翻译TCP backlog在Linux中的工作原理
Posted sduzh
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了翻译TCP backlog在Linux中的工作原理相关的知识,希望对你有一定的参考价值。
原文How TCP backlog works in Linux
水平有限,难免有错,欢迎指出!
以下为翻译:
当应用程序通过系统调用listen将一个套接字(socket)置为LISTEN状态时,需要为该套接字指定一个backlog参数,该参数通常被描述为用来限制进来的连接队列长度(queue of incoming connections)。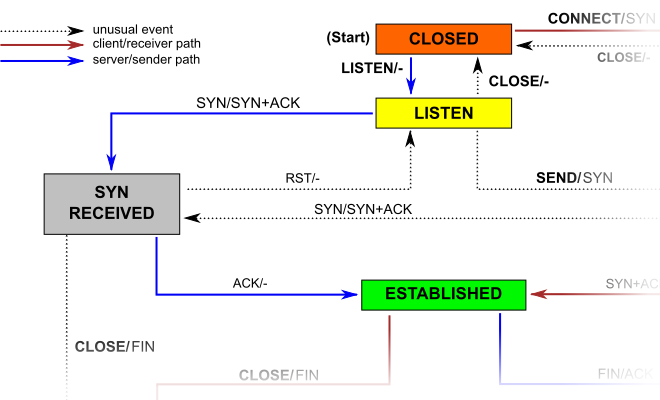
由于TCP协议的三次握手机制,一个进来的套接字连接在进入ESTABLISHED状态并且可以被accept调用返回给应用程序之前,会经历中间状态SYN RECEIVED(见上图)。这意味着TCP协议栈可以有两种方案来实现backlog队列:
- 只使用一个队列,队列大小由系统调用listen的backlog参数指定。服务端收到一个SYN数据包后将返回一个SYN/ACK数据包,同时将该连接放入到队列中。当服务端再次收到客户端返回的ACK时,该连接状态将变为ESTABLISHED,从而有资格被交给应用程序处理。
- 使用两个队列,一个SYN队列和一个accept队列。处于SYN RECEIVED状态的连接会被添加到SYN队列中,等到后续收到ACK变为ESTABLISHED状态后,该连接会被转移到accept队列中。顾名思义,在这种实现方式下,accept系统调用可以简单地实现为从accept队列中消费连接,此时listen调用的backlog参数决定的是accept队列的大小。
历史上,BCD派生的TCP实现采用第一种方案,这意味着当队列大小达到backlog最大值时,系统将不再发送用以响应SYN数据包的SYN/ACK数据包。通常,TCP实现将简单地丢弃收到的SYN数据包(而不是发送RST数据包)以便客户端重试。这也是W. Richard Stevens的经典教科书《TCP/IP详解 卷三》14.5节listen Backlog Queue中所描述的方案。
需要注意的是,W. Richard Stevens解释说BSD的实现实际上确实是使用两个单独的队列,但是它们表现为一个单个队列,其最大长度固定且由(但不是必须完全等于)backlog参数确定,即BSD逻辑上如方案1所述。
Linux上的情况有些不同,listen的man手册写到:
The behavior of the backlog argument on TCP sockets changed with Linux 2.2. Now it specifies the queue length forcompletely established sockets waiting to be accepted, instead of the number of incomplete connection requests. The maximum length of the queue for incomplete sockets can be set using /proc/sys/net/ipv4/tcp_max_syn_backlog
TCP套接字上的backlog参数的行为随Linux 2.2而改变。 现在它指等待被接受(accept)的、完全建立的套接字的队列长度,而不是不完整的连接请求数。 不完整套接字队列的最大长度可以通过/proc/sys/net/ipv4/tcp_max_syn_backlog设置
这意味着当前Linux版本采用的是具有两个不同队列的方案二:一个SYN队列,大小由系统范围的设置指定;一个accept队列,大小由应用程序指定。 方案2一个有趣的问题是,如果当前accept队列已满,而一个连接需要从SYN队列中移到accept队列中,这个时候TCP实现将如何处理?这种情况由net/ipv4/tcp_minisocks.c中的tcp_check_req函数处理。 相关代码如下:
child = inet_csk(sk)->icsk_af_ops->syn_recv_sock(sk, skb, req, NULL);
if (child == NULL)
goto listen_overflow;对于IPV4,第一行代码实际会调用net/ipv4/tcp_ipv4.c中的tcp_v4_syn_recv_sock,其中包含如下代码:
if (sk_acceptq_is_full(sk))
goto exit_overflow;上面的代码中可以看到对accept队列的检查。exit_overflow标签之后的代码将执行一些清理工作,更新/proc/net/netstat中的ListenOverflows和ListenDrops统计信息,然后返回NULL,这将触发执行tcp_check_req中的listen_overflow代码:
listen_overflow:
if (!sysctl_tcp_abort_on_overflow) {
inet_rsk(req)->acked = 1;
return NULL;
}这意味着除非/proc/sys/net/ipv4/tcp_abort_on_overflow设置为1(这种情况下将如代码所示发送RST数据包),否则TCP实现基本上不做任何事情!
总而言之,如果Linux中的(服务端)TCP实现接收到(客户端)三次握手的ACK数据包,并且accept队列已满,则(服务端)基本上将忽略该数据包。这种处理方式刚听起来可能有点奇怪,但是请记住,SYN RECEIVED状态有一个关联定时器:如果服务端没有收到ACK(或者像这里所说的被忽略),则TCP实现将重新发送 SYN/ACK数据包(重试次数由/proc/sys /net/ipv4/tcp_synack_retries指定,并使用指数退避算法)。
上述现象可以在以下数据包跟踪中看到,客户端尝试连接(并发送数据)到已达到其最大backlog的套接字:
0.000 127.0.0.1 -> 127.0.0.1 TCP 74 53302 > 9999 [SYN] Seq=0 Len=0
0.000 127.0.0.1 -> 127.0.0.1 TCP 74 9999 > 53302 [SYN, ACK] Seq=0 Ack=1 Len=0
0.000 127.0.0.1 -> 127.0.0.1 TCP 66 53302 > 9999 [ACK] Seq=1 Ack=1 Len=0
0.000 127.0.0.1 -> 127.0.0.1 TCP 71 53302 > 9999 [PSH, ACK] Seq=1 Ack=1 Len=5
0.207 127.0.0.1 -> 127.0.0.1 TCP 71 [TCP Retransmission] 53302 > 9999 [PSH, ACK] Seq=1 Ack=1 Len=5
0.623 127.0.0.1 -> 127.0.0.1 TCP 71 [TCP Retransmission] 53302 > 9999 [PSH, ACK] Seq=1 Ack=1 Len=5
1.199 127.0.0.1 -> 127.0.0.1 TCP 74 9999 > 53302 [SYN, ACK] Seq=0 Ack=1 Len=0
1.199 127.0.0.1 -> 127.0.0.1 TCP 66 [TCP Dup ACK 6#1] 53302 > 9999 [ACK] Seq=6 Ack=1 Len=0
1.455 127.0.0.1 -> 127.0.0.1 TCP 71 [TCP Retransmission] 53302 > 9999 [PSH, ACK] Seq=1 Ack=1 Len=5
3.123 127.0.0.1 -> 127.0.0.1 TCP 71 [TCP Retransmission] 53302 > 9999 [PSH, ACK] Seq=1 Ack=1 Len=5
3.399 127.0.0.1 -> 127.0.0.1 TCP 74 9999 > 53302 [SYN, ACK] Seq=0 Ack=1 Len=0
3.399 127.0.0.1 -> 127.0.0.1 TCP 66 [TCP Dup ACK 10#1] 53302 > 9999 [ACK] Seq=6 Ack=1 Len=0
6.459 127.0.0.1 -> 127.0.0.1 TCP 71 [TCP Retransmission] 53302 > 9999 [PSH, ACK] Seq=1 Ack=1 Len=5
7.599 127.0.0.1 -> 127.0.0.1 TCP 74 9999 > 53302 [SYN, ACK] Seq=0 Ack=1 Len=0
7.599 127.0.0.1 -> 127.0.0.1 TCP 66 [TCP Dup ACK 13#1] 53302 > 9999 [ACK] Seq=6 Ack=1 Len=0
13.131 127.0.0.1 -> 127.0.0.1 TCP 71 [TCP Retransmission] 53302 > 9999 [PSH, ACK] Seq=1 Ack=1 Len=5
15.599 127.0.0.1 -> 127.0.0.1 TCP 74 9999 > 53302 [SYN, ACK] Seq=0 Ack=1 Len=0
15.599 127.0.0.1 -> 127.0.0.1 TCP 66 [TCP Dup ACK 16#1] 53302 > 9999 [ACK] Seq=6 Ack=1 Len=0
26.491 127.0.0.1 -> 127.0.0.1 TCP 71 [TCP Retransmission] 53302 > 9999 [PSH, ACK] Seq=1 Ack=1 Len=5
31.599 127.0.0.1 -> 127.0.0.1 TCP 74 9999 > 53302 [SYN, ACK] Seq=0 Ack=1 Len=0
31.599 127.0.0.1 -> 127.0.0.1 TCP 66 [TCP Dup ACK 19#1] 53302 > 9999 [ACK] Seq=6 Ack=1 Len=0
53.179 127.0.0.1 -> 127.0.0.1 TCP 71 [TCP Retransmission] 53302 > 9999 [PSH, ACK] Seq=1 Ack=1 Len=5
106.491 127.0.0.1 -> 127.0.0.1 TCP 71 [TCP Retransmission] 53302 > 9999 [PSH, ACK] Seq=1 Ack=1 Len=5
106.491 127.0.0.1 -> 127.0.0.1 TCP 54 9999 > 53302 [RST] Seq=1 Len=0
客户端TCP实现由于收到多个SYN/ACK数据包,会假定其发送的ACK数据包丢失,从而重新发送ACK(参见上述跟踪中的TCP Dup ACK行)。
如果服务器端的应用程序在达到SYN/ACK最大重试次数之前减少了backlog(即从accept队列中消耗了一个条目),则TCP实现最终将会处理一个客户端重复发送的ACK,将连接状态从SYN RECEIVED转换到ESTABLISHED,并将连接添加到accept队列。否则的话,客户端最终会收到一个RST数据包(如上图所示)。
数据包跟踪同时也展示了上述行为另一个有趣的一面。从客户端的角度来说,TCP连接将在收到第一个SYN/ACK数据包之后变为ESTABLISHED状态。如果客户端向服务端发送数据(不等待来自服务端的数据),则该数据也会被重传。幸运的是,TCP的慢启动可以限制重传阶段发送的数据段个数。
另一方面,如果客户端一直在等待来自服务端的数据,而服务端的backlog一直没有降低,则最终的结果是客户端的连接状态是ESTABLISHED,而服务端的连接状态则是SYN_RCVD(注:原文说的是CLOSED状态,应该是不对的),也就是处于一个半连接的状态!
还有另一个方面我们目前没有讨论。listen的man手册引用表明,除非SYN队列已满,否则每个SYN数据包都将导致TCP连接被添加到SYN队列中,这种说法和实际情况有所出入,原因在于net/ipv4/tcp_ipv4.c中的tcp_v4_conn_request函数存在以下一段代码:
/* Accept backlog is full. If we have already queued enough
* of warm entries in syn queue, drop request. It is better than
* clogging syn queue with openreqs with exponentially increasing
* timeout.
*/
if (sk_acceptq_is_full(sk) && inet_csk_reqsk_queue_young(sk) > 1) {
NET_INC_STATS_BH(sock_net(sk), LINUX_MIB_LISTENOVERFLOWS);
goto drop;
}上面的代码意味着,如果当前accept队列已满,内核会对接收SYN数据包的速率施加限制。如果收到太多SYN数据包其中一些将会被丢弃,这将导致客户端重试发送SYN数据包,从而最终得到与BSD派生实现中相同的行为。
最后看看为什么Linux的设计选择会优于传统的BSD实现。 Stevens提出了以下有趣的观点:
The backlog can be reached if the completed connection queue fills (i.e., the server process or the server host is so busy that the process cannot call accept fast enough to take the completed entries off the queue) or if the incomplete connection queue fills. The latter is the problem that HTTP servers face, when the round-trip time between the client and server is long, compared to the arrival rate of new connection requests, because a new SYN occupies an entry on this queue for one round-trip time. […]
The completed connection queue is almost always empty because when an entry is placed on this queue, the server’s call to accept returns, and the server takes the completed connection off the queue.
Stevens提出的解决方案只是增加backlog。这样做的问题在于它假定如果应用程序希望调整backlog,不仅要考虑如何处理新建立的传入连接,还有考虑诸如往返时间等流量特性。Linux中的实现有效地分离了这两个问题:应用程序只负责调整backlog,使其可以足够快地接收(accept)连接,避免填满accept队列; 系统管理员则可以根据流量特性调整/proc/sys/net/ipv4/tcp_max_syn_backlog
以上是关于翻译TCP backlog在Linux中的工作原理的主要内容,如果未能解决你的问题,请参考以下文章