强化学习专栏|有限马尔可夫决策过程(Finite Markov Decision Processes)
Posted 码丽莲梦露
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了强化学习专栏|有限马尔可夫决策过程(Finite Markov Decision Processes)相关的知识,希望对你有一定的参考价值。
有限马尔可夫决策问题(后文简写为finite MDPs)包括评价性的反馈,就像强盗一样,但也有联想的一面——在不同的情况下选择不同的行动。MDPs是顺序决策的经典形式,其中行动不仅影响眼前的reward,还影响随后的情况或状态。因此,MDP涉及权衡即时和延迟奖励的需要。而在强盗问题中,我们估计每个动作a的值q*(a),在MDPs中,我们估计每个状态s中每个动作a的值q*(s,a )。MDP是强化学习问题的数学理想化形式,可以对其进行精确的理论陈述。
1 代理-环境接口(The Agent-Environment Interface)
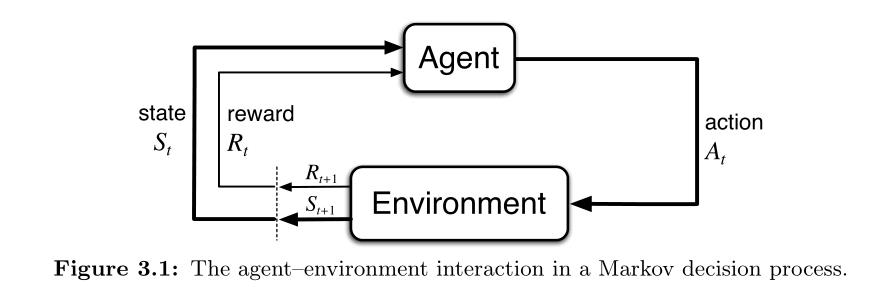
以上是关于强化学习专栏|有限马尔可夫决策过程(Finite Markov Decision Processes)的主要内容,如果未能解决你的问题,请参考以下文章