最为详细的卷积神经网络笔记--吴恩达深度学习课程笔记
Posted 无乎648
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了最为详细的卷积神经网络笔记--吴恩达深度学习课程笔记相关的知识,希望对你有一定的参考价值。
卷积神经网络(三)
三.目标检测
3.1 目标定位
对于分类定位问题,通常只有一个较大的物体在图片的中央,我们需要识别该物体的类别并标记物体的位置。而对象检测问题在一张图片中可能会有多个不同类别的对象,我们需要识别各个物体的类别并标记位置。具体如下图:
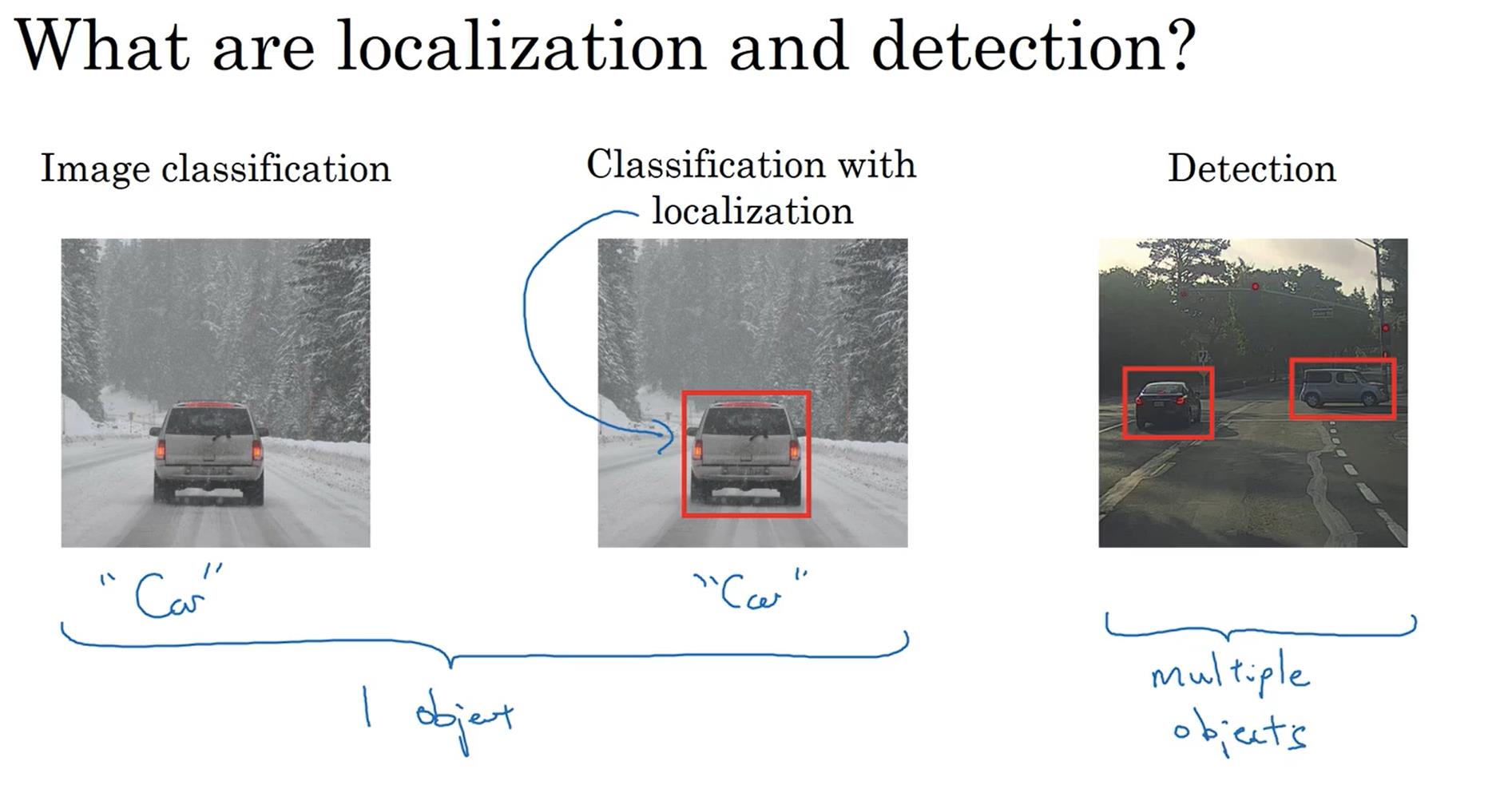
对于目标定位问题,我们通常要输出该物体的类别以及物体中心点的坐标和宽高。
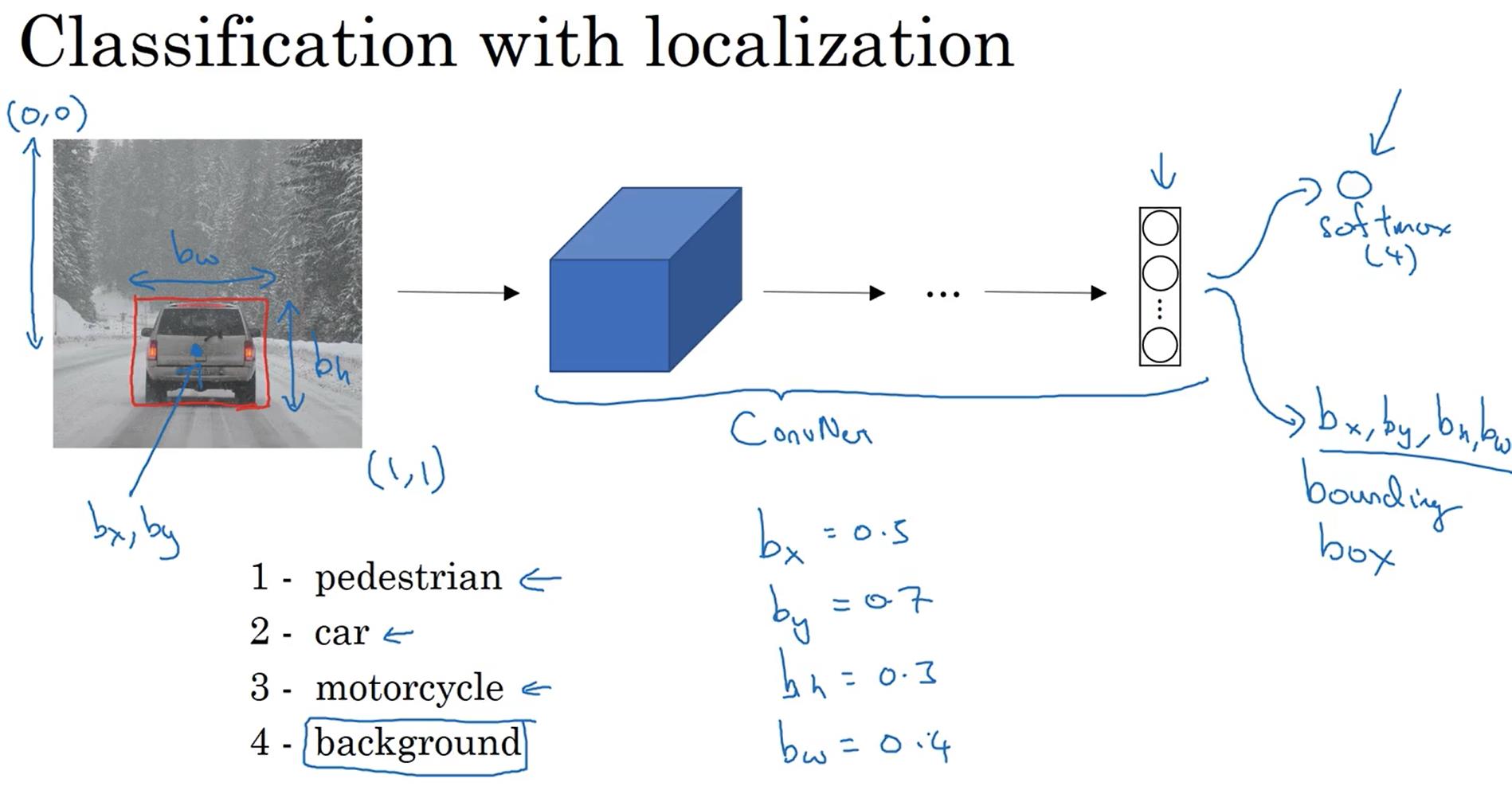
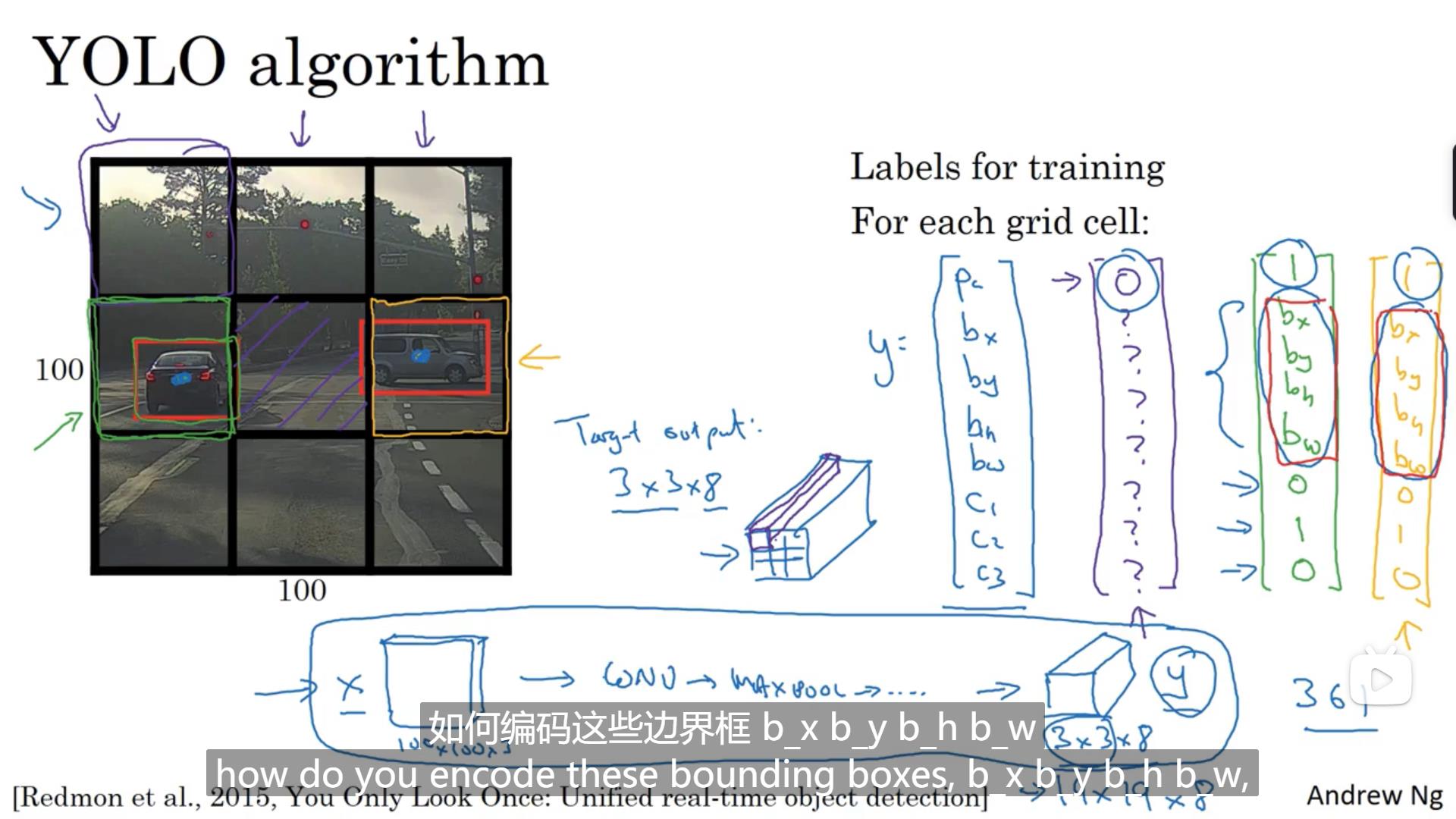
该目标定位神经网络要输出8个值,分别是图中是否有目标对象(pc)、目标对象的坐标(bx、by)、目标对象的宽和高(bh、bw)和三种类别物体的可能性(c1、c2、c3)。当pc=1时,下面7个值是有效的;当pc=0时,下面7个值是无效的。所以这也就对应着两种代价函数的计算公式,这里代价函数使用的是平方差。
3.2 特征点检测
如果我们想要做人脸识别或者人体姿态检测,我们可以人为设置一些特征点,在训练集上标记处特征点的位置用来训练,这样在输出时就可以输出标记点的位置,要注意训练集上标记点要前后一致。
3.3 目标检测
这里介绍的是基于滑动窗口的目标检测方法。训练集是类似于图像分类的,标记图片中是否有汽车。
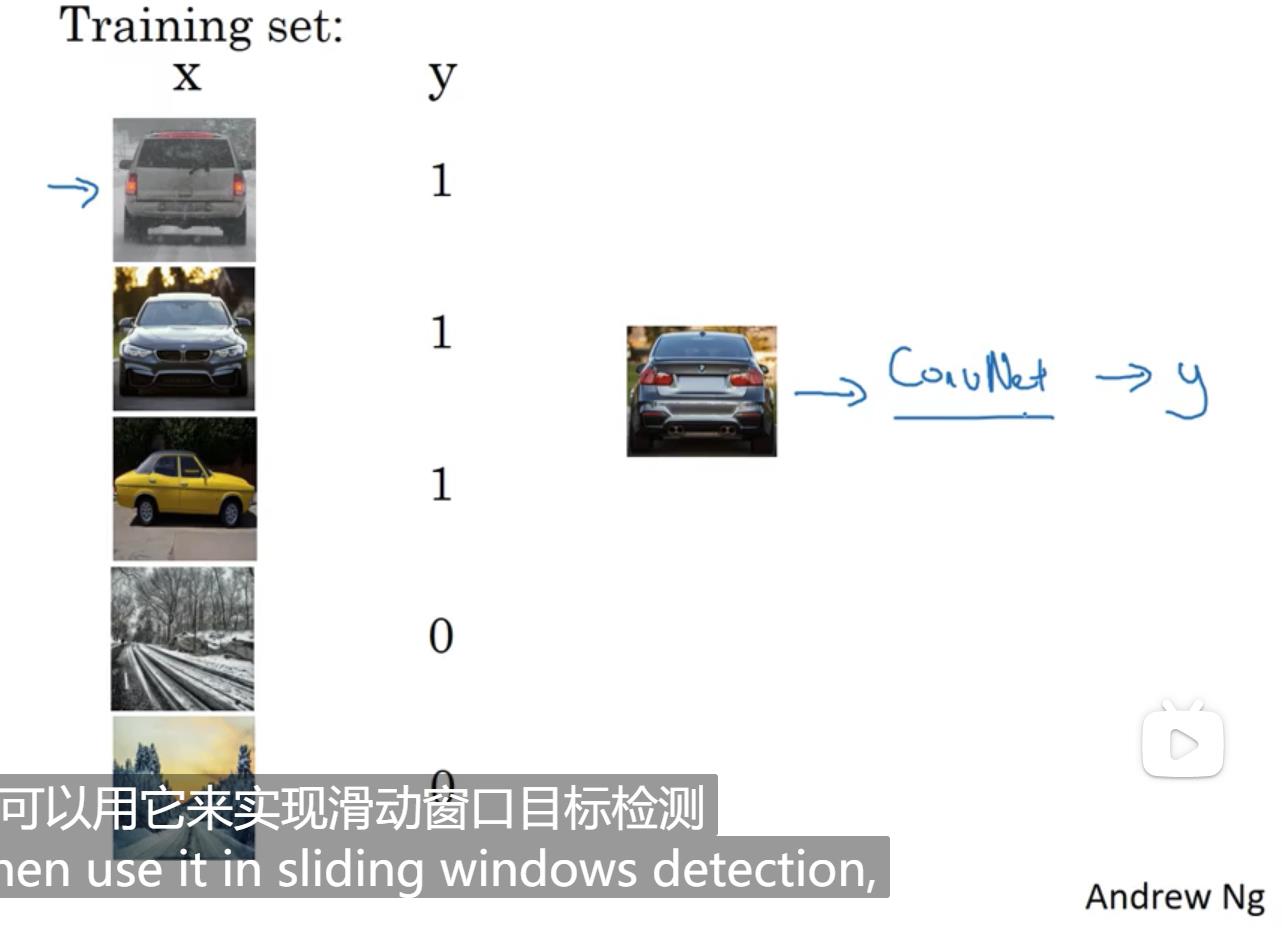
具体检测时是选定一个检测窗口大小以及步长,然后从图片的左上角开始依次将检测窗口中的图像输入到网络中。这种检测方法存在问题:当选择的步长过大时,检测效果可能不是很好,但当步长过小时,需要的运算量会很大。

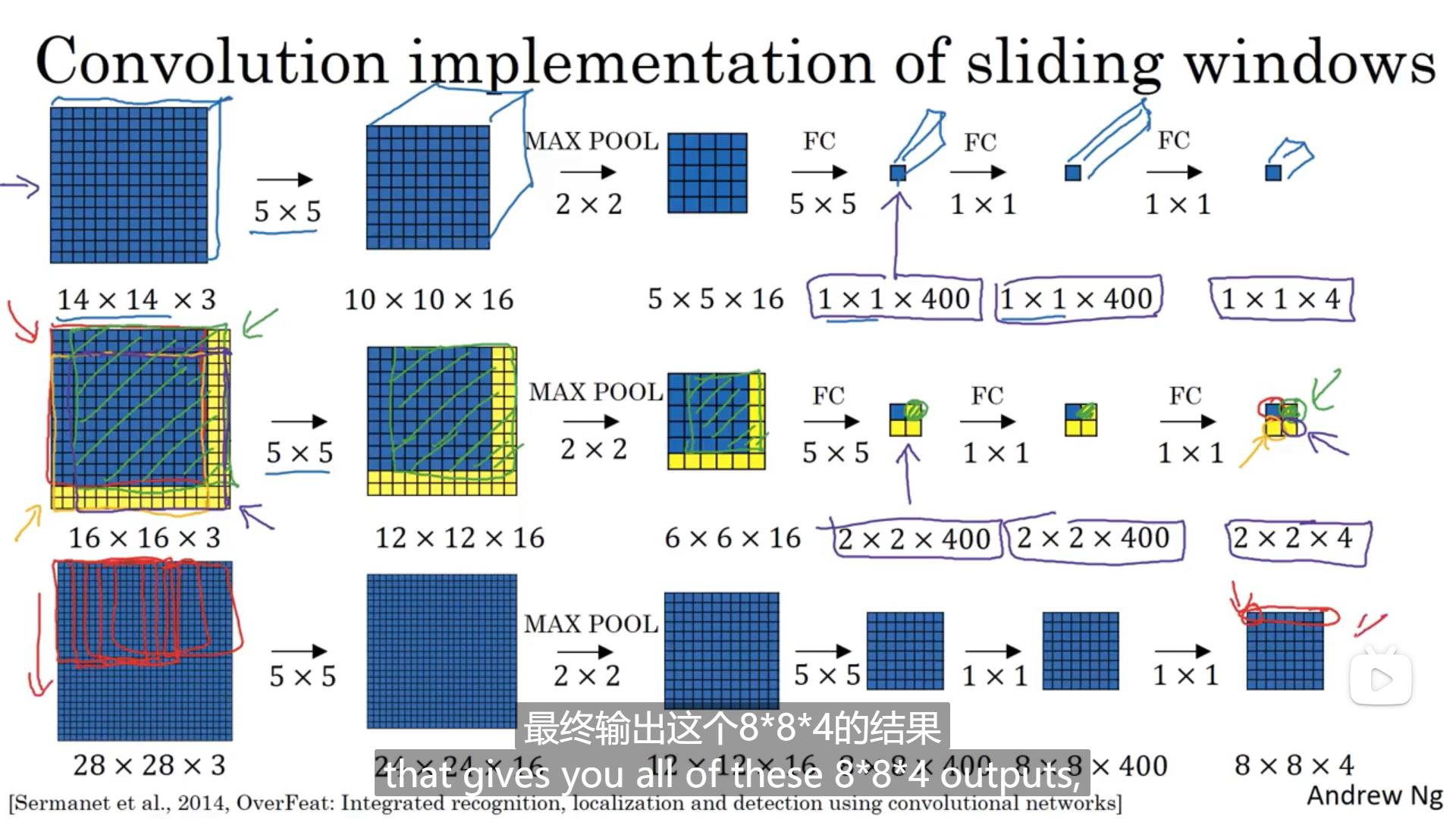
3.4 卷积的滑动窗口实现
要实现的卷积的滑动窗口,我们首先要将之前神经网络中的全连接层转化为卷积层。具体如下图,通过设置相应的卷积核就可以实现这样的操作
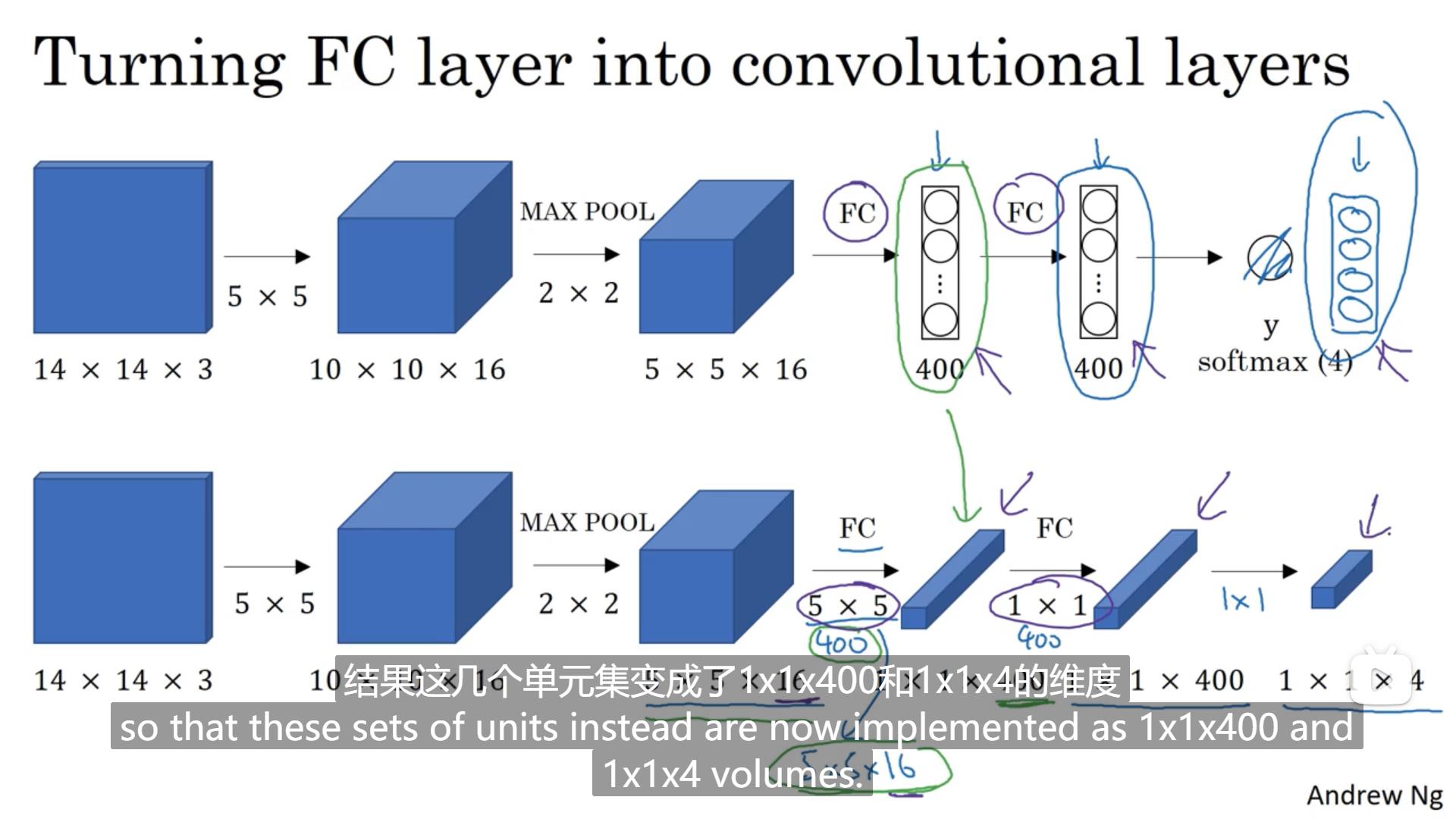
如果我们在选择的检测窗口大小是14143,那我们训练集中的图片大小与检测窗口的大小相同。按照上一节的方法,假如我们输入的图片大小是16163,选择的步长为2,则我们先从图片的左上角开始选择一个检测窗口,然后输入到网络中输出分类结果,然后右移两个单元,在重复上面的方法,然后再移动,这样的操作要重复4次。但这种方法会有很多重复的运算。所以我们采用卷积层代替全连接层,不再按检测窗口输入图片,而是将整个图片一起输入到网络中,这样重复的部分会共享结果,不会重复运算。就如下图中的第二个网络最后输出的是一个224的矩阵,每一个114的矩阵相当于之前网络的一个输出。
3.5 Bounding Box预测
下图展示了滑动窗口在目标检测方面的问题,即不能准确识别目标的边界。

YOLO算法可以很好的解决图像边界的问题。这里我们将图片分成9个部分,当然分的越细检测的越精准,我们按对象中心点所在的方块决定对象所属的方块。对于每一个方块,我们都要输出8个值,分别是是否有物体、物体的坐标、物体的宽高和属于各个种类的概率。我们并不是将方块一个一个输入,而是对整个图像整体进行输入,这样会加快计算速度。
3.6 交并比
交并比函数用来评价对象检测算法表现是否良好。在下图中,红框是对象的实际边界,紫框是对象检测算法检测出来的边界,交并比函数的计算方法就是用两个边界交集的大小除以两个边界并集的大小。一般当交并比(IOU)>0.5时可以接受,如果交并比=1,则两个边界完美重合。

3.7 非极大值抑制
如下图,由于我们会先将图片划分称很多小网格,所以可能出现一个对象在很多网格中的情况,这样一个对象就会被检测多次,因为有多个网格会认为该对象在自己的区域内,同时输出多个对象边界,但在下图中实际上只有两个对象,所以我们的目标是输出两个对象边界。这里采用的方法就是非极大值抑制。
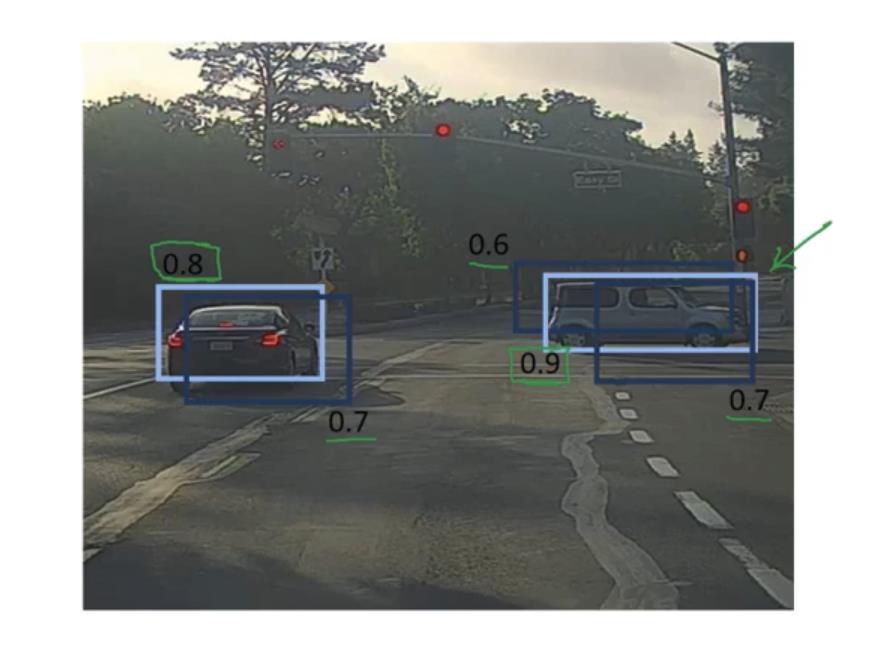
下图我们做的是汽车检测,只有汽车和非汽车两种可能,所以不需要c1、c2、c3。具体方法:先将pc值小于0.6的边框去除,然后选取剩余边框中pc值最大的边框输出,将与该边框交并比小于0.5的边框去除。然后循环选取剩余边框中pc值最大的,重复上述操作。如果是多目标检测,则最好对每一个目标独立进行上述过程。

3.8 Anchor Box
之前算法存在一个问题:一个格子只能检测一个对象。所以这里我们引入了anchor box,我们可以根据要检测对象的形状认为设定anchor box的形状,anchor box可以有多个。如下图,行人和汽车的中心点位于一个方格中,这是就要根据汽车和行人的形状设定两个anchor box,此时神经网络的输出不再是8维的,而是16维,其中上面8维是anchor box1的,下面8维是anchor box2的。至于如何判定对象输入anchor box1还是anchor box2,通过检测出目标的形状于anchor box的形状取交并比来判定。
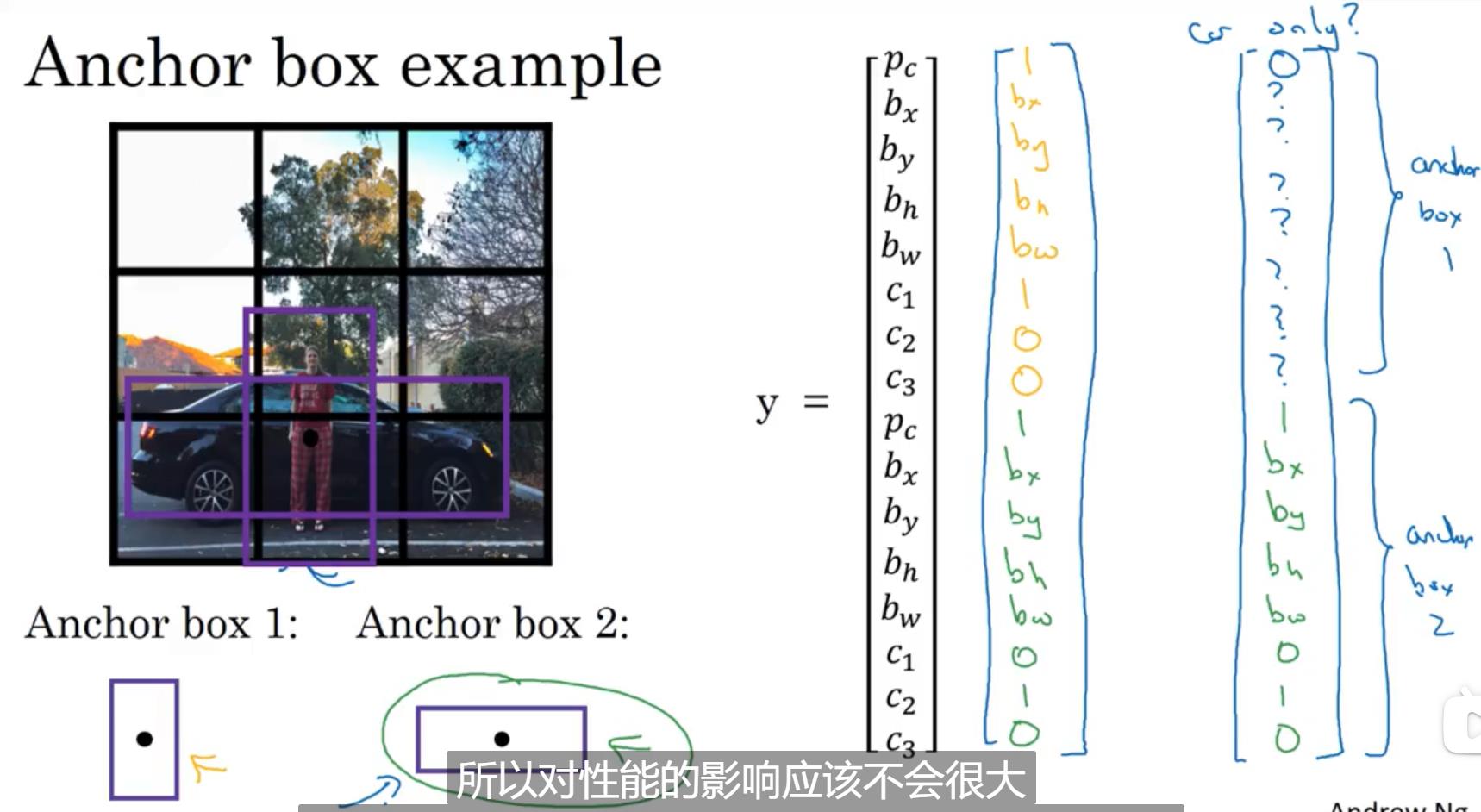
anchor box可以使网络更具有针对性。但是也存在一些问题:
-
如果你设定了两个anchor box,但是一个网格中有三个对象,anchor box将无法很好的解决。
-
如果两个相同的对象在同一个anchor box中,anchor box也无法很好的解决。
3.9 YOLO算法
如果我们要做一个识别三个对象的目标检测网络,分别是行人、汽车和摩托车。我们将输入图像划分称33的网格。然后遍历每个网格进行目标检测。这里我们设定两个anchor box,所以网络最后会输出一个3328的矩阵。
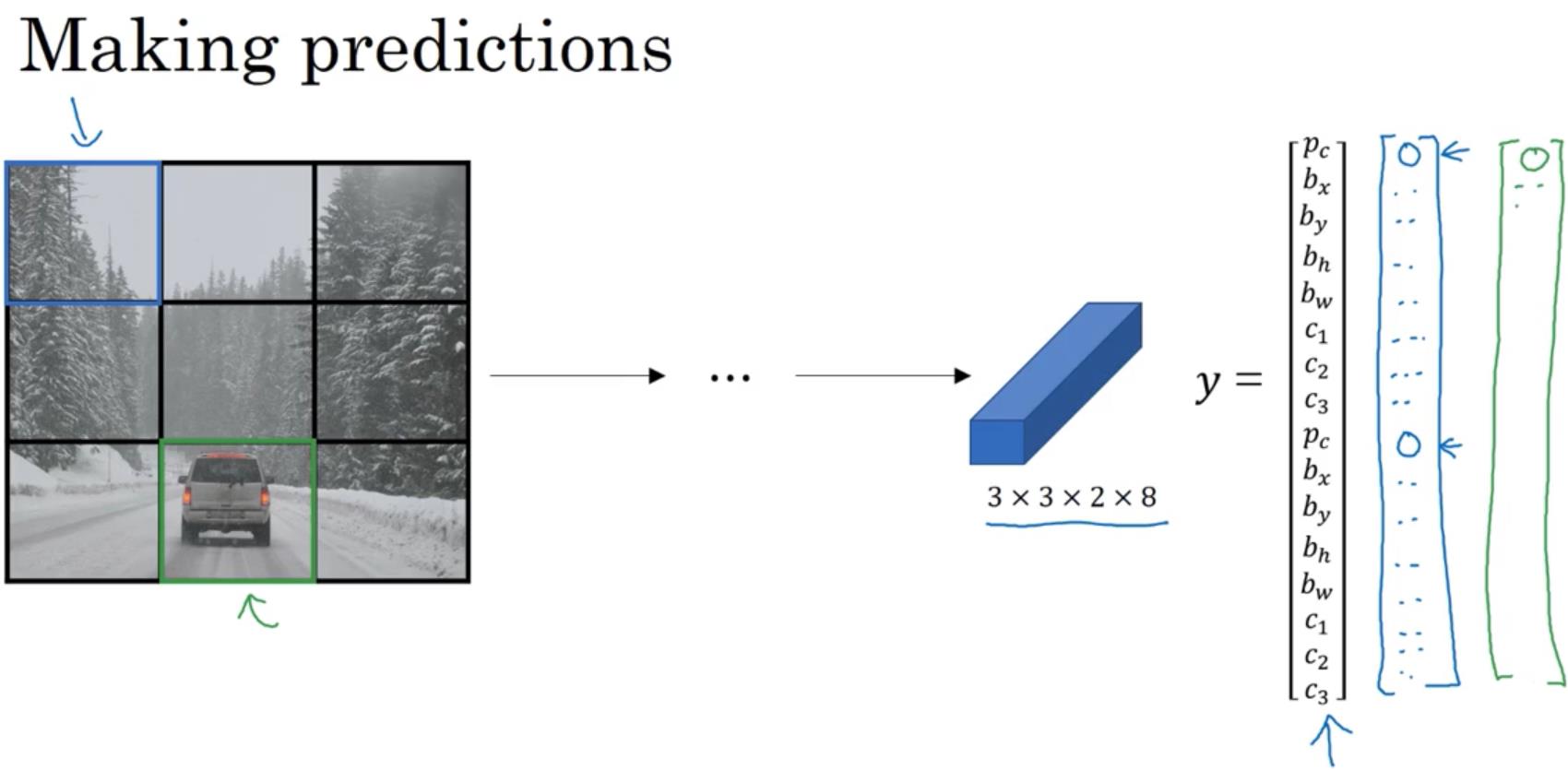
由于我们选择的是两个anchor box,所以每个网格都会有两个边框,注意:这里的边框并不一定要在一个网格内,也可以超出。然后若边框的pc值小于设定的阈值则删除,然后再根据非极大值抑制算法进行筛选,最后输出结果。

3.10 候选区域
R-CNN算法,也被称为带区域的CNN算法。它将目标检测分为两个过程,首先根据图像分割选出候选区域,然后对候选区域进行分类。

以上是关于最为详细的卷积神经网络笔记--吴恩达深度学习课程笔记的主要内容,如果未能解决你的问题,请参考以下文章