深度解剖HashMap底层原理
Posted 勇敢牛牛不怕困难@帅
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度解剖HashMap底层原理相关的知识,希望对你有一定的参考价值。
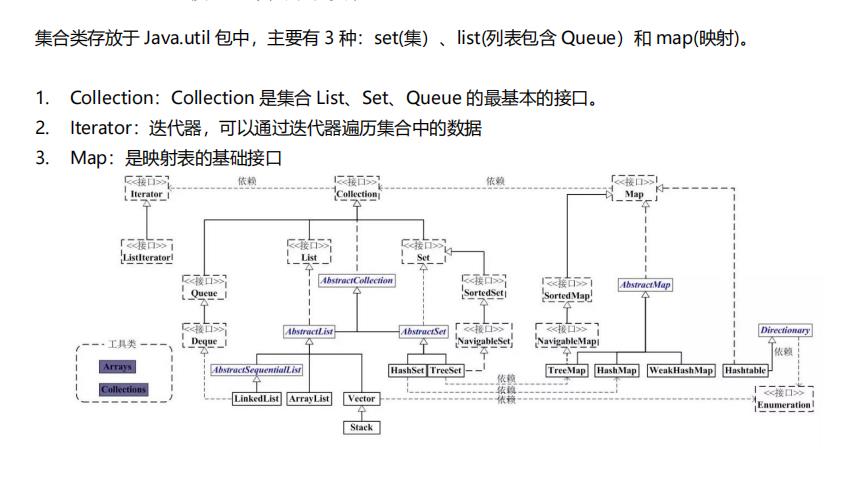
HashMap底层原理

写在前面
HashMap实现了Map, Cloneable, Serializable接口,继承了AbstractMap类,Map也是属于容器的父接口,Map接口主要用来存储的是键值对,根据hashCode值存储数据,大多数情况下可以直接定位到它的值,因而具有很快的访问速度,但遍历的顺序却是不确定的。HashMap最多只允许有一条记录的键为null,允许多个值为null。HashMap的线程并不安全,可能多个线程对HashMap进行操作会导致数据不一致,如果想满足线程安全,可以使用Collections帮助类的synchronizedMap方法使HashMap具有线程安全能力,或者使用ConcurrentHashMap。
JDK1.7版本——HashMap
JAVA7对于HashMap的实现主要用的数据结构是数组+链表,每个数组中的每个元素是一个单向链表,下图中每个绿色的实体就是内部类Entry的实例对象,Entry包括四个属性:key、value、hash值和指向下一个Entry对象的next指针。每个链表相当于一个hashtable的桶,链表主要用于解决hash冲突:如果不同key值计算出来的hash值相同,将会存储到数组相同的位置,由于之前的hash值数组位置已经存放了元素,则将原先位置的元素移到单链表的中,冲突hash值对应的键值存放到数组元素中。(发生冲突时新元素总是放在数组中,也就是在链表的头部,然后将原来的元素移入到链表中,类似于单链表的头插法!)
该采用链表解决hash冲突的方法 = 链地址法
重要参数
1.capacity:当前数组容量,始终保持 2^n,可以扩容,扩容后数组大小为当前的 2 倍。
2. loadFactor:负载因子,默认为 0.75。
3. threshold:扩容的阈值,等于 capacity * loadFactor

java.1.7源码分析
类的定义:基于Map接口的实现类,继承了AbstractMap抽象类,实现了Cloneable接口和Serializable接口,可实现序列化和拷贝。
public class HashMap<K,V>
extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable
Entry内部类实现源码,具体信息看注释!Entry主要作用也就是用来存储HashMap中的Key和Value,通过HashCode计算出Entry对象应该去的数组下标位置。
/**
* Entry类实现了Map.Entry接口
* 即 实现了getKey()、getValue()、equals(Object o)和hashCode()等方法
**/
static class Entry<K,V> implements Map.Entry<K,V> {
final K key; // 键
V value; // 值
Entry<K,V> next; // 指向下一个节点 ,也是一个Entry对象,从而形成解决hash冲突的单链表
int hash; // hash值
/**
* 构造方法,创建一个Entry
* 参数:哈希值h,键值k,值v、下一个节点n
*/
Entry(int h, K k, V v, Entry<K,V> n) {
value = v;
next = n;
key = k;
hash = h;
}
// 返回 与 此项 对应的键
public final K getKey() {
return key;
}
// 返回 与 此项 对应的值
public final V getValue() {
return value;
}
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
/**
* equals()
* 作用:判断2个Entry是否相等,必须key和value都相等,才返回true
*/
public final boolean equals(Object o) {
if (!(o instanceof Map.Entry))
return false;
Map.Entry e = (Map.Entry)o;
Object k1 = getKey();
Object k2 = e.getKey();
if (k1 == k2 || (k1 != null && k1.equals(k2))) {
Object v1 = getValue();
Object v2 = e.getValue();
if (v1 == v2 || (v1 != null && v1.equals(v2)))
return true;
}
return false;
}
/**
* hashCode()
*/
public final int hashCode() {
return Objects.hashCode(getKey()) ^ Objects.hashCode(getValue());
}
public final String toString() {
return getKey() + "=" + getValue();
}
/**
* 当向HashMap中添加元素时,即调用put(k,v)时,
* 对已经在HashMap中k位置进行v的覆盖时,会调用此方法
* 此处没做任何处理
*/
void recordAccess(HashMap<K,V> m) {
}
/**
* 当从HashMap中删除了一个Entry时,会调用该函数
* 此处没做任何处理
*/
void recordRemoval(HashMap<K,V> m) {
}
}
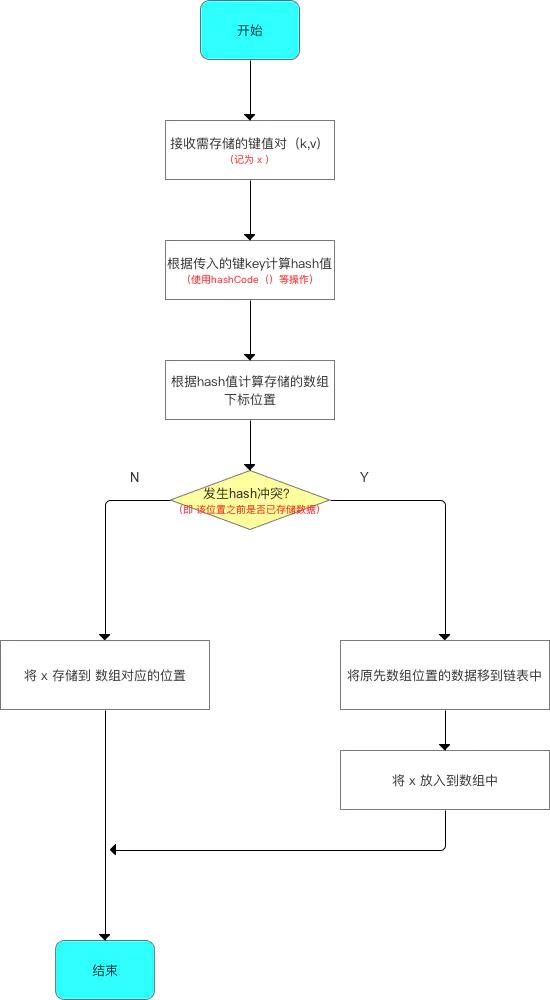
new一个HashMap实例的存储流程图如下:
API常用方法
V get(Object key); // 获得指定键的值
V put(K key, V value); // 添加键值对
void putAll(Map<? extends K, ? extends V> m); // 将指定Map中的键值对 复制到 此Map中
V remove(Object key); // 删除该键值对
boolean containsKey(Object key); // 判断是否存在该键的键值对;是 则返回true
boolean containsValue(Object value); // 判断是否存在该值的键值对;是 则返回true
Set<K> keySet(); // 单独抽取key序列,将所有key生成一个Set
Collection<V> values(); // 单独value序列,将所有value生成一个Collection
void clear(); // 清除哈希表中的所有键值对
int size(); // 返回哈希表中所有 键值对的数量 = 数组中的键值对 + 链表中的键值对
boolean isEmpty(); // 判断HashMap是否为空;size == 0时 表示为 空
API中重要的变量
// 1. 容量(capacity): HashMap中数组的长度
// a. 容量范围:必须是2的幂 & <最大容量(2的30次方)
// b. 初始容量 = 哈希表创建时的容量
// 默认容量 = 16 = 1<<4 = 00001中的1向左移4位 = 10000 = 十进制的2^4=16
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;
// 最大容量 = 2的30次方(若传入的容量过大,将被最大值替换)
static final int MAXIMUM_CAPACITY = 1 << 30;
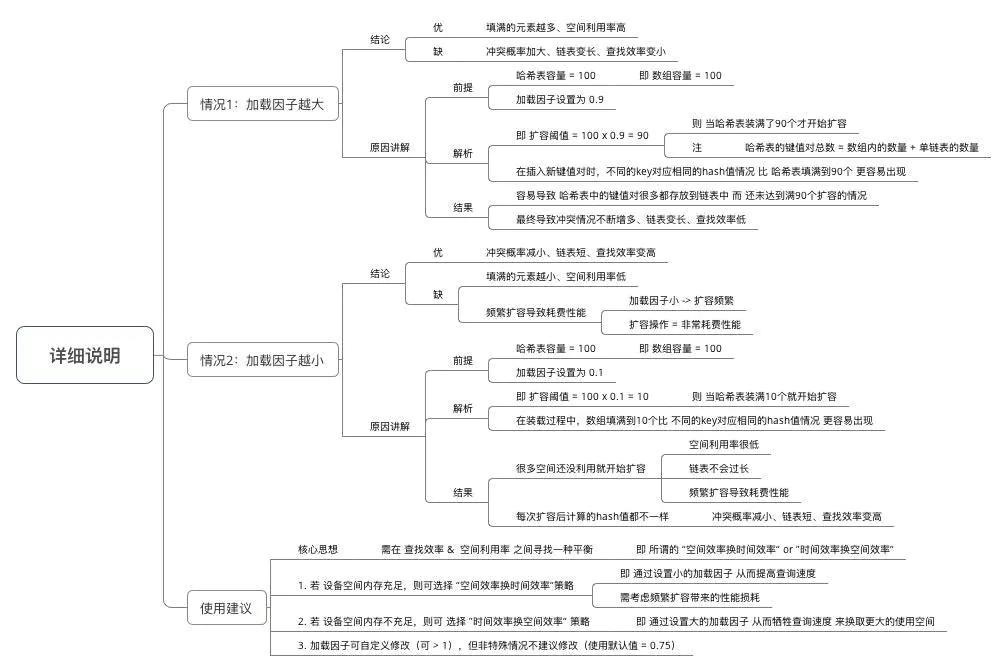
// 2. 加载因子(Load factor):HashMap在其容量自动增加前可达到多满的一种尺度
// a. 加载因子越大、填满的元素越多 = 空间利用率高、但冲突的机会加大、查找效率变低(因为链表变长了)
// b. 加载因子越小、填满的元素越少 = 空间利用率小、冲突的机会减小、查找效率高(链表不长)
// 实际加载因子
final float loadFactor;
// 默认加载因子 = 0.75
static final float DEFAULT_LOAD_FACTOR = 0.75f;
// 3. 扩容阈值(threshold):当哈希表的大小 ≥ 扩容阈值时,就会扩容哈希表(即扩充HashMap的容量)
// a. 扩容 = 对哈希表进行resize操作(即重建内部数据结构),从而哈希表将具有大约两倍的桶数
// b. 扩容阈值 = 容量 x 加载因子
int threshold;
// 4. 其他
// 存储数据的Entry类型 数组,长度 = 2的幂
// HashMap的实现方式 = 拉链法,Entry数组上的每个元素本质上是一个单向链表
transient Entry<K,V>[] table = (Entry<K,V>[]) EMPTY_TABLE;
// HashMap的大小,即 HashMap中存储的键值对的数量
transient int size;
加载因子详细说明:
第一步:申明一个HashMap对象
/**
* 函数使用原型
*/
Map<String,Integer> map = new HashMap<String,Integer>();
/**
* 源码分析:主要是HashMap的构造函数 = 4个
* 仅贴出关于HashMap构造函数的源码
*/
public class HashMap<K,V>
extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable{
// 省略上节阐述的参数
/**
* 构造函数1:默认构造函数(无参)
* 加载因子 & 容量 = 默认 = 0.75、16
*/
public HashMap() {
// 实际上是调用构造函数3:指定“容量大小”和“加载因子”的构造函数
// 传入的指定容量 & 加载因子 = 默认
this(DEFAULT_INITIAL_CAPACITY, DEFAULT_LOAD_FACTOR);
}
/**
* 构造函数2:指定“容量大小”的构造函数
* 加载因子 = 默认 = 0.75 、容量 = 指定大小
*/
public HashMap(int initialCapacity) {
// 实际上是调用指定“容量大小”和“加载因子”的构造函数
// 只是在传入的加载因子参数 = 默认加载因子
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
/**
* 构造函数3:指定“容量大小”和“加载因子”的构造函数
* 加载因子 & 容量 = 自己指定
*/
public HashMap(int initialCapacity, float loadFactor) {
// HashMap的最大容量只能是MAXIMUM_CAPACITY,哪怕传入的 > 最大容量
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
// 设置 加载因子
this.loadFactor = loadFactor;
// 设置 扩容阈值 = 初始容量
// 注:此处不是真正的阈值,是为了扩展table,该阈值后面会重新计算,下面会详细讲解
threshold = initialCapacity;
init(); // 一个空方法用于未来的子对象扩展
}
/**
* 构造函数4:包含“子Map”的构造函数
* 即 构造出来的HashMap包含传入Map的映射关系
* 加载因子 & 容量 = 默认
*/
public HashMap(Map<? extends K, ? extends V> m) {
// 设置容量大小 & 加载因子 = 默认
this(Math.max((int) (m.size() / DEFAULT_LOAD_FACTOR) + 1,
DEFAULT_INITIAL_CAPACITY), DEFAULT_LOAD_FACTOR);
// 该方法用于初始化 数组 & 阈值,下面会详细说明
inflateTable(threshold);
// 将传入的子Map中的全部元素逐个添加到HashMap中
putAllForCreate(m);
}
}
第二步:存放键值对,put()方法
/**
* 函数使用原型
*/
map.put("A", 1);
map.put("B", 2);
map.put("C", 3);
map.put("D", 4);
map.put("E", 5);
/**
* 源码分析:主要分析: HashMap的put函数
*/
public V put(K key, V value)
(分析1)// 1. 若 哈希表未初始化(即 table为空)
// 则使用 构造函数时设置的阈值(即初始容量) 初始化 数组table
if (table == EMPTY_TABLE) {
inflateTable(threshold);
}
// 2. 判断key是否为空值null
(分析2)// 2.1 若key == null,则将该键-值 存放到数组table 中的第1个位置,即table [0]
// (本质:key = Null时,hash值 = 0,故存放到table[0]中)
// 该位置永远只有1个value,新传进来的value会覆盖旧的value
if (key == null)
return putForNullKey(value);
(分析3) // 2.2 若 key ≠ null,则计算存放数组 table 中的位置(下标、索引)
// a. 根据键值key计算hash值
int hash = hash(key);
// b. 根据hash值 最终获得 key对应存放的数组Table中位置
int i = indexFor(hash, table.length);
// 3. 判断该key对应的值是否已存在(通过遍历 以该数组元素为头结点的链表 逐个判断)
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
(分析4)// 3.1 若该key已存在(即 key-value已存在 ),则用 新value 替换 旧value
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue; //并返回旧的value
}
}
modCount++;
(分析5)// 3.2 若 该key不存在,则将“key-value”添加到table中
addEntry(hash, key, value, i);
return null;
}
第三步:获取数据get()
/**
* 函数原型
* 作用:根据键key,向HashMap获取对应的值
*/
map.get(key);
/**
* 源码分析
*/
public V get(Object key) {
// 1. 当key == null时,则到 以哈希表数组中的第1个元素(即table[0])为头结点的链表去寻找对应 key == null的键
if (key == null)
return getForNullKey(); --> 分析1
// 2. 当key ≠ null时,去获得对应值 -->分析2
Entry<K,V> entry = getEntry(key);
return null == entry ? null : entry.getValue();
}
/**
* 分析1:getForNullKey()
* 作用:当key == null时,则到 以哈希表数组中的第1个元素(即table[0])为头结点的链表去寻找对应 key == null的键
*/
private V getForNullKey() {
if (size == 0) {
return null;
}
// 遍历以table[0]为头结点的链表,寻找 key==null 对应的值
for (Entry<K,V> e = table[0]; e != null; e = e.next) {
// 从table[0]中取key==null的value值
if (e.key == null)
return e.value;
}
return null;
}
/**
* 分析2:getEntry(key)
* 作用:当key ≠ null时,去获得对应值
*/
final Entry<K,V> getEntry(Object key) {
if (size == 0) {
return null;
}
// 1. 根据key值,通过hash()计算出对应的hash值
int hash = (key == null) ? 0 : hash(key);
// 2. 根据hash值计算出对应的数组下标
// 3. 遍历 以该数组下标的数组元素为头结点的链表所有节点,寻找该key对应的值
for (Entry<K,V> e = table[indexFor(hash, table.length)]; e != null; e = e.next) {
Object k;
// 若 hash值 & key 相等,则证明该Entry = 我们要的键值对
// 通过equals()判断key是否相等
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
}
return null;
}
对HashMap的其他操作
/**
* 函数:isEmpty()
* 作用:判断HashMap是否为空,即无键值对;size == 0时 表示为 空
*/
public boolean isEmpty() {
return size == 0;
}
/**
* 函数:size()
* 作用:返回哈希表中所有 键值对的数量 = 数组中的键值对 + 链表中的键值对
*/
public int size() {
return size;
}
/**
* 函数:clear()
* 作用:清空哈希表,即删除所有键值对
* 原理:将数组table中存储的Entry全部置为null、size置为0
*/
public void clear() {
modCount++;
Arrays.fill(table, null);
size = 0;
}
/**
* 函数:putAll(Map<? extends K, ? extends V> m)
* 作用:将指定Map中的键值对 复制到 此Map中
* 原理:类似Put函数
*/
public void putAll(Map<? extends K, ? extends V> m) {
// 1. 统计需复制多少个键值对
int numKeysToBeAdded = m.size();
if (numKeysToBeAdded == 0)
return;
// 2. 若table还没初始化,先用刚刚统计的复制数去初始化table
if (table == EMPTY_TABLE) {
inflateTable((int) Math.max(numKeysToBeAdded * loadFactor, threshold));
}
// 3. 若需复制的数目 > 阈值,则需先扩容
if (numKeysToBeAdded > threshold) {
int targetCapacity = (int)(numKeysToBeAdded / loadFactor + 1);
if (targetCapacity > MAXIMUM_CAPACITY)
targetCapacity = MAXIMUM_CAPACITY;
int newCapacity = table.length;
while (newCapacity < targetCapacity)
newCapacity <<= 1;
if (newCapacity > table.length)
resize(newCapacity);
}
// 4. 开始复制(实际上不断调用Put函数插入)
for (Map.Entry<? extends K, ? extends V> e : m.entrySet())
put(e.getKey(), e.getValue())以上是关于深度解剖HashMap底层原理的主要内容,如果未能解决你的问题,请参考以下文章