浅析 hive udaf 的正确编写方式- 论姿势的重要性
Posted michaelli916
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了浅析 hive udaf 的正确编写方式- 论姿势的重要性相关的知识,希望对你有一定的参考价值。
大家好!我是明哥。
又到了周末,很高兴有时间可以坐下来更新下公众号,希望小伙伴们能度过一个愉快又有所收获的愉快的周末时光。
题外话
先说几句题外话,所谓酒香也怕巷子深,运营是门大学问,关注明哥的小伙伴们应该知道,明哥最近在跟一些运营小伙伴学习如何涨粉以进一步推广自己的公众号,所以会转发一些不错的其它公众号的文章,也会不定时推荐一些不错的公众号,大家可以关注下。
也欢迎大家转发明哥的原创文章到自己的公众号,朋友圈或其他分享渠道,交更多的朋友,走更宽的路,哈哈,谢谢大家。
以下是正文。
从一个问题现象说起
某 hive UDAF 执行时在聚合阶段需要读取 hdfs 上的一个配置文件,所以该 hive udaf 被设计为在调用时通过入参形式传入该配置文件在 hdfs上的路径,该UDAF示例调用语句如下:
select my_udaf_sample(colA,colB,colC,'/user/userA/conf/') as my_udaf_result from tableA a group by a.cust_id;
但是在某些客户现场该 UDAF 执行时会报类似以下错误:
org.apache.hadoop.hive.ql.metadata.HiveException: 读取文件[configure-fileA.xml]异常:java.io.FileNotFoundException: File does not exist: /user/hive/configure-fileA.xml;
即 UDAF 执行时,实际读取的配置文件的路径不是调用时入参中指定的路径,此时因为目标路径下找不到配置文件,作业执行失败报上述错误;
UDAF 相关代码细节
该 UDAF 类中通过静态变量的形式定义了配置文件的路径,且在定义该静态变量时初始化为空,然后在 iterate() 方法中根据 UDAF 调用语句中的入参为该静态变量重新赋值,最后在terminate() 方法中调用 HdfsUtil.getConfFileStream(FILE_NAME, udfFilePath) 来读取配置文件具体内容,相关代码如下:
1. private static String udfFilePath = ""; //定义静态变量并赋初始值
2. public void iterate(AggregationBuffer aggregationBuffer, Object[] objects) :// iterate 方法中对静态变量重新赋值
if (StringUtils.isBlank(udfFilePath)) {
udfFilePath = (String) stringOI.getPrimitiveJavaObject(objects[13]);
}
3. public Object terminate(AggregationBuffer aggregationBuffer):// terminate 方法中使用该静态变量
InputStream ips = HdfsUtil.getConfFileStream(FILE_NAME, udfFilePath);
4. HdfsUtil.getConfFileStream(): //HdfsUtil读取配置文件内容
FileSystem fs = FileSystem.get(URI.create(udfFilePath + fileName),conf);
FSDataInputStream inputStream = fs.open(new Path(udfFilePath + fileName));
大家可以先自己思考下,以上代码实现,为什么有时会报上述错误。
问题发生的根本原因
上述代码有时会出现上述问题的根本原因就在于,hive UDAF 执行时是以多进程的形式在多个 yarn container 中即多个 JVM 中执行的,所以在 map 阶段通过执行 iterate() 方法改变的静态变量 udfFilePath 的值,在 reduce 阶段的 terminate() 方法中是访问不到 iterate() 方法更改后的 udfFilePath 的值的,因为 map 阶段和 reduce 阶段是在不同的 JVM 中执行的!所以此时 terminate() 方法实际访问的文件的路径为空(因为我们定义该静态变量时,初始值赋的是空),此时 HDFS 默认是在作业提交者的 home directory 下寻找同名文件!所以当作业提交者的 home directory 下不存在该文件时就会报上述错误。
由于我们在不同客户现场部署我们的应用时,各个客户的大数据环境不同,相应的作业真实提交用户的身份也不同,而上述配置文件只上传到了某个特定用户的 home directory下,比如 /user/userA, 此时当作业真实提交用户身份时userB时,就会尝试在 /user/userB 目录下寻找同名配置文件,如果找不到就会报上述错误。
ps. 在使用 kerberos 做 Hive 认证时,kinit 的用户就是 hive 作业的提交用户;在使用 ldap 或 None 做 hive 认证时, beeline 中 –n 指定的用户就是 hive 作业提交用户;
问题解决方法
知道了问题发生的根本原因,解决方法也就顺藤摸瓜出来了。笼统来看有两个解决办法:
一是在客户现场部署我们的应用时,根据客户大数据环境中我们作业的真实提交用户的身份,在其 hdfs 的 home_directory 下存储一份配置文件,比如:/user/userA/configure-fileA.xml, /user/userB/configure-fileA.xml 等等;
二是将该配置文件作为一个本地文件跟 UDAF 的 jar 包打到一起,UDAF 执行时直接访问JAR包中的本地的配置文件。(在该配置文件不需要更改或很少更改时,推荐使用该方案。)
最后有必要说明下,一个配置文件的路径,其实是不适合作为 UDAF 的入参传入的,因为一般来讲 UDAF 的入参是迭代读取的表中的每一行记录的不同字段的值,而配置文件的路径是固定的,对迭代读取的表中的每一行记录都传入该固定的配置文件的路径,在性能上不是一个高效的实现。
背景知识回顾与总结
Hive 有两种类型的 UDAF: simple 和 generic,由于前者性能不如后者(内部使用了 java 的反射机制),且不支持变长变量都特性,hive 社区推荐使用后者,具体来讲就是推荐使用 org.apache.hadoop.hive.ql.udf.generic.GenericUDAFEvaluator 而不是 org.apache.hadoop.hive.ql.exec.UDAFEvaluator, 官方源码中也有说明:
A Generic User-defined aggregation function (GenericUDAF) for the use with Hive. New GenericUDAF classes need to inherit from this GenericUDAF class. The GenericUDAF are superior to normal UDAFs in the following ways: 1. It can accept arguments of complex types, and return complex types. 2. It can accept variable length of arguments. 3. It can accept an infinite number of function signature - for example, it's easy to write a GenericUDAF that accepts array , array > and so on (arbitrary levels of nesting).
Hive 作业在执行时,在内部根据执行的不同阶段分为了以下四个 MODE:
1. public static enum Mode {
2. /**
3. * PARTIAL1: This is the map phase of mapreduce: from raw data to partial data aggregation
4. * iterate() and terminatePartial() will be called
5. */
6. PARTIAL1,
7. /**
8. * PARTIAL2: This is the map-side Combiner phase of mapreduce, responsible for merging map data at the map-side: from partial data aggregation to partial data aggregation:
9. * merge() and terminatePartial() will be called
10. */
11. PARTIAL2,
12. /**
13. * FINAL: mapreduce Reduction phase: from partial data aggregation to complete aggregation
14. * merge() and terminate() will be called
15. */
16. FINAL,
17. /**
18. * COMPLETE: If this stage occurs, it means that map reduce has only map, not reduce, so the map side will produce the result directly: from the original data directly to the complete aggregation.
19. * iterate() and terminate() will be called
20. */
21. COMPLETE
22. };
在不同的 MODE, 即不同的执行阶段,框架会调用GenericUDAFEvaluator中的不同方法,上述源码中做了描述,明哥也准备了以下图表帮助大家理解:
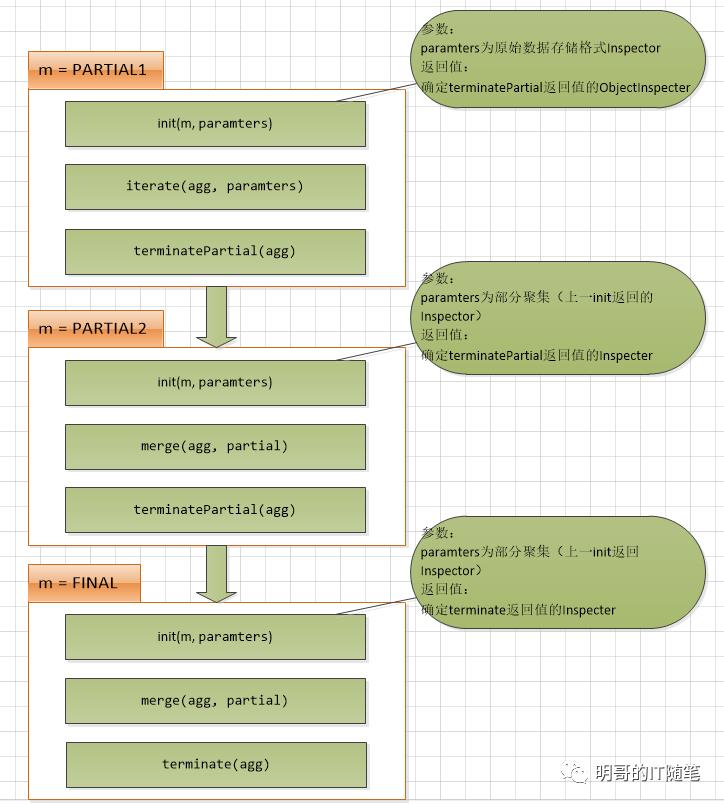
更多关于 UDAF 函数执行时各阶段 map/combiner/reducer 都执行了类中哪些方法,大家可以查阅源码 GenericUDAFEvaluator 以获取更多细节。
以上是关于浅析 hive udaf 的正确编写方式- 论姿势的重要性的主要内容,如果未能解决你的问题,请参考以下文章
浅析 hive udf 的正确编写和使用方式- 论姿势的重要性 - 系列三 - hdfs 相对路径与静态代码块引起的问题