JavaLearn # (10)集合List栈队列Set外部比较器哈希表
Posted LRcoding
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了JavaLearn # (10)集合List栈队列Set外部比较器哈希表相关的知识,希望对你有一定的参考价值。
1. 引入集合
1.1 集合的使用场合
需要将一些相同结构的个体整合在一起时,可以使用集合。
1.2 集合和数组的区别
- 相同:都可以存储多个对象(
集合的元素,必须是对象类型,不能是基本类型),对外作为一个整体存在 - 不同:
- 数组长度必须在初始化时指定,且固定不变
- 数组存储时采用连续的空间,删除和添加效率低下
- 数组无法直接保存映射关系
- 数组缺乏封装,操作繁琐
1.3 集合框架
Java 提供了一套使用方便、性能优良的接口和类,位于 java.util 包中
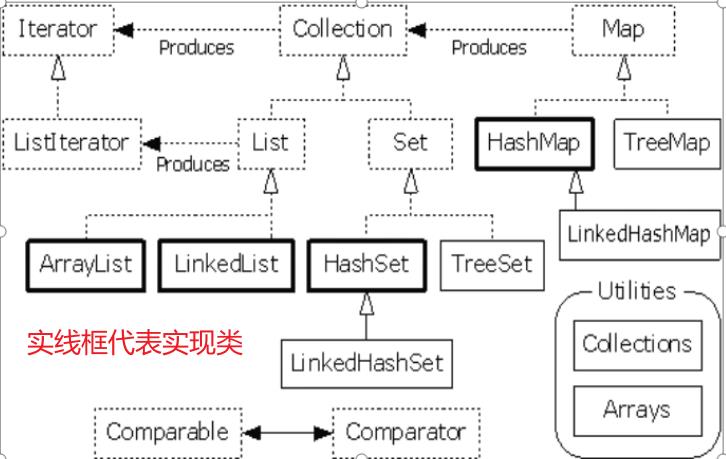
- 集合架构:
- Collection 接口存储 不唯一、无序 的对象
- List接口:不唯一、有序(索引顺序)
- Set接口:唯一、无序
- Map接口:键值对象
- key 唯一、无序
- value 不唯一、无序
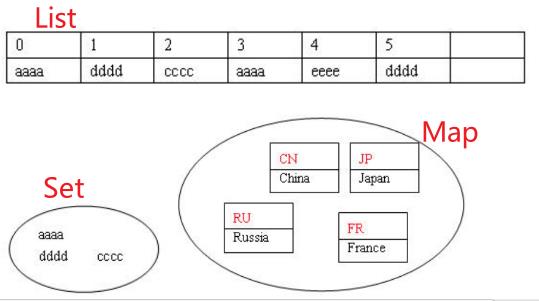
2. List的主要实现类
有序(索引有序)、不唯一
2.1 ArrayList
- 在内存中分配连续的空间,实现了长度可变的数组
- 优点:遍历元素和随机访问元素的效率比较高
- 缺点:添加和删除时,需要移动大量元素,效率低,按照内容查找效率低
2.2 LinkedList
- 采用双向链表存储方式
- 优点:插入、删除元素效率高(倒是需要先进行效率低的查询)
- 缺点:遍历和随机访问元素效率低下
3. ArrayList
3.1 简单使用
使用 ArrayList 存储多个分数的信息:
// 1.创建一个 ArrayList 对象,用来存储信息
ArrayList list = new ArrayList();
ArrayList list2 = new ArrayList();
// 2.向 list 中添加分数
list.add(76); // 实际是 list.add(Integer.valueOf(76));
list.add(85);
list.add(76);
list.add(99);
// [76, 85, 76, 99]
list.add(2, 134); // 实际是 list.add(new Integer(134));
// [76, 85, 134, 76, 99]
list2.add(13);
list2.add(16);
list.addAll(list2); // 一次添加多个元素
// [76, 85, 134, 76, 99, 13, 16]
// 3.操作 list
System.out.println(list.size()); // list 的长度
System.out.println(list); // 输出 list
System.out.println(list.get(1)); // 获取第 2 个元素
// 4.循环输出 list 的值 -- 使用 for 循环
System.out.println("-------for 循环-------");
for (int i = 0; i < list.size(); i++) {
System.out.print((int)list.get(i) + "\\t");
}
// 循环输出 list 的值 -- 使用 for-each 循环
System.out.println("\\n-------for-each 循环-------");
for (Object o : list) {
System.out.print((int)o + "\\t");
}
// 循环输出 list 的值 -- 使用迭代器 Iterator
System.out.println("\\n-------迭代器 Iterator-------");
Iterator iterator = list.iterator();
while (iterator.hasNext()) {
Object next = iterator.next();
System.out.print((int)next + "\\t");
}
3.2 使用泛型
上面代码的缺点:
-
不安全
list.add(76);
list.add(99);list.add(“lwclick”); // 允许添加,编译时不会报错,运行时报错
-
繁琐,需要强制转换
int num = (int) list.get(i);
解决方法:使用泛型 ArrayList<Integer> list = new ArrayList<Integer>();
-
安全
list.add(76);
list.add(99);list.add(“lwclick”); // 不允许添加,编译时报错
-
简单,无需强制转换
int num = list.get(i);
Iterator<Integer> iterator = list.iterator();
3.3 ArrayList 的更多方法
/**
* ArrayList 的其他方法:
* (1)添加
* list.add(123)
* list.add(1, 100)
* list.addAll(list2)
* list.addAll(0, list2)
*
* (2)查询
* list.get(3)
* list.size()
* list.contains(123); // 是否包含 123
* list.isEmpty(); // list是否为空
*
* (3)删除
* list.clear()
* list.remove(new Integer(89)); // 根据内容删除,由于下标也是数值,所以需要使用对象
* list.remove(2); // 根据下标删除
* list.removeAll(list2); // 从 list 中【删除】所有 list2 里有的值
* list.retainAll(list2); // 在 list 中【保留】所有 list2 里有的值
*
* (4)修改
* list.set(1, 98); // 将下标为 1 的位置,设置为 98
*/
3.4 ArrayList的源码
ArrayList 底层,是一个长度可以动态增长的 Object 数组(StringBuffer底层是一个动态增长的char数组)
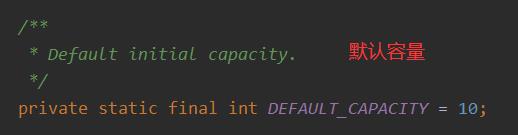
源码解析–成员变量
JDK1.7中,使用 无参构造方法创建 ArrayList 对象时,默认底层数组长度为 10:
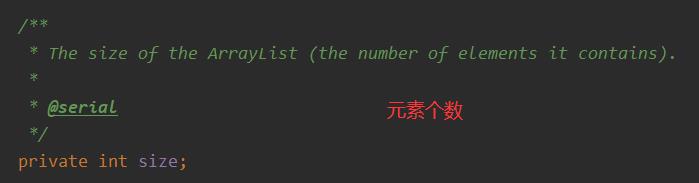
JDK1.8中,使用 无参构造方法创建 ArrayList 对象时,默认底层数组长度为 0,第一次添加元素,就需要扩容:

添加元素时的个数:
源码解析–实现,继承关系:

3.5 扩容机制
list.add(),如果使用的是 JDK1.8,第一次添加元素,就需要扩容(默认扩容1.5倍,如果还不够,就扩容为能容纳新增元素的最小数量)

4. LinkedList
4.1 概述
与 ArrayList 的方法和功能基本一致:
- 相同的地方:
- 代码没有变化(
list.add()、list.remove()、list.contains等) - 运行结果没有变化
- 代码没有变化(
- 变化的地方:
- 底层的存储结构发生了变化( ArrayList:数组。 LinkedList:双向链表 )
- 功能的底层实现改变,例如 add
- ArrayList:需要大量移动元素(效率低) --> 查找相反:效率高
- LinkedList:修改前后结点的指针(效率高) --> 查找相反:效率低
使用 ArrayList 和 LinkedList 的时机:
- 查询多:ArrayList
- 操作多:LinkedList
LinkedList 相比 ArrayList 提供了更多的方法:
// 多继承了一个 Deque 接口
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable {}
list.addFirst(); list.addLast(); remove 和 get 方法也具有
基于此,声明时,使用:List<Integer> list = new ArrayList<>();
4.2 LinkedList 源码
底层是一个双向链表

LinkedList 还可以作为栈和队列使用
5. 栈和队列
/**
* public class Stack<E> extends Vector<E> {} 栈 -- 已经过时
*/
Stack stack = new Stack();
/**
* 双端队列,可以替代栈使用, push()入栈 pop()出栈 peek()获取栈顶元素
* 实现类: ArrayDeque底层数组, LinkedList底层链表
*/
Deque deque;
/**
* 队列
* 实现类: ArrayQueue底层数组, LinkedList底层链表
*/
Queue queue;
// 模拟放盘子
Deque<String> deque1 = new LinkedList<>();
deque1.push("盘子1");
deque1.push("盘子2");
System.out.println(deque1.peek()); // 盘子2
deque1.push("盘子3");
while (!deque1.isEmpty()) {
System.out.println(deque1.pop()); // 3 2 1的顺序
}
6. Set
无序的,唯一(没有重复的数据)。
Set 相对于 Collection(父类),没有增加任何方法,而 List 加了一些和索引相关的操作
6.1 HashSet
唯一,无序
- 采用 Hashtable 的 哈希表存储 结构
- 优点:添加快,查询快,删除快(按照内容操作的)
- 缺点:无序
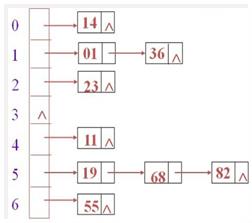
遍历的时候,从数组为 0 的开始循环后面的桶
6.2 LinkedHashSet
唯一,有序(添加顺序)
- 采用 哈希表存储 结构,同时使用 链表 维护插入的顺序
- 有序(添加顺序)
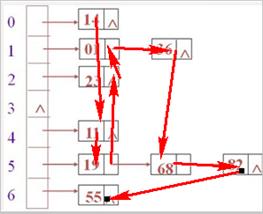
遍历的时候,根据链表的顺序来进行遍历
6.3 TreeSet
唯一,有序(自然顺序:字母,数字排列顺序等)
- 采用 **二叉树(红黑树)**的存储结构
- 优点:数值大小有序(中序遍历),查询速度比 List 快
- 缺点:查询速度没有 HashSet 快
6.4 简单使用
// 创建一个 HashSet 对象 : 唯一,无序,哈希表
Set<String> hashSet = new HashSet<>();
// 创建一个 LinkedHashSet 对象 : 唯一,有序(插入顺序),哈希表+链表
Set<String> linkedHashSet = new LinkedHashSet<>();
// 创建一个 TreeSet 对象 : 唯一,有序(自然顺序),红黑树
Set<String> treeSet = new TreeSet<>();
// 添加元素(操作都一样)
hashSet.add("java");
hashSet.add("mysql");
hashSet.add("ssm");
hashSet.add("html");
hashSet.add("java");
// 输出
System.out.println(hashSet.size()); // 3 唯一性
System.out.println(hashSet.toString()); // [java, mysql, html, ssm] 无序
// 遍历1 :for-each(无法使用 fori 循环)
for (String elem : hashSet) {
System.out.println(elem);
}
// 遍历2:使用 Iterator
Iterator<String> iterators = hashSet.iterator();
while (iterators.hasNext()) {
System.out.println(iterators.next());
}
6.5 复杂操作(存储自定义类)
定义 Student 类:
// Student类
public class Student {
private int sno;
private String name;
private double score;
// getter,setter,toString,构造方法
}
存储学生信息:
Set<Student> set = new HashSet<>();
// Set<Student> set = new HashSet<>();
// Set<Student> set = new HashSet<>();
Student stu1 = new Student(1, "lisi", 90);
Student stu2 = new Student(2, "zhangsan", 67);
Student stu3 = new Student(3, "wangwu", 86);
Student stu4 = new Student(1, "lisi", 90); // 虽然是不同的对象,但是值是一样的,可以认为是一个学生
set.add(stu1);
set.add(stu2);
set.add(stu3);
set.add(stu4);
System.out.println(set.size()); // 4 --> 没有保证唯一性???
System.out.println(set.toString());
课程(String类)放入HashSet,LinkedHashSet ,TreeSet 都可以正常实现功能,但是自定义类(Student)放入时有问题。
问题1:Student (自定义类)放入到 HashSet、LinkedHashSet 中,无法保证唯一性
==》 解答1:任意对象放入 HashSet、LinkedHashSet 等,底层是 哈希表 的集合中,必须重写 hashCode()、equals() 方法
// Student类,进行 hashCode(),equals() 方法的重写
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Student student = (Student) o;
if (sno != student.sno) return false;
if (Double.compare(student.score, score) != 0) return false;
return name.equals(student.name);
}
@Override
public int hashCode() {
int result;
long temp;
result = sno;
result = 31 * result + name.hashCode();
temp = Double.doubleToLongBits(score);
result = 31 * result + (int) (temp ^ (temp >>> 32));
return result;
}
问题2:Student (自定义类)放入 TreeSet 中,直接抛出异常 java.lang.ClassCastException: com.lwclick.java.Student cannot be cast to java.lang.Comparable
==》 解答2:任意 对象 放入 TreeSet 等,底层是 红黑树 的集合中,必须实现 Comparable 接口(内部比较器)
public class Student implements Comparable<Student> {
// .....
@Override
public int compareTo(Student o) {
return this.sno - o.sno;
}
}
==》 comparable 只能实现一种比较规则,如果希望使用多种比较规则,使用 外部比较器 comparator
7. 外部比较器实现 TreeSet的存储
内部比较器:在实体类中实现 Comparable 接口,将最长使用的比较值定义在里面
外部比较器:如果使用次数较少,一般使用匿名内部类,在业务逻辑处定义(外部比较器优先级高)
Student stu1 = new Student(1, "lisi", 90);
Student stu2 = new Student(2, "zhangsan", 67);
Student stu3 = new Student(3, "wangwu", 86);
Student stu4 = new Student(4, "zhaoliu", 86);
Student stu5 = new Student(1, "lisi", 90);
// 定义外部比较器
Comparator comp = new Comparator<Student>() {
@Override
public int compare(Student stu1, Student stu2) {
double num1 = stu1.getScore();
double num2 = stu2.getScore();
if (num1 > num2) {
return 1;
} else if (num2 > num1) {
return -1;
} else {
// 如果分数相同的情况下,再比较学号,否则相同分数的只显示一个
return stu1.getSno() - stu2.getSno();
}
}
};
// 使用外部比较器
Set<Student> treeSet = new TreeSet<>(comp);
treeSet.add(stu1);
treeSet.add(stu2);
treeSet.add(stu3);
treeSet.add(stu4);
treeSet.add(stu5);
System.out.println(treeSet.size());
for (Student student : treeSet) {
System.out.println(student);
}
外部比较器如果使用次数很多,也可以定义成一个类,实现 Comparator类
public class StuScoreDescComparator implements Comparator<Student> {
@Override
public int compare(Student stu1, Student stu2) {
double num1 = stu1.getScore();
double num2 = stu2.getScore();
if (num1 > num2) {
return 1;
} else if (num2 > num1) {
return -1;
} else {
return 0;
}
}
}
// 使用
Comparator comparator = new StuScoreDescComparator();
Set<Student> treeSet = new TreeSet<>(comparator);
8. 哈希表的原理
8.1 引入哈希表
查找元素的几种方式:
- 在数组中,按索引进行查找:
- 不进行比较和技术,直接计算得到地址,效率最高,时间复杂度 O( 1)
- 如果是普通的,按照内容进行查找:
- 在无序数组中,按照内容查找,效率低下,时间复杂度是 O( n)
- 在有序数组中,按照内容查找,可以使用折半查找,时间复杂度 O( logn)
- 在二叉平衡树(首先是二叉查找树)中,按照内容查找,时间复杂度 O( logn)
哈希表:按照内容查找,同时通过计算得到地址,实现时间复杂度为 O( 1)的查询
===》 需要在数据的存储位置(数组的索引)与该数据的关键字之间,建立一种确定的对应关系,使每个数据的关键字与一个存储位置相对应
8.2 哈希表的结构和特点
hashtable,也叫散列表
最流行、容易理解的结构:顺序表 + 链表(桶) (主结构:顺序表,每个顺序表的节点再单独引出来一个链表)

数组下标为 1 的地方,后面有多个元素:是因为通过计算得到的数组索引位置,01、14、27等元素都需要放在下标为 1 的地方,所以依次往后链。
8.3 哈希表添加数据
-
计算哈希码,整数的哈希码就为它自己。
x = key.hashCode(); -
根据哈希码计算存储位置(数组的下标位置)
y = x % 数组的长度 -
存入指定的数组位置
-
情况1:如果存储位置是空 ===》 直接生成一个结点,存入数据,然后将结点的地址,存入该位置中
-
情况2:如果不是空的(
发生了冲突,需要通过 *equals()* 进行判断,判断是否为相同的内容),内容不同===》 调用 equals() 进行比较,添加到链表中,继续往后链
-
情况3:如果不是空的,但是内容相同 ===》 不再添加,保证唯一性
-
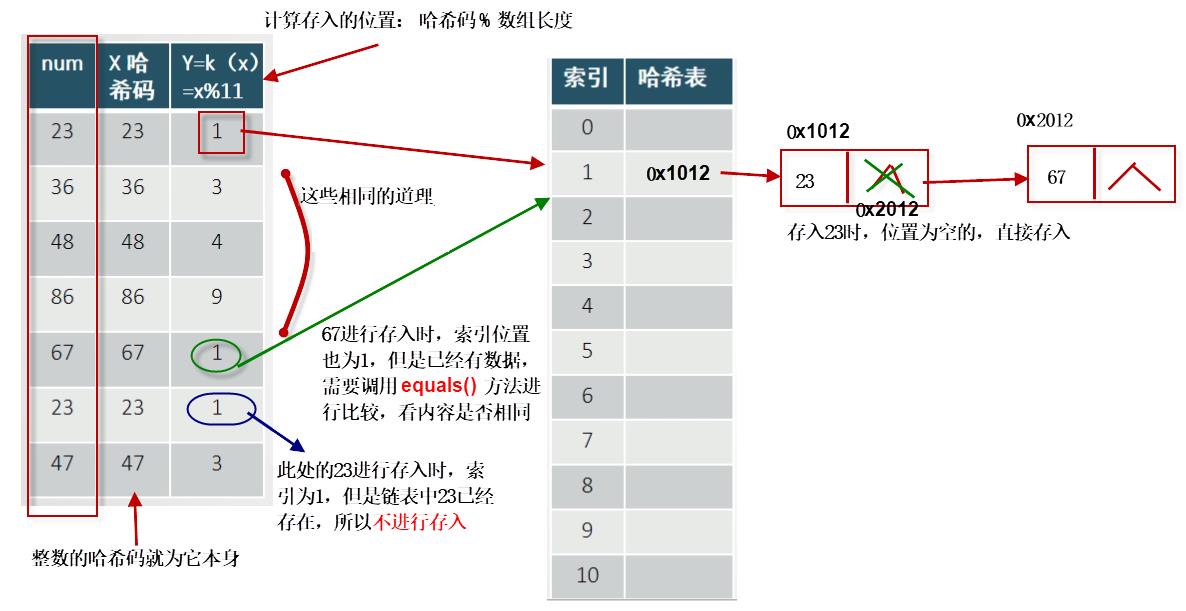
结论:添加快,唯一,无序
8.4 哈希表查询数据
查询数据时,与添加的步骤一样:计算哈希码,根据哈希码计算存储位置,去存储位置查找链表
- 一次找到:比如上图中的86,计算存储位置为 9 ,去索引位置为 9 的地方,查找结点,只有一个,成功找到
- 多次找到:比如 47,存储位置为 3,去索引为 3 的地方找,第一个结点(36)不是,第二个才找到
- 找不到:比如58,计算存储位置为 3,去索引为 3 的地方找,找不到
结论:查询速度快
8.5 hashcode() 和 equals() 的作用
- hashcode(): 计算哈希码,返回一个整数,获得数据在哈希表中的存储位置
- equals():添加时发生了冲突,需要判断是否相同
8.6 各种类型的数据的哈希码如何计算
-
int:自身 -
double:先转成 long,然后无符号右移 32位,再与自身进行异或,最后结果取整 -
String:public int hashCode() { int h = hash; // hash 的值默认为 0 if (h == 0 && value.length > 0) { char val[] = value; for (int i = 0; i < value.length; i++) { h = 31 * h + val[i]; // 每个字符的ASCII编码进行计算 } hash = h; } // 如果该值已经算过了,直接返回(同一个 String 对象) return h; } -
自定义实体类:先计算实体类中属性的哈希码,然后加和,即为该对象的哈希码
8.7 如何减少冲突
-
哈希表的长度和表中的记录数的比例 – 装填因
以上是关于JavaLearn # (10)集合List栈队列Set外部比较器哈希表的主要内容,如果未能解决你的问题,请参考以下文章