论文泛读197带有注意力的 TextCNN 用于文本分类
Posted 及时行樂_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文泛读197带有注意力的 TextCNN 用于文本分类相关的知识,希望对你有一定的参考价值。
贴一下汇总贴:论文阅读记录
论文链接:《TextCNN with Attention for Text Classification》
一、摘要
绝大多数文本内容都是非结构化的,这使得自动分类成为许多应用程序的一项重要任务。文本分类的目标是将文本文档自动分类为一个或多个预定义的类别。最近提出的用于文本分类的简单架构,例如由 Kim, Yoon 提出的用于句子分类的卷积神经网络,显示出有希望的结果。在本文中,我们建议将注意力机制纳入网络以提高其性能,我们还提出 WordRank 用于词汇选择以减少网络嵌入参数并以最小的精度损失加速训练。通过采用提出的想法,TextCNN 在 20News 上的准确率从 94.79 增加到 96.88,此外,使用 WordRank 可以在几乎没有精度损失的情况下显着减少嵌入层的参数数量。通过使用 WordRank 进行词汇选择,我们可以将参数数量从 7.9M 减少到 1.5M,减少 5 倍以上,准确率只会下降 1.2%。
二、结论
本文介绍了将注意力机制结合到TextCNN[3]的有效性,这导致模型精度的显著提高,并被证明有助于超参数选择(过滤器大小)。此外,论文还论证了与常用的基于频率的选择标准相比,将页面排名应用于词汇选择是一种更有效的方法。
为了进一步推进这里所做的工作,可以合并赖、四维等人提出的模型“用于文本分类的递归卷积神经网络”[4]看看结合这两种架构能否产生更有效的文本分类特征提取方法。
PageRank是一种有效但有些过时的排序算法,由于相似矩阵的巨大规模,它在可以排序的单词数量方面也受到限制。对RankNet和LambdaRank等模型进行排名的更高级的学习可能会产生更令人印象深刻的结果。
三、model
TextCNN:
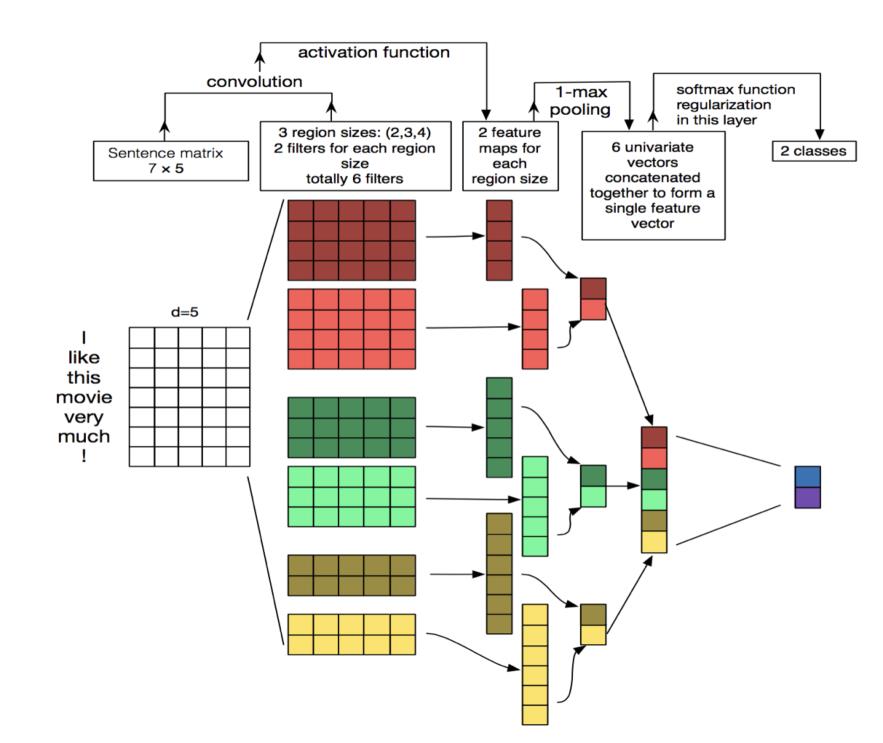
词汇选择过程:
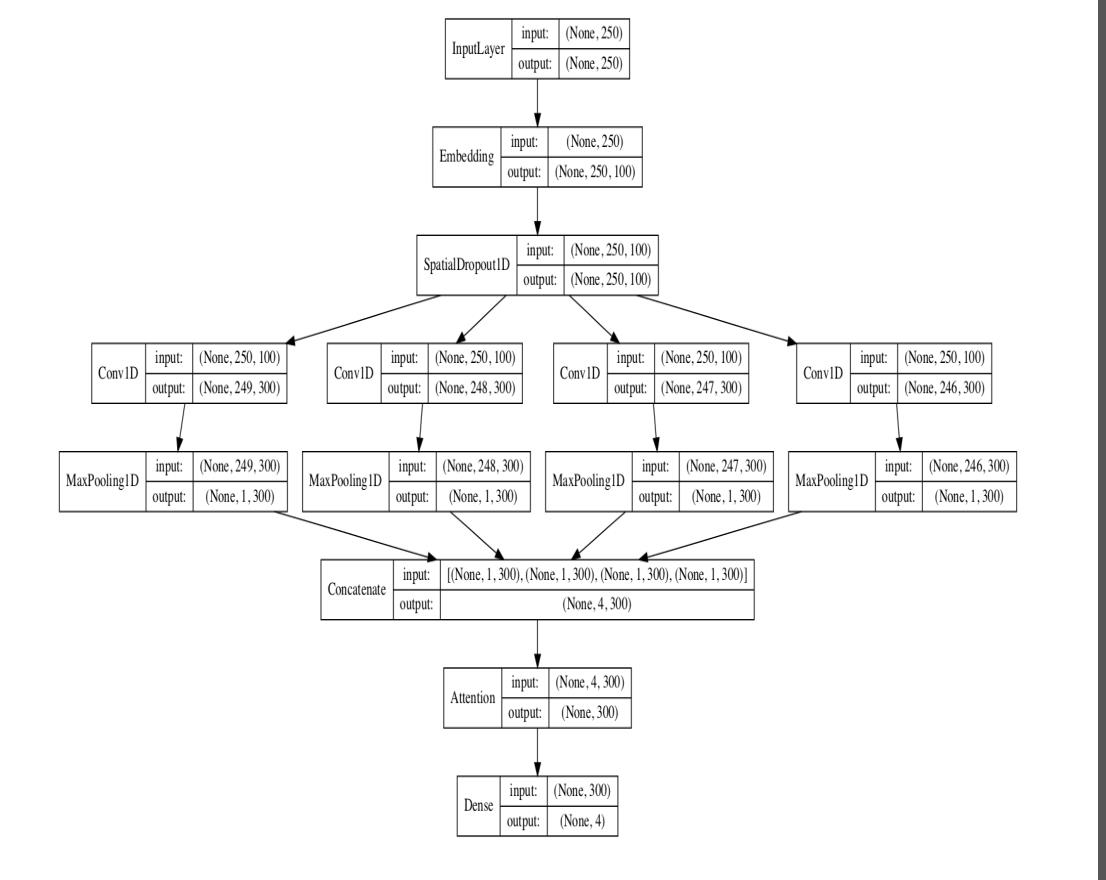
- Spatial Dropout
- Pooling
- Attention
- WordRank
以上是关于论文泛读197带有注意力的 TextCNN 用于文本分类的主要内容,如果未能解决你的问题,请参考以下文章