(源码剖析)HashSet集合是如何保证元素的唯一性
Posted 我永远信仰
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了(源码剖析)HashSet集合是如何保证元素的唯一性相关的知识,希望对你有一定的参考价值。
HashSet集合特点
- 底层数据结构是哈希表
- 对集合的迭代顺序不作任何保证,也就是说不保证存储和取出的元素顺序一致
- 没有带索引的方法,所以不能使用普通for循环遍历
- 由于是Set集合,所以是不包含重复元素的集合
HashSet集合保证元素唯一性的源码分析
HashSet<String> hashSet = new HashSet<>();
//添加元素
hashSet.add("java");
hashSet.add("hello");
hashSet.add("world");
hashSet.add("world");
//---------------------------
//源码部分:
//跟进add方法,参数就是我们传进来的参数,比如E是String类型,e=hello
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
//hash(),该方法返回的是一个hash值
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
//跟进put,hash值与元素的hashCode相关
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
//跟进putVal,这里我们只需要观察前面这两个参数,
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
//元素为结点的数组,hash的一种实现
Node<K,V>[] tab; Node<K,V> p; int n, i;
//为空,长度为0。意思是如果哈希表未初始化,就对其进行初始化
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
//根据对象的哈希值计算对象的存储位置,如果该位置没有元素,就存储元素,
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {//如果该位置由元素
Node<K,V> e; K k;
/*
存入的元素和之前的元素比较哈希值
如果哈希值不同,会继续向下执行,把元素添加到集合
如果哈希值相同,会调用对象的equals方法比较
如果返回false,会继续向下执行,把元素添加到集合
如果返回true,说明元素重复
*/
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))//equals方法比较
e = p;//说明元素重复,并没有将它添加到集合。
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {//哈希值不同
for (int binCount = 0; ; ++binCount) {
//把元素添加到集合
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
流程图:
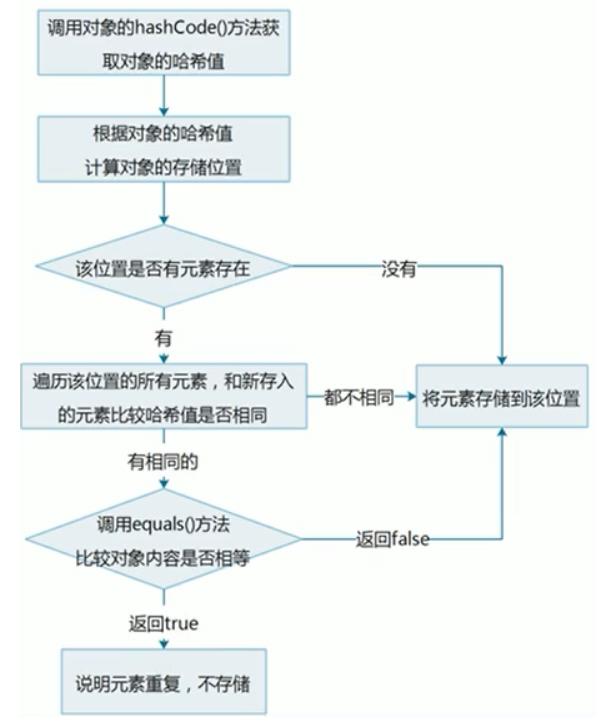
总结:
- 它是根据hashCode方法和equals方法来确认元素是否重复
- HashSet集合存储元素,要保证元素的唯一性,需要重写hashCode方法和equals方法
以上是关于(源码剖析)HashSet集合是如何保证元素的唯一性的主要内容,如果未能解决你的问题,请参考以下文章