Redis高可用
Posted 还行少年
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Redis高可用相关的知识,希望对你有一定的参考价值。
在web服务器中,高可用是指服务器可以正常访问的时间,衡量的标准是在多长时间内可以提供正常服务
但是在redis中,高可用的含义似乎要宽泛一些,除了保证提供正常服务,还需要考虑数据容量的扩展,数据不会丢失等
高可用技术
-
持久化
持久化是最简单的高可用方式,主要作用是数据备份,即将数据存储在硬盘,保证数据不会因为进程退出而丢失 -
主从复制
主从复制时高可用Redis的基础,哨兵和集群都是在主从复制的基础上实现高可用的,主从复制主要是实现了数据的多机备份,以及对于读操作的负载均衡和简单的故障恢复。
缺陷:故障恢复无法自动化;写操作无法负载均衡;存储能力受到单机的限制 -
哨兵
在主从复制的基础上,哨兵实现了自动化的故障恢复。
缺陷:写操作无法负载均衡;存储能力受到了单机的限制 -
集群
通过集群,Redis解决了写操作无法负载均衡,以及存储能力受到单机限制的问题,实现了较为完善的高可用方案
1.持久化
1.1 RDB持久化
RBD持久化是指在指定的时间间隔内将内存中当前进程中的数据生成快照保存到硬盘(也称为快照持久化),用二进制压缩保存,保存的文件后缀时rdb:当Redis重新启动时,可以读取快照文件恢复数据
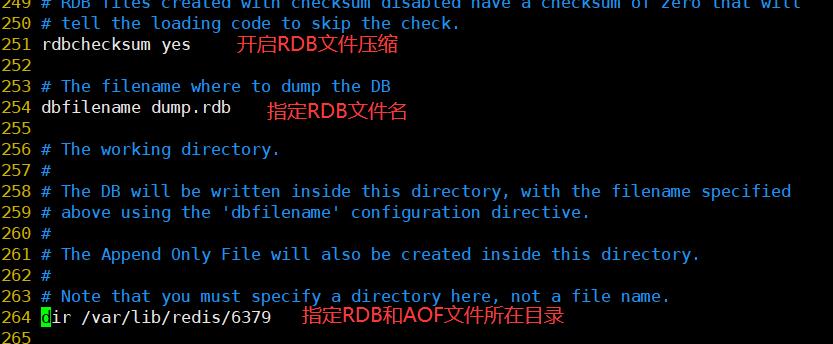
1.1.1 触发条件
- 手动触发
save命令和bgsave命令都可以生成RDB文件
[root@localhost ~]# redis-cli //进入数据库
127.0.0.1:6379> bgsave //手动执行
Background saving started
127.0.0.1:6379>
[root@localhost ~]# ls /var/lib/redis/6379/
dump.rdb //RDB文件
- 自动触发
自动触发RDB持久化时,Redis也会选择bgsave而不是save来进行持久化
在配置文件中通过save m n,指定当m s内发生n次变化,会触发bgsave
在主从复制场景下,如果从节点执行全量复制操作,则主节点会执行bgsave,并将rdb文件发送给从节点
执行shutdown命令时,自动执行rdb持久化

1.1.2 执行流程
- Redis父进程首先判断:当前是否在执行save或bgsave的子进程,如果在则bgsave命令直接返回;bgsave/bgrewriteaof的子进程不能同时执行
- 父进程执行fork操作创建子进程,这个过程中父进程是阻塞的,Redis不能执行来自客户端的任何命令
- 父进程fork后,bgsave命令返回“Backgroud saveing started”信息并不在阻塞父进程,并可以响应其他命令
- 子进程创建RDB文件,根据父进程内存快照生成临时快照文件,完成后对原有文件进行原子替换
- 子进程发送信号给父进程表示完成,父进程更新统计信息
1.1.3 启动时加载
- 在服务器中,仅当AOF功能关闭,才会载入RDB文件
- 启动过程中进行持久化文件的检测校验,若损坏,则打印错误,启动失败
1.2 AOF持久化
RDB持久化是将数据写入文件,而AOF持久化,则是将Redis执行的每次写、删除命令记录到单独的日志文件中,查询操作不会记录
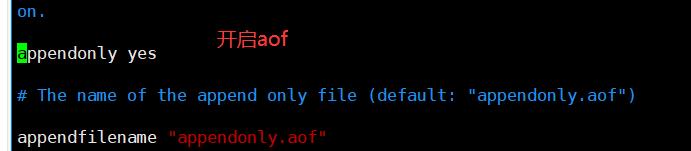
1.2.1 开启AOF


[root@localhost ~]# vim /etc/redis/6379.conf
[root@localhost ~]# /etc/init.d/redis_6379 restart //重启使配置文件生效
Stopping ...
Redis stopped
Starting Redis server...
1.2.2 执行流程
- 命令追加:将Redis的写命令追加到缓冲区aof_buf
- 文件写入和文件同步:根据不同的同步策略将aof_buf的内容同步到硬盘
- 文件重写:定期重写AOF文件,以达到压缩的目的
1.2.3 启动时加载
当AOF开启时,Redis启动会优先载入AOF文件来恢复数据;当AOF开启时,但AOF文件不存在,即使RDB文件存在也不会加载。
Redis载入AOF文件时,会对AOF文件进行校验,如果文件损坏,则日志中会打印错误,但是如果是AOF文件结尾不完整,切aof-load-treuncated开启,则会忽略尾部,启动成功
2.主从复制
2.1 流程
- 若启动一个slave机器进程,则他会向master机器发送一个sync_command命令,请求同步链接
- 无论是第一次连接还是重新连接,master机器都会启动一个后台进程,将数据快照保存到数据文件中,同时master还会记录修改数据的所有命令并缓存在数据文件中
- 后台进程完成缓存操作之后,,master机器就会向slave机器发送数据文件,slave将数据文件保存至硬盘,然后将其加载到内存中
- master机器收到slave的连接后,将其完整的数据文件发送给slave,如果master同时收到多个slave发来的同步请求则master会在后台启动一个进程以保存数据文件,然后将其发送给所有的slave机器,确保所有的slave机器都正常
2.2 搭建
环境
master 192.168.30.7
slave1 192.168.30.8
slave2 192.168.30.9
2.2.1 安装redis
2.2.1.1 安装依赖包和环境
[root@localhost opt]# yum -y install gcc gcc-c++ make
已加载插件:fastestmirror, langpacks
Loading mirror speeds from cached hostfile
* base: mirrors.aliyun.com
* extras: mirrors.aliyun.com
* updates: mirrors.aliyun.com
软件包 gcc-4.8.5-44.el7.x86_64 已安装并且是最新版本
软件包 gcc-c++-4.8.5-44.el7.x86_64 已安装并且是最新版本
软件包 1:make-3.82-24.el7.x86_64 已安装并且是最新版本
无须任何处理
[root@localhost opt]#
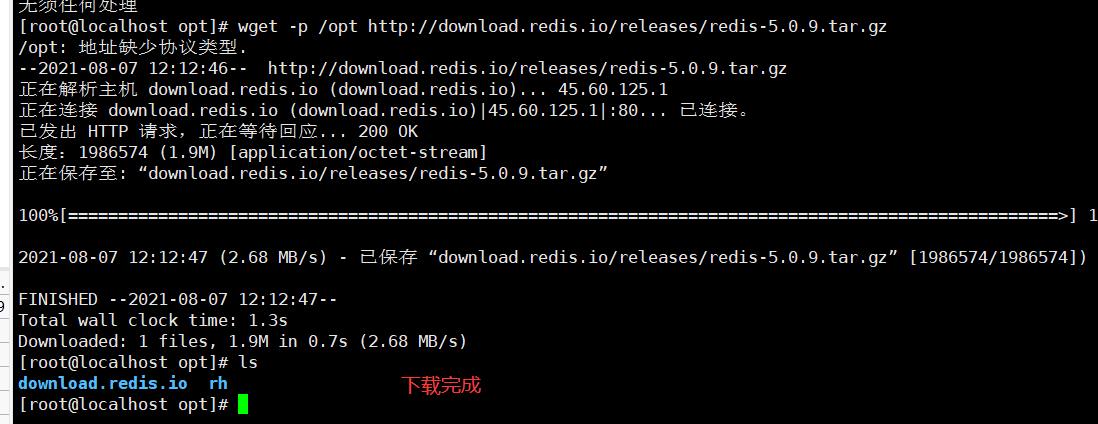
2.2.1.2 下载软件包
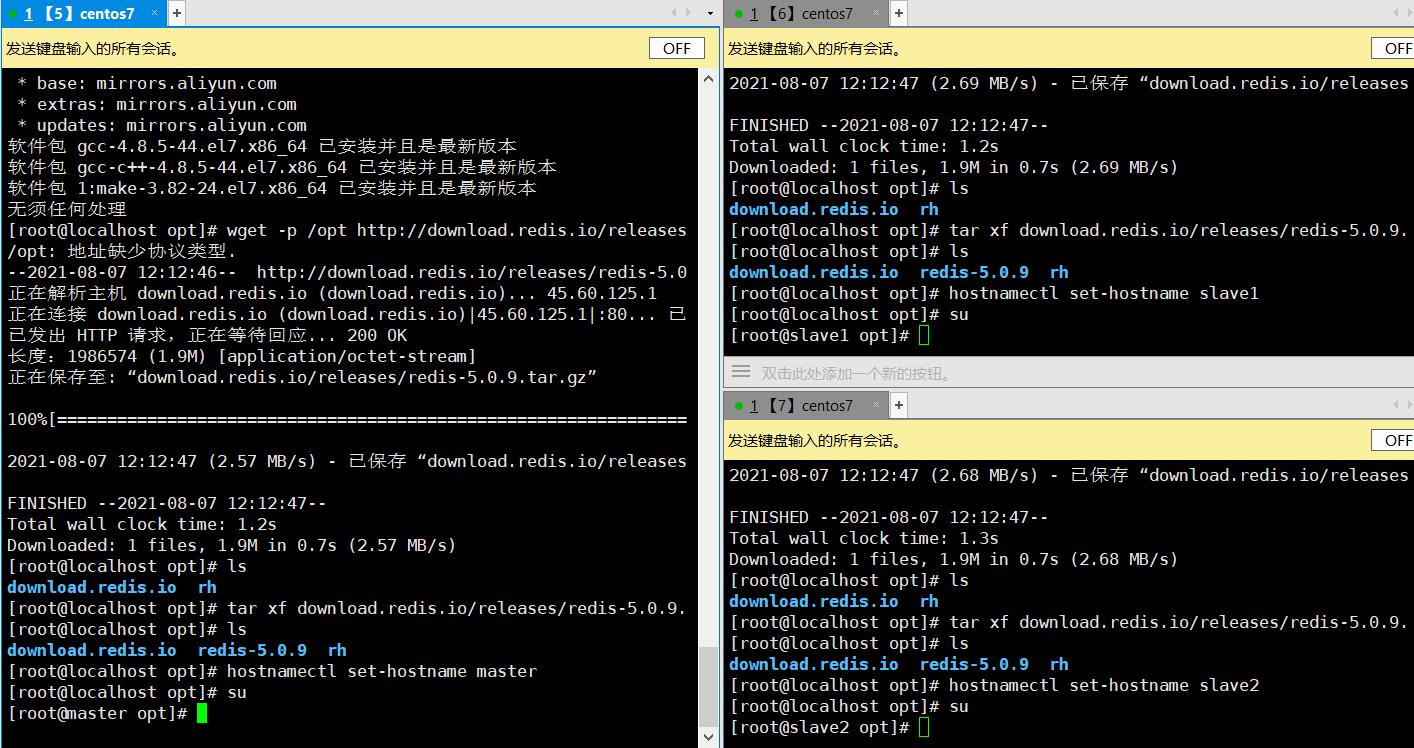
2.2.1.3 解压并修改节点名
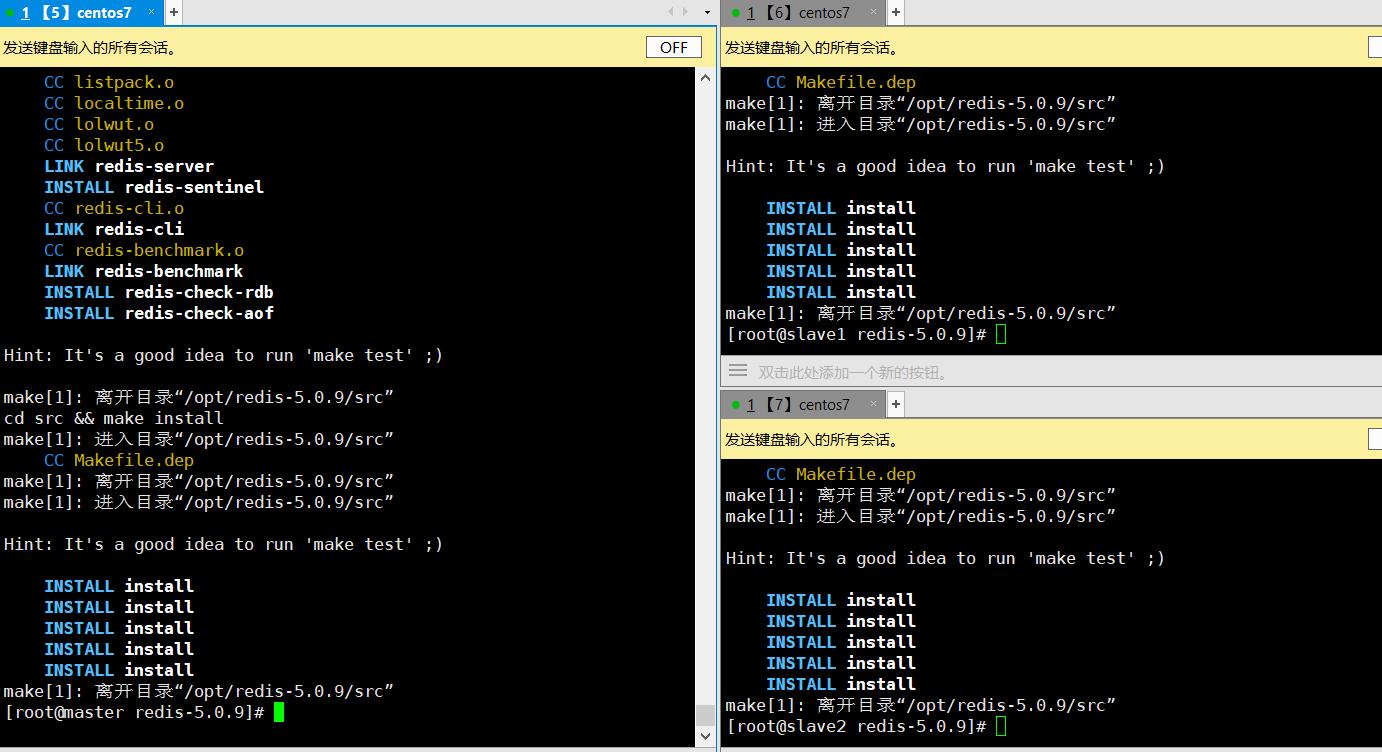
2.2.1.4 安装
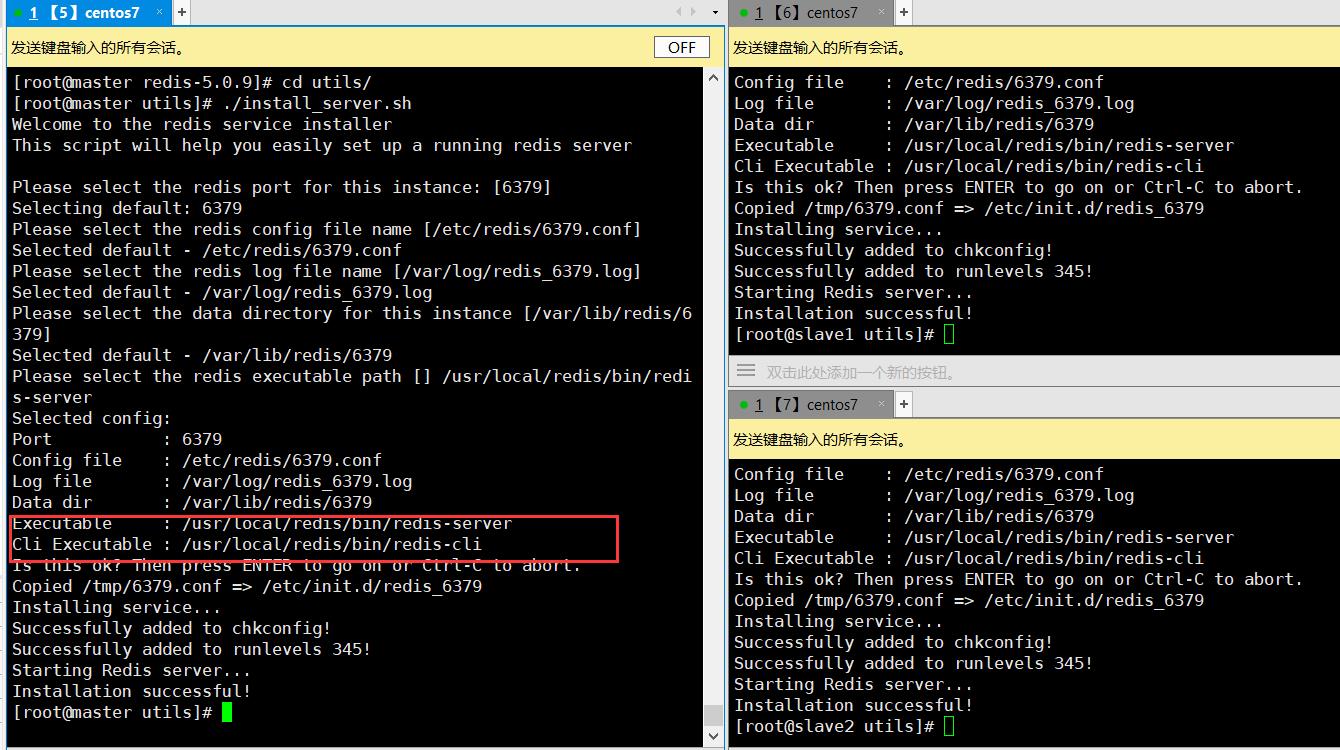
2.2.1.5 优化管理路径
[root@master utils]# ln -s /usr/local/redis/bin/* /usr/local/bin/
[root@master utils]# ls /usr/local/bin/
redis-benchmark redis-check-rdb redis-sentinel
redis-check-aof redis-cli redis-server
2.2.1.6 检查服务状态
[root@master utils]# ss -natp | grep redis
LISTEN 0 128 127.0.0.1:6379 *:* users:(("redis-server",pid=26462,fd=6))
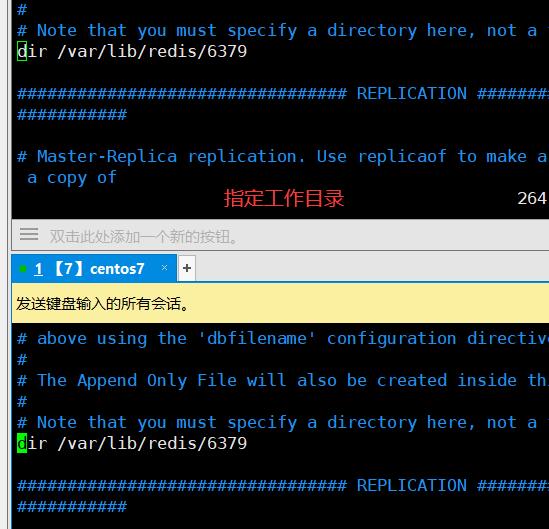
2.2.2 修改配置文件
master

slave
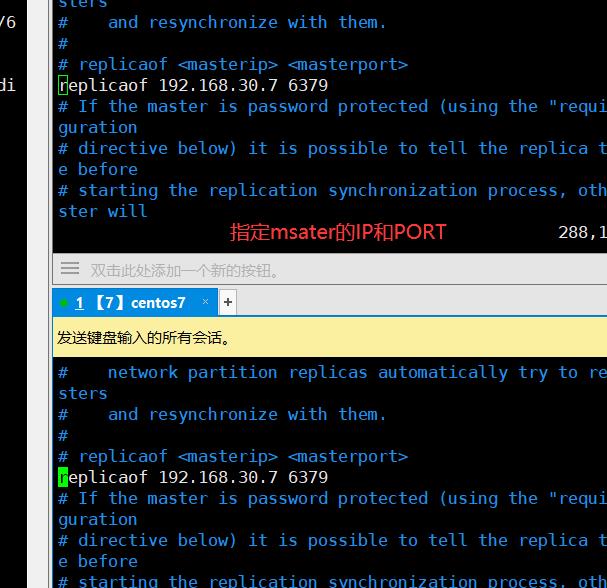
2.2.3 验证主从效果
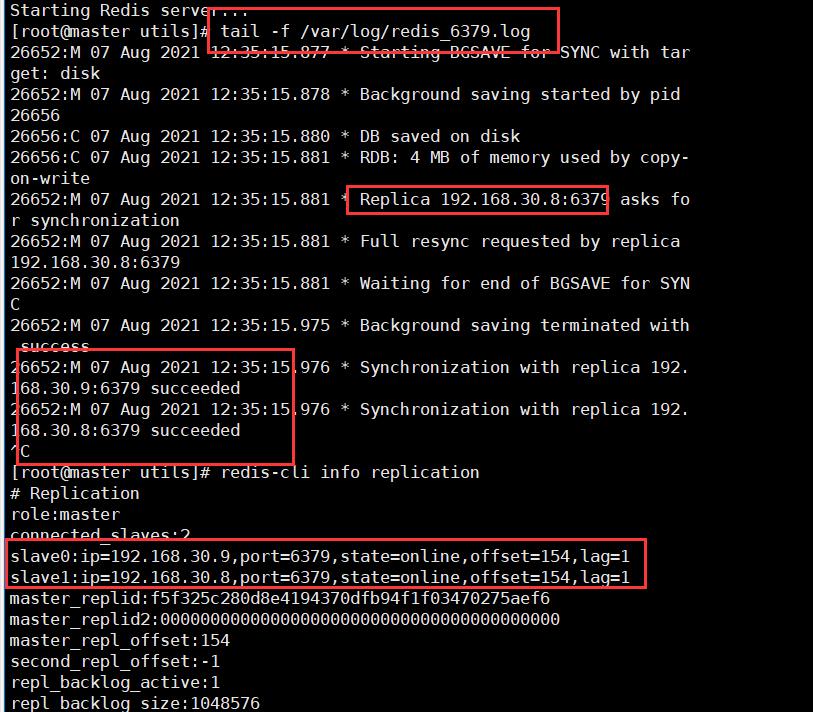
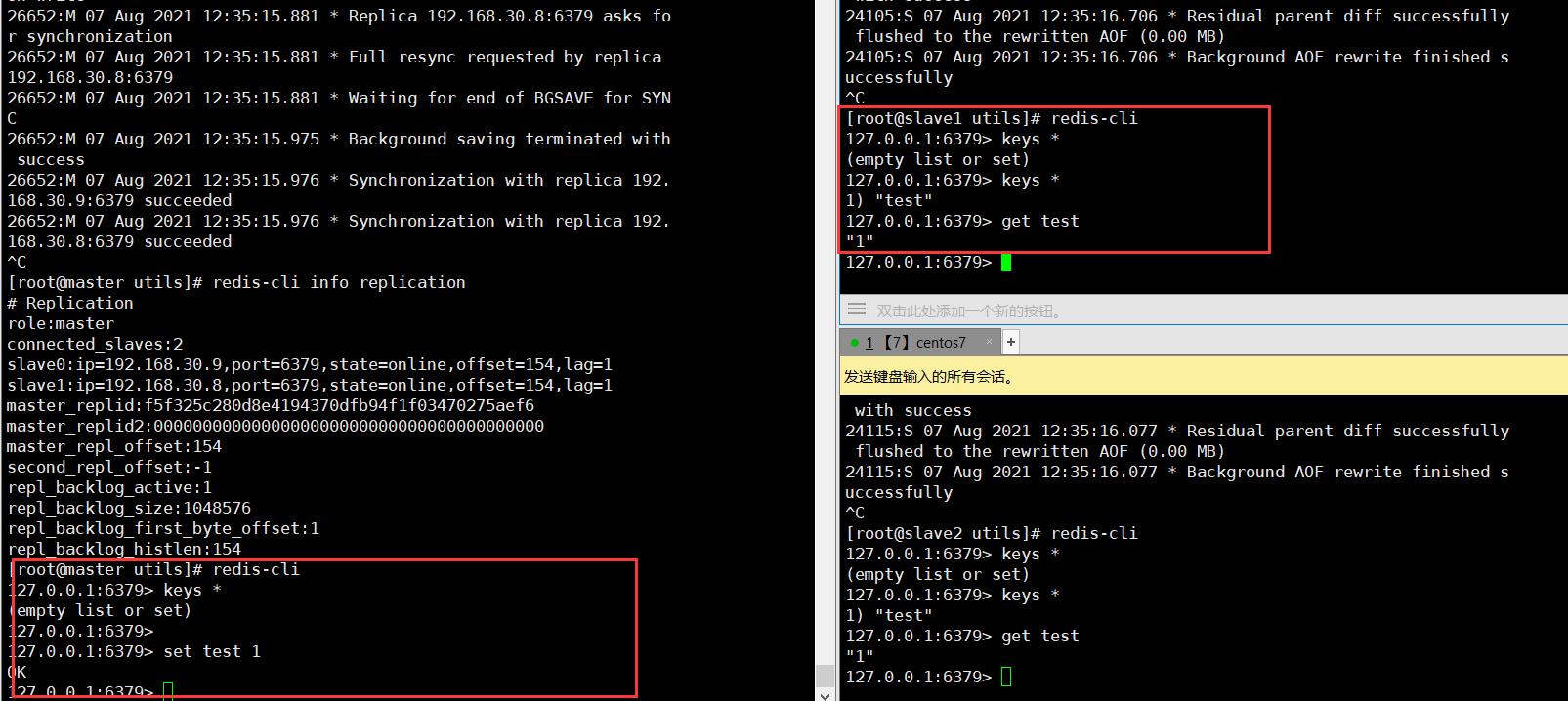
3.哨兵模式
3.1 作用
- 监控
哨兵会不断地检查主节点和从节点是否运转正常 - 自动故障转移
当主节点不能正常工作时,哨兵会自动开始故障转移操作 - 通知
将故障转移的结果发给客户端
3.2 原理
他是一个分布式系统,用于对主从结构中的每台服务器进行监控,它会将失效节点的其中一个从节点升级为新的主节点,并让其他从节点改为复制新的主节点
3.3 结构
- 哨兵节点
哨兵节点时特殊的redis节点,不存储数据 - 数据节点
主节点和从节点都是数据节点
3.4 工作过程
当master出现问题时,因为其他节点和主节点失去联系,因此会投票,投票过半就认为这个master的确出现问题,然后通知哨兵会会推出一个哨兵来进行故障转移工作,然后从slaves中选取一个作为新的master
3.5 搭建哨兵模式
环境
master 192.168.30.7
slave1 192.168.30.8
slave2 192.168.30.9
3.5.1 修改哨兵配置文件
[root@master utils]# vim /opt/redis-5.0.9/sentinel.conf
17 protected-mode no //关闭保护模式
21 port 26379 //默认端口
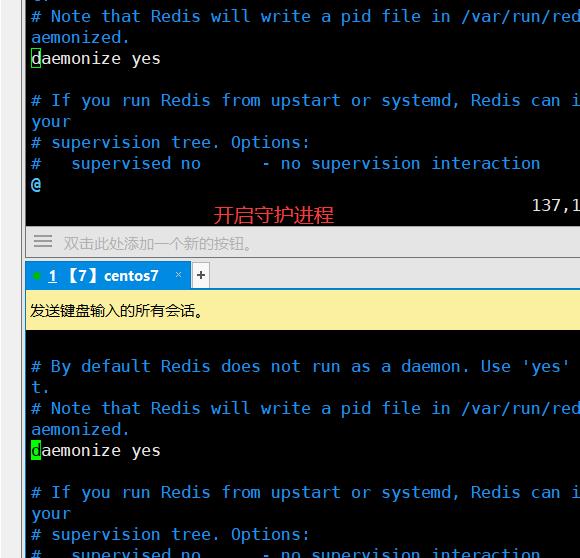
26 daemonize yes //开启守护进程
36 logfile "/var/log/sentinel.log" //指定日志位置
65 dir /var/lib/redis/6379 //指定工作目录
84 sentinel monitor mymaster 192.168.30.7 6379 2 //至少两个哨兵同意才能进行故障转移
113 sentinel down-after-milliseconds mymaster 30000 //判断节点down掉的时间周期,默认30s
146 sentinel failover-timeout mymaster 180000 //最大超时时间,默认180s
3.5.2 启动哨兵模式
[root@master redis-5.0.9]# redis-sentinel sentinel.conf //启动哨兵模式,先主后从
[root@master redis-5.0.9]# netstat -antp | grep 26379
tcp 0 0 0.0.0.0:26379 0.0.0.0:* LISTEN 26978/redis-sentine
tcp 0 0 192.168.30.7:26379 192.168.30.9:41478 ESTABLISHED 26978/redis-sentine
tcp 0 0 192.168.30.7:26379 192.168.30.8:59552 ESTABLISHED 26978/redis-sentine
tcp 0 0 192.168.30.7:43886 192.168.30.8:26379 ESTABLISHED 26978/redis-sentine
tcp 0 0 192.168.30.7:41942 192.168.30.9:26379 ESTABLISHED 26978/redis-sentine
tcp6 0 0 :::26379 :::* LISTEN 26978/redis-sentine
[root@master redis-5.0.9]#
3.5.3 查看哨兵信息
[root@master redis-5.0.9]# redis-cli -p 26379 info sentinel
# Sentinel
sentinel_masters:1
sentinel_tilt:0
sentinel_running_scripts:0
sentinel_scripts_queue_length:0
sentinel_simulate_failure_flags:0
master0:name=mymaster,status=ok,address=192.168.30.7:6379,slaves=2,sentinels=3
3.5.4 模拟故障
3.5.4.1 结束master的redis进程
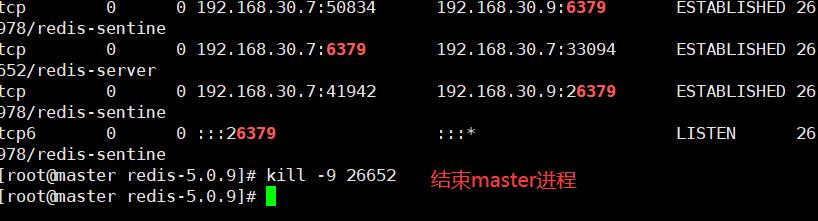
3.5.4.2 查看slave节点
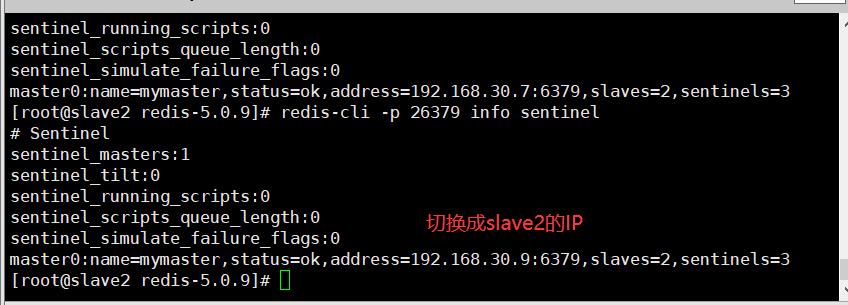
3.5.4.3 查看哨兵日志

4.Cluster集群
主节点负责读写请求和集群信息的维护,从节点只进行主节点数据和状态信息的复制
4.1 作用
-
数据分区
数据分区(或称数据分片)是集群最核心的功能(分布式)
集群将数据分散到多个节点,一方面突破了 Redis 单机内存大小的限制,存储容量大大增加,另一方面每个主节点都可以对外提供读服务和写服务,大大提高了集群的响应能力
Redis 单机内存大小受限问题,在介绍持久化和主从复制时都有提及,例如,如果单机内存太大,bgsave 和 bgrewriteaof 的 fork 操作可能导致主进程阻塞,主从环境下主机切换时可能导致从节点长时间无法提供服务,全量复制阶段主节点的复制缓冲区可能溢出 -
高可用
集群支持主从复制(模式)和主节点的自动故障转移(与哨兵类似),当任意节点发送故障时,集群仍然可以对外提供服务 -
数据分片
Redis 集群引入了哈希槽的概念,有 16384 个哈希槽(编号 0~16383)集群的每个节点负责一部分哈希槽,每个 Key 通过 CRC16 校验后对 16384 取余来决定放置哪个哈希槽,通过这个值,去找到对应的插槽所对应的节点,然后直接自动跳转到这个对应的节点上进行存取操作
4.2 搭建Cluster集群
环境
三主三从都是同一台服务器
主节点 6001 6002 6003
从节点 6004 6005 6006
4.2.1 安装redis
4.2.2 创建6个节点的工作目录
[root@localhost redis]# cd redis-cluster/
[root@localhost redis-cluster]# ls
redis6001 redis6002 redis6003 redis6004 redis6005 redis6006
[root@localhost redis-cluster]#
4.2.3 将配置文件拷过来
[root@localhost opt]# bash -x /opt/redis.sh
+ for i in '{1..6}'
+ cp /opt/redis-5.0.9/redis.conf /etc/redis/redis-cluster/redis6001
+ cp /opt/redis-5.0.9/src/redis-cli /opt/redis-5.0.9/src/redis-server /etc/redis/redis-cluster/redis6001
+ for i in '{1..6}'
+ cp /opt/redis-5.0.9/redis.conf /etc/redis/redis-cluster/redis6002
+ cp /opt/redis-5.0.9/src/redis-cli /opt/redis-5.0.9/src/redis-server /etc/redis/redis-cluster/redis6002
+ for i in '{1..6}'
+ cp /opt/redis-5.0.9/redis.conf /etc/redis/redis-cluster/redis6003
+ cp /opt/redis-5.0.9/src/redis-cli /opt/redis-5.0.9/src/redis-server /etc/redis/redis-cluster/redis6003
+ for i in '{1..6}'
+ cp /opt/redis-5.0.9/redis.conf /etc/redis/redis-cluster/redis6004
+ cp /opt/redis-5.0.9/src/redis-cli /opt/redis-5.0.9/src/redis-server /etc/redis/redis-cluster/redis6004
+ for i in '{1..6}'
+ cp /opt/redis-5.0.9/redis.conf /etc/redis/redis-cluster/redis6005
+ cp /opt/redis-5.0.9/src/redis-cli /opt/redis-5.0.9/src/redis-server /etc/redis/redis-cluster/redis6005
+ for i in '{1..6}'
+ cp /opt/redis-5.0.9/redis.conf /etc/redis/redis-cluster/redis6006
+ cp /opt/redis-5.0.9/src/redis-cli /opt/redis-5.0.9/src/redis-server /etc/redis/redis-cluster/redis6006
[root@localhost opt]#
4.2.5 修改配置文件
[root@localhost redis6001]# vim redis.conf //其他配置文件如下改,除了port
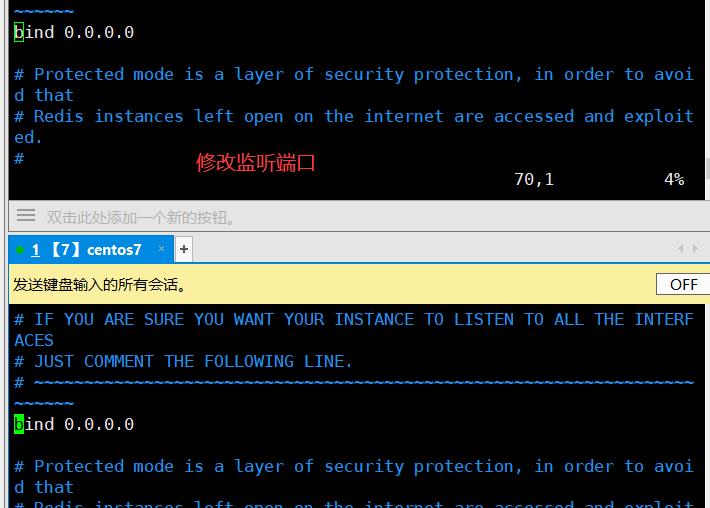
69 bind 127.0.0.1 //监听IP
92 port 6001 //监听PORT
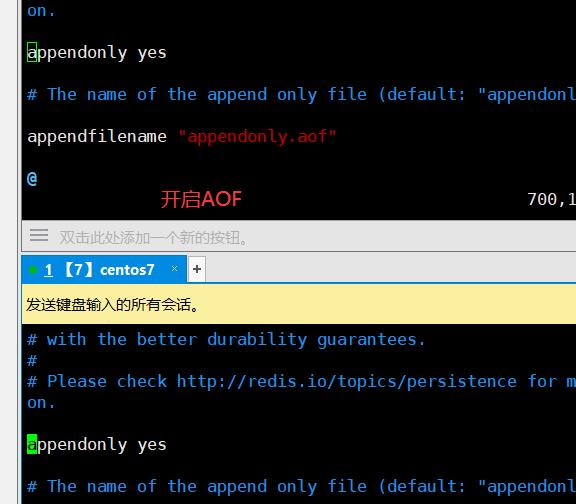
699 appendonly yes //开启AOF
832 cluster-enabled yes //开启集群
840 cluster-config-file nodes-6001.conf //集群名称文件
846 cluster-node-timeout 15000 //集群超时时间
4.2.6 启动服务
root@localhost redis6001]# redis-server redis.conf //其他端口同样启动
29027:C 07 Aug 2021 14:58:31.123 # oO0OoO0OoO0Oo Redis is starting oO0OoO0OoO0Oo
29027:C 07 Aug 2021 14:58:31.123 # Redis version=5.0.9, bits=64, commit=00000000, modified=0, pid=29027, just started
29027:C 07 Aug 2021 14:58:31.123 # Configuration loaded
4.2.7 加入集群
[root@localhost redis6001]# redis-cli --cluster create 127.0.0.1:6001 127.0.0.1:6002 127.0.0.1:6003 127.0.0.1:6004 127.0.0.1:6005 127.0.0.1:6006 --cluster-replicas 1
>>> Performing hash slots allocation on 6 nodes...
Master[0] -> Slots 0 - 5460
Master[1] -> Slots 5461 - 10922
Master[2] -> Slots 10923 - 16383
Adding replica 127.0.0.1:6005 to 127.0.0.1:6001
Adding replica 127.0.0.1:6006 to 127.0.0.1:6002
Adding replica 127.0.0.1:6004 to 127.0.0.1:6003
>>> Trying to optimize slaves allocation for anti-affinity
[WARNING] Some slaves are in the same host as their master
M: 370c0e26c898d9fa13b4c471b0e6259dfadec731 127.0.0.1:6001
slots:[0-5460] (5461 slots) master
M: dbd8e38b6c8d48f25cc8331624627e7411a43d15 127.0.0.1:6002
slots:[5461-10922] (5462 slots) master
M: 331ee4d7369d949fdef5970be4f0233fa0313efe 127.0.0.1:6003
slots:[10923-16383] (5461 slots) master
S: 2b1a0dd61a2e2a275429b2ec818e95654c29acd8 127.0.0.1:6004
replicates dbd8e38b6c8d48f25cc8331624627e7411a43d15
S: dd86a642078a74f5ebb7f0bb452455e418c5b160 127.0.0.1:6005
replicates 331ee4d7369d949fdef5970be4f0233fa0313efe
S: 822219d31b1248348f223406da72ef69537f4cc4 127.0.0.1:6006
replicates 370c0e26c898d9fa13b4c471b0e6259dfadec731
Can I set the above configuration? (type 'yes' to accept): yes
>>> Nodes configuration updated
>>> Assign a different config epoch to each node
>>> Sending CLUSTER MEET messages to join the cluster
Waiting for the cluster to join
...
>>> Performing Cluster Check (using node 127.0.0.1:6001)
M: 370c0e26c898d9fa13b4c471b0e6259dfadec731 127.0.0.1:6001
slots:[0-5460] (5461 slots) master
1 additional replica(s)
M: dbd8e38b6c8d48f25cc8331624627e7411a43d15 127.0.0.1:6002
slots:[5461-10922] (5462 slots) master
1 additional replica(s)
S: 822219d31b1248348f223406da72ef69537f4cc4 127.0.0.1:6006
slots: (0 slots) slave
replicates 370c0e26c898d9fa13b4c471b0e6259dfadec731
S: dd86a642078a74f5ebb7f0bb452455e418c5b160 127.0.0.1:6005
slots: (0 slots) slave
replicates 331ee4d7369d949fdef5970be4f0233fa0313efe
M: 331ee4d7369d949fdef5970be4f0233fa0313efe 127.0.0.1:6003
slots:[10923-16383] (5461 slots) master
1 additional replica(s)
S: 2b1a0dd61a2e2a275429b2ec818e95654c29acd8 127.0.0.1:6004
slots: (0 slots) slave
replicates dbd8e38b6c8d48f25cc8331624627e7411a43d15
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
4.2.8 测试集群
[root@localhost redis6001]# redis-cli -p 6001 -c
127.0.0.1:6001> cluster slots //查看节点的哈希槽编号范围
1) 1) (integer) 0
2) (integer) 5460 //哈希槽编号范围
3) 1) "127.0.0.1"
2) (integer) 6001 //主节点IP和端口号
3) "370c0e26c898d9fa13b4c471b0e6259dfadec731"
4) 1) "127.0.0.1"
2) (integer) 6006 //从节点IP和端口号
3) "822219d31b1248348f223406da72ef69537f4cc4"
2) 1) (integer) 5461
2) (integer) 10922
3) 1) "127.0.0.1"
2) (integer) 6002
3) "dbd8e38b6c8d48f25cc8331624627e7411a43d15"
4) 1) "127.0.0.1"
2) (integer) 6004
3) "2b1a0dd61a2e2a275429b2ec818e95654c29acd8"
3) 1) (integer) 10923
2) (integer) 16383
3) 1) "127.0.0.1"
2) (integer) 6003
3) "331ee4d7369d949fdef5970be4f0233fa0313efe"
4) 1) "127.0.0.1"
2) (integer) 6005
3) "dd86a642078a74f5ebb7f0bb452455e418c5b160"
127.0.0.1:6001>
127.0.0.1:6001> set test 123
-> Redirected to slot [6918] located at 127.0.0.1:6002
OK
127.0.0.1:6002> cluster keyslot test //查看test键的槽编号
(integer) 6918
小结
- 持久化分为RDB和AOF
RDB:周期性的快照
AOF:接近实时的持久化
优先级 : AOF > RDB - 主从复制
提供了备份冗余,但是无法针对故障进行自动修复,写操作无法负载均衡 - 哨兵
为主从提供了故障自动修复功能,但是写操作无法负载均衡 - 集群
基于主从复制,解决故障自动修复,写操作无法负载均衡的问题,同时对于资源需求相较于前两种集群得到了一定的改善
以上是关于Redis高可用的主要内容,如果未能解决你的问题,请参考以下文章