K8sHelm配置图形,prometheu(采集的自定义指标转化为集群内的量度指标,与hpa结合,实现自动伸缩)
Posted S4061222
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了K8sHelm配置图形,prometheu(采集的自定义指标转化为集群内的量度指标,与hpa结合,实现自动伸缩)相关的知识,希望对你有一定的参考价值。
目录
一 Helm配置图形
部署kubeapps应用,为Helm提供web UI界面管理
添加阿里云的库,拉取kubeapps
helm repo add apphub https://apphub.aliyuncs.com
helm search repo kubeapps
helm pull bitnami/kubeapps
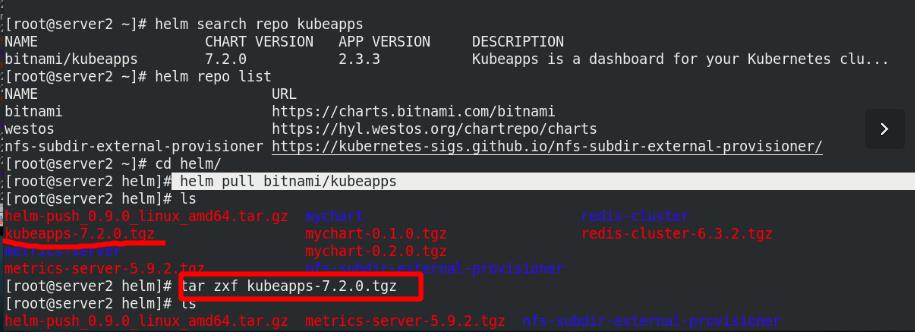
编辑value.yaml文件

修改仓库位置,global全局
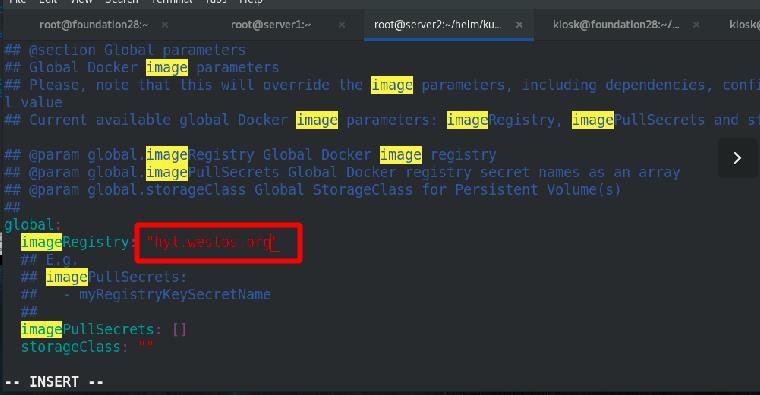
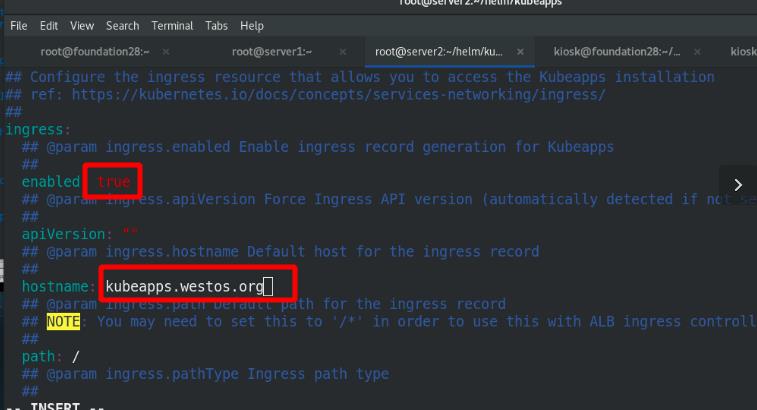
启用ingress方式进行外部访问,添加域名
修改镜像位置为私有仓库中bitnami项目
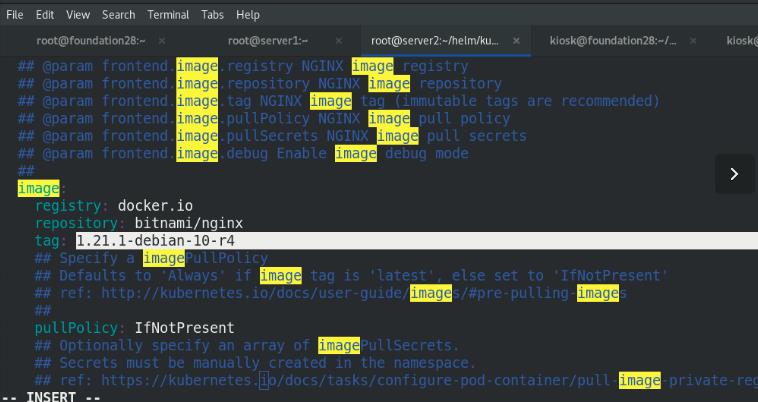
准备yaml文件中需要的镜像

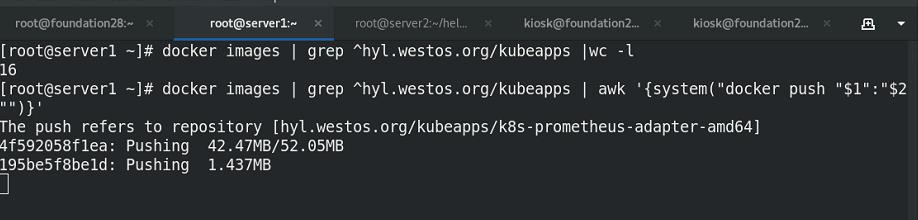
将需要的镜像全部上传至私有仓库中的bitnami项目中
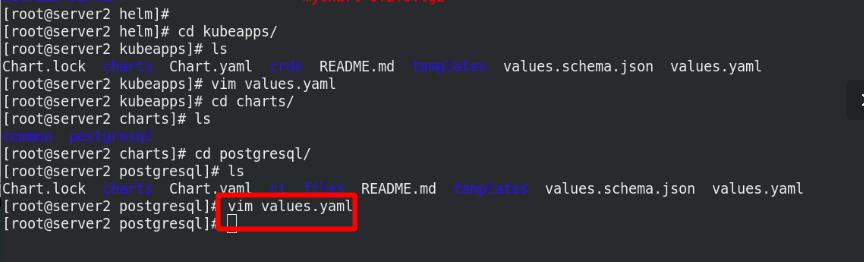
编辑postgresql的配置文件value.yaml
修改仓库位置,global全局,确定镜像拉取位置

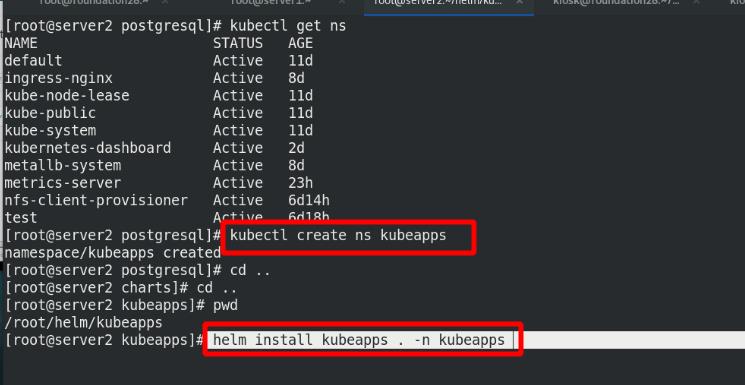
创建新的ns为kubeapps进行隔离,指定ns进行安装
查看ns中节点状况
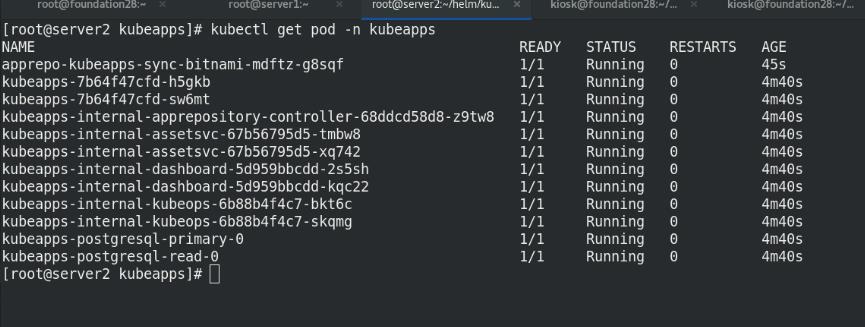
查看ns中节点所有信息
查看ns中的svc信息

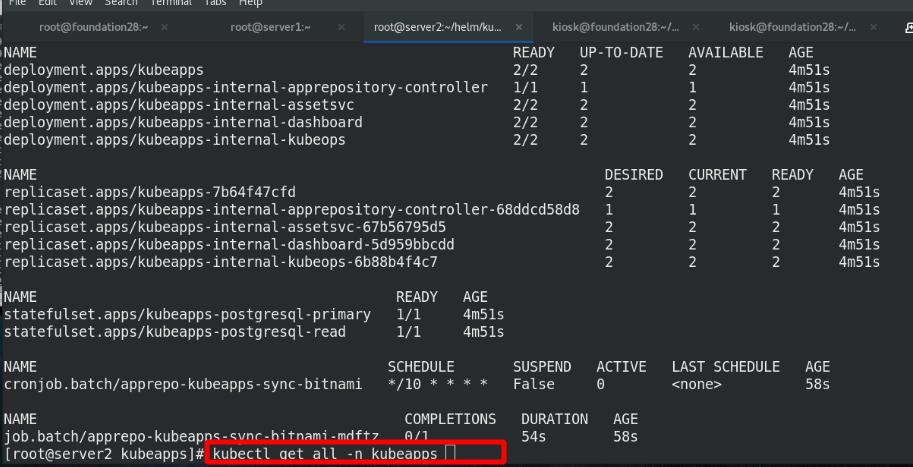
查看ns为kubeapps的ingress信息

查看ingress的详细信息,此域名有2个后端
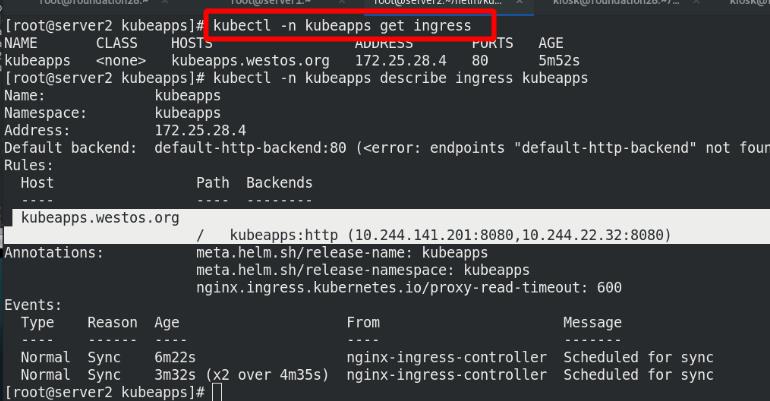
查看ingress所分配的对外IP,(前提ingress已经部署成功)

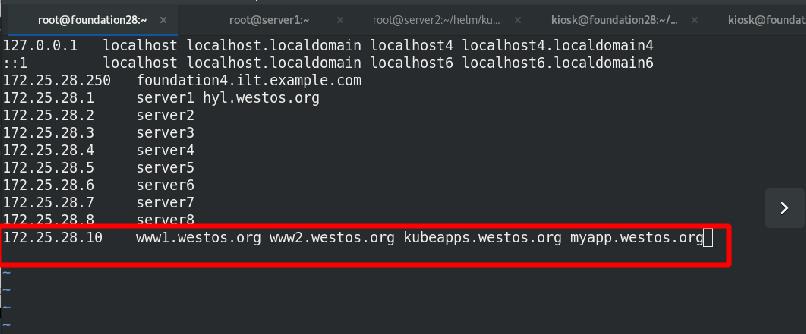
添加域名解析
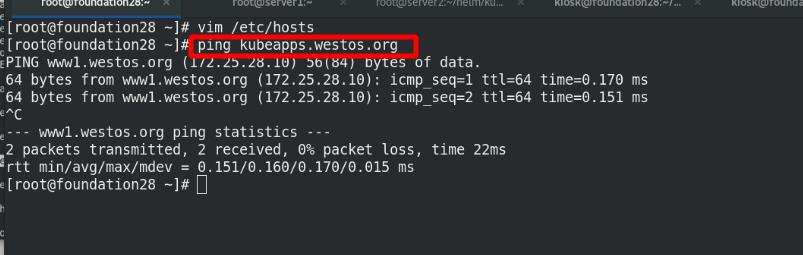
集群外部访问域名进行测试
此ns中创建sa :kubeapps-operator

此ns中创建clusterrolebinding: kubeapps-operator

集群角色(cluser-admin)绑定与授权rbac
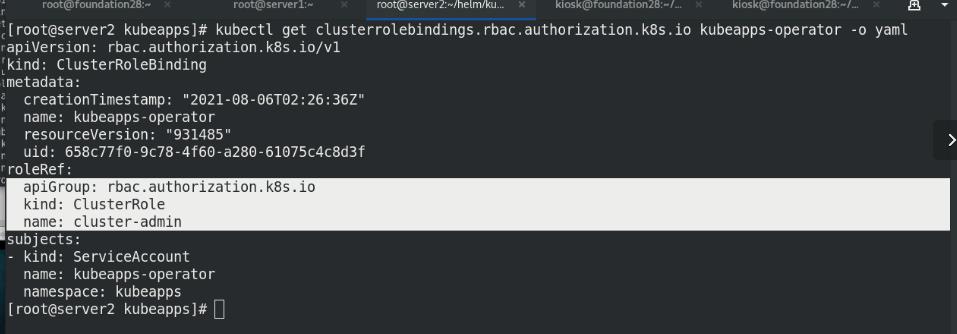
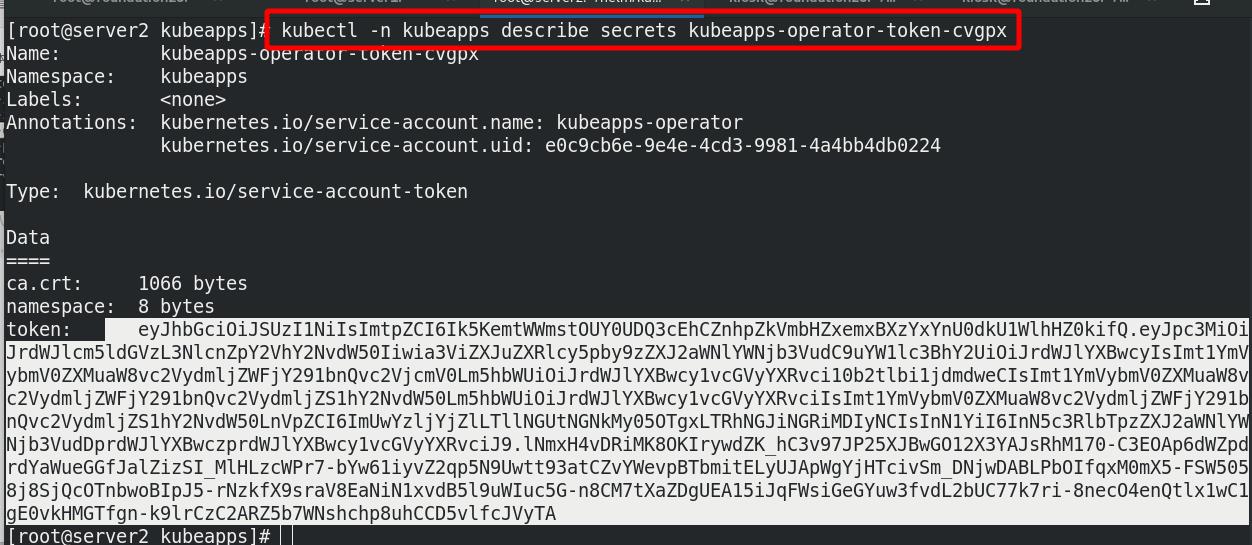
获取token

查看登陆token
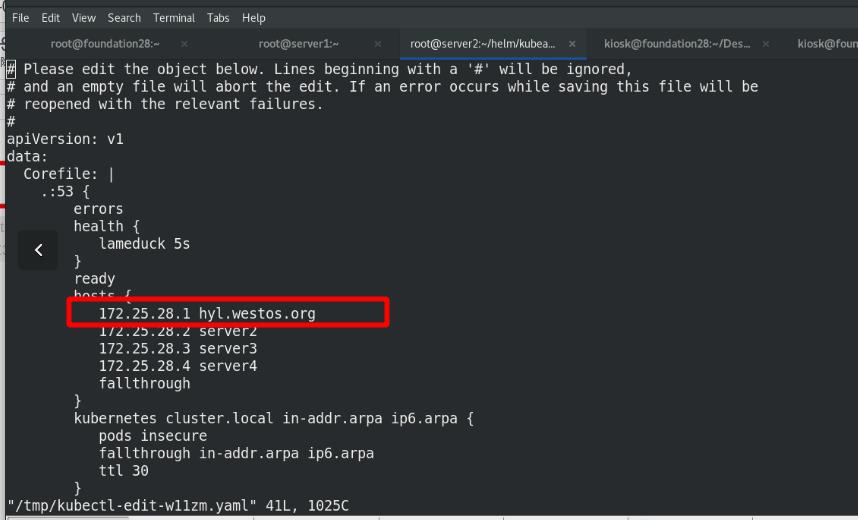
需要做解析,不然登陆会报错

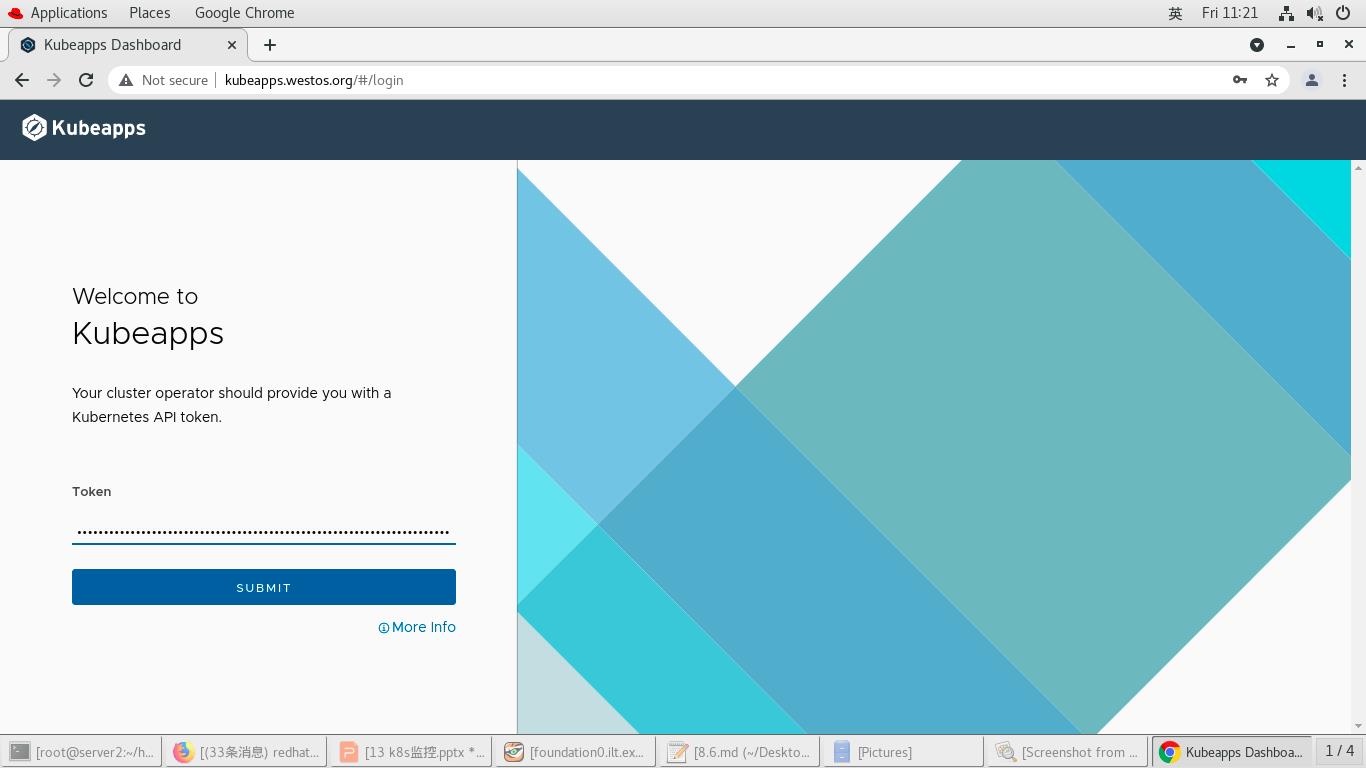
网页登陆
查看此ns中部署
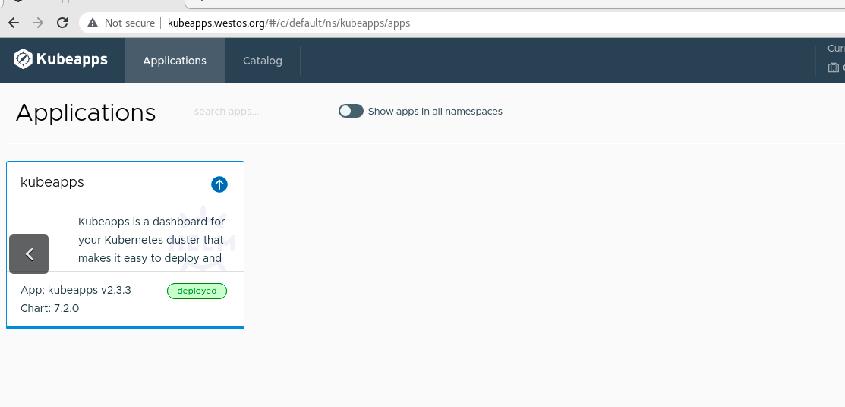
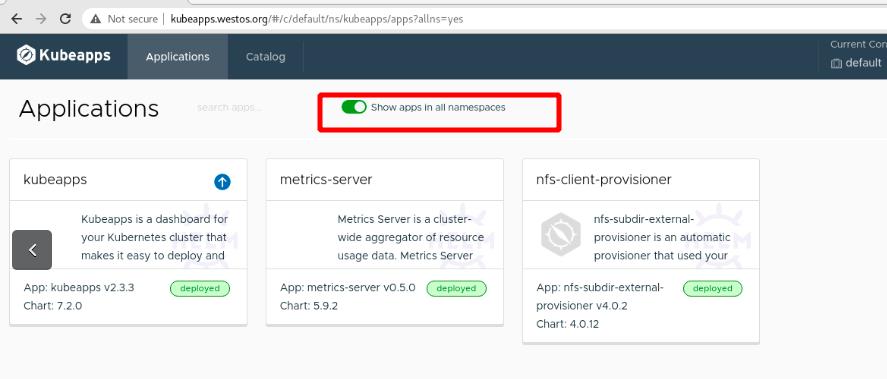
查看所有ns中所有部署
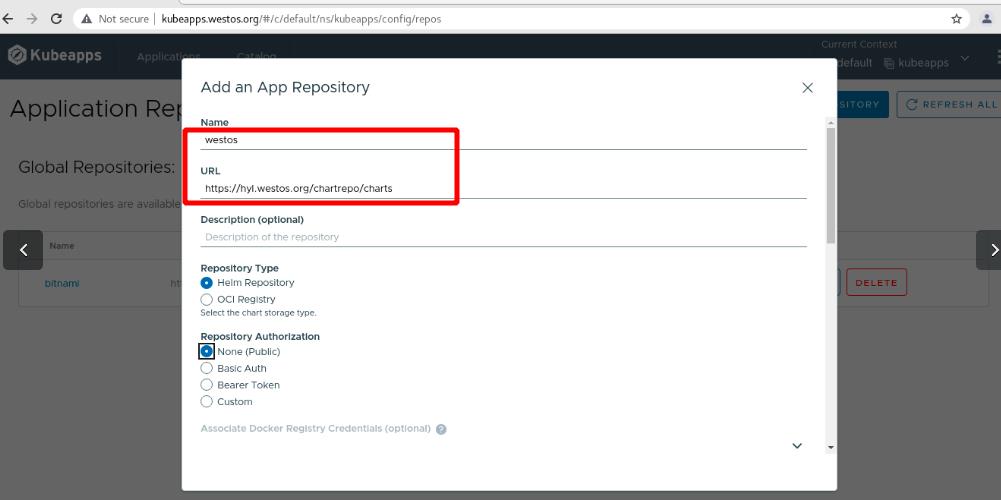
图形化添加仓库URL到helm

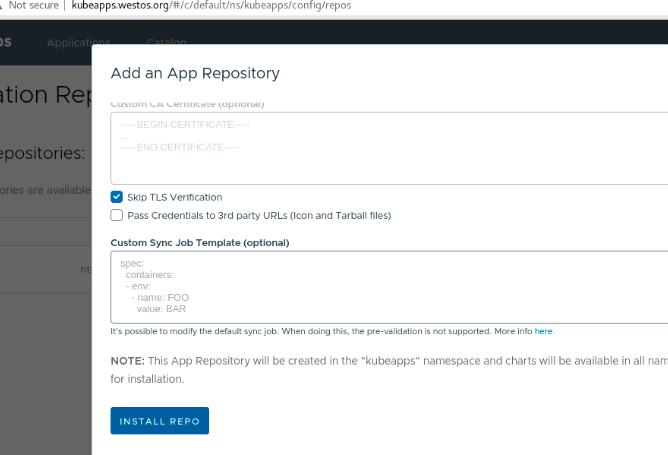
添加成功
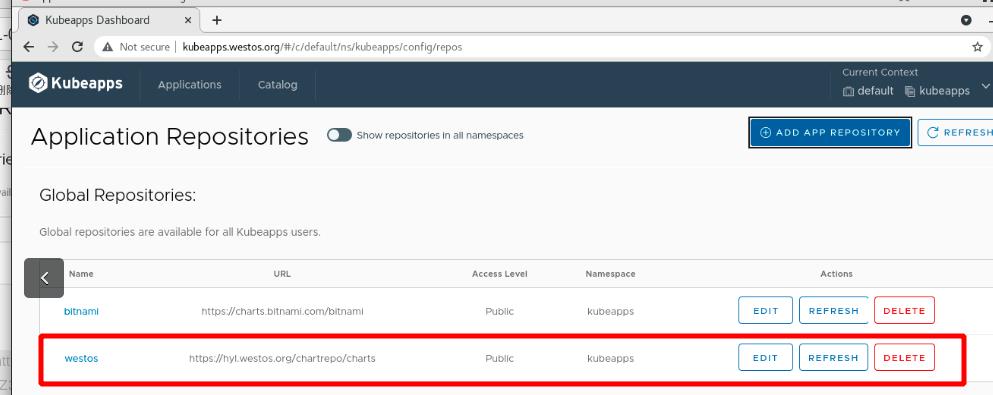

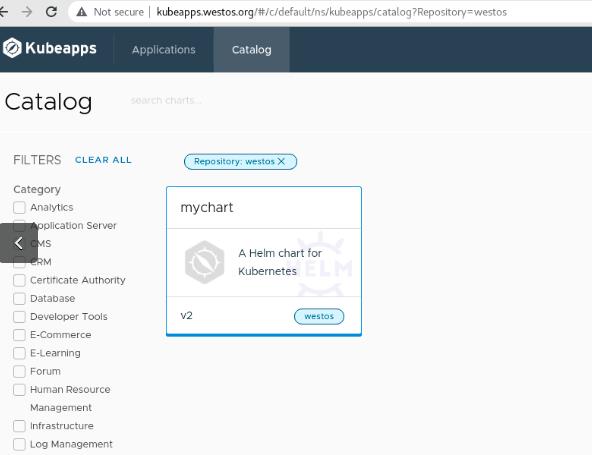
kubeapps结合harbor仓库管理helm应用
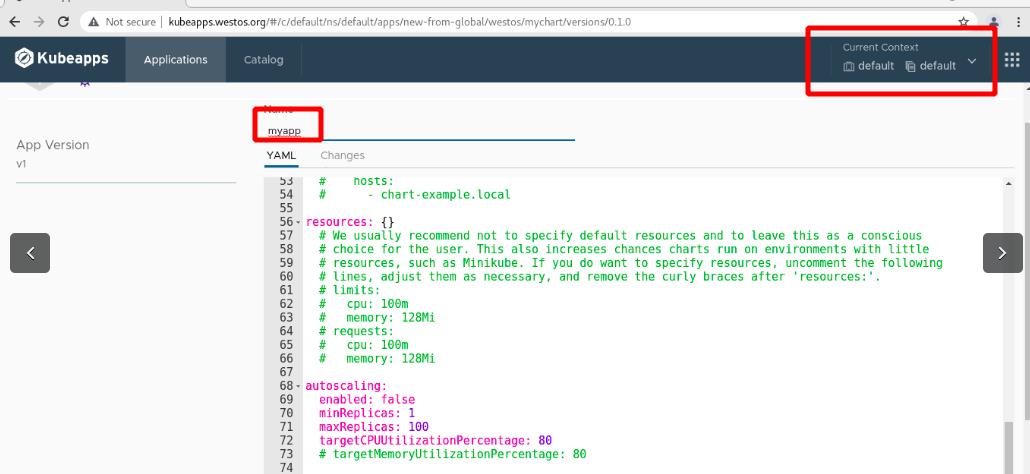

查看pod的健康状况,集群内部访问成功

集群外部使用ingress方式访问
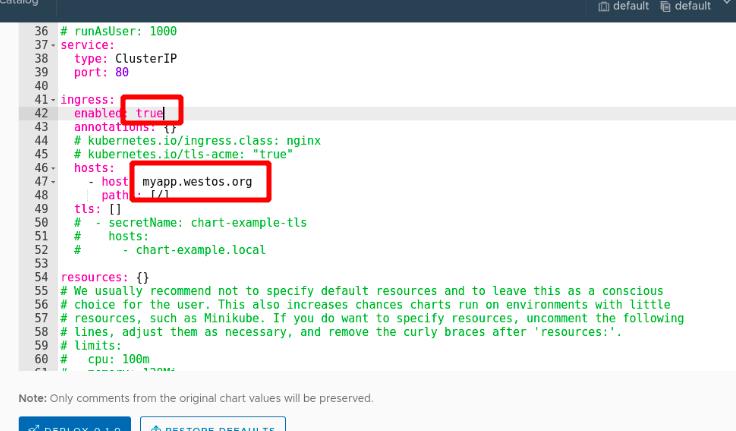
添加域名解析

外部访问测试
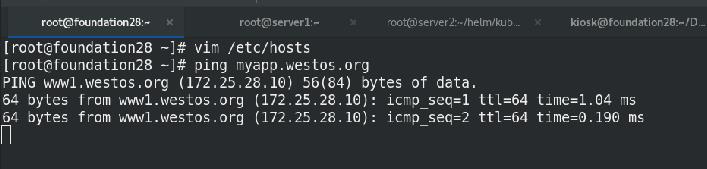

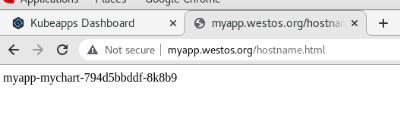
增加副本数
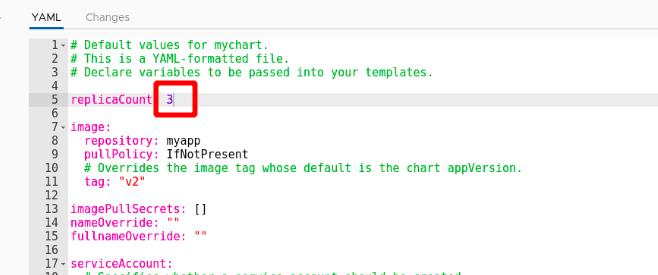
增加副本数量至3个
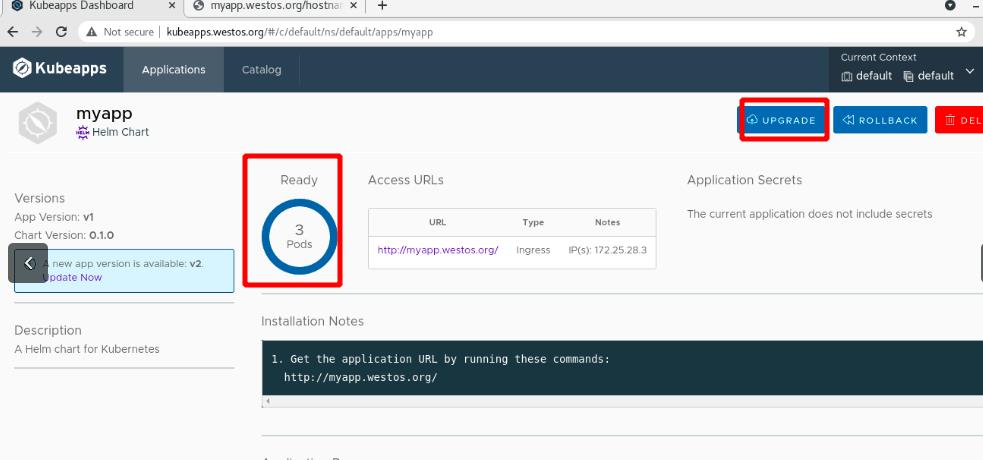
外部访问成功,且负载均衡
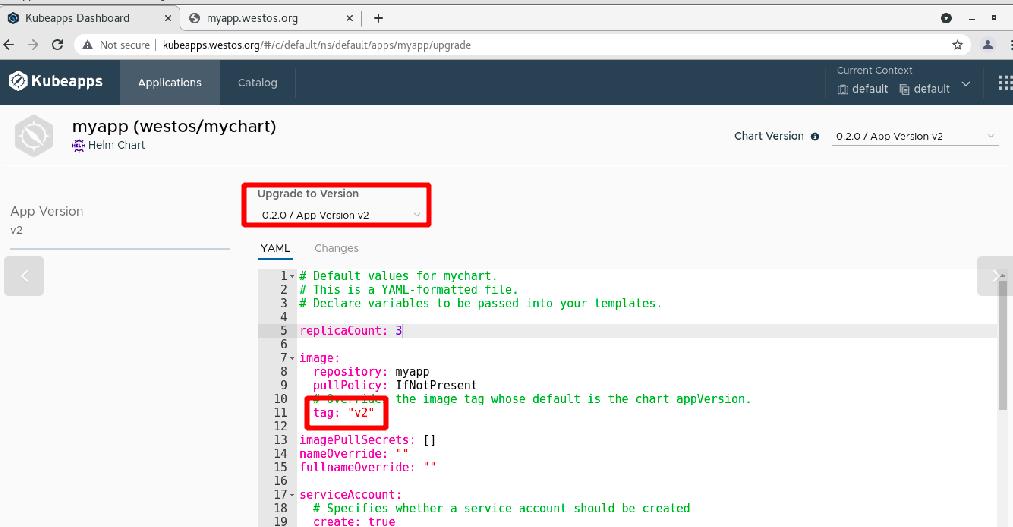
版本更新
(v1-v2)
外部访问测试

版本回滚
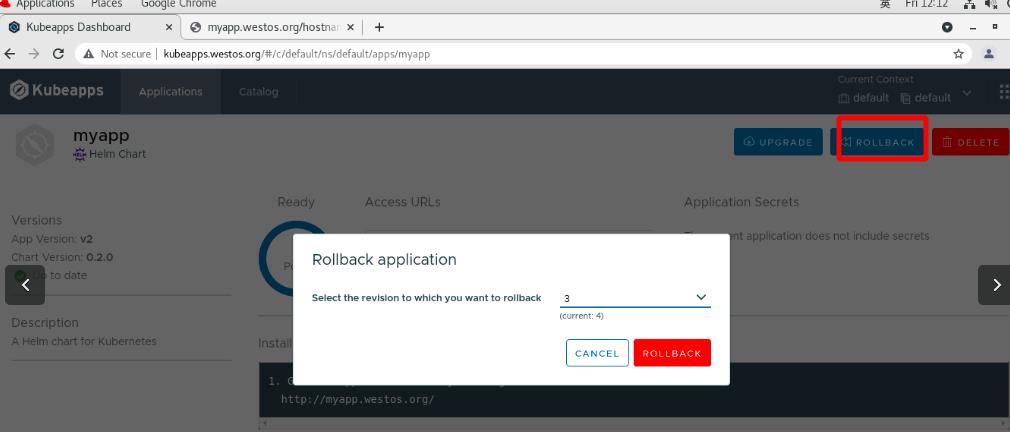
1是404!!!


选择2
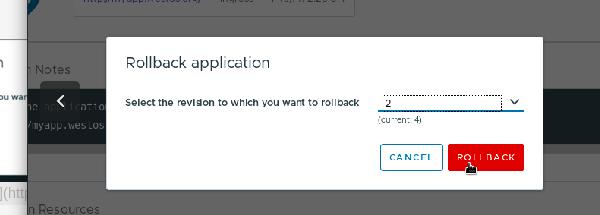
可以回滚成功
删除
二 prometheus
简介
Prometheus 是由 SoundCloud 开源监控告警解决方案,与Kubernetes同属CNCF,也是仅次于k8s的第二大开源项目。Prometheus 提供了通用的数据模型和便捷的数据采集、存储和查询接口,同时基于Go实现也大大降低了服务端的运维成本,目前已支持Kubernetes、Etcd、Consul等多种服务发现机制。
相较于zabbix,zabbix监控服务,Prometheus监控应用。
Prometheus监控:
把普罗米修斯采集的自定义指标转化为集群内的指标,为量度指标,与hpa结合,实现自动伸缩
metrics-server只能监控核心指标:cpu和mem,监控其他指标使用prometheus

Prometheus Server直接从HTTP接口或者Push Gateway拉取指标(Metric)数据。Prometheus Server在本地存储所有采集的指标(Metric)数据,并在这些数据上运行规则,从现有数据中聚合和记录新的时间序列,或者生成告警。Alertmanager根据配置文件,对接收到的告警进行处理,发出报警。在Grafana或其他API客户端中,可视化收集的数据。exporters:负责向prometheus server做数据汇报的程序统。而不同的数据汇报由不同的exporters实现,比如监控主机有node-exporters,mysql有MySQL server exporterpull metrics:正常拉取,server从agent正常拉取,pod内的附属容器作为普罗米修斯的agent,pod内loclahost可以采集,客户端应用上传到网关,普罗从网关拉取web Ui:主要通过grafana来实现webui展示
metrics-server只能监控核心指标:cpu和mem,监控其他指标:如应用,数据格式和k8s不兼容,需要Grafana插件,接入api-server(身份键权)
prometheus-operator监控:
https://github.com/coreos/prometheus-operator/
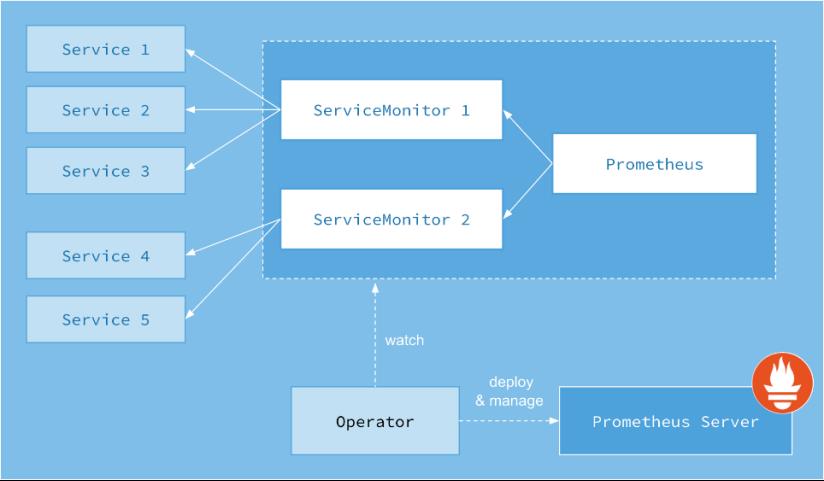
1 部署prometheus-operator集群监控
添加aliyun的repo源,拉取chart到本地
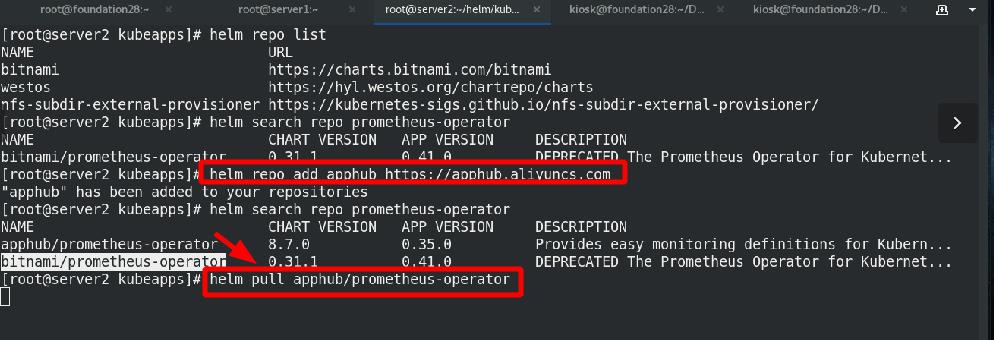
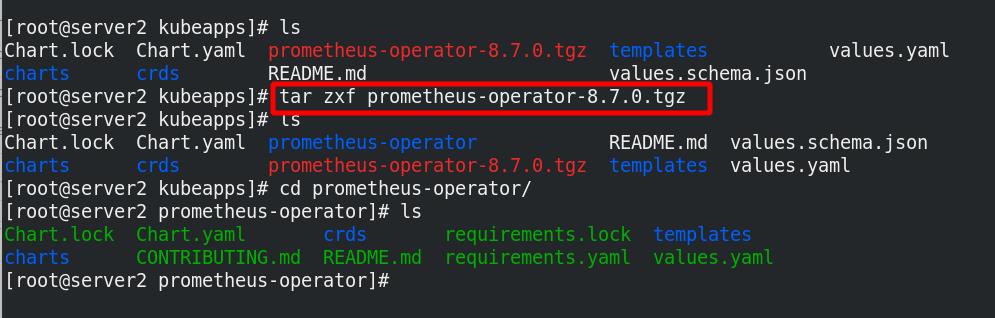
解压后进入工作目录
(1)grap:图像化
(2)kube-metrics :数据格式转化
(3)prometheus-node-exporter:取核心指标,与应用结合(nginx-node,mysql-node)


准备好4个value文件中需要的镜像,上传至私有仓库

修改主value.yaml文件和各个子服务value.yaml,共4个value.yaml文件,修改镜像路径到私有harbor仓库,打开ingress服务并添加hosts.
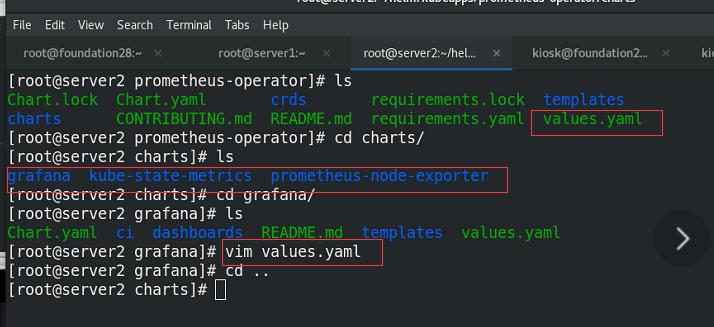
主yaml文件修改(3个ingress和8个镜像位置):
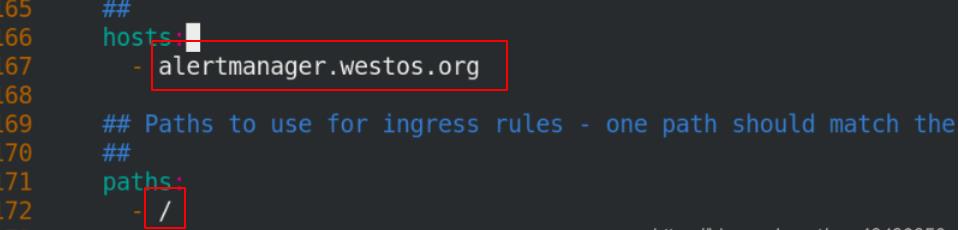
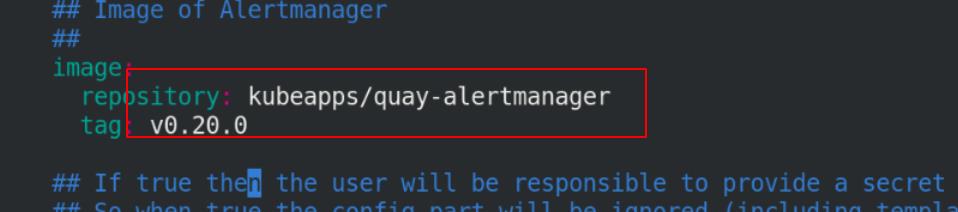
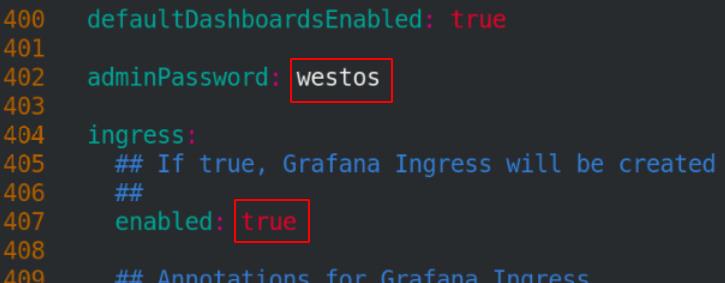






修改grafana目录下的yaml文件(4个镜像和1个ingress)
cd charts/
cd grafana/
vim values.yaml
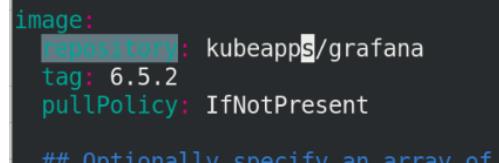
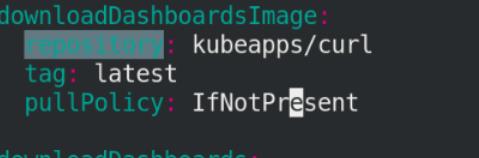
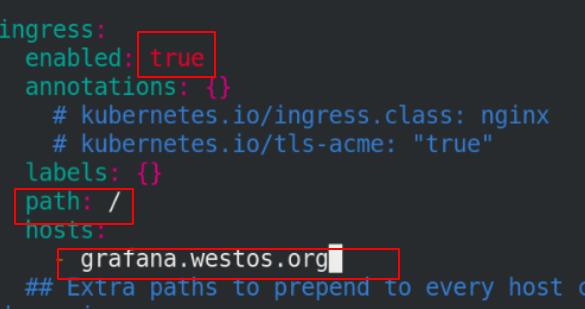


修改kube-state-metrics目录下的yaml文件(1个镜像)
cd kube-state-metrics/
vim values.yaml
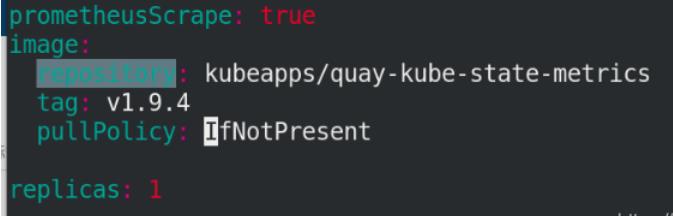

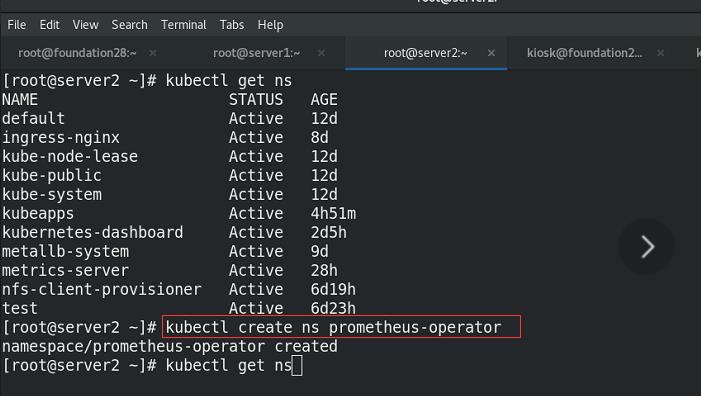
创建namespace,并指定namespace安装
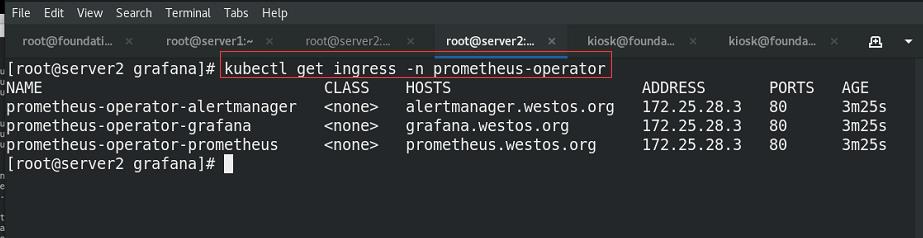
查看ingress状态
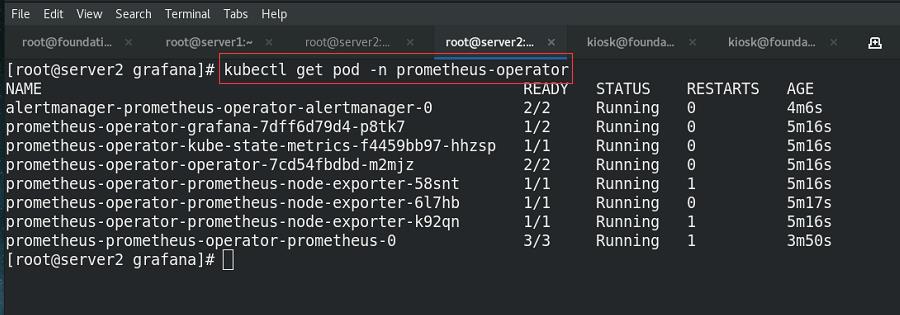
查看节点的状态
添加解析

网页访问测试

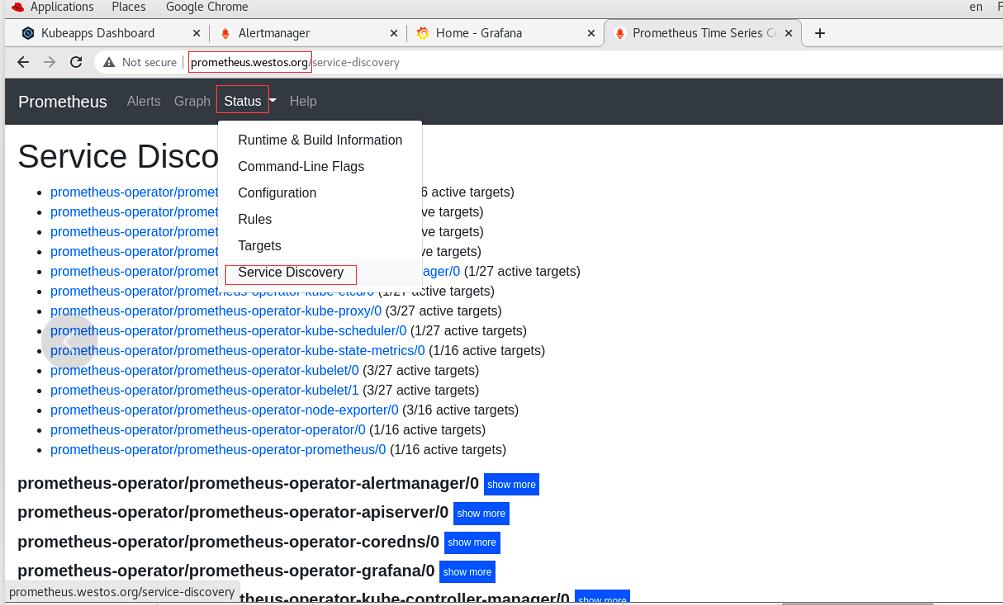
测试成功



选择prometheus
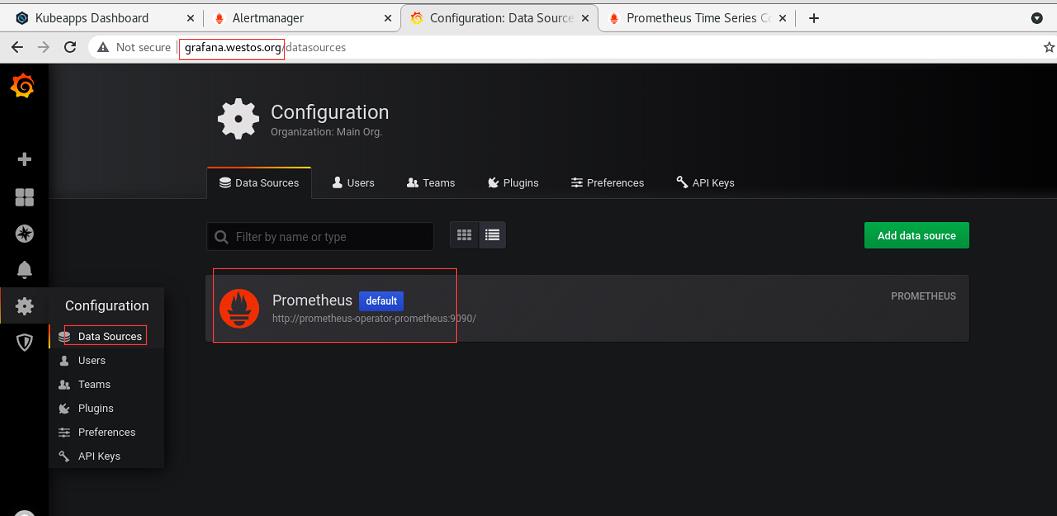
成功抓取到数据(注意时间同步)

2 使用prometheus-operator集群监控nginx
Loadbalancer
搜索nginx,使用helm图形化界面安装nginx

部署9.4.2版本的

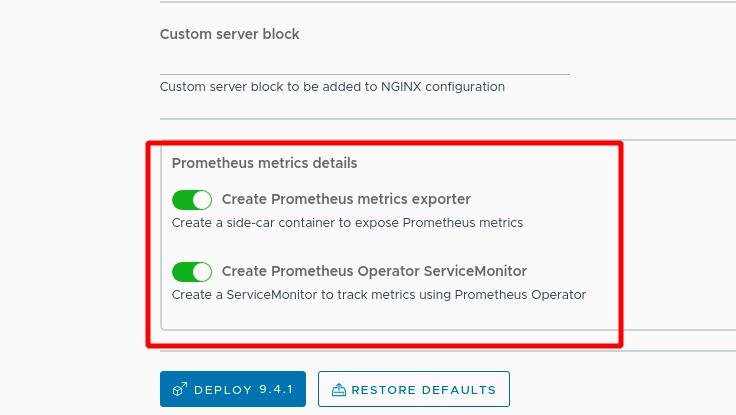
修改yaml文件中私有仓库位置为reg.westos.org,指定ns
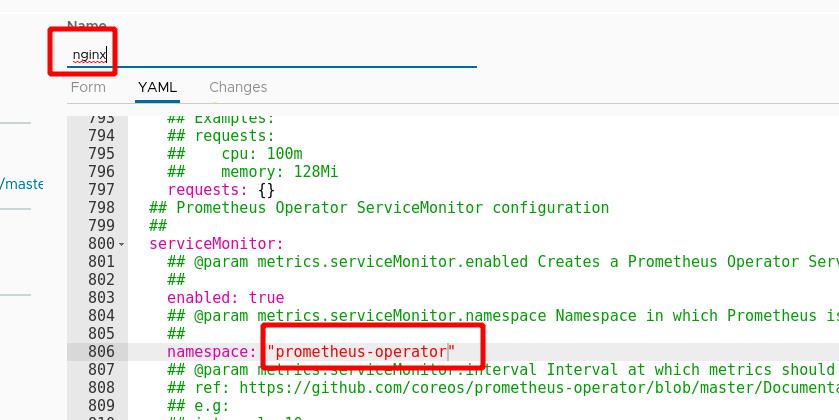
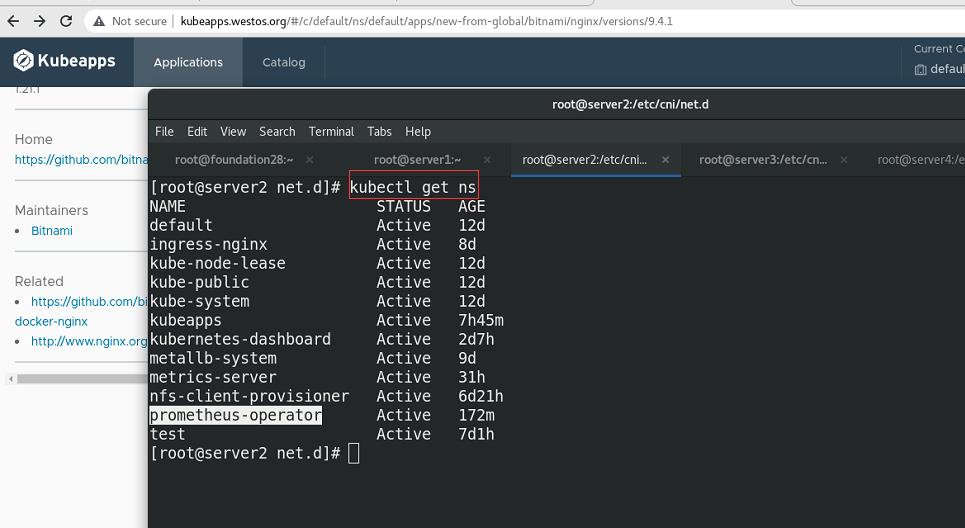
私有仓库中准备镜像

nginx成功部署,可以看到svc分配的IP地址
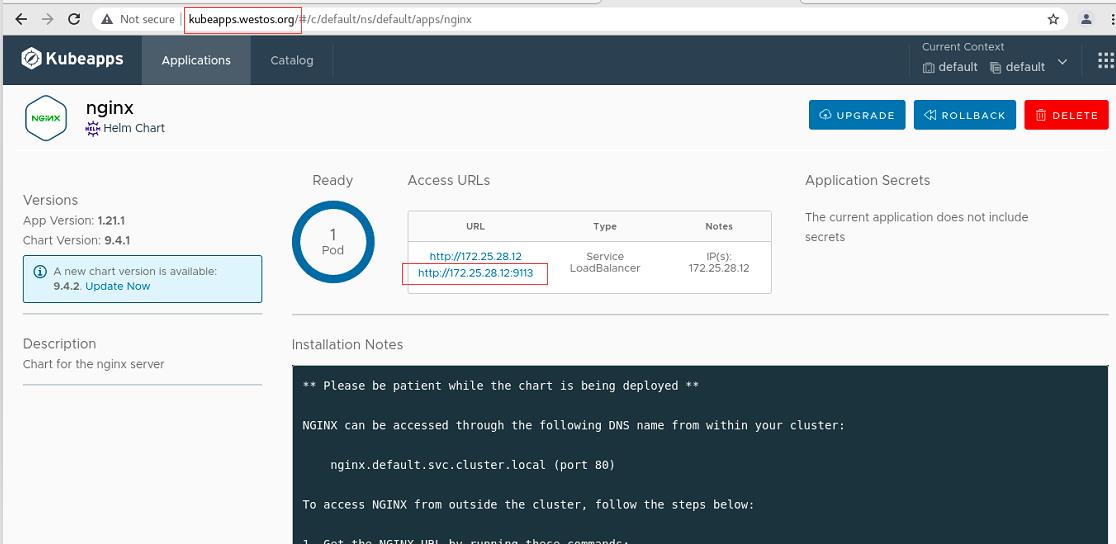
查看svc分配的IP地址

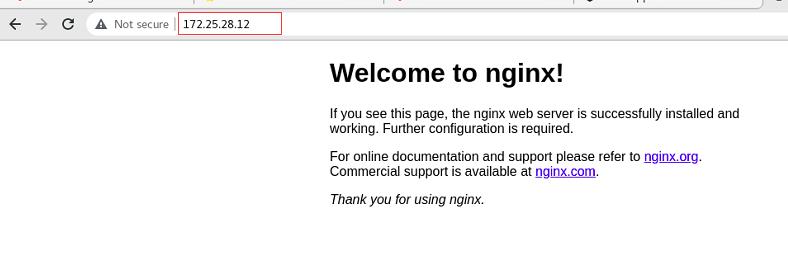
访问IP,可以看到nginx发布页面!!
此时的nginx还无法被prometheus发现,原因是未添加对应的标签release=prometheus-operator!!!
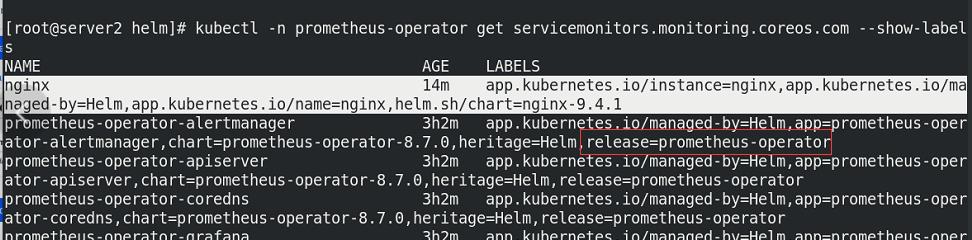
添加标签给nginx

此时在prometheus.westos.org下的status中的Service Discovery可以看到被发现的nginx服务

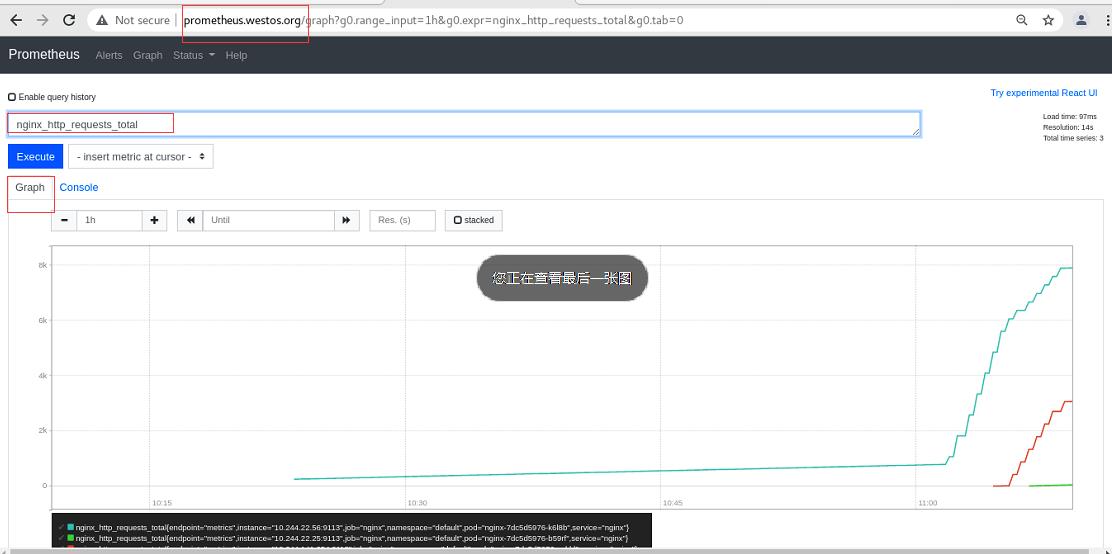
选择nginx的访问流量指标
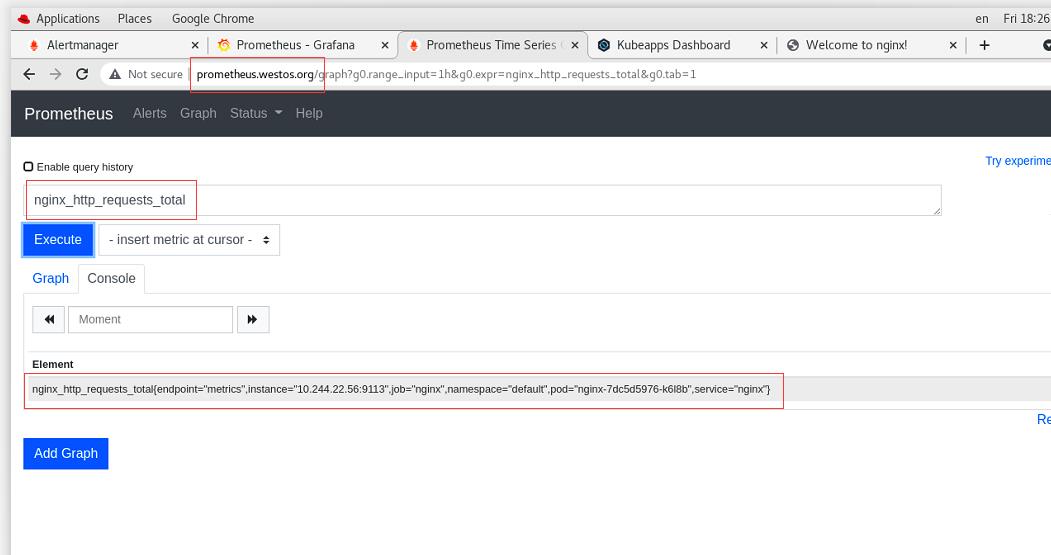
点击Graph 添加Graph
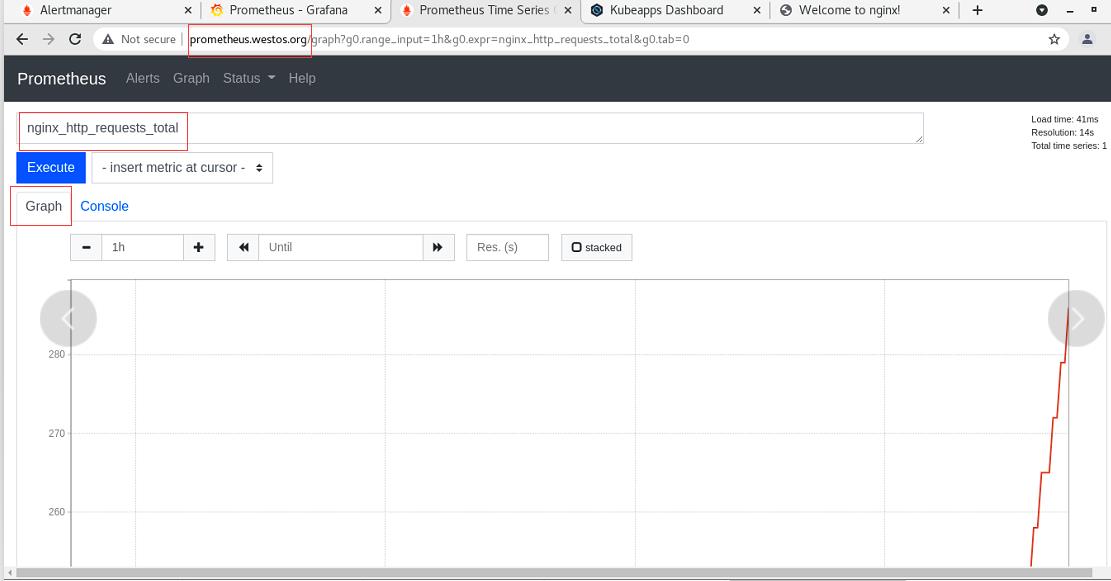
可以看到图形
3 prometheus实现k8s集群的hpa动态伸缩(nginx)
由于数据不兼容,需要进行转化
添加prometheus-adapter插件
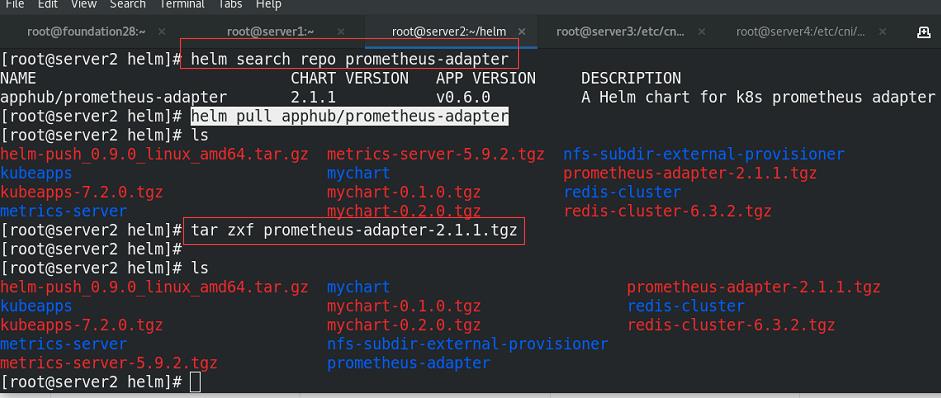
准备镜像

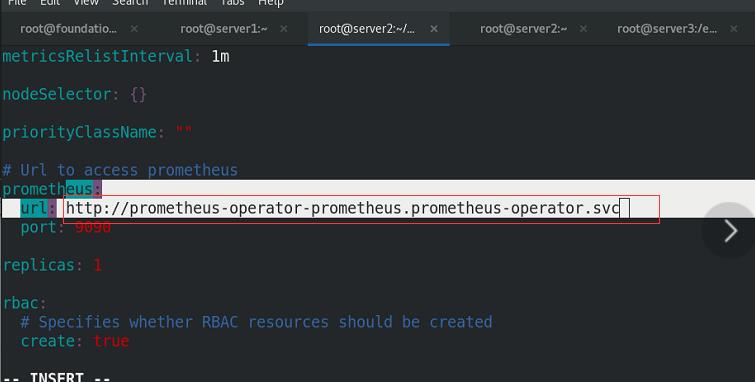
编辑values.yaml文件,修改镜像的信息

9090: prometheus的server的端口(无头服务)
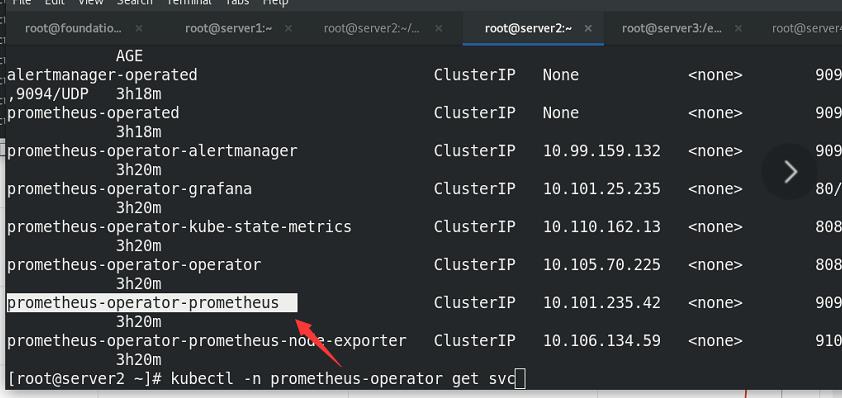
进入一个镜像,查看它是否有解析

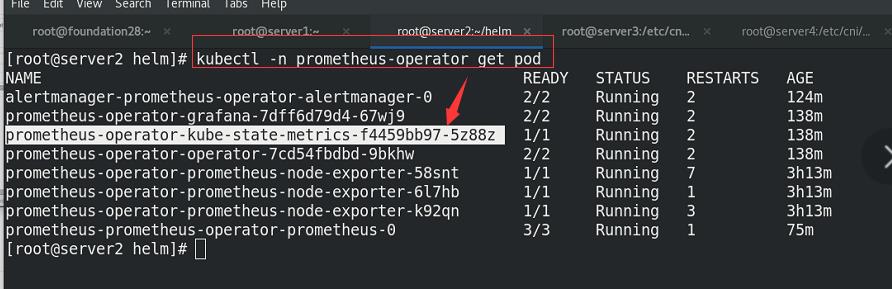
可以看到一个pod中有两个容器,其中一个是nginx服务本身,另一个:9113端口是对prometheus监控开放的agent(metrics的)。
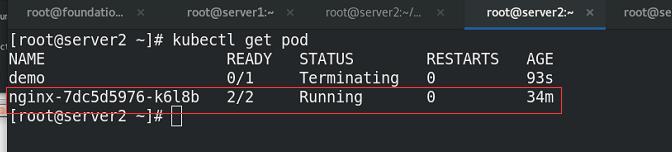
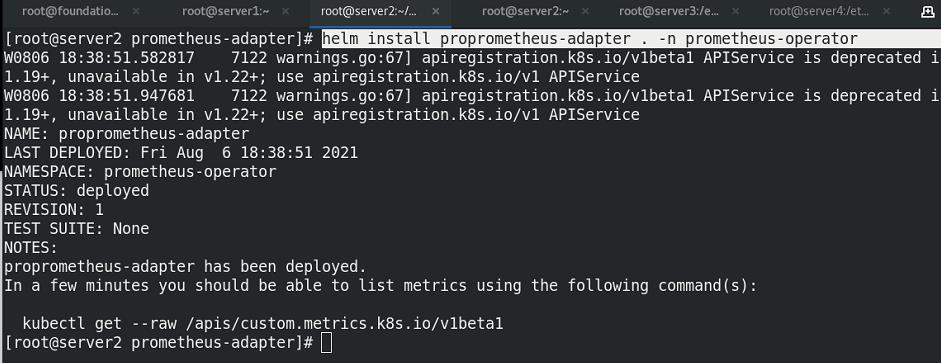
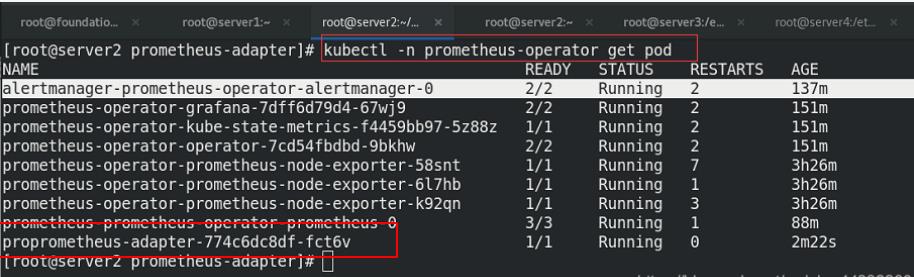
指定namespace安装

查看有了custom.metrics!!!数据格式可以匹配

查看pod信息
一个pod内两个容器
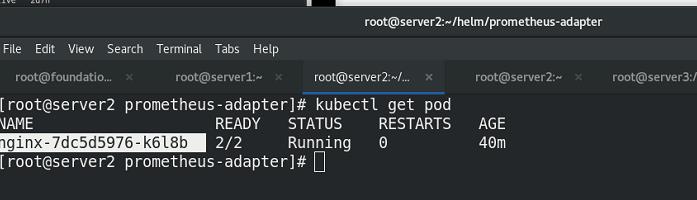
获取nginx的访问流量指标
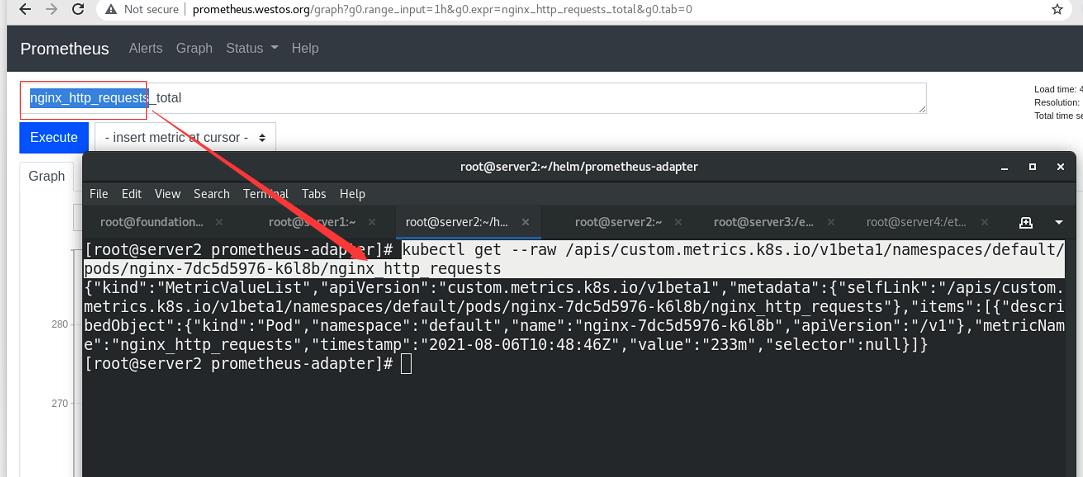
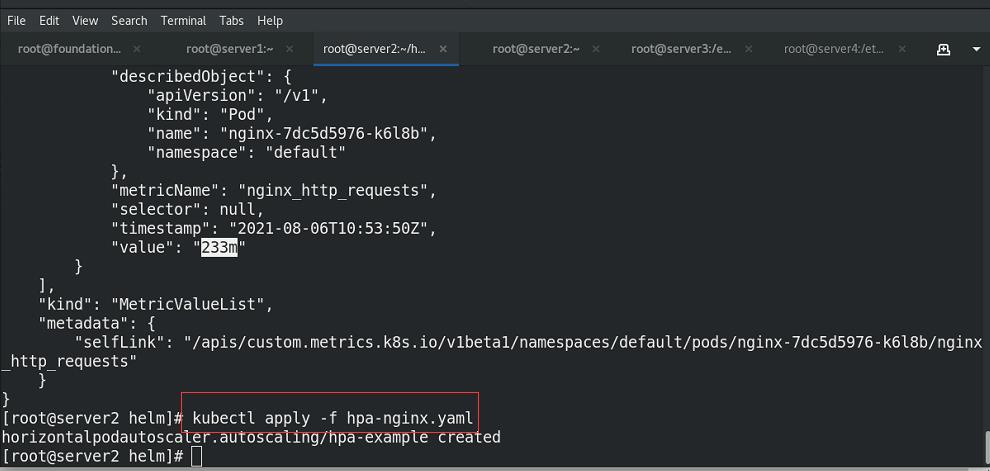
获取nginx的访问流量指标,以python格式输出,发现value为233m

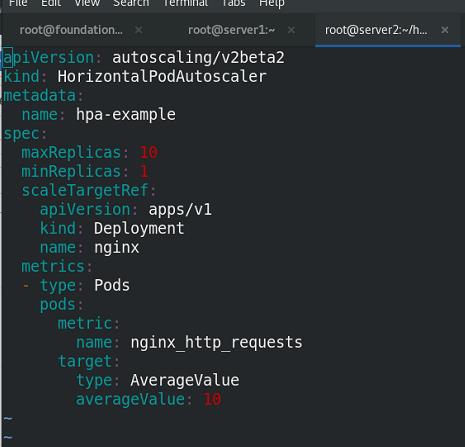
使用hpa测试监控

设定平均值为10个访问请求
hpa:平均和固定值
执行yaml文件
查看nginx的hpa

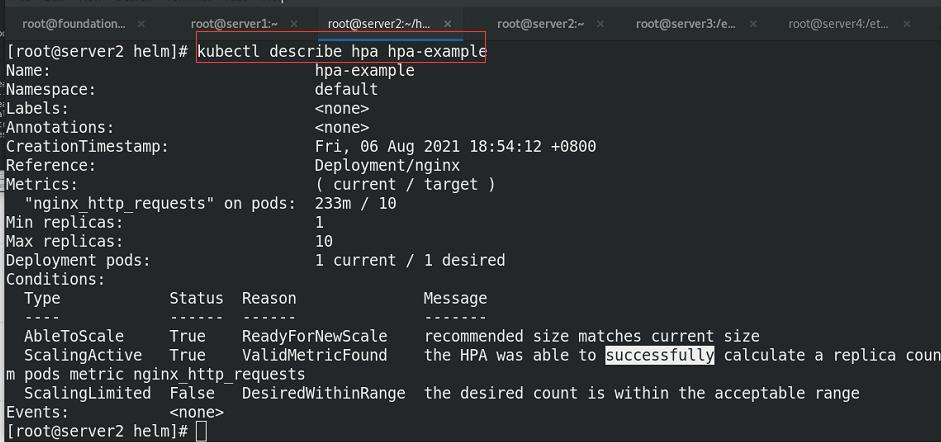
使用hey访问nginx,给予压力
将hey的二进制程序放到/usr/local/bin/



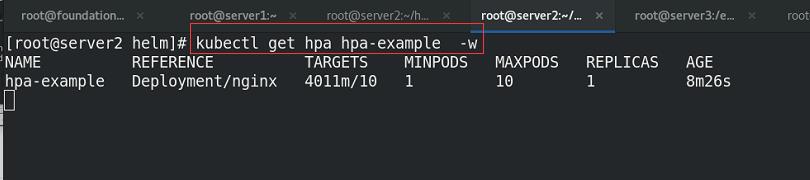
设定每秒25个请求去访问nginx,10*1000=10000

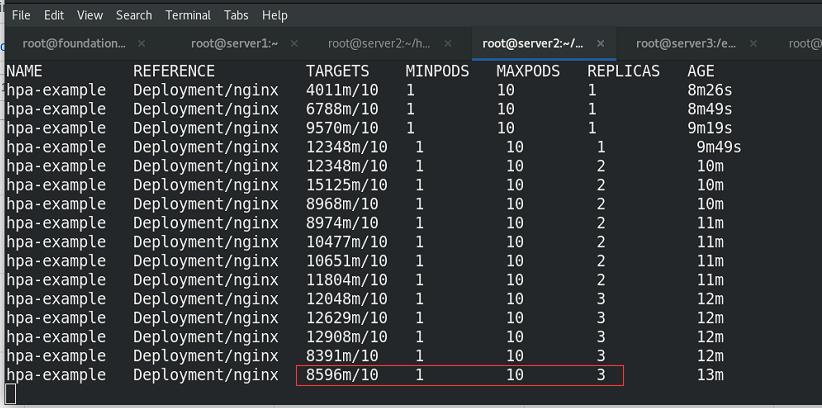
持续查看hpa状况,可以看到集群根据压力大小进行动态添加副本,实现动态伸缩
yaml文件中设定了每个pod最多10个请求,所以,需要3个replicas之后就可以稳定!!!
hpa的伸缩算法:<0.9和<1.1
选择graph可以查看到每个时刻的数据(访问nginx的请求)
以上是关于K8sHelm配置图形,prometheu(采集的自定义指标转化为集群内的量度指标,与hpa结合,实现自动伸缩)的主要内容,如果未能解决你的问题,请参考以下文章
Nacos + Grafana + Prometheu安装(standalone-derby)