LongAdder核心源码分析
Posted 可持续化发展
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了LongAdder核心源码分析相关的知识,希望对你有一定的参考价值。
以下内容为 本人观看小刘老师的源码培训班视频后整理的学习笔记。
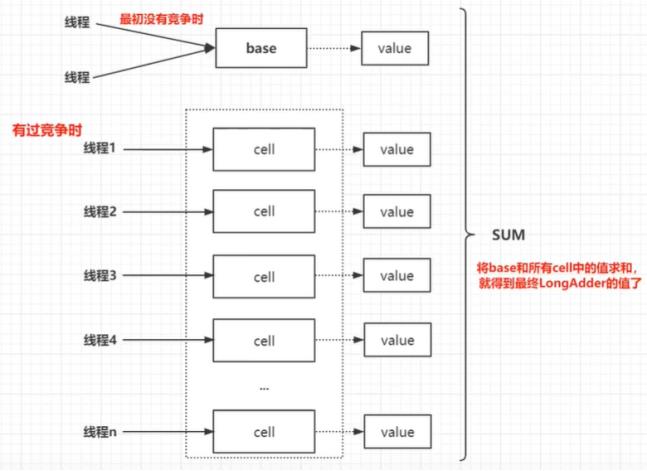
LongAdder是在高并发下实现高性能统计的一个类。以前使用AtomicLong来在高并发下统计一些数据。
但AtomicLong在高并发的情景下性能会越来越差。因为它是通过CAS的方式去操作的,而且只有一个变量去记录累计值。同一轮只有一个线程能竞争成功,抢到锁,把数据修改成功。有很多线程都会CAS失败,然后去自旋了。
所以就有了替代方案,LongAdder。
大概的逻辑
LongAdder的设计:
当写base没有竞争时,线程就将数据写在base里面。当线程在写base发生竞争了,用CAS的方式修改base失败的时候,竞争失败的线程,就会去把cells数组创建出来。在这个cells数组里面也是通过CAS的方式给long类型的value设置值。有了cells数组后,之后线程就会去cells数组里面写数据了。根据UNSAFE.getInt方法,获取当前线程的hash值。hash值 & 数组长度-1,当前线程就得到了cell元素的下标。就往这个cell元素里写数据。当线程在写cell元素的时候,发生竞争了。竞争失败的线程,会重试几次,去写这个cell。如果重试几次后,还是写不进这个cell,说明这个cell是一个热点。这个线程就会对这个cells数组进行扩容。当有其他线程在对cells数组进行扩容或初始化时,当前线程会把数据写到base中。LongAdder是化整为零,以空间换时间的思想。
源码逻辑
LongAdder的add(long x) 的流程是这样的:
先判断cells数组是否初始化了。如果未初始化,当前所有线程应该将数据写到base中。通过CAS的方式写base。如果当前线程cas替换数据成功,就完了。如果base写失败了且cells数组未初始化,就会调用Striped64的longAccumulate方法,去初始化cells数组。
如果cells数组初始化过了,当前线程应该将数据写入到对应的cell中。如果通过当前线程的hash值 & cells数组长度-1得到的下标对应的cell为null,则需要调用longAccumulate方法。如果命中的cell不空且通过CAS的方式修改cell成功了,就结束。如果失败了,需要去longAccumulate方法中扩容cells或者重试。
longAccumulate的逻辑是这样的:
调用longAccumulate方法的情况分三种:
- 第一种情况,cells 未初始化且多线程写base发生竞争了,就需要初始化cells。就会通过CAS的方式给cells数组加锁。假设加锁成功后,就会真正执行初始化逻辑。初始化完后,这个线程会释放锁。因为初始化的过程中加了锁。此时,其他线程就拿不到这把锁。在cells数组初始化的时候,其他线程就会把数据写到base中。
- 第二种情况,当前线程对应下标的cell数组元素为空,需要创建一个cell。先判断当前cellsBusy的锁状态。如果无锁,就new一个cell。再通过CAS的方式获取锁cellsBusy。假设拿锁成功,会再次验证命中的cell此时是否为null。为了防止有其他线程在当前线程停顿的时候,给命中的cell赋过值了,这个cell又不空了。如果它此时不空了,就自旋,然后通过CAS的方式尝试写入cell中。如果还是空的,就把新创建的cell对象放进去,然后break。
- 第三种情况,当前线程对应的cell 写入有竞争,需要重试或扩容。通过CAS的方式去写命中的cell。如果成功,则break。如果失败,就将扩容意向collide设为true。rehash一次当前线程的hash值。然后自旋。再次重试CAS写入命中的cell。如果成功,则break。如果失败,则先获取cellsBusy的锁。假设拿锁成功,就开始执行真正的扩容逻辑。扩容完后,就自旋,再重试写入。
- 当 当前线程写base没有竞争或者有其他线程在对cells数组进行初始化时,当前线程会通过CAS的方式把数据写到base中。
- cells数组扩容时不影响 写,也就是扩容期间,老的cells字段 值不变,然后新线程进来 还是 根据寻址算法找到 线程匹配的 cell ,将数据写入。 扩容那边会创建一个新的cells 数组,会把老的 cells 数组中的cell 全部拷贝过去的。
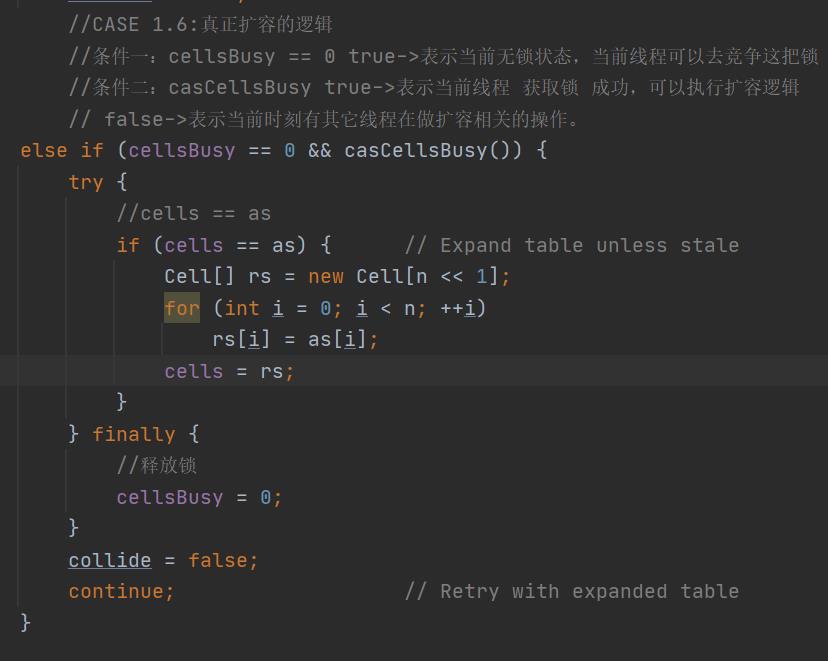
问题1:
会不会这样?线程1在扩容,线程2要去下标6写数据。然而线程1先把下标6的元素copy,而线程2又在老数组里面写了数据(即线程1copy的是旧值)。
答:
rs[i] = as[i];
它们是同一个引用地址。所以无论copy在写前还是在写后,都没影响,不会丢失数据。因为改的是同一个对象。
数据存到对象内了,对象在堆里。
- 当前的cells数组长度不能超过CPU的数量。因为一个CPU同一时间只能执行一个线程。假设有16个CPU,有一个32长度的cells数组,那么同一时刻这台电脑最多占用16个cell,并发到16。剩下的16个cell就浪费空间了。
LongAdder的sum方法的作用是把base和cells数组中的值累计求和,但结果不一定精确。拿到的是一个接近值,它的准确性体现为最终一致性。如果业务场景是高精度高准确性的话,还是得用AtomicLong。
以上是关于LongAdder核心源码分析的主要内容,如果未能解决你的问题,请参考以下文章