滴滴出行大数据数仓实战
Posted 大数据Manor
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了滴滴出行大数据数仓实战相关的知识,希望对你有一定的参考价值。
文章目录
大家好,我是ChinaManor,直译过来就是中国码农的意思,我希望自己能成为国家复兴道路的铺路人,大数据领域的耕耘者,平凡但不甘于平庸的人。
前言
作为技术人,我是不怎么八卦的,奈何这次国家重拳整理的是“大数据乱象”,manor作为大数据专业的学生,不得不关注此次的滴滴事件。 滴滴出行APP被下架,此时入职滴滴,好比49年加入国军~
滴滴出行APP被下架,此时入职滴滴,好比49年加入国军~

但是,外面的世界不管怎么变化,掌握好技术是你安身立命的根本,接下来我们就来学习一下:数仓实战项目之滴滴出行
本课程会综合应用HDFS、Hive、SparSQL、Zeppelin、Sqoop、Superset等技术,结合滴滴出行的数据完成数仓实战。
滴滴出行实战需要的技术
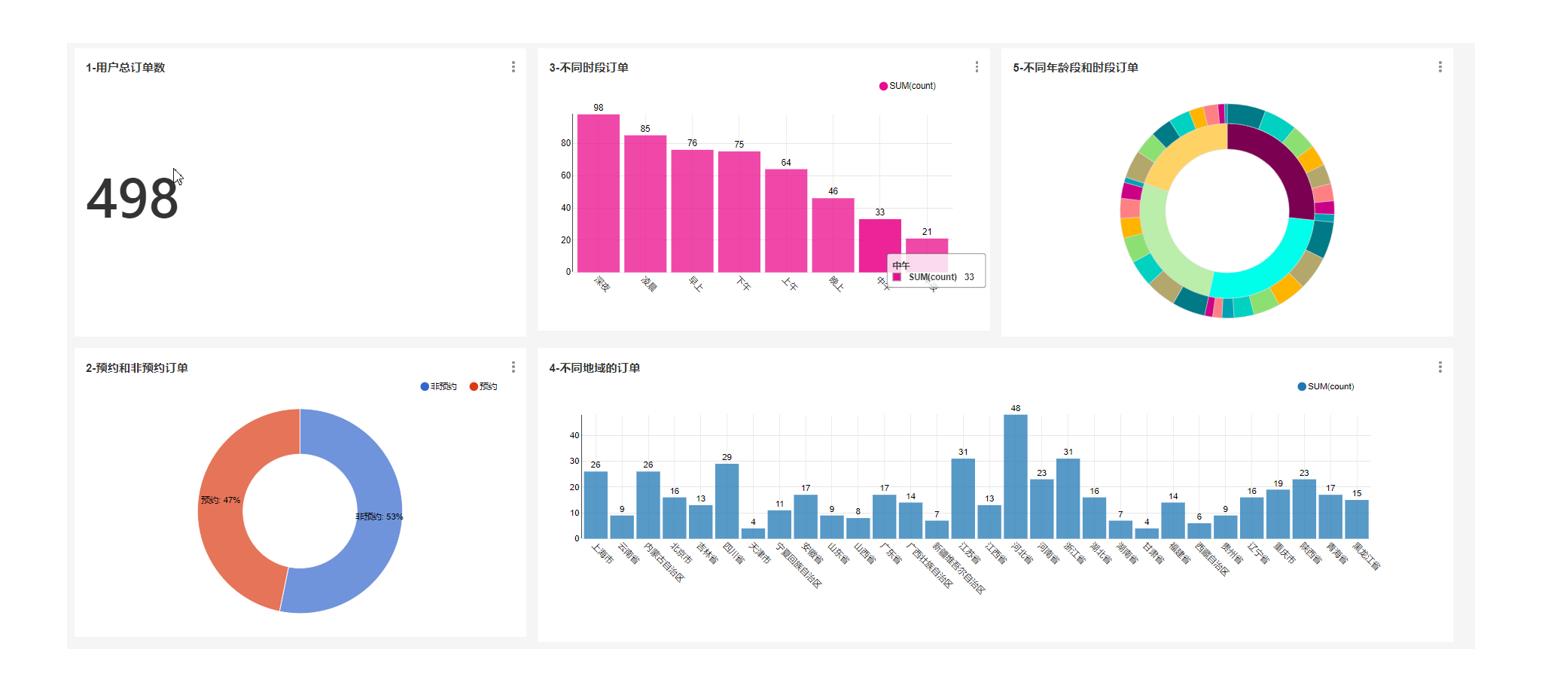
滴滴出行项目可视化
因此,学习本课程,需要你具备以下技术的简单基础技能:
HDFS
Hive
SparSQL
Zeppelin
Sqoop
Superset
该实战项目能够教会你,如何做:
日志数据集
数据仓库构建
数据分区表构建
数据预处理
订单指标分析
Sqoop数据导出
Superset数据可视化
那么如何学习本课呢?
一定要动手实践,在自己的电脑上完成。
接下来就开始学习吧!
1. 业务背景
1.1 业务介绍
滴滴拥有超过4.5亿用户,在中国400多个城市开展服务,每天的订单量高达2500W,每天要处理
的数据量4500TB。仅仅在北京,工作日的早高峰一分钟内就会有超过1600人在使用滴滴打车。通过对这些数据进行分析,了解到不同区域、不同时段运营情况。通过这些出行大数据,还可以看到不同城市的教育、医疗资源的分布,长期观察对城市经济、社会资源的发展、变迁情况,有非常有研究价值。
本次的案例将某出行打车的日志数据来进行数据分析,例如:我们需要统计某一天订单量是多少、
预约订单与非预约订单的占比是多少、不同时段订单占比等。最终效果如下:

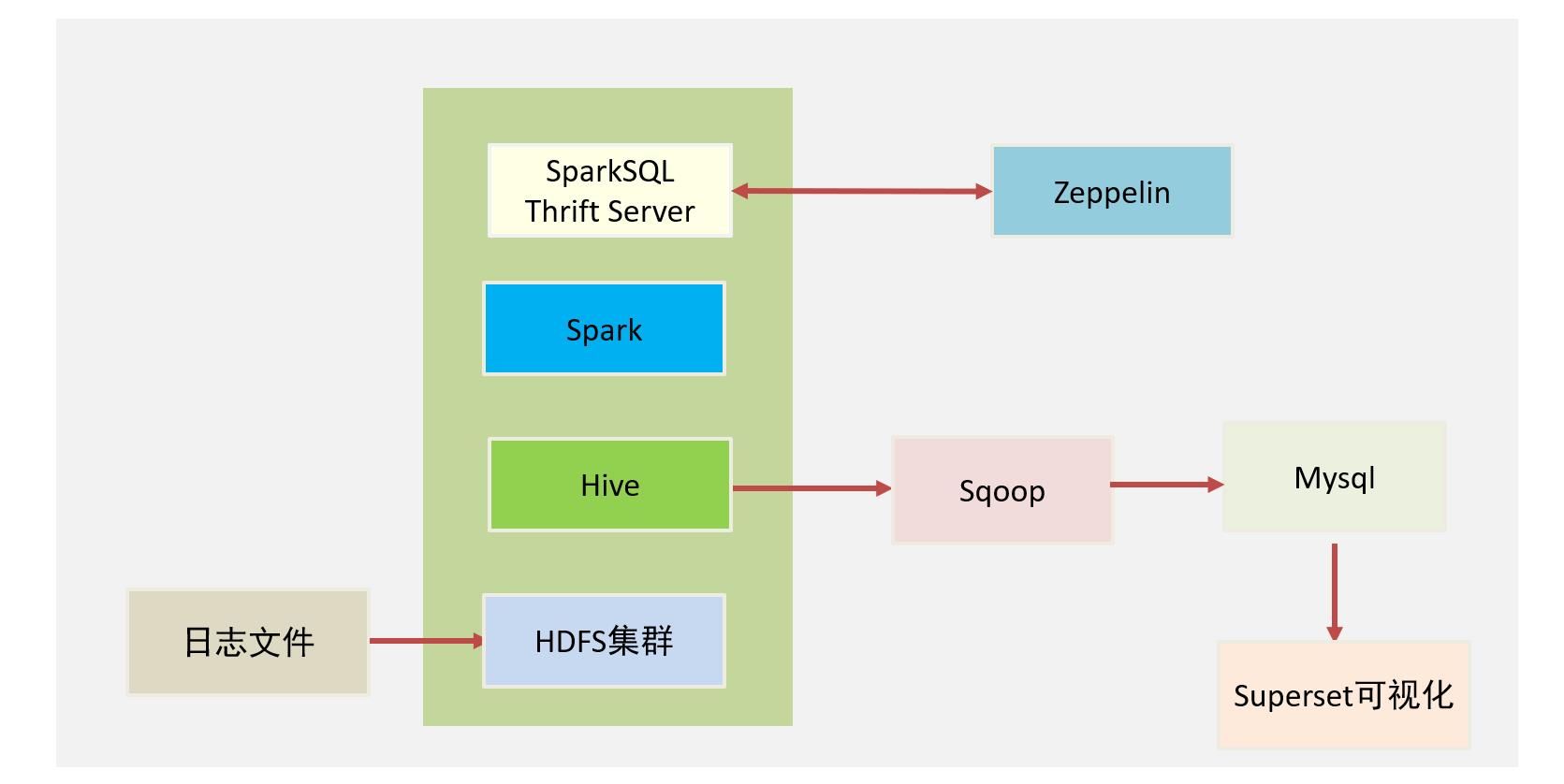
1.2 架构图
要进行大规模数据分析,我们要考虑几个问题:
- 打车的用户量非常庞大,数以亿记的用户将会有海量的数据需要存储。如何保存这些数据呢?
- 为了方便对这些大规模数据进行处理、分析,我们如何建立数据模型,方便进行业务分析呢?
- 亿级的数据如何保证效率,效率分析?
- 数据分析的结果,应该以更易懂的方式呈现出现,如何展示这些数据?
要解决这些问题,我们需要设计一套大数据架构来解决上述问题。
解决方案:
- 用户打车的订单数据非常庞大。所以我们需要选择一个大规模数据的分布式文件系统来存储这些
日志文件,此处,我们基于Hadoop的HDFS文件系统来存储数据。 - 为了方便进行数据分析,我们要将这些日志文件的数据映射为一张一张的表,所以,我们基于
Hive来构建数据仓库。所有的数据,都会在Hive下来几种进行管理。为了提高数据处理的性能。 - 我们将基于Spark引擎来进行数据开发,所有的应用程序都将运行在Spark集群上,这样可以保证
数据被高性能地处理。 - 我们将使用Zeppelin来快速将数据进行可视化展示。

2. 日志数据集介绍
2.1 日志数据文件
我们要处理的数据都是一些文本日志,例如:以下就是一部门用户打车的日志文件。
b05b0034cba34ad4a707b4e67f681c71,15152042581,109.348825,36.068516, 陕 西 省 , 延 安
市,78.2,男,软件工程,70后,4,1,2020-4-12 20:54,0,,2020-4-12 20:06
23b60a8ff11342fcadab3a397356ba33,15152049352,110.231895,36.426178, 陕 西 省 , 延 安
市,19.5,女,金融,80后,3,0,,0,,2020-4-12 4:04
1db33366c0e84f248ade1efba0bb9227,13905224124,115.23596,38.652724, 河北省 , 保 定
市,13.7,男,金融,90后,7,1,2020-4-12 10:10,0,,2020-4-12 0:29
46cfb3c4b94a470792ace0efdd2df11a,13905223853,113.837765,34.743035, 河 南 省 , 郑 州
市,41.9,女,新能源,00后,9,0,,0,,2020-4-12 1:15
878f401c9ca6437585ce1187053c220a,13905223356,113.837765,31.650084, 湖 北 省 , 随 州
市,35.6,男,教育和培训,80后,8,1,2020-4-12 1:06,0,,2020-4-12 4:35
44165cf545734bf6a114aa641479e828,15895252169,109.275236,34.255614, 陕 西 省 , 西 安
市,30.8,女,O2O,90后,8,0,,1,15152049060,2020-4-12 5:07
2.2 用户打车订单日志
每当用户发起打车时,后台系统都会产生一条日志数据,并形成文件。
b05b0034cba34ad4a707b4e67f681c71,15152042581,109.348825,36.068516, 陕西省 , 延 安
市,78.2,男,软件工程,70后,4,1,2020-4-12 20:54,0,,2020-4-12 20:06
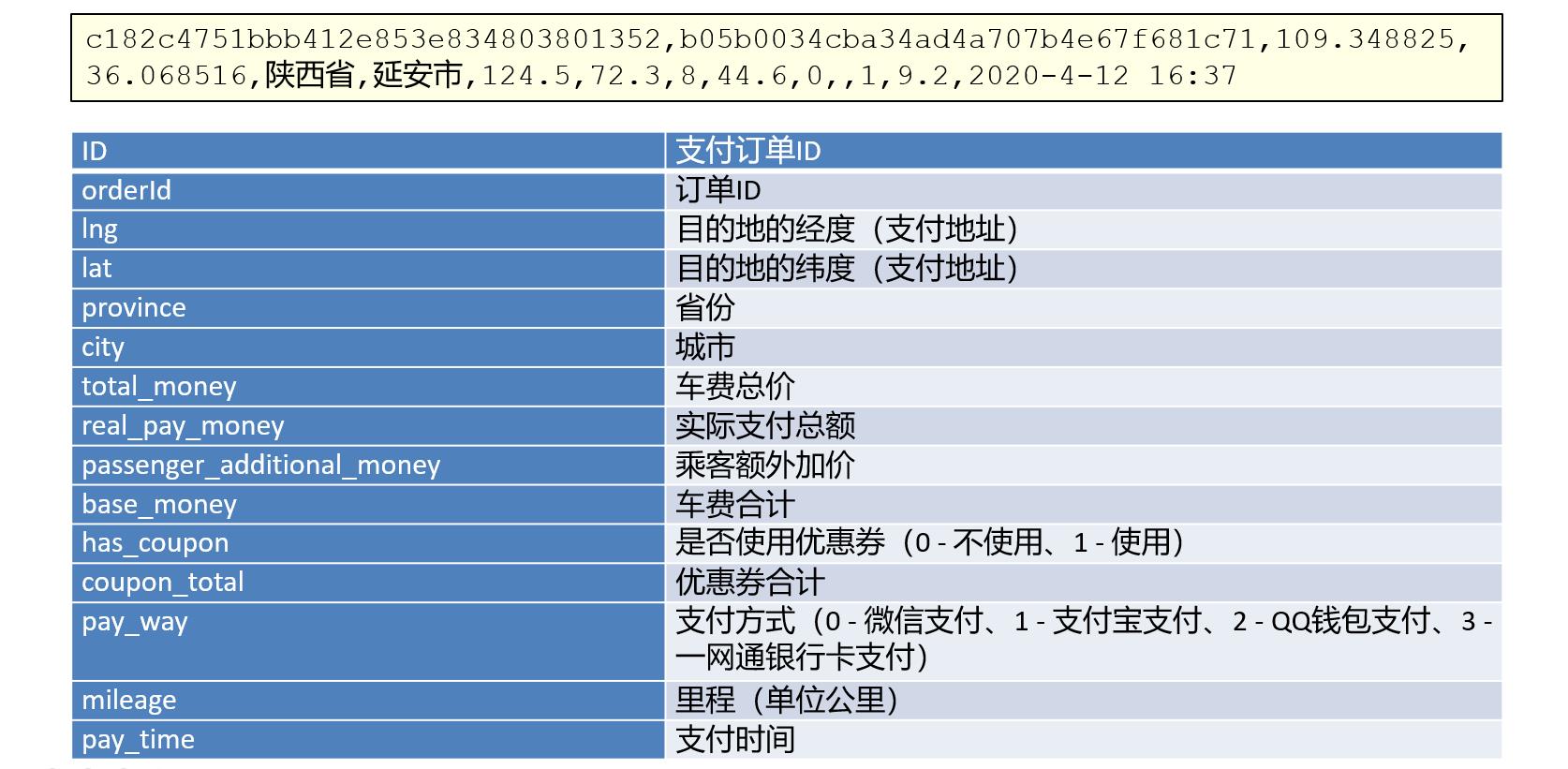
这条日志包含了以下这些字段:
orderId 订单id
telephone 打车用户手机
long 用户发起打车的经度
lat 用户发起打车的纬度
province 所在省份
city 所在城市
es_money 预估打车费用
gender 用户信息 - 性别
profession 用户信息 - 行业
age_range 年龄段(70后、80后、…)
tip 小费
subscribe 是否预约(0 - 非预约、1 - 预约)
sub_time 预约时间
is_agent 是否代叫(0 - 本人、1 - 代叫)
agent_telephone 预约人手机
order_time 订单时间
2.3 用户取消订单日志

当用户取消订单时,也会在系统后台产生一条日志。用户需求选择取消订单的原因。

2.4 用户支付日志
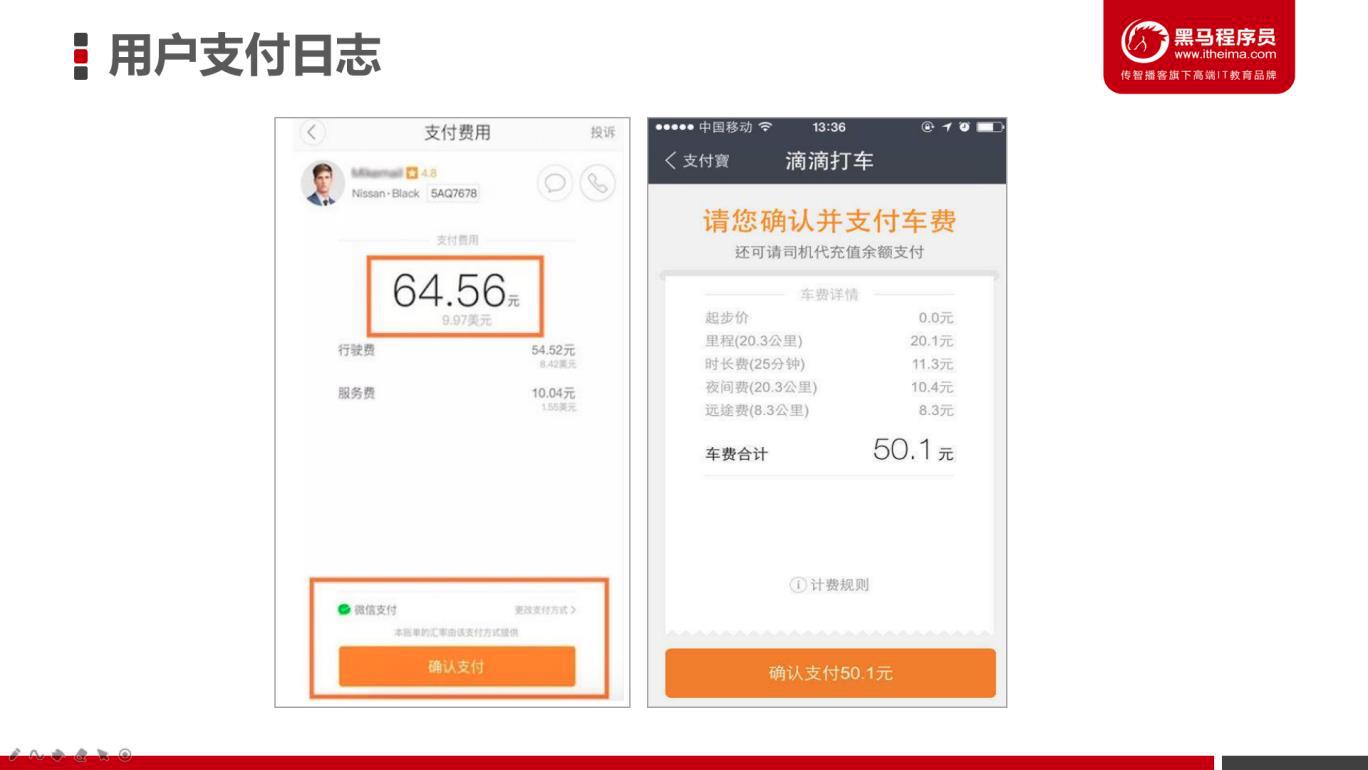
用户点击确认支付后,系统后台会将用户的支持信息保存为一条日志。
2.5 用户评价日志
用户评价日志:用户点击提交评价后,系统后台也会产生一条日志。
用户评价日志数据内容

3. 构建数据仓库
需要对日志文件的原始数据进行预处理,才能进行分析。
有这么几类数据要考虑:
原始日志数据(业务系统中保存的日志文件数据)
预处理后的数据
分析结果数据
这些数据通过Hive来进行处理,因为Hive可以将数据映射为一张张的表,然后就可以通过编写HQL来处理数据了,简单、快捷、高效。为了区分以上这些数据,我们将这些数据对应的表分别保存在不同的数据库中。

接下来就要创建三个数据库,分别用来管理每一层的表数据

在ods数据库中创建三种表单
创建用户打车订单表
创建取消订单表
创建订单表支付表
创建用户评价表
大规模数据的处理,必须要构建分区。
此处的需求每天都会进行数据分析(做的是离线分析),采用T+1的模式。
表加载数据的代码如下

4 数据预处理
预处理的需求

建宽表语句

预处理SQL语句

加载到宽表中

5 订单指标分析
需求:计算4月12日总订单笔数
1.编写HQL语句
select
count(orderid) as total_cnt
from
dw_didi.t_user_order_wide
where
dt = '2020-04-12’
;
- app层建表
-- 创建保存日期对应订单笔数的app表
create table if not exists app_didi.t_order_total(
date string comment '日期(年月日)',
count integer comment '订单笔数'
)
partitioned by (month string comment '年月,yyyy-MM')
row format delimited fields terminated by ','
;
- 加载数据到app表
insert overwrite table app_didi.t_order_total partition(month='2020-04')
select
'2020-04-12',count(orderid) as total_cnt
From dw_didi.t_user_order_wide
Where dt = '2020-04-12';
6 Sqoop数据导出
Apache Sqoop是在Hadoop生态体系和RDBMS体系之间传送数据的一种工具。来自于Apache软件基金会提供。
Hadoop生态系统包括:HDFS、Hive、Hbase等
RDBMS体系包括:mysql、Oracle、DB2等。
Sqoop可以理解为:“SQL 到 Hadoop 和 Hadoop 到SQL”。
-- 创建目标数据库
create database if not exists app_didi;
-- 创建预约订单/非预约订单结果表
CREATE TABLE IF NOT EXISTS app_didi.t_order_subscribe_total(
DATE DATE COMMENT '日期',
subscribe_name VARCHAR(20) COMMENT '是否预约',
COUNT INT COMMENT '订单数量'
);
-- 创建不同时段订单占比分析结果表
CREATE TABLE IF NOT EXISTS app_didi.t_order_timerange_total(
DATE DATE COMMENT '日期',
timerange VARCHAR(20) COMMENT '时间段',
COUNT INTEGER COMMENT '订单数量'
);
-- 创建不同地域订单占比分析结果表
CREATE TABLE IF NOT EXISTS app_didi.t_order_province_total(
DATE DATE COMMENT '日期',
province VARCHAR(20) COMMENT '省份',
COUNT INTEGER COMMENT '订单数量'
);
-- 创建不同年龄段订单占比分析结果表
CREATE TABLE IF NOT EXISTS app_didi.t_order_agerange_total(
DATE DATE COMMENT '日期',
age_range VARCHAR(20) COMMENT '年龄段',
COUNT INTEGER COMMENT '订单数量'
);
7.数据导出操作
将Hive中的结果表导出到Mysql中
(非全部)
#导出订单总笔数表数据
bin/sqoop export \\
--connect jdbc:mysql://192.168.88.100:3306/app_didi \\
--username root \\
--password 123456 \\
--table t_order_total \\
--export-dir /user/hive/warehouse/app_didi.db/t_order_total/month=2020-04
#导出预约和非预约订单统计数据
bin/sqoop export \\
--connect jdbc:mysql://192.168.88.100:3306/app_didi \\
--username root \\
--password 123456 \\
8 Superset数据可视化
Superset是一款开源的现代化企业级BI,是目前开源的数据分析和可视化工具中比较好用的,功能简单但可以满足我们对数据的基本需求,支持多种数据源,图表类型多,易维护,易进行二次开发。
它的特点如下:
1.丰富的数据可视化集
2.易于使用的界面,用于浏览和可视化数据
3.可提供身份验证
在真正开始利用Superset对数据可视化之前,要先将Superset连接据库,又称创建数据源。
实现步骤
1.创建看板
2.设置看板名字
3.进入看板
4.编辑看板
5.选择自定义图表
6.制作看板
7.调整看板位置
至于看板效果呈现,就交给读者自行完成了~~

总结
希望这次国家重拳出击整顿“大数据杀熟”,能够彻底有效,毕竟即便是笔者是学大数据的,如果不多下几个APP比价,也免不了被杀熟。此外,希望通过此次整顿,大数据行业能够更加健康有序发展,这对于我们从业人员也是有好处的,因为大数据技术的出现并不全是坏处,前不久的疫情严重时,健康码,快速检测过关都有大数据在背后做支撑,使用“大数据”利剑并没有错,错的是使用在什么地方,真心祝愿技术都能用在有益于全人类的地方。
要下的配套资料,已经上传到百度网盘好了
关注之后,私信我免费获取!
为了涨粉也是拼了~
ps:资料已同步更新到 微信公众号:大数据智能ai

以上是关于滴滴出行大数据数仓实战的主要内容,如果未能解决你的问题,请参考以下文章
滴滴出行-杭州职位:实时计算工程师/golang开发专家(分布式存储)/前端Leader/高级java专家/数据仓库专家