括 HDFS Sink、Logger Sink、Avro Sink、File Roll Sink、Null Sink、HBase Sink等。注意:一个 Sink 仅能接收一个 Channel 的事件。
Logger Sink:将数据作为日志处理,可以选择打印到控制台或者写到文件中,这个主要在测试的时候使用。
HDFS Sink:将数据传输到 HDFS 中,这个是比较常见的,主要针对离线计算的场景。
Kafka Sink:将数据发送到 kafka 消息队列中,这个也是比较常见的,主要针对实时计算场景,数据不落盘,实时传输,最后使用实时计算框架直接处理。
(7) Flume 的结构流程为: Source 接收数据,当 Source 捕获数据后会进行特定的格式化,产生事件,然后 Source 会把事件推入(单个或多个)到缓冲区(Channel)中。Channel 将保存事件直到 Sink 处理完该事件,Sink 将事件发送到指定的外部目标。如果把 Flume 比作情报人员,情报人员的工作为:搜集信息、传递信息、记忆信息,即存储信息。那么 Flume 中,Source 实现了搜集信息,Channel 实现了传递信息,Sink 实现了存储信息。
Flume 的其他结构:
Flume 分布式系统中最核心的角色是 Agent,Flume 系统就是由一个个 Agent 所连接起来形成。根据 Flume 中 Agent 的个数,Flume 的体系结构可以有多种,下面分别进行介绍。
- 单一 Agent 结构。单一 Agent 结构即只有一个 Agent 的结构,是 Flume 的最基本的结构在前面已经介绍过,这里不再进行赘述。
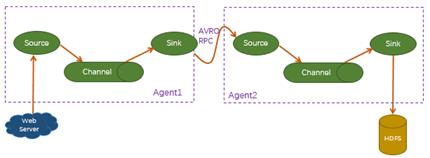
- Agent 的顺序结构。如果有两个 Agent,那么 Flume 的结构如下图所示:
- Agent 的合并结构。如果有多个 Agent 需要连接的话,一般使用合并 Agent 的结构,即多个 Agent 的数据汇聚到同一个 Agent,这种结构如下图所示:
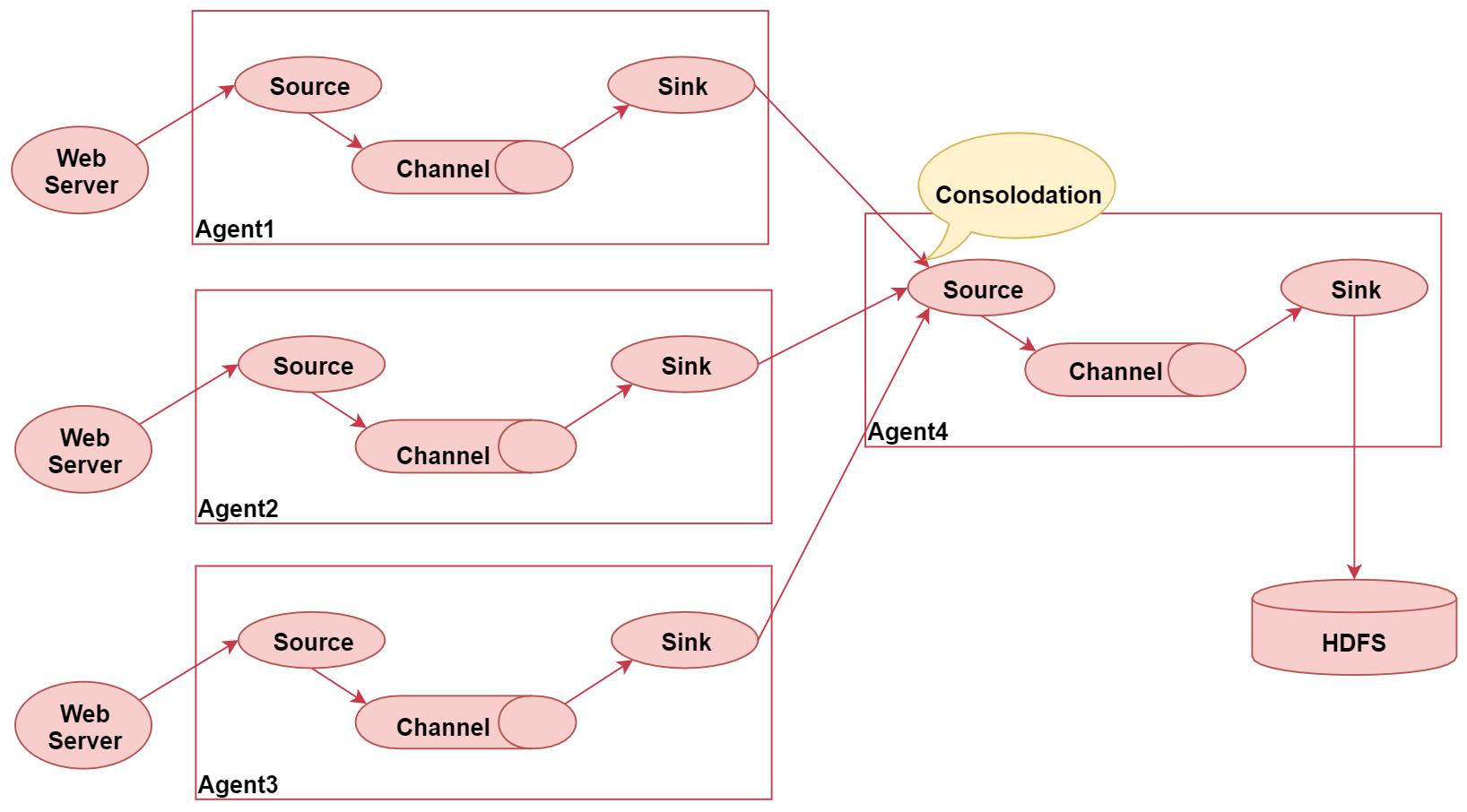
这种连接方式应用的场景比较多,例如要收集 Web 网站的用户行为日志,Web 网站为了可用性所使用的负载集群模式,每个节点都会产生用户行为日志,可以为每个节点都配置一个 Agent 来单独收集日志数据,然后多个 Agent 将数据最终汇聚到一个用来存储数据存储系统,如 HDFS 上。 - Agent 的多路复用结构。Flume 中还支持 Agent 的多路复用结构,当syslog、java、nginx、tomcat 等混合在一起的日志流入一个 Agent 后,可以在 Agent 中将混杂的日志分开,然后给每种日志建立一个自己的传输通道,如下图所示:
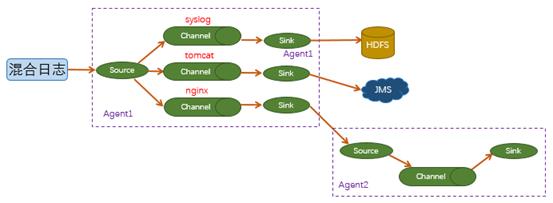
总结: 一个完整的 Flume 是由以下六个模块组成的。
- 外部输入数据。
- Event(事件)。
- Source(数据收集组件)。
- Channel(数据通道)。
- Sink(数据汇聚)。
- 输出数据。
Flume 结构与水槽很类似,如下图所示:
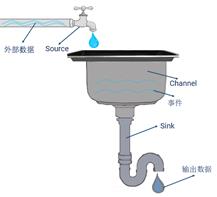
分析一下水槽中各部分的场景对应在 Flume 哪一部分结构。
- 从水厂供到家中的水:外部数据。
- 水龙头:Source。
- 水槽中的盛水盆:Channel。
- 暂存在盛水盆中的水:Event。
- 盛水盆下方的管道:Sink。
- 从管道流出的水:输出数据。
Flume 的特点与优势:
Flume 是一个分布式、可靠和高可用的海量日志采集、聚合和传输的系统,支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume 提供对数据进行简单处理,并写到各种数据接受方(比如文本、HDFS、Hbase等)的能力 。Flume具有以下的特点:
- 可靠性。当节点出现故障时,日志能够被传送到其他节点上而不会丢失。Flume 提供了三种级别的可靠性保障,从强到弱依次分别为:End to End:收到数据 Agent 首先将 Event 写到磁盘上,当数据传送成功后,再删除;如果数据发送失败,可以重新发送。Store on failure:这也是 Scribe(Facebook的开源日志收集系统)采用的策略,当数据接收方宕机时,将数据写到本地,待恢复后,继续发送。Besteffort:数据发送到接收方后,不会进行确认。
- 可扩展性。Flume 中的组件数目可扩展。
- 可管理性。可以动态地增加和删除组件。
- 可恢复性。通道可以用内存或文件的方式实现。内存更快,但是不可恢复;文件比较慢但提供了可恢复性。
Flume 与其他日志收集系统相比,具有以下优势:
- Flume 可以将应用产生的数据存储到任何集中存储器中,比如 HDFS,HBase 等。
- 当收集数据的速度超过将写入数据的时候,也就是当收集信息遇到峰值时,这时候收集的信息非常大,甚至超过了系统的写入数据能力,Flume 会在数据生产者和数据收容器间做出调整,保证其能够在两者之间提供平稳的数据。
- Flume 的管道是基于事务,保证了数据在传送和接收时的一致性。
安装并配置 Flume:
重新克隆一台 Linux 机器,主机名设置为 bigdata04,ip 设置为192.168.182.103,关闭防火墙,安装 jdk 并配置环境变量,因为 Flume 是 java 开发,所以需要依赖 jdk 环境。这些基本配置不会的话,可以查看 2021年 全网最细大数据学习笔记(二):Hadoop 伪分布式安装 一文。
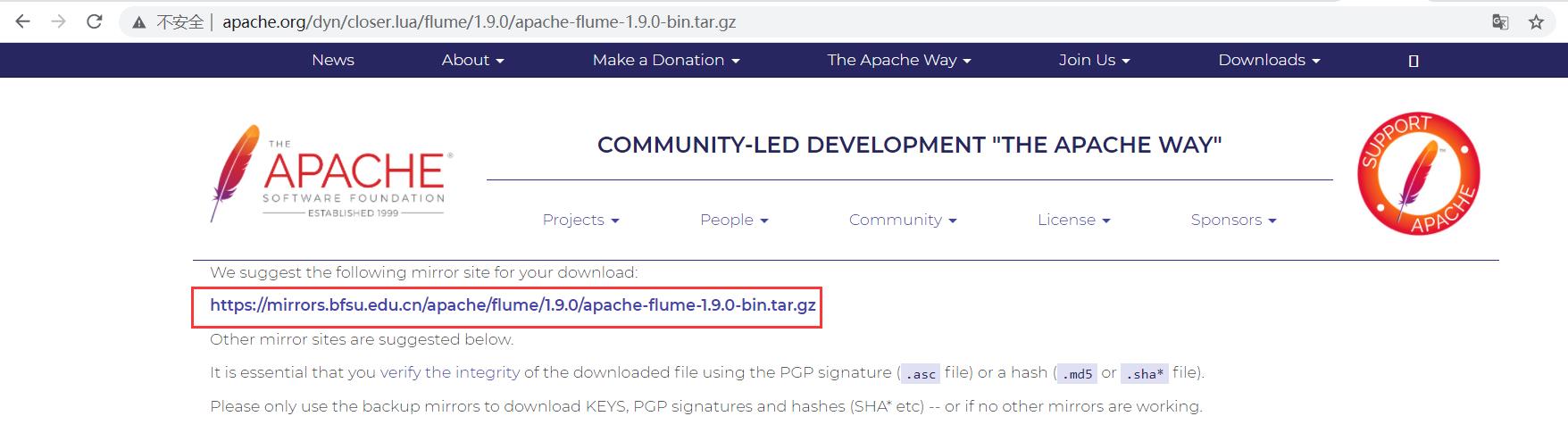
点击 此处 进行下载。Flume 的安装包有两种,一种 xxx-src.tgz,为 Flume 的源代码,需要自行编译安装,较为灵活;另一种 xxx-bin.tar.gz,为已经编译好的,可以直接使用的安装包。这里我们直接选择第二种,已经被编译过的安装包进行下载安装,如下图所示:
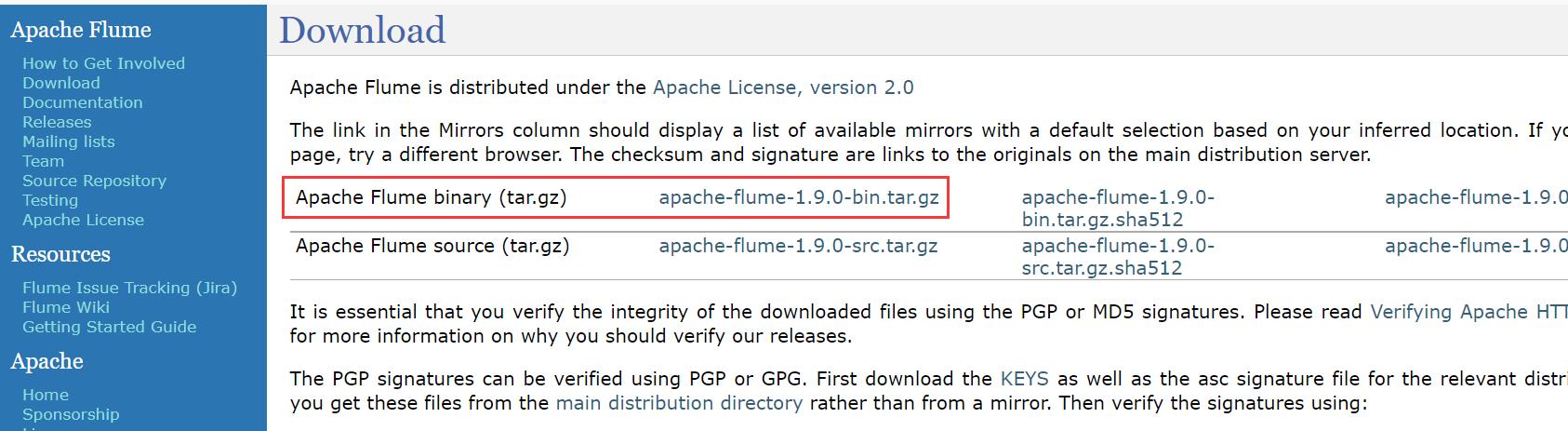
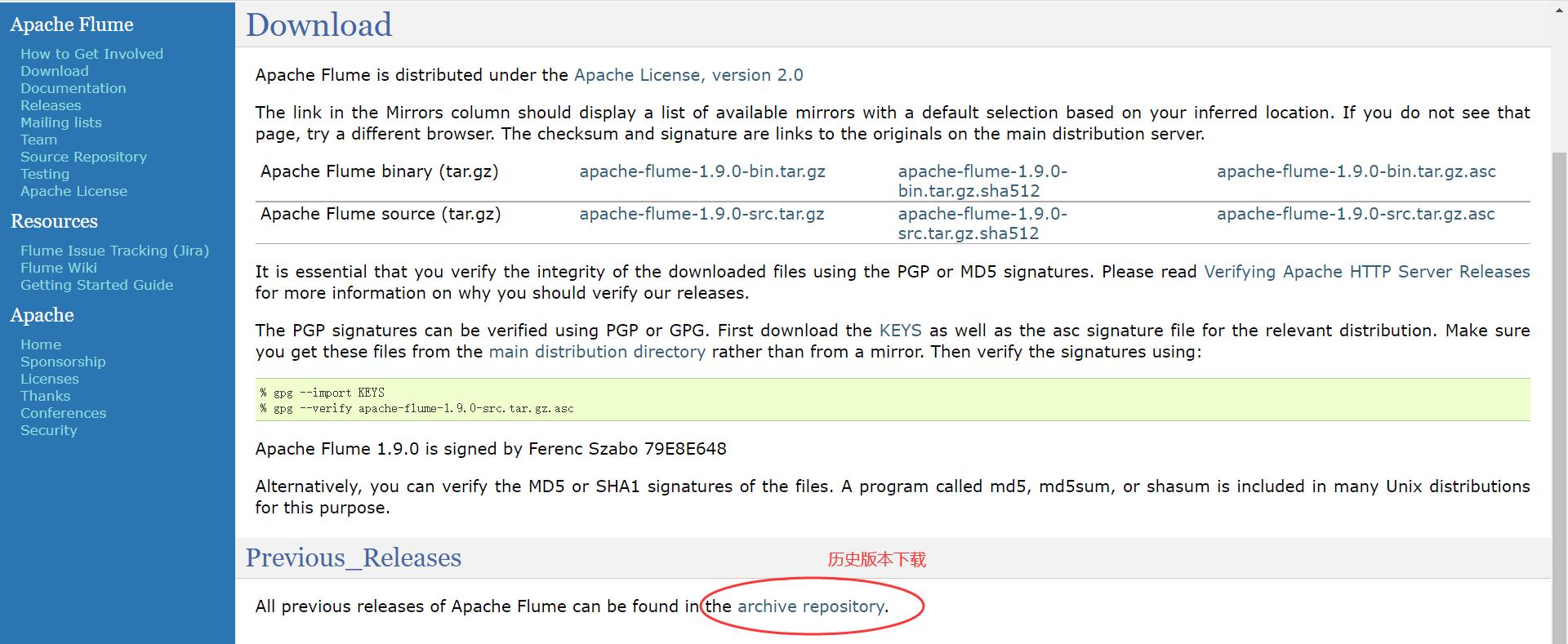
确定了要下载的 Flume 版本之后,单击 apache-flume-1.9.0-bin.tar.gz 链接,进入到下一页面,如下图所示,单击 https://mirrors.bfsu.edu.cn/apache/flume/1.9.0/apache-flume-1.9.0-bin.tar.gz 进行下载。
安装包下载好以后上传到 linux 机器的 /data/soft 目录下,并且解压,如下:
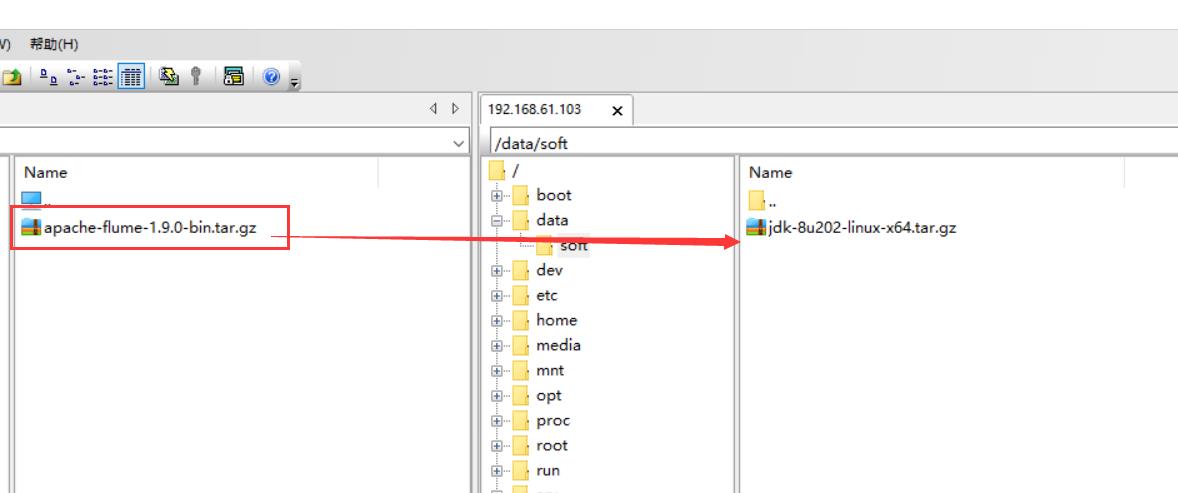
tar -zxvf apache-flume-1.9.0-bin.tar.gz。修改 flume 的 env 环境变量配置文件。在 flume 的 conf 目录下,修改 flume-env.sh.template 的名字,去掉后缀 template,命令:
[root@bigdata04 soft]# ls
apache-flume-1.9.0-bin apache-flume-1.9.0-bin.tar.gz jdk1.8 jdk-8u202-linux-x64.tar.gz
[root@bigdata04 soft]# cd apache-flume-1.9.0-bin
[root@bigdata04 apache-flume-1.9.0-bin]# ls
bin conf doap_Flume.rdf lib NOTICE RELEASE-NOTES
CHANGELOG DEVNOTES docs LICENSE README.md tools
[root@bigdata04 apache-flume-1.9.0-bin]# cd conf/
[root@bigdata04 conf]# mv flume-env.sh.template flume-env.sh
使用命令 vi flume-env.sh(注意先要进入到 conf 目录) 打开 flume-env.sh 文件中添加 JAVA_HOME,如下:
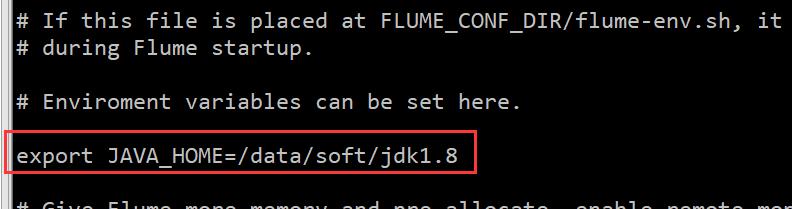
创建 Flume 的软链接的命令:ln -s apache-flume-1.9.0-bin/ flume。修改 .bashrc 文件,vi ~/.bashrc。在文件末尾添加如下代码:
export FLUME_HOME=/data/soft/apache-flume-1.9.0-bin
export PATH=$FLUME_HOME/bin:$PATH
source ~/.bashrc。然后使用 flume-ng version 命令查看 Flume 的版本,如果出现了正确的版本号,则说明 Flume 安装成功,命令如下:
[root@bigdata04 conf]# flume-ng version
Flume 1.9.0
Source code repository: https://git-wip-us.apache.org/repos/asf/flume.git
Revision: d4fcab4f501d41597bc616921329a4339f73585e
Compiled by fszabo on Mon Dec 17 20:45:25 CET 2018
From source with checksum 35db629a3bda49d23e9b3690c80737f9
如果系统里安装了 HBase,就会出现错误:找不到或无法加载主类。解决办法为:进入到 HBase 安装目录的 conf 目录下,打开 hbase-env.sh 文件,将 export HBASE_CLASSPATH.... 的代码前添加一个#,即将此行配置注释掉。注意:如果没有安装 HBase,则不会出现此错误。
三、极速上手 Flume 使用
3.1 案例:Flume 的 Hello World!
先来看一个入门级别的 Hello World 案例。启动 Flume 任务其实就是启动一个 Agent,Agent 是由 source、channel、sink 组成的,这些组件在使用的时候只需要写几行配置就可以了。那 source、channel、sink 该如何配置呢?打开官网,找到左边的 Documentation,查看文档信息:

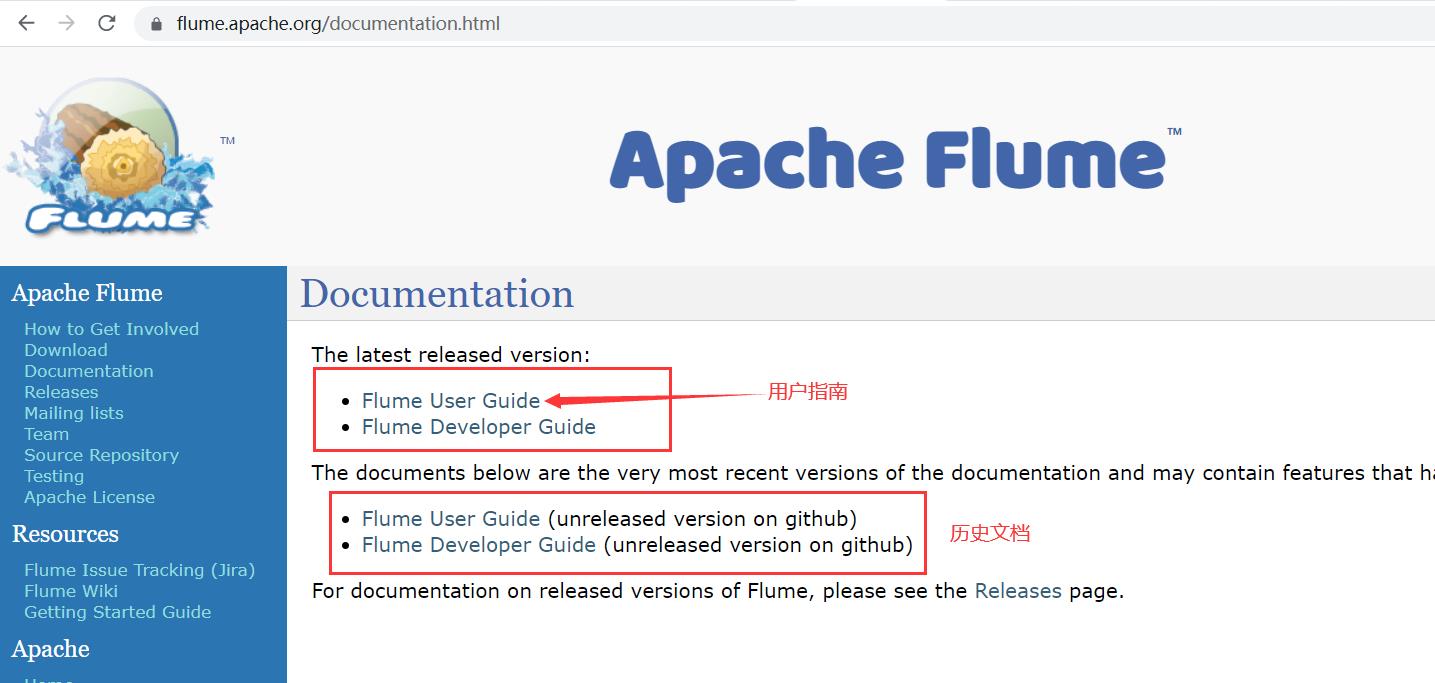
进入 Flume User Guide:
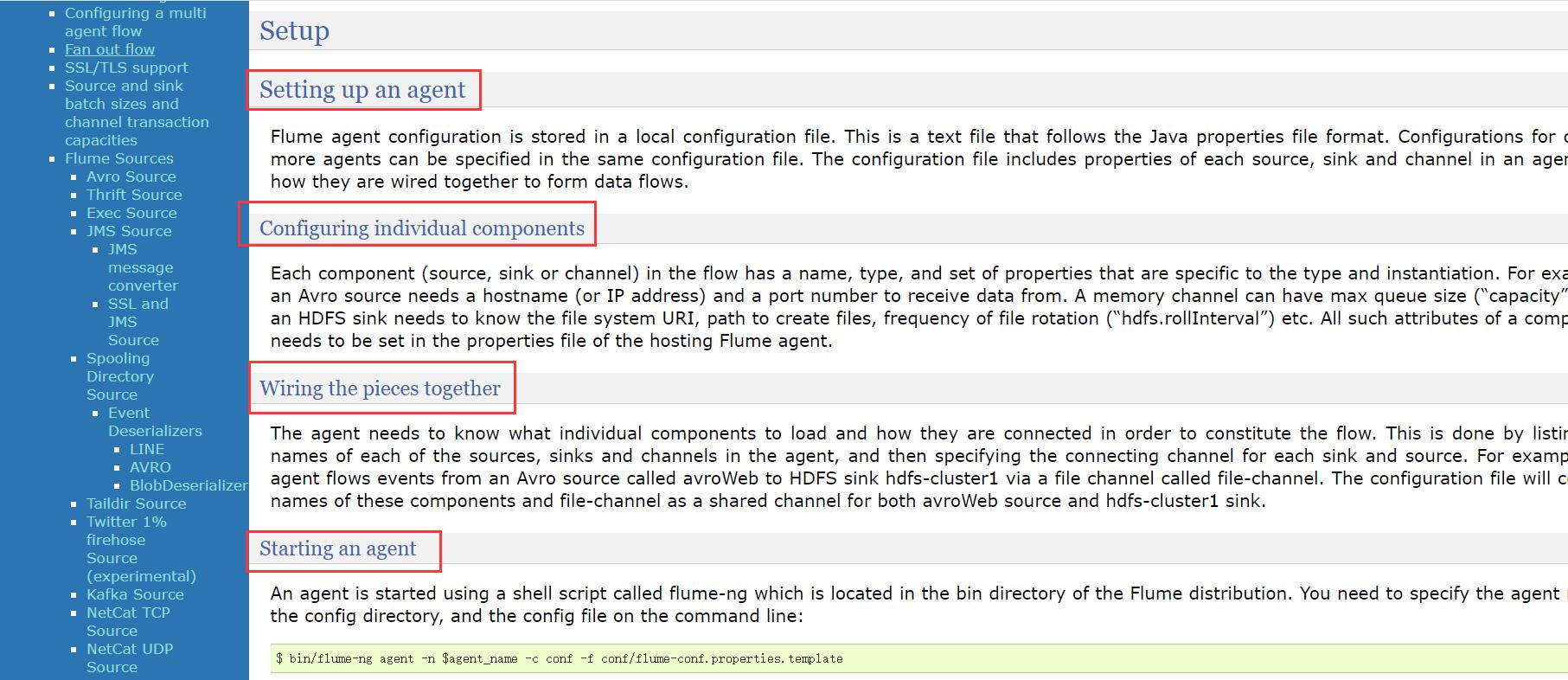
找到下方的一个入门示例,A simple example,Here, we give an example configuration file, describing a single-node Flume deployment. This configuration lets a user generate events and subsequently logs them to the console.
# example.conf: A single-node Flume configuration
# Name the components on this agent 定义三大组件的名称
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source 配置source组件
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
# Describe the sink 配置sink组件
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory 配置和描述Channel组件
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel 将Source和Sink绑定到Channel上面
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
这个例子中首先定义了 source 的名字、sink 的名字还有 channel 的名字,下面配置 source 的相关参数,下面配置了 sink 的相关参数,接着配置了 channel 的相关参数,最后把这三个组件连接到了一起,就是告诉 source 需要向哪个 channel 写入数据,告诉 sink 需要从哪个 channel 读取数据,这样 source、channel、sink 这三个组件就联通了。总结下来,配置 Flume agent 的主要流程是这样的:
- 给每个组件起名字
- 配置每个组件的相关参数
- 把它们联通起来
注意了,在 Agent 中配置的三大组件为什么要这样写呢?如果是第一次使用我也不会写啊。三大组件的配置在文档中是有详细说明的,来看一下,在 Flume Sources 下面显示的都是已经内置支持的 Source 组件:
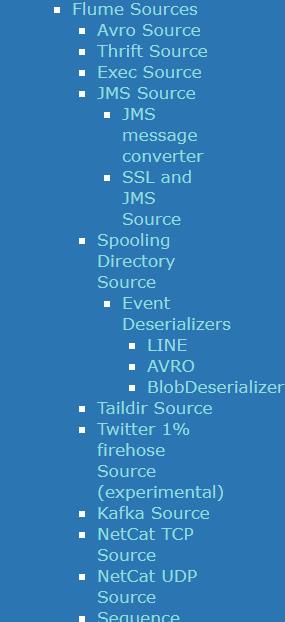
刚才看的案例中使用的是 source 类型是 netcat,其实就是 NetCat TCP Source,看一下详细内容:
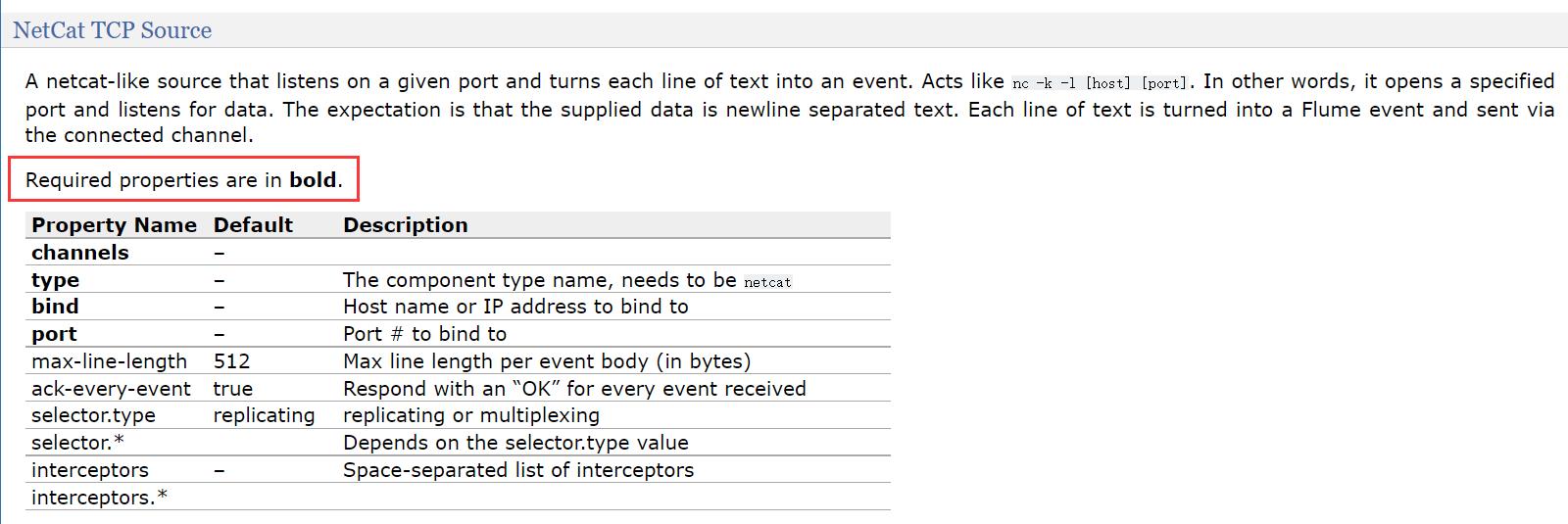
这里面的粗体字体是必选的参数。第一个参数是为了指定 source 需要向哪个 channel 写数据,这个其实是通用的参数,主要看下面这三个,type、bind、port。type:类型需要指定为 natcat,bind:指定当前机器的 ip,使用 hostname 也可以,port:指定当前机器中一个没有被使用的端口。指定 bind 和 port 表示开启监听模式,监听指定 ip 和端口中的数据,其实就是开启了一个 socket 的服务端,等待客户端连接进来写入数据。在这里给 agent 起名为 a1,所以 netcat 类型的配置如下,这里面还指定了 source、channel 的名字,并且把 source 和 channel 连接到一起了,抛开这几个配置之外就剩下了三行配置,就是刚才我们分析的那三个必填参数。
a1.sources = r1
a1.channels = c1
a1.sources.r1.type = netcat
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port = 6666
a1.sources.r1.channels = c1
注意了,bind 参数后面指定的 ip 是四个 0,这个当前机器的通用 ip,因为一台机器可以有多个 ip,例如:内网ip、外网ip,如果通过 bind 参数指定某一个 ip 的话,表示就只监听通过这个 ip 发送过来的数据了,这样会有局限性,所以可以指定 0.0.0.0。下面几个参数都是可选配置,默认可以不配置。接着是 channel,案例中 channel 使用的是 memory。

查看 memory channel:

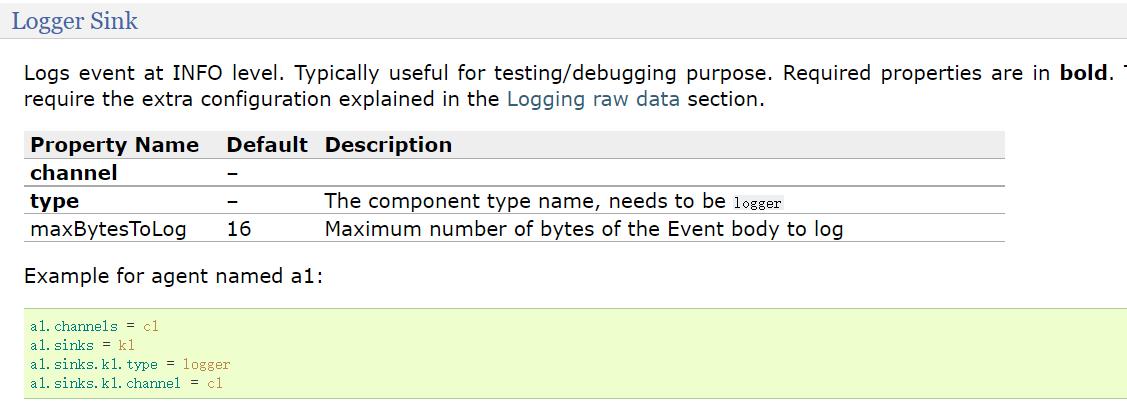
这里面只有 type 是必填项,其他都是可选的。最后看一下 sink,在案例中 sink 使用的是 logger,对应的就是 Logger Sink:

logger sink 中默认也只需要指定 type 即可,
后期我们如果想要使用其他的内置组件,直接到官网文档这里查找即可,这里面的配置有很多,没有必要去记,肯定记不住,只要知道到哪里去找就可以,官网是可以随便使用的,所以建议大家到官网找到配置之后直接拷贝,要不然自己手写很容易出错。配置文件分析完了,可以把这些配置放到一个配置文件中,起名叫 example.conf,把这个配置文件放到 conf/ 目录下。
[root@bigdata04 ~]# cd /data/soft/apache-flume-1.9.0-bin/conf/
[root@bigdata04 conf]# vi example.conf
mple.conf: A single-node Flume configuration
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
# Describe the sink
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
~
"example.conf" 23L, 540C
mple.conf: A single-node Flume configuration
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
# Describe the sink
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
注意了,这个配置文件中的 a1 表示是 agent 的名称,还有就是 port 指定的端口必须是未被使用的,可以先查询一下当前机器使用了哪些端口,端口的可用范围是1-65535,如果懒得去查的话,就尽量使用偏大一些的端口,这样被占用的概率就非常低了。Agent 配置好了以后就可以启动了,下面来看一下启动 Agent 的命令:
[root@bigdata04 conf]# cd ..
[root@bigdata04 apache-flume-1.9.0-bin]# bin/flume-ng agent --name a1 --conf conf --conf-file conf/example.conf -Dflume.root.logger=INFO,console
这里面使用 flume-ng 命令,解释如下:
后面指定 agent,表示启动一个Flume的agent代理
--name:指定 agent 的名字
--conf:指定 flume 配置文件的根目录
--conf-file:指定 Agent 对应的配置文件(包含source、channel、sink配置的文件)
-D:动态添加一些参数,在这里是指定了flume的日志输出级别和输出位置,INFO表示日志级别,console表示是控制台的意思,
也就是说默认会把日志数据打印到控制台上,方便查看,一般在学习测试阶段会指定这个参数
注意了,其实 agent 的启动命令还可以这样写:
bin/flume-ng agent -n $agent_name -c conf -f conf/flume-conf.properties.template
这里面的-n属于简写,完整的写法就是 --name
-c 完整写法的 --conf
-f 完整写法是 --conf-file
所以以后看到这两种写法要知道它们都是正确的写法。启动 Agent,在这里我们使用完整的写法,看起来清晰一些:
[root@bigdata04 apache-flume-1.9.0-bin]# bin/flume-ng agent --name a1 --conf conf --conf-file conf/example.conf -Dflume.root.logger=INFO,console
启动之后会看到如下信息,表示启动成功,启动成功之后,这个窗口会被一直占用,因为 Agent 服务一直在运行,现在属于—个前台进程。
2021-07-03 14:28:14,708 (lifecycleSupervisor-1-0) [INFO - org.apache.flume.source.NetcatSource.start(NetcatSource.java:166)] Created serverSocket:sun.nio.ch.ServerSocketChannelImpl[/127.0.0.1:44444]
如果看到提示的有 ERROR 级别的日志信息,就需要具体问题具体分析了,一般都是配置文件配置错误了。接下来我们需要连接到 source 中通过 netcat 开启的 socket 服务端,克隆一个 bigdata04 的会话,因为前面启动 Agent 之后,窗口就被占用了,使用 telnet命令 可以连接到指定 socket 服务,telnet 后面的主机名和端口是根据 example.conf 配置文件 中配置的。注意:如果提示找不到 telnet 命令,则需要使用 yum 在线安装。
[root@bigdata04 ~]# telnet localhost 44444
Trying ::1...
telnet: connect to address ::1: Connection refused
Trying 127.0.0.1...
Connected to localhost.
Escape character is '^]'.
Hello World!
OK
回到 Agent 所在的窗口,可以看到下面多了一行日志,就是我们在 telnet 中输入的内容:

按 ctrl+c 断开 telnet 连接,重新使用 telnet 连接,此时不使用 localhost,使用本机的内网ip可以吗? 192.168.61.103:
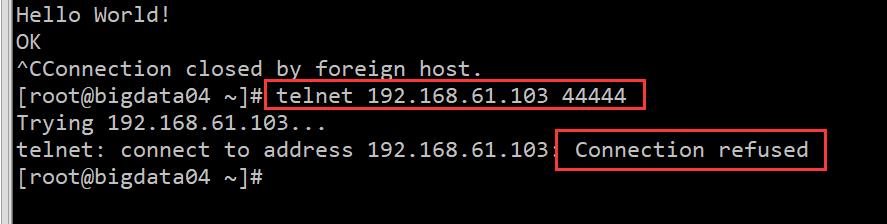
所以此时 Agent 中 source 的配置在使用的时候就受限制了,在开启 telnet 客户端的时候就只能在本地开启了,无法在其他机器上使用,因为 source 中绑定的 ip 是 localhost。如果想要支持一个网络内其它机器上也可以使用 telnet 链接的话就需要修改 bind 参数指定的值了,最直接的就是指定192.168.61.103 这个内网 ip,其实还有一种更加通用的方式是指定 0.0.0.0,此时表示会监听每一个可用的 ip 地址,所以在绑定 ip 端口时,ip 通常都会使用 0.0.0.0,那在这里我们把 example.conf 中的 localhost 改为0.0.0.0,按 ctrl+c 停止刚才启动的 agent。
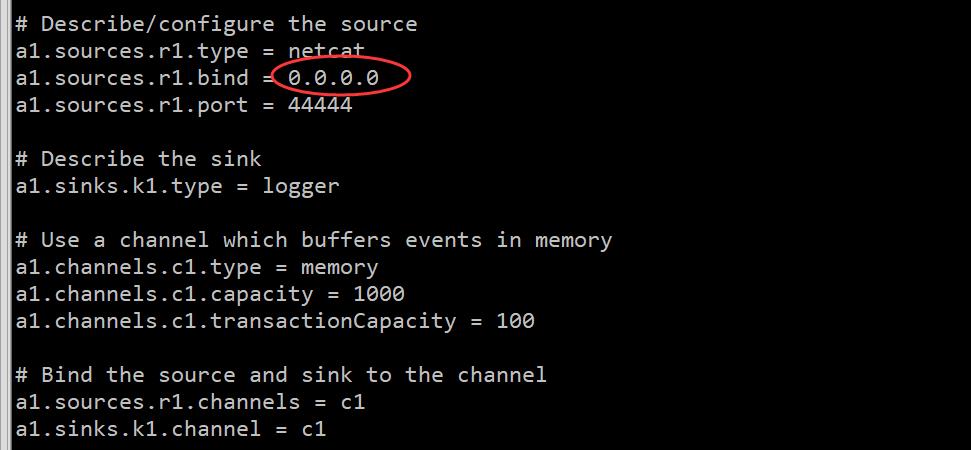
启动 Agent,在另一个会话窗口中使用 telnet 连接,
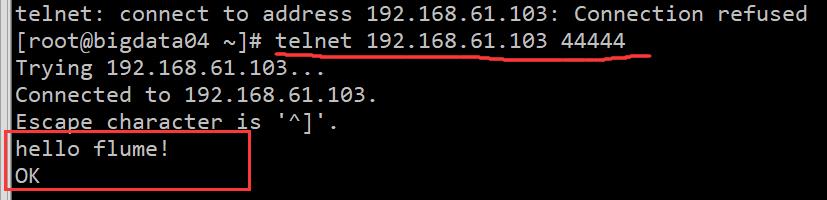
此时可以在其他机器上使用 telnet 连接也可以,在 bigdata01 机器上,
[root@bigdata01 ~]# yum install -y telnet
[root@bigdata01 ~]# telnet 192.168.61.103 44444
Trying 192.168.61.103...
Connected to 192.168.61.103.
Escape character is '^]'.
I am bigdata01
OK
这就是 Flume 中的 Hello World 了。但是注意了,此时 Flume 中 Agent 服务是在前台运行,这个服务实际工作中需要一直运行,所以需要放到后台运行。Flume 自身没有提供直接把进程放到后台执行的参数,需要使用 nohup和& 了。此时就不需要指定 -Dflume.root.logger=lNFO,console 参数了,默认情况下 flume 的日志会记录到日志文件中。停掉之前的 Agent,重新执行。
[root@bigdata04 apache-flume-1.9.0-bin]# nohup bin/flume-ng agent --name a1 --conf conf --conf-file conf/example.conf &
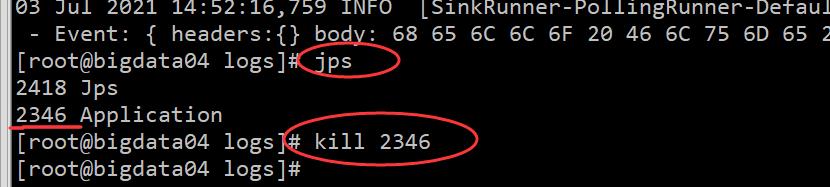
启动之后,通过 jps 命令可以查看到一个 application 进程,这个就是启动的 Agent:

这样看起来不清晰,如果后期启动了多个 Agent,都分不出来哪个是哪个了可以在 jps 后面加上参数 -m,这样可以看到启动时指定的一些参数信息:
[root@bigdata04 apache-flume-1.9.0-bin]# jps -m
2346 Application --name a1 --conf-file conf/example.conf
2395 Jps -m
或者使用 ps 命令也可以:

这个 Agent 中的 sink 组件把数据以日志的方式写出去了,所以这个数据默认就会进入到 flume 的日志文件中,那我们来看一下 flume 的日志文件,在 flume 的 logs 目录中有一个 flume.log:
[root@bigdata04 apache-flume-1.9.0-bin]# cd logs/
[root@bigdata04 logs]# tail -2 flume.log
03 Jul 2021 14:45:54,561 INFO [lifecycleSupervisor-1-0] (org.apache.flume.source.NetcatSource.start:155) - Source starting
03 Jul 2021 14:45:54,563 INFO [lifecycleSupervisor-1-0] (org.apache.flume.source.NetcatSource.start:166) - Created serverSocket:sun.nio.ch.ServerSocketChannelImpl[/0:0:0:0:0:0:0:0:44444]
再使用 telnet 向里面输入一些数据,查看一下日志,可以看到数据,是没有问题的,如果后期发现 Agent 服务突然不干活了,或者对应的进程没有了,就需要到这里来查看日志了。此时想要停止这个 Agent 的话就需要使用 kill 命令了,如下:
3.2 案例:采集文件内容上传至 HDFS
需求: 某服务器的某特定目录下,会不断产生新的文件,每当有新文件出现,就需要把文件中的内容采集到 HDFS 中去。根据需求,首先定义以下 3 大要素。
- 采集源,即 Source——监控文件目录:Spooldir。其作用为,监控一个目录,只要此目录中出现新文件,就会采集文件中的内容。采集完成,文件会被 agent 自动添加一个后缀,即 .COMPLETED,缺点是不支持老文件新增数据的收集。注意:所监控的目录中不允许重复出现相同文件名的文件。
- 下沉目标,即 Sink——HDFS 文件系统: HDFS Sink。
- Source 和 Sink 之间的传递通道——Channel:可用 File Channel 也可以用内存 Channel。
实现: 首先是基于目录的 source,

channels 和 type 肯定是必填的,还有一个是 spoolDir,就是指定一个监控的目录,看它下面的案例,里面还多指定了一个 fileHeader,这个暂时不用,配置 source:
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.c1.type = spooldir
a1.sources.c1.spoolDir = /data/log/studentDir
接下来是 channel 了,channel 在这里使用基于文件的,可以保证数据的安全性。如果针对采集的数据,丢个两条对整体结果影响不大,只要求采集效率,那么这个时候完全可以使用基于内存的 channel,这里使用基于文件的 channel,
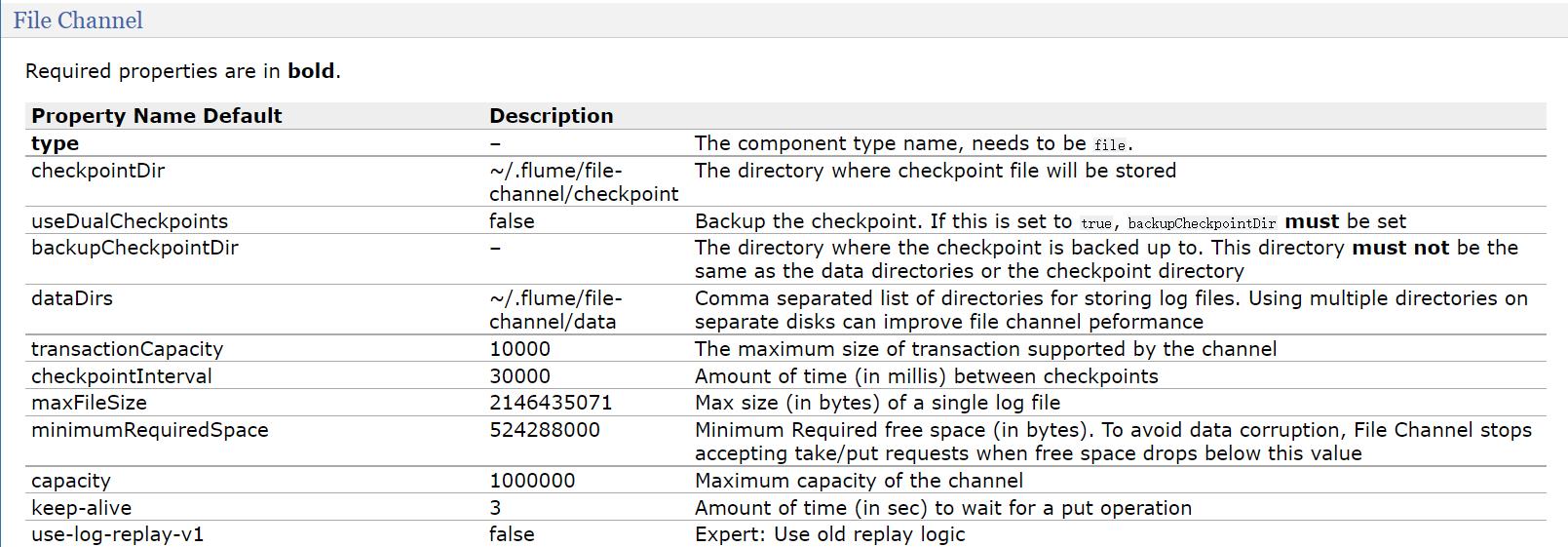
根据这里的例子可知,要配置 checkpointDir 和 dataDir,因为这两个目录默认会在用户家录下生成,建议修改到其他地方,checkpointDir 是存放检查点的目录,data 是存放数据的目录。
a1.channels.c1.type = file
a1.channels.c1.checkpointDir = /data/soft/apache-flume-1.9.0-bin/data/studentDir/checkpoint
a1.channels.c1.dataDirs = /data/soft/apache-flume-1.9.0-bin/data/studentDir/data
最后是 sink,因为要向 hdfs 中输出数据,所以可以使用 hdfs sink。
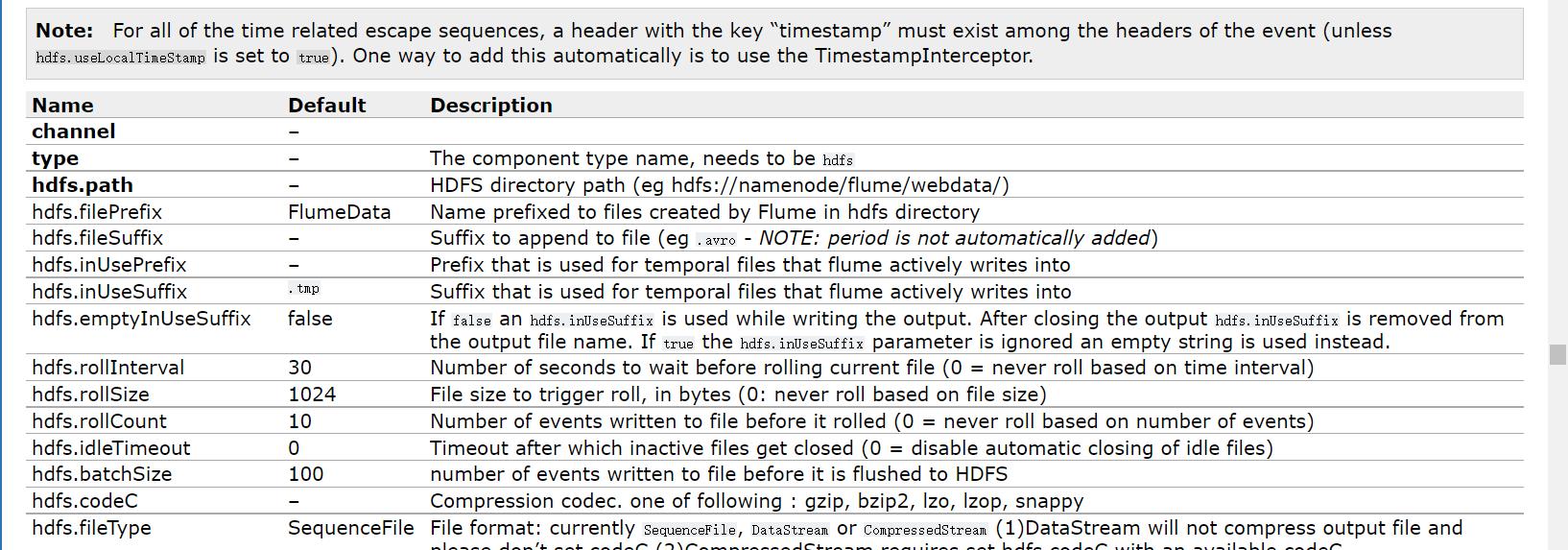
参数解析如下表所示:
| 参数 | 说明 |
|---|---|
| type | Sinks的类型,这里为HDFS,指将数据采集到HDFS中 |
| path | 写入HDFS文件的目录,需要包含文件系统标识,比如:hdfs://namenode/flume/webdata/,使用Flume提供的日期及%{host}表达式 |
| filePrefix | 放置文件的前缀,为access_log。还有fileSuffix参数是设置放置文件的后缀,如.lzo,.log等 |
| maxOpenFiles | 允许打开的HDFS的文件数,当打开的文件数达到该值时,最早打开的文件将会被关闭,默认为5000 |
| batchSize | 每个批次刷新到HDFS上的events数量 |
| fileType | 定义文件格式,包括SequenceFile,DataStream,CompressedStream当使用DataStream时候,文件不会被压缩,不需要设置hdfs.codeC当使用CompressedStream时候,必须设置一个正确的hdfs.codeC值注意:写入的文件和读取的文件类型保持一致 |
| writeFormat | 写sequence文件的格式。包含:Text, Writable(默认) |
| rollSize | 当临时文件达到该大小(单位:bytes)时,滚动成目标文件默认值为1024如果设置成0,则表示不根据临时文件大小来滚动文件 |
| rollCount | 当events数据达到该数量时候,将临时文件滚动成目标文件默认值为10 如果设置成0,则表示不根据events数据来滚动文件 |
| rollInterval | HDFS Sink间隔多长将临时文件滚动成最终目标文件,单位:秒默认值为30如果设置成0,则表示不根据时间来滚动文件注意:滚动(roll)指的是,hdfs sink 将临时文件重命名成最终目标文件,并新打开一个临时文件来写入数据 |
| round | 是否启用时间上的“舍弃”,这里的“舍弃”,类似于“四舍五入”,后面再介绍。如果启用,则会影响除了%t的其他所有时间表达式默认值为false |
| roundValue | 时间上进行“舍弃”的值默认值为1 |
| roundUnit | 时间上进行“舍弃”的单位,包含:second,minute,hour默认值为seconds在这里因为设置的是舍弃10分钟内的时间,因此该目录每10分钟新生成一个 |
| useLocalTimeStamp | 是否使用当地时间默认值为flase |
配置 Sinks,代码如下:
# Describe the sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = hdfs://192.168.61.100:9000/flume/studentDir
a1.sinks.k1.hdfs.filePrefix = stu-
a1.sinks.k1.hdfs.fileType = DataStream
a1.sinks.k1.hdfs.writeFormat = Text
a1.sinks.k1.hdfs.rollInterval = 3600
a1.sinks.k1.hdfs.rollSize = 134217728
a1.sinks.k1.hdfs.rollCount = 0
最后把组件连接到一起:
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
把 Agent 的配置保存到 flume 的 conf 目录下的 file-to-hdfs.conf 文件中:
# example.conf: A single-node Flume configuration
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = spooldir
a1.sources.r1.spoolDir = /data/log/studentDir
# Describe the sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = hdfs://192.168.61.100:9000/flume/studentDir
a1.sinks.k1.hdfs.filePrefix = stu-
a1.sinks.k1.hdfs.fileType = DataStream
a1.sinks.k1.hdfs.writeFormat = Text
a1.sinks.k1.hdfs.rollInterval = 3600
a1.sinks.k1.hdfs.rollSize = 134217728
a1.sinks.k1.hdfs.rollCount = 0
# Use a channel which buffers events in memory
a1.channels.c1.type = file
a1.channels.c1.checkpointDir = /data/soft/apache-flume-1.9.0-bin/data/studentDir/checkpoint
a1.channels.c1.dataDirs = /data/soft/apache-flume-1.9.0-bin/data/studentDir/data
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
下面就可以启动 Agent 了,在启动 Agent 之前,先初始化一下测试数据,创建 /data/log/studentDir 目录,然后在里面添加一个文件,class1.dat,class1.dat 中存储的是学生信息,学生姓名、年龄、性别,如下:
[root@bigdata04 log]# mkdir -p /data/log/studentDir
[root@bigdata04 log]# cd /data/log/studentDir/
[root@bigdata04 studentDir]# vi class1.dat
jack 18 male
jessic 20 female
tom 17 male
paul 25 male
jerry 30 female
[root@bigdata04 studentDir]# more class1.dat
jack 18 male
jessic 20 female
tom 17 male
paul 25 male
jerry 30 female
注意:在开启 Agent 之前,必须首先开启 Hadoop。并且把集群中修改好配置的 hadoop 目录远程拷贝到 bigdata04 上。拷完成之后到 bigdata04 节点上验证一下,如下:
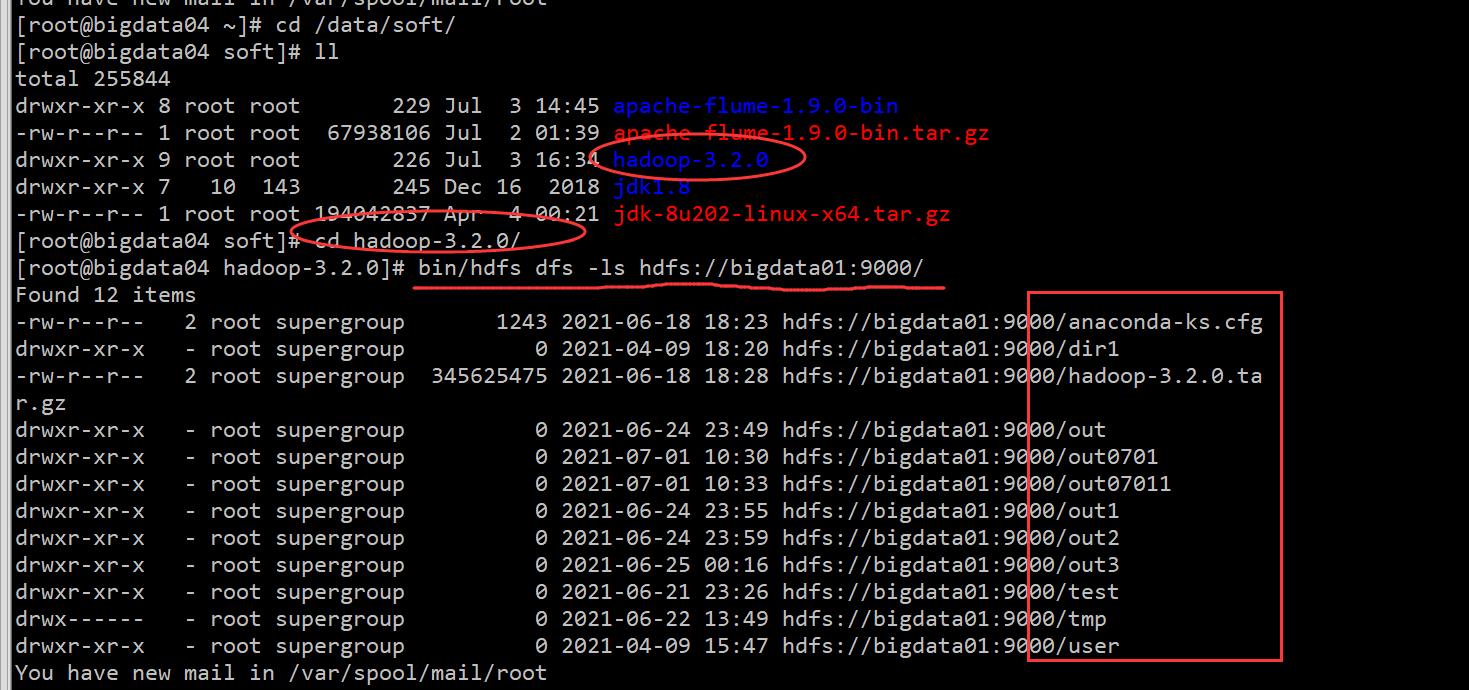
注意:还需要修改环境变量,配置 HADOOP_ HOME,否则启动 Agent 的时候还是会报错。
启动 Agent,此时可以看到 Agent 正常启动,还可以看到类似这样的日志:
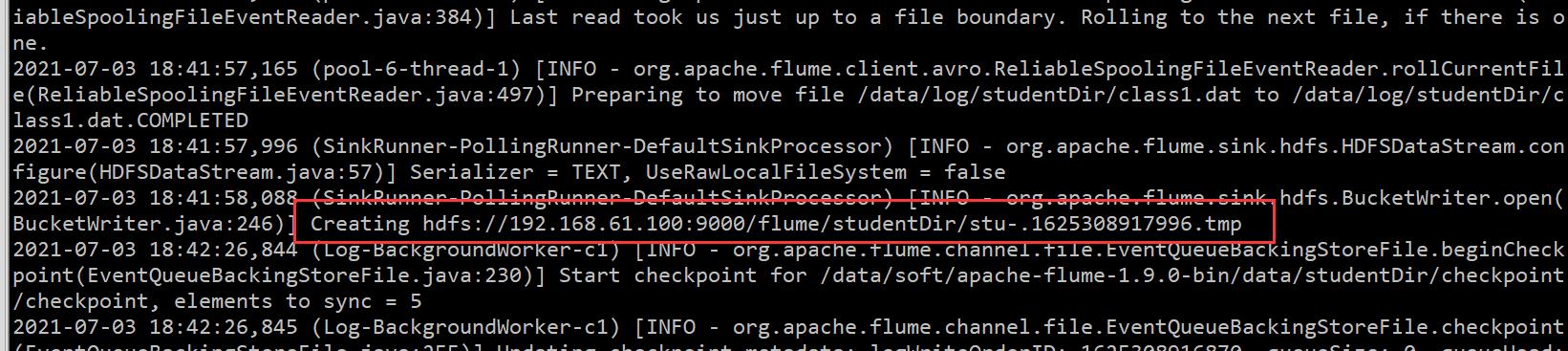
到 hdfs 上验证结果,如下:

此时发现文件已经生成了,只不过默认情况下现在的文件是 .tmp 结尾的,表示它在被使用,因为 Flume 只要采集到数据就会向里面写,这个后缀默认是由 hdfs.inUsesuffix 参数来控制的。文件名上还拼接了一个当前时间戳,这个是默认文件名的格式,当达到文件切割时机的时候会给文件改名字,去掉 .tmp,这个文件现在也是可以查看的,里面的内容其实就是 class1.dat 文件中的内容。如下:

所以此时 Flume 就会监控 linux 中的 /data/log/studentDir 目录,当发现里面有新文件的时候就会把数据采集过来。那 Flume 怎么知道哪些文件是新文件呢?它会不会重复读取同一个文件的数据呢?不会的,我们到 /data/log/studentDir 目录看一 下你就知道了,如下:
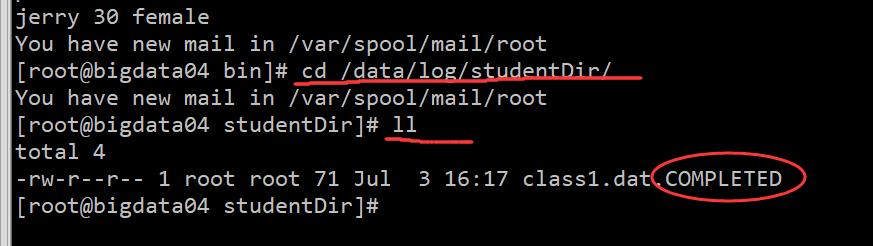
我们发现此时这个文件已经被加了一个后缀 .COMPLETED ,表示这个文件已经被读取过了,所以 Flume 在读取的时候会忽略后缀为 .COMPLETED 的文件。接着我们再看一下 channel 中的数据, 因为数据是存在本地磁盘文件中的,所以是可以去看一下的, 进入 dataDir 指定的目录:
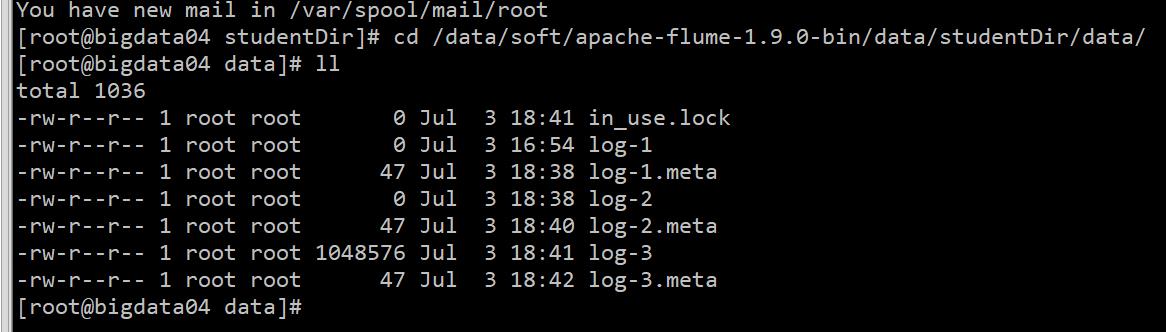
发现里面有类似 log-N 的文件,这个文件中存储的其实就是读取到的内容,不过在这无法直接查看。现在我们想看一下 Flume 最终生成的文件是什么样子的,停止 Agent 就可以看到了(暴力操作),当 Agent 停止的时候就会去掉 .tmp 标志了。

当再重启 Agent 之后,不会再给加上 .tmp 了,每次停止之前都会把所有的文件解除占用状态,下次启动的时候如果有新数据,则会产生新的文件,这其实就模拟了一下自动切文件之后的效果。但是这个文件看起来比较别扭,连个后缀都没有,没有后缀倒不影响使用,就是看起来不好看,大家可以自己去查看官网文档资料,修改 Agent 配置,添加测试数据,验证效果。
3.3 案例:采集网站日志上传至 HDFS
需求: 将 bigdata02 和 bigdata03 两台机器实时产生的日志数据汇总到机器 bigdata04 中,通过机器 bigdata04 将数据统一上传至 HDFS 的指定目录中。看下面这个图,来详细分析一下:
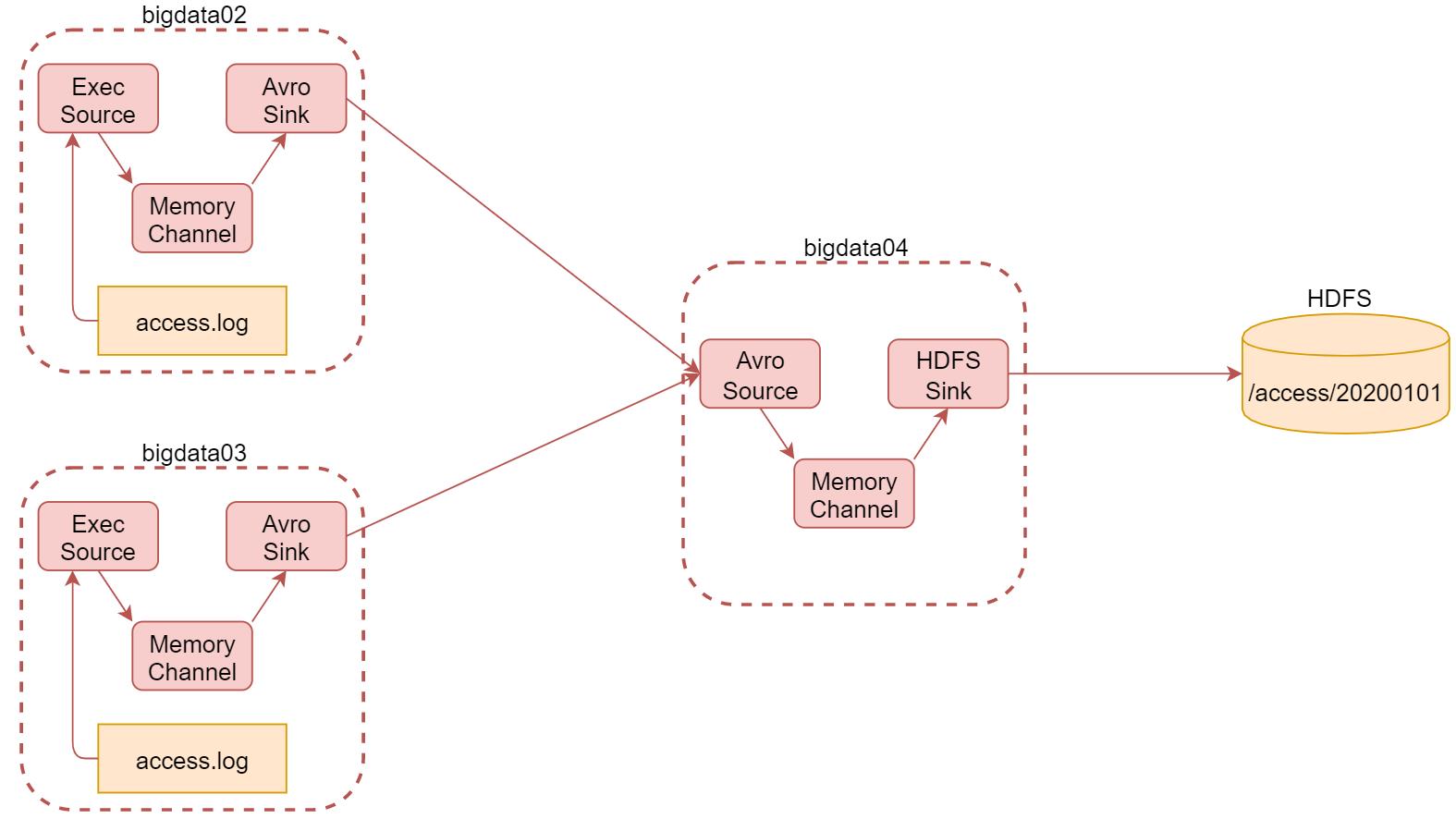
根据刚才的需求分析可知,我们一共需要三台机器,这里使用 bigdata02 和 bigdata03 采集当前机器产生的实时日志数据,统一汇总到 bigdata04 机器上。其中 bigdata02 和 bigdata03 中的 source 使用基于 file 的 source,ExecSource,因为要实时读取文件中的新增数据,channel 在这里我们使用基于内存的 channel,因为这里是采集网站的访问日志,就算丢一两条数据对整体结果影响也不大,我们只希望采集到的数据可以快读进入 hdfs 中,所以就选择了基于内存的 channel。由于 bigdata02 和 bigdata03 的数据需要快速发送到 bigdata04 中,为了快速发送我们可以通过网络直接传输,sink 建议使用 avrosink,avro 是一种数据序列化系统,经过它列化的数据传输起来效率更高,并且它对应的还有一个 avrosource,avrosink 的数据可以直接发送给 avrosource,所以他们可以无缝衔接。这样 bigdata04 的 source 就确定了使用 avrosource、channel 还是基于内存的 channel,sink 就使用 hdfs sink,因为是要向 hdfs 中写数据的。这里面的组件,只有 execsource、 avrosource、 avrosink 在之前还没有使用过, 其他的组件都使用过了。最终需要在每台机器上启动一个 agent,启动的时候需要注意先后顺序,先启动 bigdata04 上面的,再启动 bigdata02 和 bigdata03 上面的。
实现:
(1) 将 bigdata04 中配置好的 apache-flume-1.9.0-bin 安装目录拷贝到 bigdata02 以及 bigdata03 机器上。
[root@bigdata04 soft]# scp -rq apache-flume-1.9.0-bin bigdata02:/data/soft/
[root@bigdata04 soft]# scp -rq apache-flume-1.9.0-bin bigdata03:/data/soft/
(2) 配置 bigdata02 上的 Agent,创建文件 file-to-avro-101.conf:
# agent的名称是a1
# 指定source组件、channel组件和Sink组件的名称
a1.sources = r1
a1.channels = c1
a1.sinks = k1
# 配置source组件
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /data/log/access.log
# 配置channel组件
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# 配置sink组件
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = 192.168.61.103
a1.sinks.k1.port = 45454
# 把组件连接起来
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
这里面的配置没有特殊配置,直接参考官网文档就可以搞定。
(3) 配置 bigdata03 上的 Agent,创建文件 file-to-avro-102.conf:
# agent的名称是a1
# 指定source组件、channel组件和Sink组件的名称
a1.sources = r1
a1.channels = c1
a1.sinks = k1
# 配置source组件
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /data/log/access.log
# 配置channel组件
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# 配置sink组件
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = 192.168.61.103
a1.sinks.k1.port = 45454
# 把组件连接起来
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
(4) 配置 bigdata04 上的 Agent,创建文件 avro-to-hdfs.conf:
# agent的名称是a1
# 指定source组件、channel组件和Sink组件的名称
a1.sources = r1
a1.channels = c1
a1.sinks = k1
# 配置source组件
a1.sources.r1.type = avro
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port = 45454
# 配置channel组件
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# 配置sink组件
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = hdfs://192.168.61.100:9000/access/%Y%m%d
a1.sinks.k1.hdfs.filePrefix = access
a1.sinks.k1.hdfs.fileType = DataStream
a1.sinks.k1.hdfs.writeFormat = Text
a1.sinks.k1.hdfs.rollInterval = 3600
a1.sinks.k1.hdfs.rollSize = 134217728
a1.sinks.k1.hdfs.rollCount = 0
a1.sinks.k1.hdfs.useLocalTimeStamp = true
# 把组件连接起来
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
三台机器中的 Flume Agent 都配置好了,在开始启动之前需要先在 bigdata02 和 bigdata03 中生成测试数据,为了模拟真实情况,在这里我们就开发一个脚本, 定时向文件中写数据:
#!/bin/bash
# 循环向文件中生成数据
while [ "1" = "1" ]
do
# 获取当前时间戳
curr_time=`date +%s`
# 获取当前主机名
name=`hostname`
echo ${name}_${curr_time} >> /data/log/access.log
# 暂停1秒
sleep 1
done
(5) 在 bigdata02 和 bigdata03 中使用这个脚本生成数据,首先在 bigdata02 上创建 /data/log 目录,然后创建 generateAccessLog.sh 脚本,如下:
[root@bigdata02 ~]# mkdir -p /data/log
[root@bigdata02 ~]# cd /data/log/
[root@bigdata02 log]# vi generateAccessLog.sh
同样在 bigdata03 上创建 /data/log 目录,然后创建 generateAccessLog.sh 脚本。接下来开始启动相关的服务进程,首先启动 bigdata04 上的 agent 服务,
bin/flume-ng agent --name a1 --conf conf --conf-file conf/avro-to-hdfs.conf -Dflume.root.logger=INFO,console
接下来启动 bigdata02 上的 agent 服务和 shell 脚本:
bin/flume-ng agent --name a1 --conf conf --conf-file conf/file-to-avro-101.conf -Dflume.root.logger=INFO,console
sh -x generateAccessLog.sh
最后启动 bigdata03 上的 agent 服务和 shell 脚本:
bin/flume-ng agent --name a1 --conf conf --conf-file conf/file-to-avro-102.conf -Dflume.root.logger=INFO,console
sh -x generateAccessLog.sh
验证结果,查看 hdfs 上的结果数据,在 bigdata01 上查看:
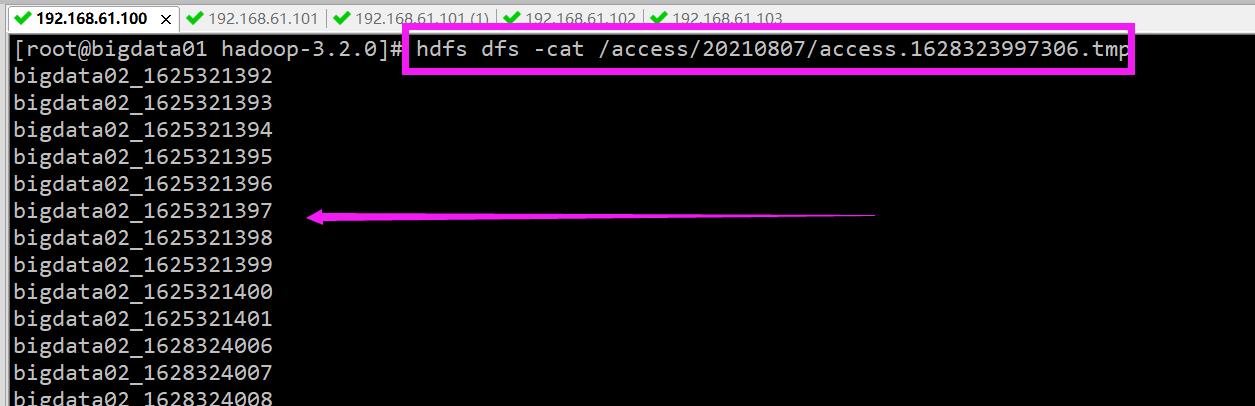
注意:启动之后稍等一会就可以看到数据了,我们观察数据的变化,会发现 hdfs 中数据增长的不是很快,它会每隔一段时间添加一批数据,实时性好像没那么高?这是因为 avrosink 中有一个配置 batch-size,它的默认值是100,也就是每次发送100条数据,如果数据不够100条,则不发送。具体这个值设置多少合适,要看你 source 数据源大致每秒产生多少数据,以及你希望的延迟要达到什么程度,如果这个值设置太小的话,会造成 sink 频繁向外面写数据,这样也会影响性能。最终,依次停止 bigdata02、bigdata03 中的服务,最后停止 bigdata04 中的服务。
四、Flume 高级组件
高级组件:
- Source Interceptors:Source 可以指定一个或者多个拦截器按先后顺序依次对采集到的数据进行处理。
- Channel Selectors:Source 发往多个 Channel 的策略设置,如果 source 后面接了多个 channel,到底是给所有的 channel 都发,还是根据规则发送到不同 channel,这些是由 Channel Selectors 来控制的。
- Sink Processors:Sink 发送数据的策略设置,一个 channel 后面可以接多个 sink,channel 中的数据是被哪个 sink 获取,这个是由 Sink Processors 控制的。
4.1 Source Interceptors
系统中已经内置提供了很多 Source Interceptors,常见的 Source Interceptors 类型:Timestamp Interceptor、Host Interceptor、Search and Replace Interceptor 、Static Interceptor、Regex Extractor Interceptor等。
- Timestamp Interceptor:向 event 中的 header 里面添加 timestamp 时间戳信息。
- Host Interceptor:向 event 中的 header 里面添加 host 属性,host 的值为当前机器的主机名或者ip。
- Search and Replace Interceptor:根据指定的规则查询 Event 中 body 里面的数据,然后进行替换,这个拦截器会修改 event 中 body 的值,也就是会修改原始采集到的数据内容。
- Static Interceptor:向 event 中的 header 里面添加固定的 key 和 value。
- Regex Extractor Interceptor:根据指定的规则从 Event 中的 body 里面抽取数据,生成 key 和 value,再把 key 和 value 添加到 header 中。
根据刚才的分析,总结一下:Timestamp Interceptor、Host Interceptor、Static Interceptor、Regex Extractor Interceptor 是向 event 中的 header 里面添加 key-value 类型的数据,方便后面的 channel 和 sink 组件使用,对采集到的原始数据内容没有任何影响。Search and Replace Interceptor 是会根据规则修改 event 中 body 里面的原始数据内容,对 header 没有任何影响,使用这个拦截器需要特别小心,因为它会修改原始数据内容。这里面这几个拦截器,其中 Search and Replace Interceptor 和 Regex Extractor Interceptor 在工作中使用的比较多一些。下面呢,来看一个案例:对采集到的数据按天按类型分目录存储,原始数据是这样的,看这个文件,Flume测试数据格式.txt:
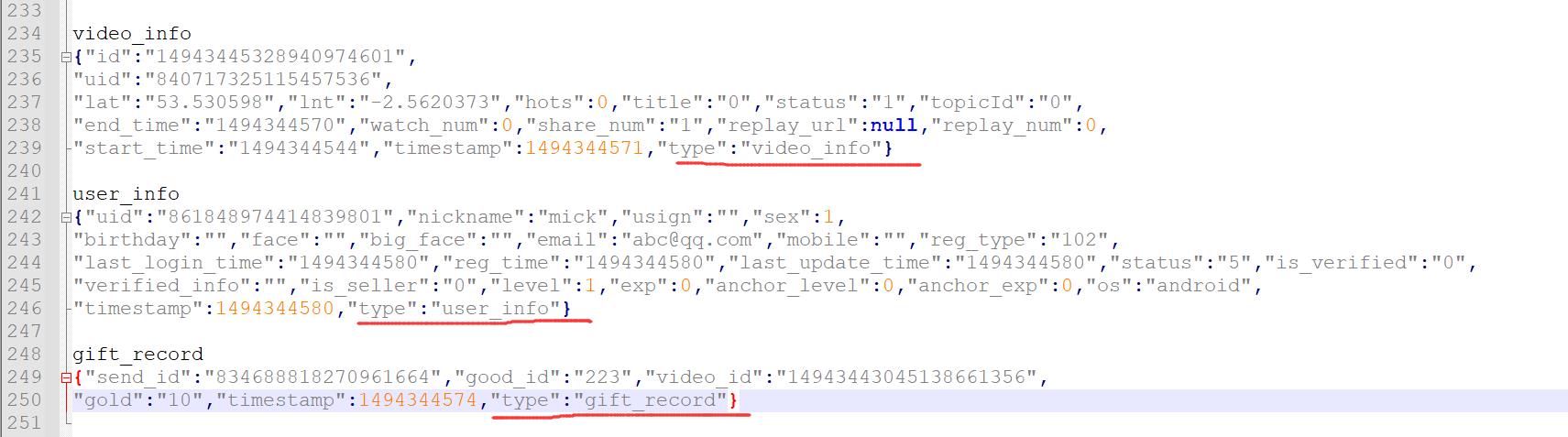
这份数据中有三种类型的数据,视频信息、用户信息、送礼信息,数据都是 json 格式的,这些数据还有一个共性就是里面都有一个 type 字段,type 字段的值代表数据类型,当直播平台正常运行的时候,会实时产生这些日志数据,我们希望把这些数据采集到 hdfs 上进行存储,并且要按照数据类型进行分目录存储,视频数据放一块、用户数据放一块、送礼数据放一块,针对这个需求配置 agent 的话,source 使用基于文件的 execsource、channle 使用基于文件的 channle,我们希望保证数据的完整性和准确性,sink 使用 hdfssink,但是注意了,hdfssink 中的 path 不能写死,首先是按天就是需要动态获取日期,然后是因为不同类型的数据要存储到不同的目录中,那也就意味着 path 路径中肯定要是有变量,除了日期变量还要有数据类型变量,这里的数据类型的格式都是单词中间有一个下划线,但是要求是目录中的单词不要出现下划线,使用驼峰的命名格式。所以最终在 hdfs 中需要生成的目录大致是这样的:
TF Boys (TensorFlow Boys ) 养成记