python入门爬虫知识点
Posted 梦子mengy7762
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python入门爬虫知识点相关的知识,希望对你有一定的参考价值。
Python学习网络爬虫主要分3个大的版块:抓取,分析,存储
当我们在浏览器中输入一个url后回车,后台会发生什么?
简单来说这段过程发生了以下四个步骤:

网络爬虫要做的,简单来说,就是实现浏览器的功能。通过指定url,直接返回给用户所需要的数据,而不需要一步步人工去操纵浏览器获取。所以想学的同学,有必要听一下这位老师的课、领取python福利奥,想学的同学可以到梦雅老师的围鑫(同音):前排的是:762,中间一排是:459,后排的一组是:510 ,把以上三组字母按照顺序组合起来即可,她会安排学习的。
抓取
这一步,你要明确要得到的内容是什么?是html源码,还是Json格式的字符串等。
- 最基本的抓取
抓取大多数情况属于get请求,Python中自带urllib及urllib2这两个模块,基本上能满足一般的页面抓取。另外,requests也是非常有用的包,与此类似的,还有httplib2等等。

此外,对于带有查询字段的url,get请求一般会将来请求的数据附在url之后,以?分割url和传输数据,多个参数用&连接。
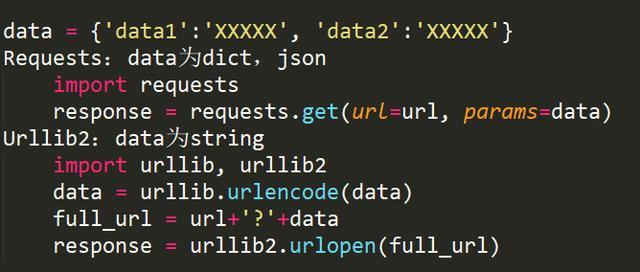
- 对于登陆情况的处理
使用表单登陆
这种情况属于post请求,即先向服务器发送表单数据,服务器再将返回的cookie存入本地。

使用cookie登陆
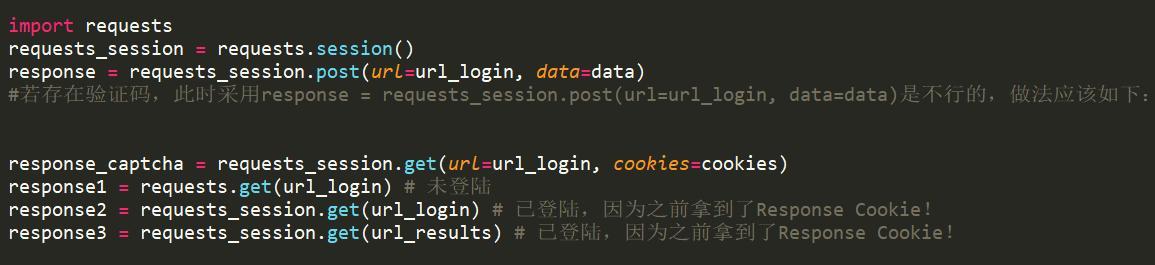
对于反爬虫机制的处理
使用代理
适用情况:限制IP地址情况,也可解决由于“频繁点击”而需要输入验证码登陆的情况。
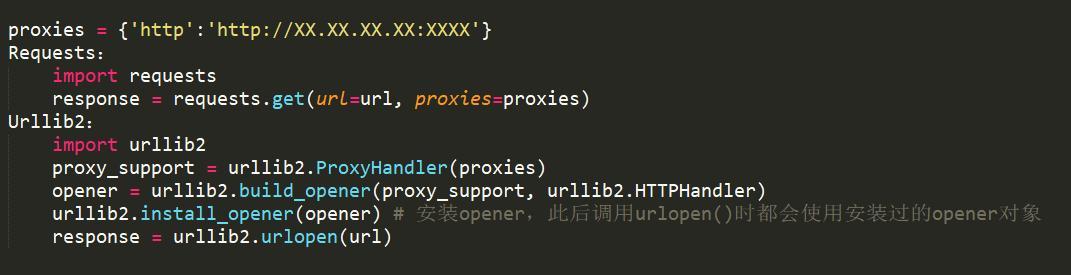
时间设置
适用情况:限制频率情况。
Requests,Urllib2都可以使用time库的sleep()函数:
import time
time.sleep(1)
伪装成浏览器,或者反“反盗链”
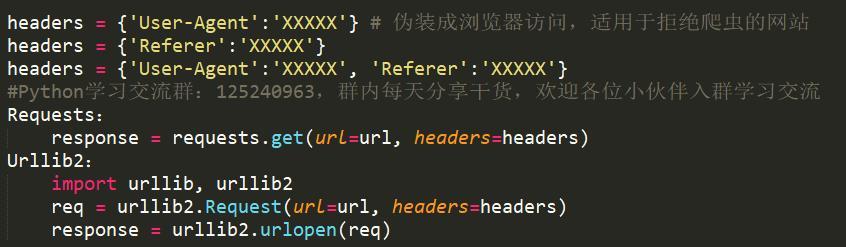
对于断线重连
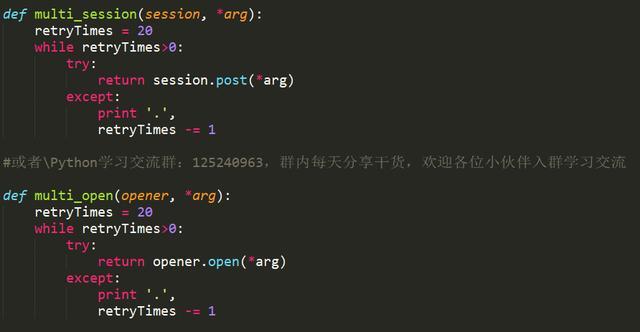
对于Ajax请求的处理
对于“加载更多”情况,使用Ajax来传输很多数据。
它的工作原理是:从网页的url加载网页的源代码之后,会在浏览器里执行javascript程序。所以想学的同学,有必要听一下这位老师的课、领取python福利奥,想学的同学可以到梦雅老师的围鑫(同音):前排的是:762,中间一排是:459,后排的一组是:510 ,把以上三组字母按照顺序组合起来即可,她会安排学习的。

验证码识别
对于网站有验证码的情况,我们有三种办法:
- 使用代理,更新IP。
- 使用cookie登陆。
- 验证码识别。
爬取有两个需要注意的问题:
- 如何监控一系列网站的更新情况,也就是说,如何进行增量式爬取?
- 对于海量数据,如何实现分布式爬取?
分析
抓取之后就是对抓取的内容进行分析,你需要什么内容,就从中提炼出相关的内容来。
常见的分析工具有正则表达式,BeautifulSoup,lxml等等。
存储
分析出我们需要的内容之后,接下来就是存储了。
我们可以选择存入文本文件,也可以选择存入mysql或MongoDB数据库等。
存储有两个需要注意的问题:
- 如何进行网页去重?
- 内容以什么形式存储?
你要不要也来试试,用 Python 测测你和女神的颜值差距(仅供娱乐,请勿联想)
如果真的遇到好的同事,那算你走运,加油,抓紧学到手。
python、爬虫技巧资源分享添加围鑫(同音):762459510
包含python, pythonweb、爬虫、数据分析等Python技巧,以及人工智能、大数据、数据挖掘、自动化办公等的学习方法。
打造从零基础到项目开发上手实战全方位解析!
以上是关于python入门爬虫知识点的主要内容,如果未能解决你的问题,请参考以下文章