基于Flink的实时数据同步原理
Posted 咬定青松
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于Flink的实时数据同步原理相关的知识,希望对你有一定的参考价值。
数据同步用一个简单的模型可以描述为源端(Source)到目标端(Sink)的数据复制过程。源端通常是数据库比如mysql、目标端通常是分布式存储系统如HDFS等,在源端和目标端有时需要进行一些数据变换,如下图:
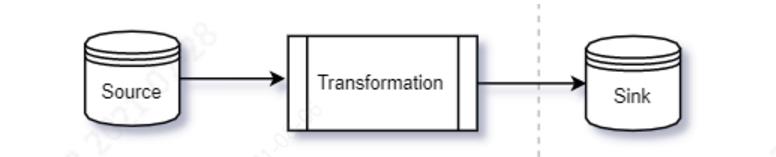
这个过程如果按照同步方式One by One地从源库read记录,然后write目标库,因为是单条记录,很容易控制写入的原子性事务:要么写成功,要么写失败,而且源端read的位置也不会丢失。这种同步方式的最大问题是效率低,因为源端和目标端系统的性能不一致,整体效率取决于较慢的一端,为了提高读写效率和吞吐量,需要将Source和Sink解耦,如基于内存Channel或者基于消息系统Kafka(Kafka本身也是Sink)的生产者和消费者模式,于是上述过程变成如下方式:
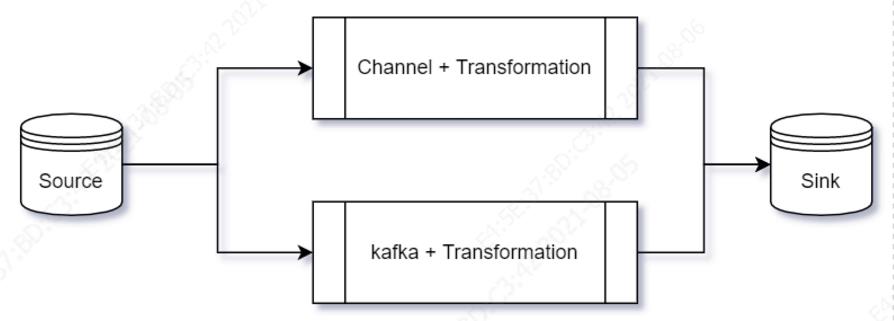
基于内存Channel的方式,当同步过程中出现读写异常或者宕机,会导致应用程序出错和产生源端和目标端不一致的脏数据,而且通常无法恢复,因为没有持久化同步过程中的状态信息,比如Datax、Sqoop等采用类似方式。还有一种基于内存Channel的实现框架是Debezium,其定位为支持多种数据库系统的实时数据捕获:
相比现有的Datax和Sqoop等,它有两大点显著性优势:实时和故障可恢复,基于Debezium的数据同步模型为:

先说实时:Source如何实时读取binlog?
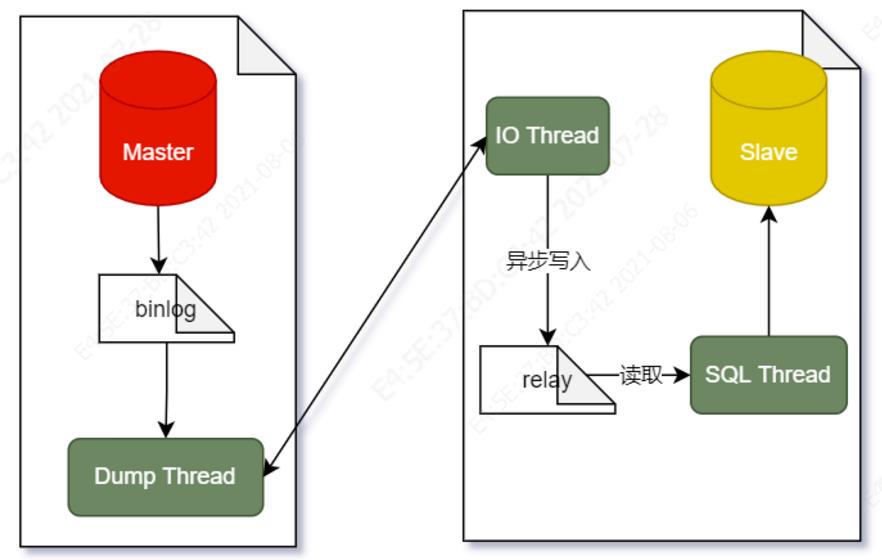
从上图可知,Mysql一次主从复制需要有三个线程来实现,其中一个线程(Binlog dump thread)在主服务器上,其它两个线程(Slave I/O thread , Slave SQL thread)在从服务器上。如果一台主服务器配两台从服务器,那主服务器上就会有两个Binlog dump 线程,而每个从服务器上各自有两个线程。
Binlog dump 线程是当有从服务器连接的时候由主服务器创建,用于向Slave发送binlog日志数据,Slave I/O 线程去连接主服务器的Binlog dump 线程并要求其发送binlog日志中记录的更新操作,然后它将Binlog dump 线程发送的数据拷贝到从服务器上的本地文件relay log中。Slave SQL线程是在从服务器上面创建的,主要负责读取由Slave I/O写的relay log文件并执行其中的事件。Slave跟Master创建连接并发送dump指令之后,两端的处理流程为:
Master端:
启动Dump Thread根据Slave发送过来需要dump的文件名和位置从读取binlog数据并发送给Slave的IO Thread。当没有更新日志,该线程将阻塞,直到有新日志事件到来将其唤醒。
Slave端:
IO Thread将接收到的日志Event写入本地relay文件,然后SQL Thread读取relay日志数据将数据反映到Slave数据库中。
从交互流程中可知,从库主动从主库请求 binlog 的副本,而不是主库主动将数据推送到从库。也就是说每个从库都是独立地与主库进行连接,每个从库只能通过向主库请求来接收 binlog 的副本,因此从库能够以自己的速度读取和更新数据库的副本,并且可以随意启动和停止该过程,而不会影响到主库或者其他从库的状态。以下代码(有删减)摘录自debezium项目中跟binlog交互过程:
//debezium#BinaryLogClient.java
public void connect() throws IOException, IllegalStateException {
try{
this.channel = this.openChannel();
GreetingPacket greetingPacket = this.receiveGreeting();
(new Authenticator(greetingPacket, this.channel, this.schema, this.username, this.password)).authenticate();
this.tryUpgradeToSSL(greetingPacket);
this.fetchBinlogFilenameAndPosition();
this.enableHeartbeat();
this.requestBinaryLogStream();
for (LifecycleListener lifecycleListener : lifecycleListeners) {
lifecycleListener.onConnect(this);
}
this.listenForEventPackets();
}finally{
for (LifecycleListener lifecycleListener : lifecycleListeners) {
lifecycleListener.onDisconnect(this);
}
}
}
private void listenForEventPackets() throws IOException {
ByteArrayInputStream inputStream = this.channel.getInputStream();
while(inputStream.peek() != -1) {
int packetLength = inputStream.readInteger(3);
inputStream.skip(1L);
int marker = inputStream.read();
if (marker == 254 && !this.blocking) {
completeShutdown = true;
break;
}
Event event;
try {
event = this.eventDeserializer.nextEvent(packetLength == 16777215 ? new ByteArrayInputStream(this.readPacketSplitInChunks(inputStream, packetLength - 1)) : inputStream);
this.notifyEventListeners(event);
this.updateClientBinlogFilenameAndPosition(event);
}finally {
this.disconnect();
}
}
}
}
再看看Debezium如何做故障恢复,而解释怎么做故障恢复,需要先了解其怎么表示进度信息。Source是Debezium的主要特征,基于Kafka Connector API对接上游源系统,比如Mysql、Sql Server、Postgrel和Mongodb,下游对接Kafka。其中Kafka是可选项,Debezium允许通过Embedding方式集成到应用程序,使用示例为:
// Define the configuration for the Debezium Engine with MySQL connector...
final Properties props = config.asProperties();
props.setProperty("name", "engine");
props.setProperty("offset.storage", "org.apache.kafka.connect.storage.FileOffsetBackingStore");
props.setProperty("offset.storage.file.filename", "/tmp/offsets.dat");
props.setProperty("offset.flush.interval.ms", "60000");
/* begin connector properties */
props.setProperty("database.hostname", "localhost");
props.setProperty("database.port", "3306");
props.setProperty("database.user", "mysqluser");
props.setProperty("database.password", "mysqlpw");
props.setProperty("database.server.name", "my-app-connector");
props.setProperty("database.history",
"io.debezium.relational.history.FileDatabaseHistory");
props.setProperty("database.history.file.filename",
"/path/to/storage/dbhistory.dat");
// Create the engine with this configuration ...
try (DebeziumEngine<ChangeEvent<String, String>> engine = DebeziumEngine.create(Json.class)
.using(props)
.notifying(record -> {
System.out.println(record);
}).build()) {
// Run the engine asynchronously ...
ExecutorService executor = Executors.newSingleThreadExecutor();
executor.execute(engine);
// Do something else or wait for a signal or an event
}
// Engine is stopped when the main code is finished
Debezium支持不同的Offset持久化方式:内存持久化和文件持久化。示例代码中配置的是基于文件的持久化:
props.setProperty("offset.storage", "org.apache.kafka.connect.storage.FileOffsetBackingStore");
props.setProperty("offset.storage.file.filename", "/tmp/offsets.dat");
其作用是将上游系统的binlog位置偏移信息保存下来,当程序异常恢复时,能基于原来的位置继续读取,避免出现数据丢失。何为偏移量?Debezium定义了一个DebeziumOffset这样的数据结构,官方解释为:
This class describes the most basic state that Debezium used for recovering based on Kafka Connect mechanism. It includes a sourcePartition and sourceOffset.
The sourcePartition represents a single input sourcePartition that the record came from (e.g. a filename, table name, or topic-partition). The sourceOffset represents a position in that sourcePartition which can be used to resume consumption of data.
主要包含两部分信息:sourcePartition和sourceOffset,两者都是Map结构,前者表示一个分区,主要是为了兼容Kafka的存储逻辑结构,在使用时候,常常对应一个固定值,比如对于Mysql数据库,partition为mysql_binlog_source,offset为binlog的文件名和pos位置以及其他可选信息,如下图:
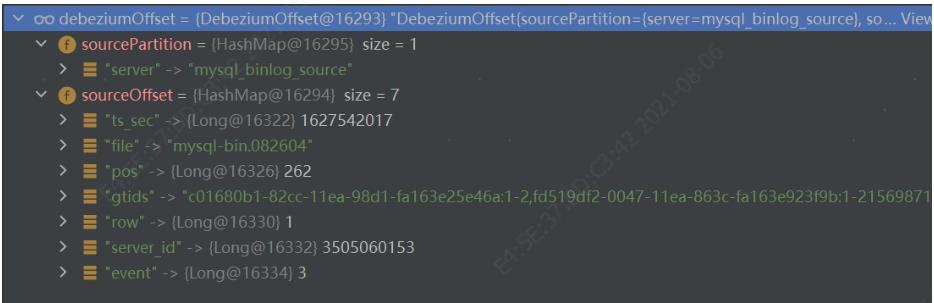
而MS Server的offset则为这样的:
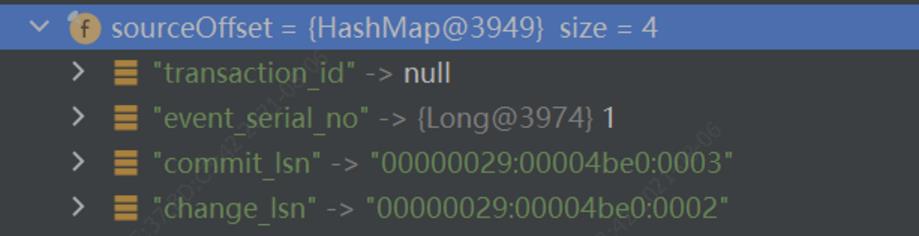
DebeziumOffset的持久化支持两者策略,AlwaysCommitOffsetPolicy和PeriodicCommitOffsetPolicy,前者每次同步binlog都进行持久化,此举是尽可能频繁地保存binlog的进度信息,后者为周期性地保存binlog进度信息,持久化频率越高,对系统性能损耗越大,因此需要结合实际情况,合理设置持久时间间隔,示例中默认1分钟一次:
props.setProperty("offset.flush.interval.ms", "60000");
接下来看看进度信息在什么情况下触发保存动作:在Debezium中,EmbeddedEngine是一个线程,其主要功能是在应用程序中,对接上游binlog数据源,在应用程序中通过自定义Consumer处理changed的,通过SourceRecord包装后的数据记录。应用程序负责所有有关容错、扩容以及如何存储上游数据消费位置和历史数据等相关问题。
#EmbeddedEngine.java
@Override
public void run() {
// Initialize the offset store ...
offsetStore.configure(workerConfig);
offsetStore.start();
RecordCommitter committer = buildRecordCommitter(offsetWriter, task, commitTimeout);
try{
while (runningThread.get() != null) {
List<SourceRecord> changeRecords = null;
changeRecords = task.poll();
changeRecords = changeRecords.stream()
.map(transformations::transform)
.filter(x -> x != null)
.collect(Collectors.toList());
handler.handleBatch(changeRecords, committer);
}
}finally {
commitOffsets(offsetWriter, commitTimeout, task);
}
}
其中handler是Debezium的默认实现:
private static ChangeConsumer buildDefaultChangeConsumer(Consumer<SourceRecord> consumer) {
return new ChangeConsumer() {
/**
* the default implementation that is compatible with the old Consumer api.
*
* On every record, it calls the consumer, and then only marks the record
* as processed when accept returns, additionally, it handles StopConnectorExceptions
* and ensures that we all ways try and mark a batch as finished, even with exceptions
* @param records the records to be processed
* @param committer the committer that indicates to the system that we are finished
*
* @throws Exception
*/
@Override
public void handleBatch(List<SourceRecord> records, DebeziumEngine.RecordCommitter<SourceRecord> committer) throws InterruptedException {
for (SourceRecord record : records) {
try {
consumer.accept(record);
committer.markProcessed(record);
}
catch (StopConnectorException | StopEngineException ex) {
// ensure that we mark the record as finished
// in this case
committer.markProcessed(record);
throw ex;
}
}
committer.markBatchFinished();
}
};
}@Override
public synchronized void markBatchFinished() throws InterruptedException {
maybeFlush(offsetWriter, offsetCommitPolicy, commitTimeout, task);
}
protected void maybeFlush(OffsetStorageWriter offsetWriter, OffsetCommitPolicy policy, Duration commitTimeout,
SourceTask task)
throws InterruptedException {
// Determine if we need to commit to offset storage ...
long timeSinceLastCommitMillis = clock.currentTimeInMillis() - timeOfLastCommitMillis;
if (policy.performCommit(recordsSinceLastCommit, Duration.ofMillis(timeSinceLastCommitMillis))) {
commitOffsets(offsetWriter, commitTimeout, task);
}
}
在maybeFlush方法中依据配置的持久化策略和持久化介质进行持久化。有了持久化,下一个问题是如何恢复持久化的位置信息?
在EmbeddedEngine的run方法中
// Initialize the offset store ...
offsetStore.configure(workerConfig);
offsetStore.start();
在引擎启动过程中初始化offsetStore并恢复数据,OffsetBackingStore是一个支持后端数据存储的接口,有3个实现实例:

比如基于文件的存储方式,在start中加载文件,恢复位置数据:
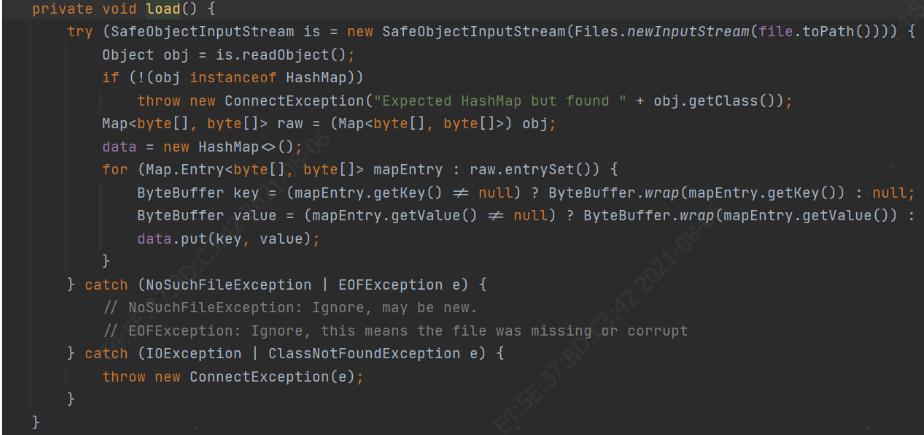
Debezium虽然能够根据消费位置从异常中恢复,但是存在数据重复处理的问题,特别是当有下游写入的时候,重复的数据又会写入下游系统。所以在应用程序中使用Debezium存在的两大问题是上游数据重复处理、下游数据重复写入。特别是如果处理支持并发,重复问题会更严重。
基于kafka方式,无论是从Source写入Kafka端还是从Sink端读取Kafka,都可以利用Kafka的Ack机制保证数据的服务质量(QoS)。为了达到读写效率最大化,生产端和消费端都支持批量Ack,但是Kafka生产端和消费端的Ack机制有所不同:消费端只有消费成功才可以Ack,而生产端提供3种Ack方式:
0 - 不保证数据成功投递,最多发送一次;
1 - 只要Kafka leader副本写入成功,即Ack;
-1 - 当Kafka全部副本写入成功才Ack
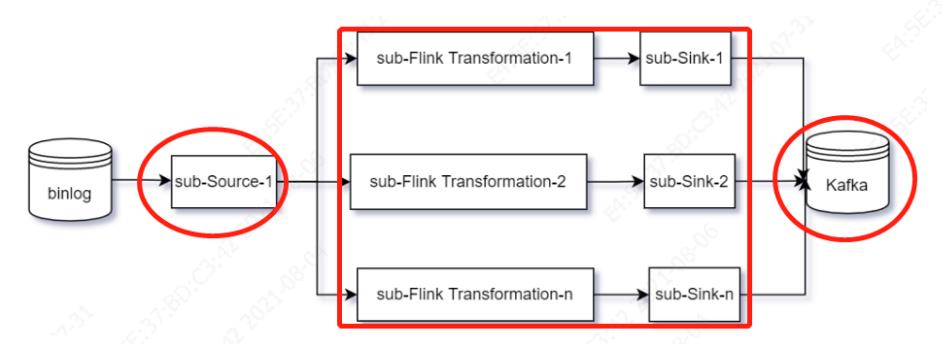
应用Kafka作为中间缓存,增大了数据存储开销和系统运维成本。另外,采用Kafka作为缓冲隐藏了很多问题,比如Source通过什么服务等级写入Kafka,Source如何维护数据位置等状态信息,采用Kafka作为缓存的框架有Canal等。同时下游消费Kafka同样需要维护Offset,Kafka的生产者又需要维护binlog的offset,维护两道offset门槛维护加强了系统脆弱性和故障率,基于Flink和Debezium的方案能够优化掉Kafka,如果此时仅仅作为一种Sink选项,将Kafka作为我们的Sink(当然还可以用其他的Sink,比如Mysql),此时的模型图如下:

相比基于Kafka作为缓存,同时又作为Sink,减少了一道维护Offset的门槛,如果换做其他类型的Sink,此时完全可以摆脱对Kafka的依赖。而且此时的模型中,数据库的binlog作为Source,Kafka作为Sink,Source、Transformation和Sink都可以被集成到一个框架内如Flink Connector,下面着重来看该方案如何解决一些关键问题的。
Flink如何提高数据同步并发性能?
单纯使用Debezium不容易实现扩容方案,而借助Flink可以让Debezium如虎添翼。在介绍如何实现扩容前,先了解下Flink的Job调度模型。
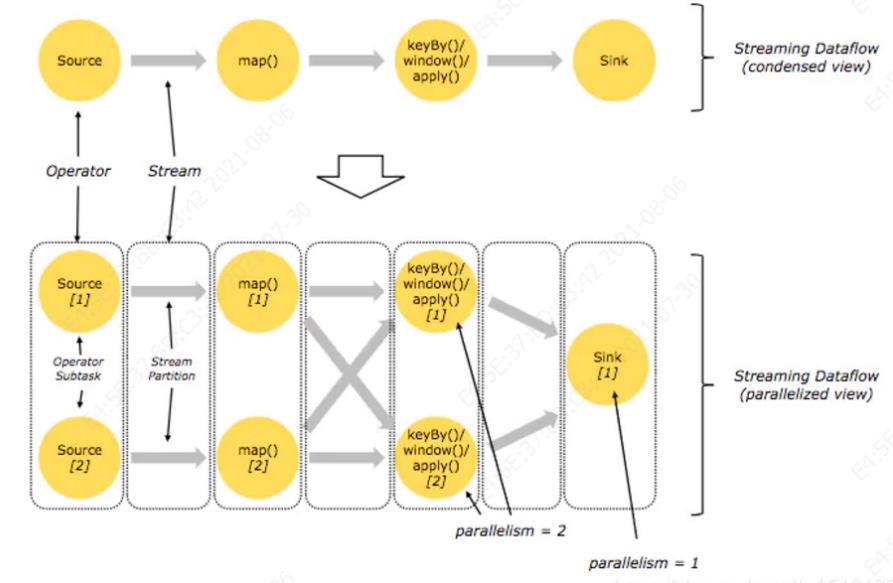
在Flink中,Job的拓扑结构有两种视图:Job逻辑视图和Job执行视图。如下图所示,一个作业逻辑:soure=>map=>keyBy|window|apply=>sink,其中keyBy|window|apply组成一个管道,在一个任务中运行。
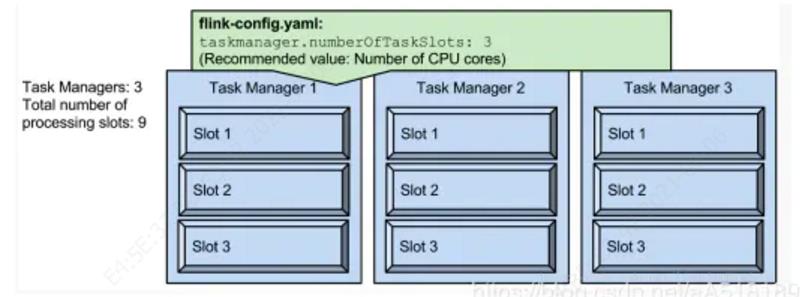
要提高Flink应用程序的并行度,可以借助slot和parallelism这两个概念来实现。其中slot是资源组的抽象,是资源分配的单位,(pipelined)任务就运行在slot里面,slot代表了taskmanager的并发执行能力,比如下图中配置了每个TaskManager的slot为3,那么3个taskmanager一共有9个TaskSlot,意味着该Flink集群最大并行任务数量为9:
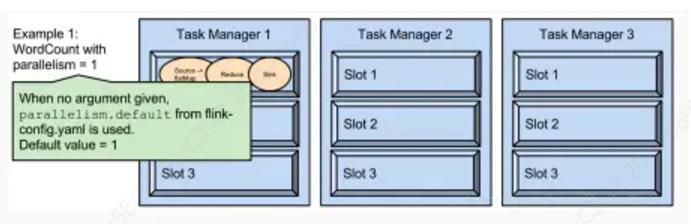
任务的并行度可以通过parallelism来设置,最大不能超过slot数量。运行程序默认的并行度为1,比如下面图中,9个TaskSlot只用了1个,有8个空闲,因此只有设置合适的并行度才能提高集群的利用率。
parallelism是可配置、可指定的,下面列举了常用方法:
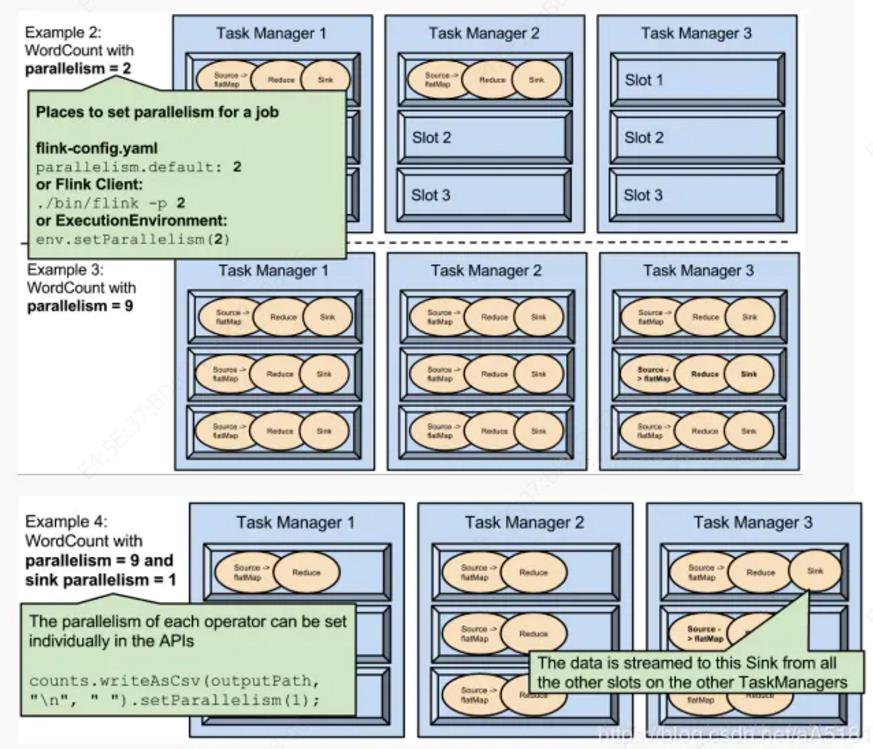
1.可以通过修改$FLINK_HOME/conf/flink-conf.yaml文件的方式更改并行度
2.可以通过设置$FLINK_HOME/bin/flink 的-p参数修改并行度
3.可以通过设置executionEnvironmentk的方法修改并行度
4.可以通过设置flink的编程API修改过并行度
5.这些并行度设置优先级从低到高排序,排序为api>env>p>file.
6.设置合适的并行度,能提高运算效率
7.parallelism不能多于slot个数。
回到我们实时数据同步的场景中,原来单纯基于Debezium的模型,在并行模式下,模型变成下面的样子:
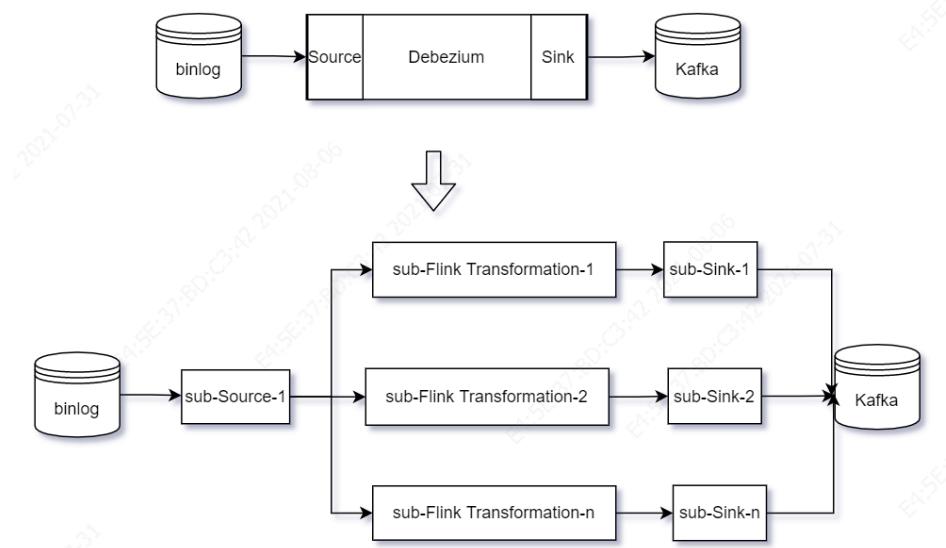
图中source的默认并行度为1,因为对数据库binlog并行支持,不同的数据库版本支持的并行策略不一样,来看看Mysql系列不同数据库版本的并行复制技术:
Mysql 5.6 按库并行复制,不同的库binlog互不影响,可以并行读取;
MariaDB 支持组提交的并行优化技术,因为一组提交的事务有一个相同的 commit_id 直接写到 binlog 里,能够在同一组里提交的事务一定不会修改同一行;
MySQL 5.7 根据同时进入 prepare 和 commit 来判断是否可以并行的策略,其依据的原则为:
同时处于prepare状态的事务,在备库执行时是可以并行的;
处于prepare状态的事务与处于commit状态之间的事务,在备库执行时也是可以并行的。
binlog_group_commit_sync_delay 和 bin_log_group_commit_sync_no_delay_count 这两个参数可以用来拉长 binlog write 和 fsync 之间的时间,以此减少binlog的写盘次数,制造更多同时处于 prepare 阶段的事务,从而增加备库复制的并行度。前者表示延迟多少微秒后才调用fsync,后者表示累积多少次以后才调用fsync。
MySQL 5.7.22 基于WRITESET的并行复制,增加了一个参数binlog-transaction-dependency-tracking,用来控制是否启用这个策略。这个参数的可选值有以下3种:
COMMIT_ORDER,表示的就是前面介绍的,根据同时进入prepare和commit来判断是否可以并行的策略。
WRITESET,表示的是对于事务涉及更新的每一行,计算出这一行的hash值,组成集合writeset。如果两个事务没有操作相同的行,也就是说它们的writeset没有交集,就可以并行。
WRITESET_SESSION,是在WRITESET的基础上多了一个约束,即在主库上同一个线程先后执行的两个事务,在备库执行的时候,要保证相同的先后顺序。
Flink如何保证数据一致性?
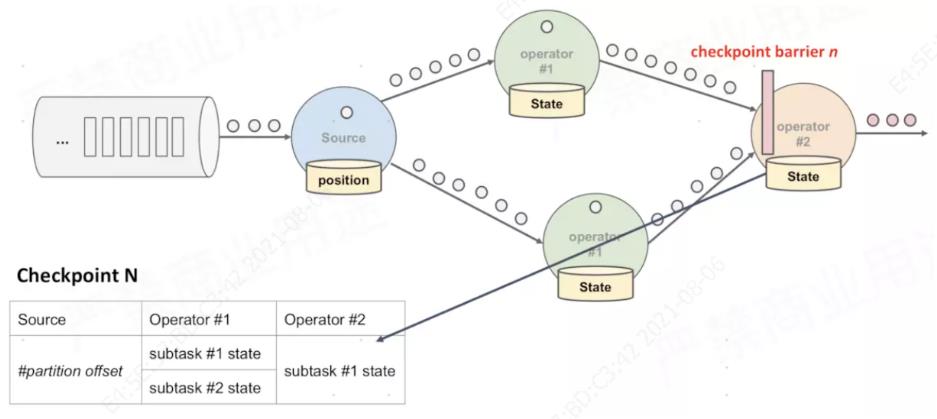
在上图中,有3个地方会存在异常导致的数据丢失和重复问题:Source端读取binlog时发生异常、Flink中间处理过程中发生异常\\Sink端写入持久化时发生异常,为了解决上述问题,Flink引入了Checkpoint机制,所谓Checkpoint就是定时打快照,通过JobManager的CheckPointCoordinator向所有SourceTask 注入barrier,然后SourceTask再向下游广播barrier,一直到SinkTask接收到barrier,这个过程当中任意一个Task收到barrier并完成本地快照后向CheckPointCoordinator注册备份数据的地址(state handle),当CheckPointCoordinator收到所有Task的数据备份地址,一次分布式快照才算完成。Flink采用的是轻量级分布式快照算法,步骤为:
Checkpoint Coordinator 向所有 source 节点 trigger Checkpoint,在数据流中安插CheckPoint barrier。
source 节点收到barrier后向下游广播 barrier,并将自己的状态(异步)写入到持久化存储中。当 task 完成 state 备份后,会将备份数据的地址(state handle)通知给 Checkpoint coordinator。
当下游Task收到所有的barrier后,继续向自己的下游传递barrier,然后自身执行快照,并将自己的状态异步写入到持久化存储中。如果下游任务为Sink节点,barrier传递终止。
当 Checkpoint coordinator 收集齐所有 task 的 state handle,这一次的 Checkpoint 全局完成了,并向持久化存储中备份Checkpoint meta 文件,每次checkpoint生成不同的元数据文件目录。
下图展示一次checkpoint过程完成后保存的算子状态:
如果CheckPoint的持续时长超过 了CheckPoint设定的超时时间,CheckPointCoordinator 还没有收集完所有的 State Handle,CheckPointCoordinator就会认为本次CheckPoint失败。下面的代码展示了有关Checpoint的配置属性:
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
CheckpointConfig checkpointConfig = env.getCheckpointConfig();
//Sets the checkpointing mode (exactly-once vs. at-least-once).
checkpointConfig.setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
//Sets the interval in which checkpoints are periodically scheduled.
checkpointConfig.setCheckpointInterval(flinkConfig.interval);
// 两个checkpoints之间最少间隔
checkpointConfig.setMinPauseBetweenCheckpoints(flinkConfig.pauseInterval);
checkpointConfig.setTolerableCheckpointFailureNumber(10);
checkpointConfig.setCheckpointTimeout(flinkConfig.checkPointTimeout);
// env.setStateBackend(new FsStateBackend(flinkConfig.checkPointDir));
checkpointConfig.setCheckpointStorage(flinkConfig.checkPointDir);
// 取消作业时是否保留 checkpoint (默认不保留)
checkpointConfig.enableExternalizedCheckpoints(
CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);Flink框架本身支持Operator级别的State快照,所谓State就是Flink处理过程中的状态数据,有keyed state和operator state两种,前者应用于 KeyedStream的函数与操作中,后者与一个 operator 的实例绑定。 这些状态信息通过定时生成的Checkpoint保存到内存或者持久化系统中,当任务失败重试时从持久化系统中恢复数据。Flink的State后端存储持久化方式有3种:MemoryStateBackend 、FsStateBackend和RocksDBStateBackend,其中 MemoryStateBackend 和 FsStateBackend 在运行时都是存储在 java heap 中的,只有在执行 Checkpoint 时,FsStateBackend 才会将数据以文件格式持久化到远程存储上,而 RocksDBStateBackend 借用了 RocksDB(内存磁盘混合的 LSM DB)对 state 进行存储。Flink框架对CheckpointableKeyedStateBackend和OperatorStateBackend分别实现了快照功能,在AbstractStreamOperator 的snapshot方法中有代码为证:
streamOperator.snapshotState(snapshotContext);
snapshotInProgress.setKeyedStateRawFuture(snapshotContext.getKeyedStateStreamFuture());
snapshotInProgress.setOperatorStateRawFuture(
snapshotContext.getOperatorStateStreamFuture());
if (null != operatorStateBackend) {
snapshotInProgress.setOperatorStateManagedFuture(
operatorStateBackend.snapshot(
checkpointId, timestamp, factory, checkpointOptions));
}
if (null != keyedStateBackend) {
if (checkpointOptions.getCheckpointType().isSavepoint()) {
SnapshotStrategyRunner<KeyedStateHandle, ? extends FullSnapshotResources<?>>
snapshotRunner = prepareSavepoint(keyedStateBackend, closeableRegistry);
snapshotInProgress.setKeyedStateManagedFuture(
snapshotRunner.snapshot(
checkpointId, timestamp, factory, checkpointOptions));
} else {
snapshotInProgress.setKeyedStateManagedFuture(
keyedStateBackend.snapshot(
checkpointId, timestamp, factory, checkpointOptions));
}
}
除了Flink本身对上述两种State类型的快照存储,也支持自定义的快照执行逻辑,特别值得一提的是Flink对除了Source和Sink外的中间算子能够做到Exactly Once,Source和Sink需要外部系统本身的支持,自定义快照执行需要算子实现CheckpointedFunction和CheckpointListener接口,比如Debezium用来实现binlog读取的DebeziumSourceFunction,其部分实现代码为:
public class DebeziumSourceFunction<T> extends RichSourceFunction<T>
implements CheckpointedFunction, CheckpointListener, ResultTypeQueryable<T> {
/**
* This method is called when the parallel function instance is created during distributed
* execution. Functions typically set up their state storing data structures in this method.
***/
@Override
public void initializeState(FunctionInitializationContext context) throws Exception {
OperatorStateStore stateStore = context.getOperatorStateStore();
this.offsetState =
stateStore.getUnionListState(
new ListStateDescriptor<>(
OFFSETS_STATE_NAME,
PrimitiveArrayTypeInfo.BYTE_PRIMITIVE_ARRAY_TYPE_INFO));
for (byte[] serializedOffset : offsetState.get()) {
if (restoredOffsetState == null) {
restoredOffsetState = new String(serializedOffset, StandardCharsets.UTF_8);
}
}
/**
* This method is called when a snapshot for a checkpoint is requested. This acts as a hook to
* the function to ensure that all state is exposed by means previously offered through {@link
* FunctionInitializationContext} when the Function was initialized, or offered now by {@link
* FunctionSnapshotContext} itself.**
*/
@Override
public void snapshotState(FunctionSnapshotContext functionSnapshotContext) throws Exception {
offsetState.clear();
final DebeziumChangeFetcher<?> fetcher = this.debeziumChangeFetcher;
byte[] currentState = fetcher.snapshotCurrentState();
offsetState.add(currentState);
pendingOffsetsToCommit.put(checkpointId, serializedOffset);
while (pendingOffsetsToCommit.size() > MAX_NUM_PENDING_CHECKPOINTS) {
pendingOffsetsToCommit.remove(0);
}
}
/**
* Notifies the listener that the checkpoint with the given {@code checkpointId} completed and
* was committed.
*/
@Override
public void notifyCheckpointComplete(long checkpointId) {
final DebeziumChangeFetcher<T> fetcher = this.debeziumChangeFetcher;
final int posInMap = pendingOffsetsToCommit.indexOf(checkpointId);
byte[] serializedOffsets = (byte[]) pendingOffsetsToCommit.remove(posInMap);
// remove older checkpoints in map
for (int i = 0; i < posInMap; i++) {
pendingOffsetsToCommit.remove(0);
}
DebeziumOffset offset =
DebeziumOffsetSerializer.INSTANCE.deserialize(serializedOffsets);
changeConsumer.commitOffset(offset);
}
}
下面看看针对这3种情况,Flink如何解决的?
1. Source端读取binlog时发生异常
如果Debezium在初始化快照时无法进行Checkpoint,假如此时发生异常,待任务恢复时候会重新全表扫描数据,存在数据重复问题。如果Debezium在增量读取binlog时发生异常,由于Debezium 通过自定义持久化策略保存offset信息,如果发生异常,可以恢复到上一次快照持久化时的读取位置,此时不会存在丢失,只是从上一次offset处重新读取一遍数据。
2. Flink中间处理过程中发生异常
在Flink中间处理过程中发生异常恢复时,keyed state和operator state 从持久化系统中加载数据,恢复中间过程数据。对于继承AbstractUdfStreamOperator的函数算子也可以基于UDF自定义快照恢复。
3. Sink端写入持久化时发生异常
Sink端写入持久化时发生异常,在恢复时由于上游Source恢复时存在重复,写入到Sink也可能会导致重复,这取决于Sink端系统是否支持幂等或者事务。如果Sink支持事务,在写入过程发生异常,此时事务不会提交,如果Sink不支持事务,当任务恢复时,会导致数据重复。Kafka通过两阶段提交来保证事务性写入,下面详细介绍。
Flink-Kafka如何通过两阶段提交保证事务?
对于事务性写入,具体又有两种实现方式:预写日志(WAL)和两阶段提交(2PC)。DataStream API 提供了 GenericWriteAheadSink 模板类和TwoPhaseCommitSinkFunction 接口,可以方便地实现这两种方式的事务性写入。
预写日志(Write-Ahead-Log,WAL)
把结果数据先当成状态保存,然后在收到 checkpoint 完成的通知的时候,一次性写入 sink 系统
简单易于实现,由于数据提前在状态后端中做了缓存,所以无论什么 sink 系统,都能用这种方式一批搞定
DataStream API 提供了一个模板类:GenericWriteAheadSink,来实现这种事务性 sink
两阶段提交(Two-Phase-Commit,2PC)
对于每个 checkpoint,sink 任务会启动一个事务,并将接下来所有接收的数据添加到事务里
然后将这些数据写入外部的 sink 系统,但不提交它们 ----- 这时只是“预提交”
当它收到 checkpoint 完成的通知时,它才正式提交事务,实现结果的真正写入
这种方式真正实现了 exactly-once ,它需要一个提供事务支持的外部 sink 系统。Flink 提供了 TwoPhaseCommitSinkFunction 接口。
TwoPhaseCommitSinkFunction 也实现了CheckpointedFunction和CheckpointListener接口,除了具有这两个接口中的方法外,额外增加了以下几个方法:
public abstract class TwoPhaseCommitSinkFunction<IN, TXN, CONTEXT> extends RichSinkFunction<IN>
implements CheckpointedFunction, CheckpointListener {
/**
* Method that starts a new transaction.
*
* @returnnewly created transaction.
*/
protected abstract TXN beginTransaction() throws Exception;
/**
* Pre commit previously created transaction. Pre commit must make all of the necessary steps to
* prepare the transaction for a commit that might happen in the future. After this point the
* transaction might still be aborted, but underlying implementation must ensure that commit
* calls on already pre committed transactions will always succeed.
*
* <p>Usually implementation involves flushing the data.
*/
protected abstract void preCommit(TXN transaction) throws Exception;
/**
* Commit a pre-committed transaction. If this method fail, Flink application will be restarted
* and {@linkTwoPhaseCommitSinkFunction#recoverAndCommit(Object)} will be called again for the
* same transaction.
*/
protected abstract void commit(TXN transaction);
/** Abort a transaction. */
protected abstract void abort(TXN transaction);
}
然后看看这几个方法的调用逻辑:
public class FlinkKafkaProducer<IN>
extends TwoPhaseCommitSinkFunction<
IN,
FlinkKafkaProducer.KafkaTransactionState,
FlinkKafkaProducer.KafkaTransactionContext> {
@Override
public void snapshotState(FunctionSnapshotContext context) throws Exception {
long checkpointId = context.getCheckpointId();
preCommit(currentTransactionHolder.handle);
pendingCommitTransactions.put(checkpointId, currentTransactionHolder);
state.clear();
state.add(
new State<>(
this.currentTransactionHolder,
new ArrayList<>(pendingCommitTransactions.values()),
userContext));
}
@Override
public final void notifyCheckpointComplete(long checkpointId) throws Exception {
while (pendingTransactionIterator.hasNext()) {
Map.Entry<Long, TransactionHolder<TXN>> entry = pendingTransactionIterator.next();
Long pendingTransactionCheckpointId = entry.getKey();
TransactionHolder<TXN> pendingTransaction = entry.getValue();
if (pendingTransactionCheckpointId > checkpointId) {
continue;
}
commit(pendingTransaction.handle);
pendingTransactionIterator.remove();
}
}
@Override
public void initializeState(FunctionInitializationContext context) throws Exception {
state = context.getOperatorStateStore().getListState(stateDescriptor);
boolean recoveredUserContext = false;
if (context.isRestored()) {
//执行恢复提交或Abort等操作
}
currentTransactionHolder = beginTransactionInternal();
}
}
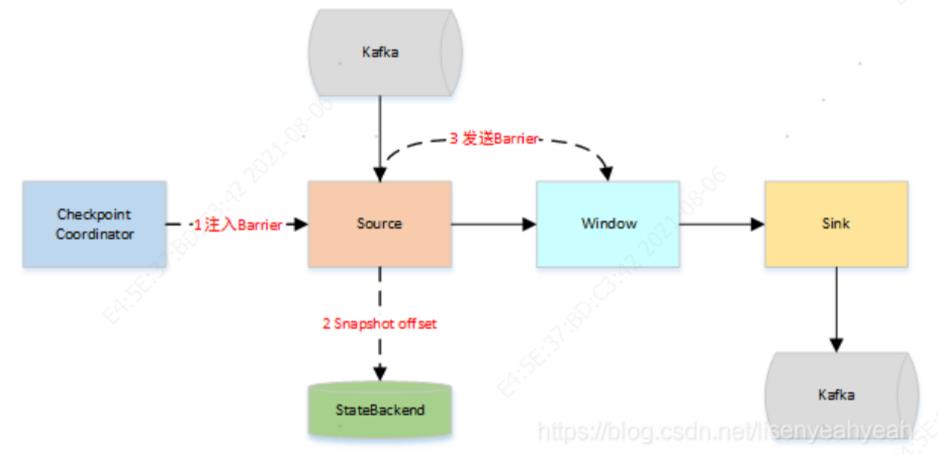
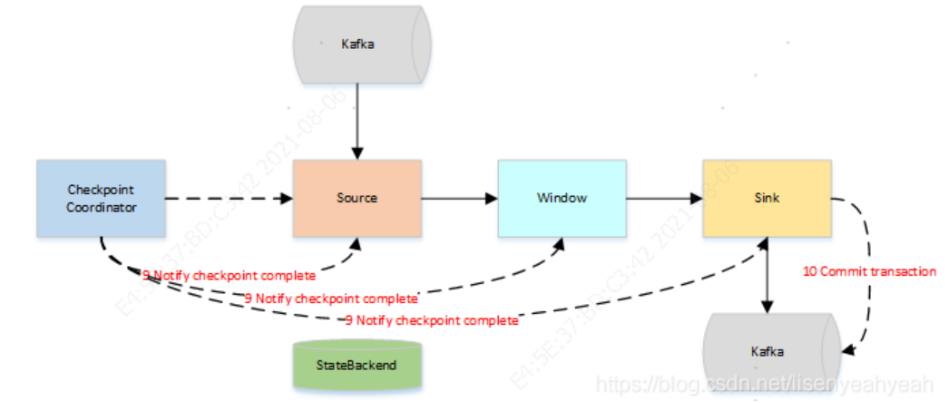
下面以从Kafka Source拉取数据,经过一次窗口聚合,最后将数据发送到Kafka Sink这样一个场景,来描述两阶段事务提交的工作流程:
JobManager向Source发送Barrier,开始进入pre-Commit阶段,当只有内部状态时,pre-commit阶段无需执行额外的操作,仅仅是写入一些已定义的状态变量即可。当chckpoint成功时Flink负责提交这些写入,否则就终止取消掉它们。
当Source收到Barrier后,将自身的状态进行保存,后端可以根据配置进行选择,这里的状态是指消费的每个分区对应的offset。然后将Barrier发送给下一个Operator。
当Window这个Operator收到Barrier之后,对自己的状态进行保存,这里的状态是指聚合的结果(sum或count的结果),然后将Barrier发送给Sink。Sink收到后也对自己的状态进行保存,之后会进行一次预提交。
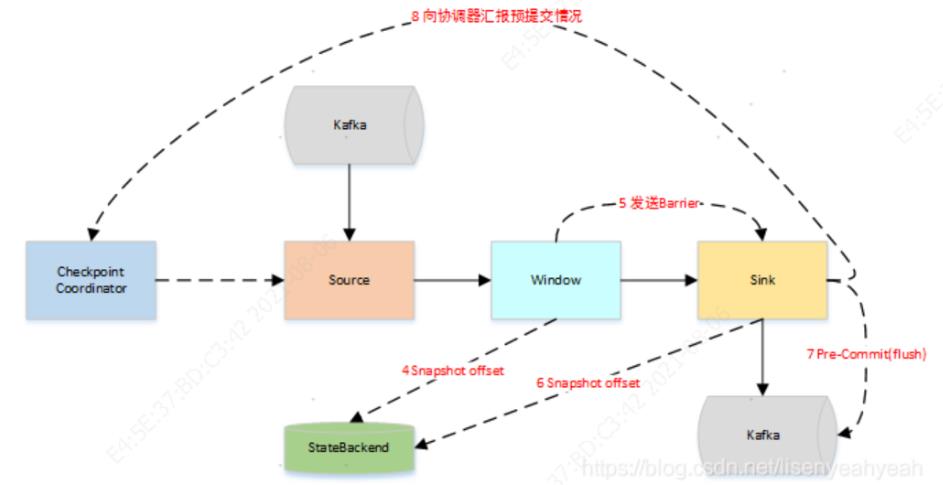
预提交成功后,JobManager通知每个Operator,这一轮检查点已经完成,这个时候,Kafka Sink会向Kafka进行真正的事务Commit。
两阶段提交的缺点:
1.同步阻塞问题。执行过程中,所有参与节点都是事务阻塞型的。
当参与者占有公共资源时,其他第三方节点访问公共资源不得不处于阻塞状态。
2.单点故障。由于协调者的重要性,一旦协调者发生故障。
参与者会一直阻塞下去。尤其在第二阶段,协调者发生故障,那么所有的参与者还都处于锁定事务资源的状态中,而无法继续完成事务操作。(如果是协调者挂掉,可以重新选举一个协调者,但是无法解决因为协调者宕机导致的参与者处于阻塞状态的问题)
3.数据不一致。在二阶段提交的阶段二中,当协调者向参与者发送commit请求之后,发生了局部网络异常或者在发送commit请求过程中协调者发生了故障,这回导致只有一部分参与者接受到了commit请求。
而在这部分参与者接到commit请求之后就会执行commit操作。但是其他部分未接到commit请求的机器则无法执行事务提交。于是整个分布式系统便出现了数据不一致性的现象。
可见,Flink作为实时数据处理的利器,一方面在伸缩性、容错性和一致性方面解放了开发人员,另一方面也承担了Sink下游存储系统应该承担的部分职责(一致性保障),将这些重任自己抗下,背负了过多的负担,然而并没有完全解决问题,还引入了复杂性和更多的性能问题。部分一致性问题仍然需要开发人员和上下游端系统来保证。从解决问题的途径来看,相对端系统来说,Flink只是在应用端打补丁,并没有触及到端系统,因此长远来看,问题的最终解决可能还需要上下游端系统来保障。
以上是关于基于Flink的实时数据同步原理的主要内容,如果未能解决你的问题,请参考以下文章