高可用集群架构——redis的主从复制与哨兵模式,cluster
Posted 遙遙背影暖暖流星
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了高可用集群架构——redis的主从复制与哨兵模式,cluster相关的知识,希望对你有一定的参考价值。
redis 的集群
一、redis的集群模式
1、三种模式
redis群集有三种模式,分别是主从同步/复制、哨兵模式、cluster,下面会讲解一下三种模式的工作方式
主从复制:
主从复制是高可用Redis的基础,哨兵和集群都是在主从复制基础上实现高可用的。主从复制主要实现了数据的多机备份,以及对于读操作的负载均衡和简单的故障恢复。
缺陷:故障恢复无法自动化;写操作无法负载均衡;存储能力受到单机的限制。
哨兵:
在主从复制的基础上,哨兵实现了自动化的故障恢复。
缺陷:写操作无法负载均衡;存储能力受到单机的限制。
集群:
通过集群,Redis解决了写操作无法负载均衡,以及存储能力受到单机限制的问题,实现了较为完善的高可用方案。
2、redis集群与哈希槽
redis3.0版本之前只支持单例模式,在3.0版本及以后才支持集群redis集群采用P2P模式,是完全去中心化/无中心化的,不存在中心节点或者代理节点
为了实现集群的高可用,即判新节点是否健康(能否正常使用),redis-cluster有一个投票容错机制;如果集群中超过半数的节点投票认为某个节点挂了,那么这个节点就挂了(fail)。这是判断节点是否挂了的方法:
判断集群是否正常:
如果集群中任意一个节点挂了,而且该节点没有从节点(备份节点),那么这整个集群就挂了。这是判断集群是否挂了的方法
中心化集群和非中心化集群的区别:
1、中心化集群 群集区分主-次关系(区分中心和普通服务器)单点故障由mha缓解(ha不仅仅包含了冗余备份,还有高性能)
2、无中心化/去中心化集群 多台相同的服务器组成集群后,服务器之间不存在主-次关系,即中心服务器和普通服务器关系
去中心化集群,典型的特点是数据共享(每个服务器都会同步对方的数据),挂掉一个不会有太大的影响(非高并发情况下)方便横向扩容(增加服务器),可以说没有特别典型的单点故障,同时去中心化实现ha(高性能)方式是分布式来实现的
有状态和无状态的概念:
无状态:加入集群之后集群认为是普通节点,没有明确的角色定位
有状态:加入集群之后有定位要求(主或从角色),有明确的角色定位
单个节点挂掉整个集群就挂掉的原因:
因为集群(cluster)内置了16384个slot (哈希槽)存储位,并且把所有的redis物理节点映射到了这16384[0-16383]个slot上,或者说把这些slot均等的分配给了各个redis节点(集群模式)。
当需要在Redis集群存放一个数据(key-value)时,redis会先对这个key进行crc16算法,然后得到一个结果再把这个结果对16384进行求余,这个余数会对应[0-16383]其中一个槽,进而决定key-value存储到哪个节点中。所以一旦某个节点挂了,该节点对应的slot就无法使用,那么就会导致集群无法正常工作。
节点A覆盖0-5460;
节点B覆盖5461-10922
节点c覆盖10923-16383
即:每个节点有5461个哈希槽
新增一个节点
节占A覆盖1365-5460
节占B覆盖6827-10922
节点c覆盖12288-16383
节点D覆盖0-1364,5461-6826,10923-12287
即:每个节点有4095个哈希槽
每个Redis集群理论上最多可以有16384个节点。
二、Redis主从复制概述
1、Redis主从复制概述
由于数据是存储在一台服务器上的,如果这台服务器出现硬盘故障等问题,也会导致数据丢失。为了避免单点故障,通常的做法是将数据库复制多个副本以部署在不同的服务器上,这样即使有一台服务器出现故障,其他服务器依然可以继续提供服务,为此,redis提供了复制(replication)功能,可以实现当一台数据库中的数据更新后,自动将更新的数据同步到其他数据库上。
在复制的概念中,数据库分为两类,一类是主数据库(master),另一类是从数据(slave)。主数据可以进行读写操作,当写操做导致数据变化时自动把数据同步给从数据库,而从数据库一般是只读的,并接收主数据同步过来的数据。一个主数据库
可以拥有多个从数据库,而一个从数据库只能拥有一个主数据库
2、主从复制流程

①若启动一个Slave机器进程,则它会向Master机器发送一个"sync command"命令,请求同步连接
②无论是第一次连接还是重新连接,Master机器都会启动一个后台进程,将数据快照(RDB)保存到数据文件中(执行rdb操作),同时Master还会记录修改数据的所有命令并缓存在数据文件中。
③后台进程完成缓存操作之后,Master机器就会向slave机器发送数据文件,Slave端机器将数据文件保存到硬盘上,然后将其加载到内存中,接着Master机器就会将修改数据的所有操作一并发送给slave端机器。若Slave出现故障导致宕机,则恢复正常后会自动重新连接。
④Master机器收到slave端机器的连接后,将其完整的数据文件发送给Slave端,如果Mater同时收到多个slave发来的同步请求则Master会在后台启动一个进程以保存数据文件,然后将其发送给所有的slave端服务器器,确保所有的slave端服务器都正常。
三、哨兵模式
1、简单介绍
(1)哨兵模式集群架构
哨兵是Redis集群架构中非常重要的一个组件,哨兵的出现主要是解决了主从复制出现故障时需要人为干预的问题
(2)哨兵模式主要功能
①集群监控:负责监控Redis master和slave进程是否正常工作
②消息通知:如界某个Redis实例有故障,那么哨兵负责发送消息作为告警通知给管理员
③故障转移:如果master node (master角色)挂掉了,会自动转移到slave node上
④配置中心:如果故障转移发生了,通知client客户端新的master地址
使用一个或者多个哨兵(Sentinel)实例组成的监控管理系统,对redis节点进行监控在主节点出现故障的情况下,能将从节点角色中升级为主节点,进行故障转移,保证系统的可用性。

哨兵服务哨兵服务介绍总结
-监视master服务器
-发现master宕机后,将从服务器升级为主服务器-主配置文件sentinel.conf
-模板文件:redis-4.0.8/sentinel.conf
2、哨兵的工作原理
①哨兵之间相互进行命令连接目的为了在同一频道进行信息共享和监控
②哨兵们向master发送命令连接和订阅连接(周期性)
③哨兵们10/s向master发送info信息,master会回应哨兵本节点的信息状态和从节点的位置
④哨兵收到回复之后,知道从节点的位置
⑤然后再向slaves发送命令连接和订阅连接(周期性),以达到监控整个集群的目的
5、哨兵模式下的故障迁移
(1)主观下线
哨兵(Sentinei)节点会每秒一次的频率向建立了命令连接的实例发送PING命令,如果在down-after-milliseconds毫秒内没有做出有效响应包括(PONG/LOADTNG/NASTERDONM)以外的响应,哨兵就会将该实例在本结构体中的状态标记为SRI_S_DOwN主观下线
(2)客观下线
多方求证(几个哨兵节点认为挂掉了由我们指定)
当一个哨兵节点发现主节点处于主观下线状态时,会向其他的哨兵节点发出询问,该节点是不是已经主观下线了。如果超过配置参数quorum(哨兵节点个数)个节点认为是主观下线时,该哨兵节点就会将自己维护的结构体中该主节点标记为SRIO DOWN客观下线
询问命令SENTINEL is-master-down-by-addr
(3)master选举
在认为主节点客观下线的情况下,哨兵节点,节点间会发起一次选举,命令为:SENTINEL is-master-down-by-addr
只是runid这次会将自己的runid带进去,希望接受者将自己设置为主节点。如果超过半数以上的节点返回将该节点标记为leader的情况下,会有该leader对故障进行迁移
服务器列表中挑选备选master原则:
选在线的
排除反应慢的,与原master断开时间久的
优先原则:
优先级
offset
runid
(4)故障转移
####在从节点中挑选出新的主节点
通讯正常
优先级排序
优先级相同时选择offset最大的(最接近master的)
###将该节点设置成新的主节点SLAVEOF no one,并确保在后续的INGO命令时该节点返回状态为master
###将其他的从节点设置成从新的主节点的从节点,SLAVEOF命令
###将旧的主节点变成新的主节点的从节点
mysql mha
原master 修复完成加入集群的时候,会以slave节点的身份加入
PS:优缺点
#优点:
高可用,哨兵模式是基于主从模式的,所有主从模式的优点,哨兵模式可以简单的检测和故障自动切换,系统更健壮,可用性更高
#缺点:
redis比较难支持在线扩容,在群集容量达到上限时在线扩容会变得很复杂
四、Cluster群集
redis的哨兵模式基本已经可以实现高可用、读写分离,但是在这种模式每台redis服务器都存储相同的数据,很浪费内存资源,所以在redis3.0上加入了cluster群集模式,实现了redis的分布式存储,也就是说每台redis节点存储着不同的内容根据官方推荐,集群部署至少要3台以上的master节点,最好使用3主3从六个节点的模式。
Cluster群集由多个redis服务器组成的分布式网络服务群集,群集之中有多个master主节点,每一个主节点都可读可写,节点之间会相互通信,两两相连,redis群集无中心节点
在redis-Cluster群集中,可以给每个一个主节点添加从节点,主节点和从节点直接尊循主从模型的特性,当用户需要处理更多读请求的时候,添加从节点可以扩展系统的读性能
redis-Cluster的故障转移:
redis群集的主机节点内置了类似redissentinel的节点故障检测和自动故障转移功能,当群集中的某个主节点下线时,群集中的其他在线主节点会注意到这一点,并且对已经下线的主节点进行故障转移
集群进行故障转移的方法和redis sentinel进行故障转移的方法基本一样(投票方式),不同的是,在集群里面,故障转移是由集群中其他在线的主节点负责进行的,所以群集不必另外使用redis sentinel
集群master的数量:奇数。原因:投票机制,挂掉的mater也会有投票。相当于遗书。

实验部分
一、redis的主从复制
实验环境:三台redis
master 192.168.100.8
slave1 192.168.100.6
salve2 192.168.100.7
(安装可参考https://blog.csdn.net/lv74134/article/details/119398093?spm=1001.2014.3001.5501)
1、主服务器上设置
[root@master redis]# vim /etc/redis/6379.conf
bind 0.0.0.0 #80行,监听所有
daemonize yes #137行,开启守护进程
logfile /var/log/redis_6379.log #172指定日志文件目录
dir /var/lib/redis/6379 #264指定工作目录
appendonly yes #700开启aof持久化功能
[root@localhost ~]# service redis restart ##重启生效
Stopping ...
Redis stopped
Starting Redis server...
2、两台slave的设置
[root@master redis]# vim /etc/redis/6379.conf
bind 0.0.0.0 #80行,监听所有
daemonize yes #137行,开启守护进程
logfile /var/log/redis_6379.log #172指定日志文件目录
dir /var/lib/redis/6379 #264指定工作目录
replicaof 192.168.100.8 6379 #288行指定主服务器的ip和端口
appendonly yes #700开启aof持久化功能
[root@localhost ~]# service redis restart ##重启生效
Stopping ...
Redis stopped
Starting Redis server...
3、验证
在master上
[root@master redis]# tail -f /var/log/redis_6379.log #-f可看动态更新
126706:M 03 Aug 2021 12:30:01.648 * Background saving terminated with success
126706:M 03 Aug 2021 12:30:01.648 * Synchronization with replica 192.168.100.7:6379 succeeded #成功
126706:M 03 Aug 2021 12:32:53.504 * Replica 192.168.100.6:6379 asks for synchronization
126706:M 03 Aug 2021 12:32:53.505 * Full resync requested by replica 192.168.100.6:6379
126706:M 03 Aug 2021 12:32:53.505 * Starting BGSAVE for SYNC with target: disk
126706:M 03 Aug 2021 12:32:53.506 * Background saving started by pid 126778
126778:C 03 Aug 2021 12:32:53.506 * DB saved on disk
126778:C 03 Aug 2021 12:32:53.507 * RDB: 0 MB of memory used by copy-on-write
126706:M 03 Aug 2021 12:32:53.549 * Background saving terminated with success
126706:M 03 Aug 2021 12:32:53.549 * Synchronization with replica 192.168.100.6:6379 succeeded #成功
^C
[root@master redis]# redis-cli info replication
# Replication
role:master
connected_slaves:2
slave0:ip=192.168.100.7,port=6379,state=online,offset=532,lag=0
slave1:ip=192.168.100.6,port=6379,state=online,offset=532,lag=0
master_replid:c2c32ec595fa836656ef72a09d2a68daca525b2f
#master启动时生成的40位16进制标识码,用于标识master节点
master_replid2:0000000000000000000000000000000000000000
#复制流中的位置偏移量
master_repl_offset:532
#都表示自己上次主实例repid1和复制偏移量;用于兄弟实例或级联复制,主库故障切换sync
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:532
[root@master redis]# redis-cli
127.0.0.1:6379> keys *
(empty list or set)
127.0.0.1:6379> set mykey zhangsan
OK
在服务器上建立数据,跑到slave上也能看到
[root@slave2 redis]# redis-cli #从服务器上
127.0.0.1:6379>
127.0.0.1:6379>
127.0.0.1:6379> keys *
1) "mykey"
127.0.0.1:6379>
一些常见问题的排错:

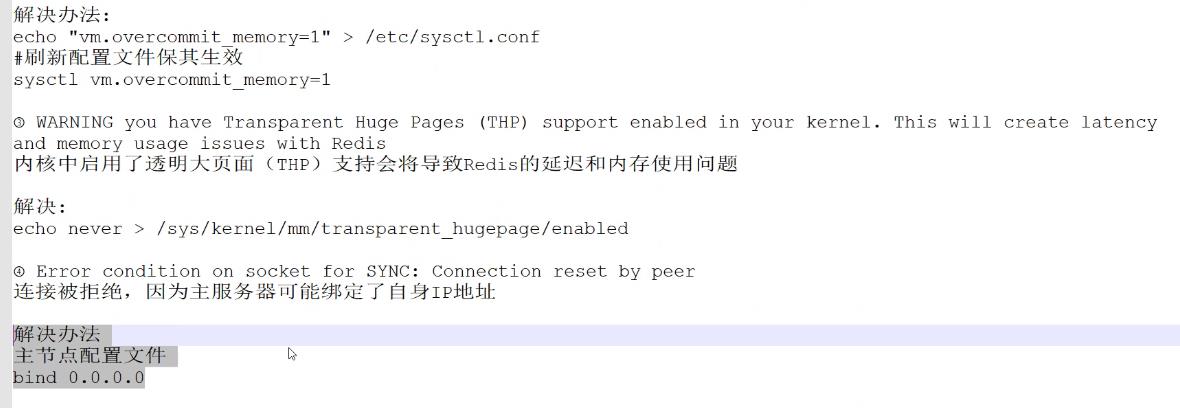
二、哨兵模式
哨兵系统由一个或多个哨兵节点组成,哨兵节点是特殊的redis节点,不存储数据数据节点
实验环境:六台redis
主从复制三台:
master 192.168.100.8
slave1 192.168.100.6
salve2 192.168.100.7
哨兵三台:
sentinel1:192.168.100.3
sentinel2:192.168.100.5
sentinel3:192.168.100.13
(主从复制看第一个实验)
1、配置哨兵(三个节点都配置)
[root@localhost ~]# cp -p /opt/redis-5.0.7/sentinel.conf /etc/redis/ ##将其拷贝到/etc/redis目录下
[root@localhost ~]# cd /etc/redis/
[root@localhost redis]# ls
6379.conf sentinel.conf
[root@localhost redis]# vim /etc/redis/sentinel.conf
port 26379 #21 行,监听端口号
daemonize yes #26行,开启守护进程
pidfile /var/run/redis-sentinel.pid #31行,PID文件位置
logfile "/var/log/sentinel.log" #36行,日志文件位置
dir /var/lib/redis/sentinel #65行,指定工作目录
sentinel monitor mymaster 192.168.100.8 6379 2 #84行,指定监控的 master 地址及端口号,2表示最少两台哨兵投票
sentinel down-after-milliseconds mymaster 3000 #113行,判定服务器down掉的时间周期,默认30000毫秒(30秒)
sentinel failover-timeout mymaster 180000 #146行,故障节点的最大超时时间为180000 (180秒)
[root@localhost ~]# mkdir -p /var/lib/redis/sentinel ##创建配置文件中指定的工作目录
----其他的两台相同配置(可以用scp复制过去scp -p /etc/redis/sentinel.conf root@192.168.100.5:/etc/redis/sentinel.conf)
...........---------------
[root@localhost ~]# redis-sentinel /etc/redis/sentinel.conf ##redis-sentinel命令指定配置文件,开启哨兵模式
[root@localhost ~]# netstat -anpt |grep 26379 ##查看端口状态
tcp 0 0 0.0.0.0:26379 0.0.0.0:* LISTEN 39120/redis-sentine
tcp 0 0 192.168.100.3:51436 192.168.100.5:26379 ESTABLISHED 39120/redis-sentine
tcp 0 0 192.168.100.3:26379 192.168.100.5:45954 ESTABLISHED 39120/redis-sentine
tcp 0 0 192.168.100.3:37216 192.168.100.13:26379 ESTABLISHED 39120/redis-sentine
tcp 0 0 192.168.100.3:26379 192.168.100.13:52986 ESTABLISHED 39120/redis-sentine
tcp6 0 0 :::26379 :::* LISTEN 39120/redis-sentine
[root@sentinel1 redis]# redis-cli -p 26379 info sentinel #查看哨兵信息
# Sentinel
sentinel_masters:1
sentinel_tilt:0
sentinel_running_scripts:0
sentinel_scripts_queue_length:0
sentinel_simulate_failure_flags:0
master0:name=mymaster,status=ok,address=192.168.100.8:6379,slaves=2,sentinels=3 #显示masterip和slave数量和哨兵数量
2、验证
进到master,关闭该redis服务器
[root@master ~]# redis-cli
192.168.10.10:6379> shutdown ##关闭master
回到哨兵下
[root@sentinel1 redis]# redis-cli -p 26379 info sentinel
# Sentinel
sentinel_masters:1
sentinel_tilt:0
sentinel_running_scripts:0
sentinel_scripts_queue_length:0
sentinel_simulate_failure_flags:0
master0:name=mymaster,status=ok,address=192.168.100.7:6379,slaves=2,sentinels=3
#master切换回了100.7
以上是关于高可用集群架构——redis的主从复制与哨兵模式,cluster的主要内容,如果未能解决你的问题,请参考以下文章