目标检测yolo系列-yolo v3(2018年)
Posted 超级无敌陈大佬的跟班
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了目标检测yolo系列-yolo v3(2018年)相关的知识,希望对你有一定的参考价值。
YOLOv3
1、网络结构图
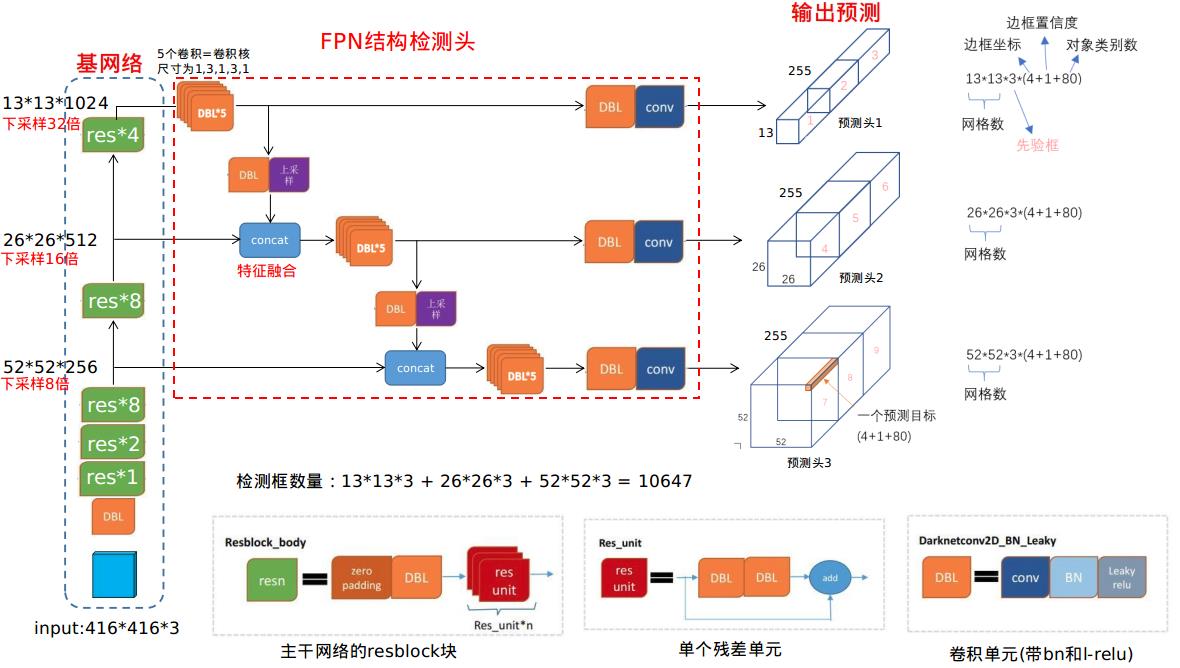
备注:图参考自 另一位作者文章
- resnetblock块(绿色):由若干个残差单元串联;
- res_unit残差单元(红色):由两个卷积单元和一个shortcut链接组成;
- DBL卷积单元(橙色):一个卷积核后面加BN和leaky-relu组成;
yolo v3结构:
- 输入尺寸:416*416*3,主干网络:使用Darknet-53,检测头:由3个检测分支的FPN结构组成,分别为原图下采样8、16、32倍。
- feature map的每个单元格有3个尺度的anchor;
- 每个bbox维度为85,由4个坐标,1个confidence,80类别概率组成;
2、yolov3边框回归
2.1 anchor的尺寸
- 下采样32倍(13*13)特征图:每个cell的三个anchor boxes为(116 ,90),(156 ,198),(373 ,326)。
- 下采样16倍(26x26)特征图:适合一般大小的物体,anchor boxes为(30,61), (62,45),(59,119)。
- 下采样8倍(52x52)特征图:感受野最小,适合检测小目标,因此anchor boxes为(10,13),(16,30),(33,23)。
- 所以当输入为416×416时,实际总共有(52×52+26×26+13×13)×3=10647个proposal boxes。

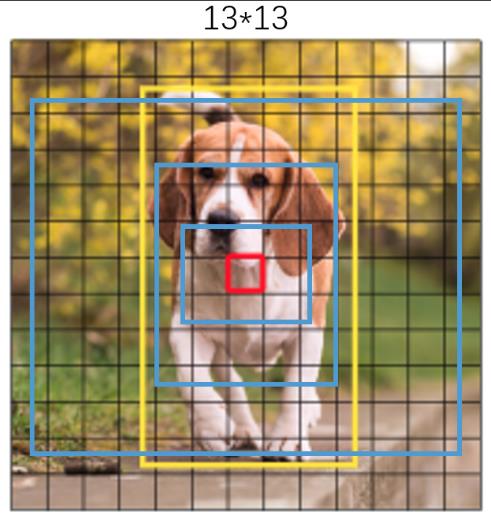
下面是通过图片实际感受一下9种先验框的尺寸,图中蓝色框为聚类得到的先验框。黄色框式ground truth,红框是对象中心点所在的网格。下面分别是三个尺寸feature map



2.2 边框回归
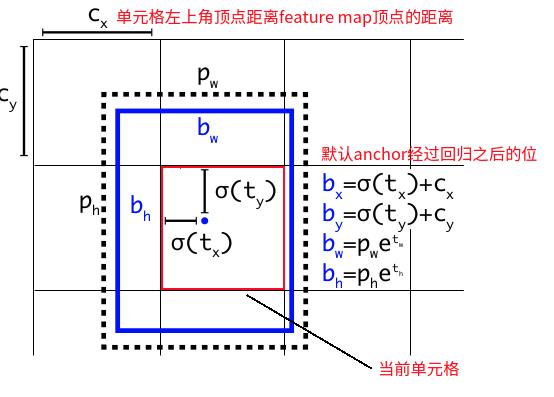
- 网络学习的参数:bbox的偏移量和尺度缩放四个值
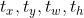 ;注意:这里的偏移量是anchor框的中心点相对于单元格左顶点的偏移量。
;注意:这里的偏移量是anchor框的中心点相对于单元格左顶点的偏移量。 -
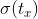 :anchor框的中心点相对于单元格左顶点的偏移量;
:anchor框的中心点相对于单元格左顶点的偏移量; -
sigmoid函数原因:将偏移量tx和ty通过sigmoid函数缩放到(0,1)范围,即
。是为了使anchor框始终在单元格内,防止偏移距离太远(如果没有sigmoid函数,tx大于1时anchor框就会偏移出当前单元格)。 - Cx、Cy:分别为当前单元格cell左顶点距离feature map的x轴距离和y轴距离;
- Pw、Ph:默认anchor框的宽度和高度值(这些值应该都是指在feature map上的坐标位置,最后再乘以比例缩放到原图);
- bx,by,bw,bh:默认anchor框经过回归矫正之后的位置;
- 边框回归计算公式:
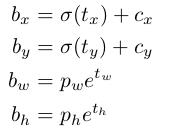
yolo v3创新点
-
1. 性能更强的新网络结构:DarkNet-53
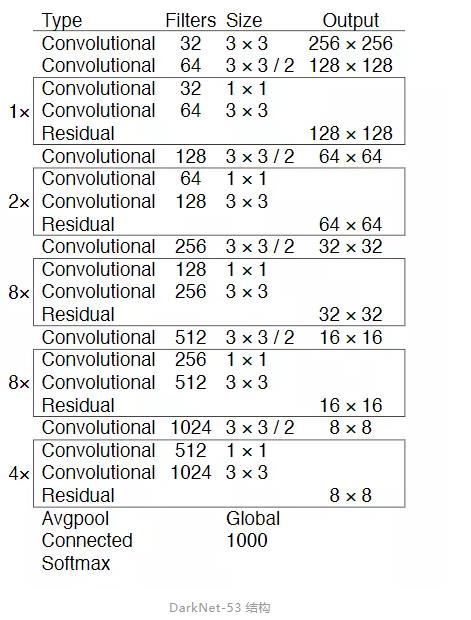
DarkNet-53 结构
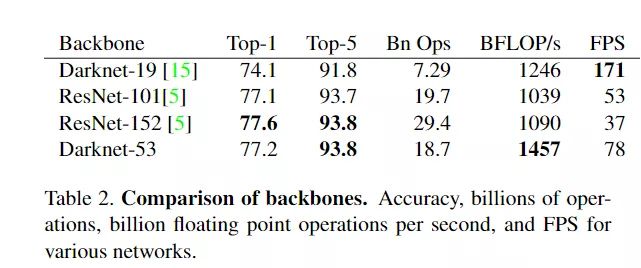
将 256x256 的图片分别输入以 Darknet-19,ResNet-101,ResNet-152 和 Darknet-53 为基础网络的分类模型中,实验得到的结果如下图所示。可以看到 Darknet-53 比 ResNet-101 的性能更好,而且速度是其 1.5 倍,Darknet-53 与 ResNet-152 性能相似但速度几乎是其 2 倍。注意到,Darknet-53 相比于其它网络结构实现了每秒最高的浮点计算量,说明其网络结构能更好的利用 GPU。
-
2. FPN.利用多尺度特征进行对象检测
YOLOv3 借鉴了 FPN 的思想,从不同尺度提取特征。相比 YOLOv2,YOLOv3 提取最后 3 层特征图,不仅在每个特征图上分别独立做预测,同时通过将小特征图上采样到与大的特征图相同大小,然后与大的特征图拼接做进一步预测。用维度聚类的思想聚类出 9 种尺度的 anchor box,将 9 种尺度的 anchor box 均匀的分配给 3 种尺度的特征图 .
-
3. 用逻辑回归Logistic替代 softmax 作为分类器
在实际应用场合中,一个物体有可能输入多个类别,单纯的单标签分类在实际场景中存在一定的限制。举例来说,一辆车它既可以属于 car(小汽车)类别,也可以属于 vehicle(交通工具),用单标签分类只能得到一个类别。因此在 YOLO v3 在网络结构中把原先的 softmax 层换成了逻辑回归层,从而实现把单标签分类改成多标签分类。用多个 logistic 分类器代替 softmax 并不会降低准确率,可以维持 YOLO 的检测精度不下降。
小结
YOLO3借鉴了残差网络结构,形成更深的网络层次,以及多尺度检测,提升了mAP及小物体检测效果。
mAP-50:
如果采用COCO mAP50做评估指标(不是太介意预测框的准确性的话),YOLO3的表现相当惊人,如下图所示,在精确度相当的情况下,YOLOv3的速度是其它模型的3、4倍。
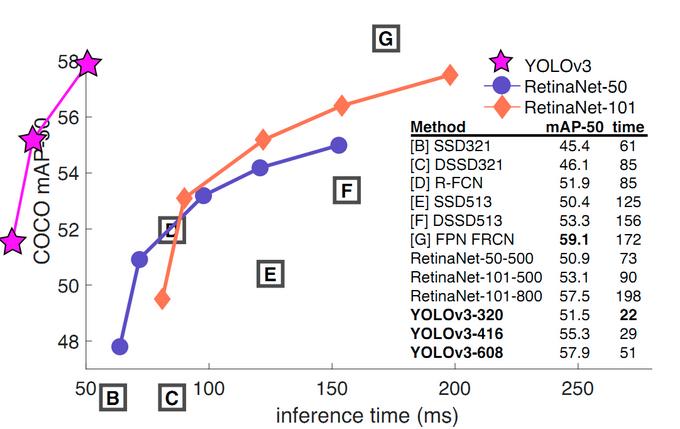
图 YOLOv3与其它模型的性能对比-mAP50
mAP:
如果要求更精准的预测边框,采用COCO AP做评估标准的话,YOLO3在精确率上的表现就弱了一些。如下图所示。
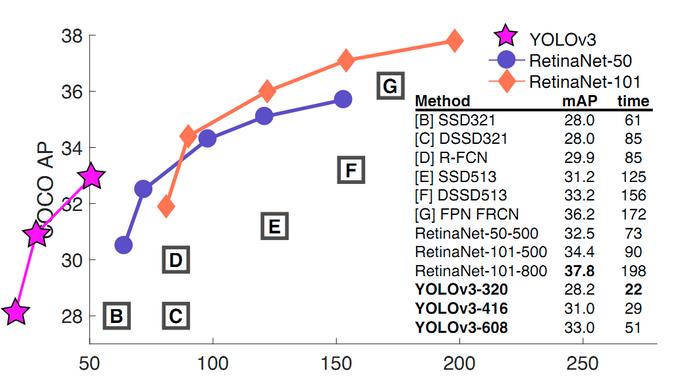
参考:
微信公众号:计算机视觉life
https://zhuanlan.zhihu.com/p/362761373
https://www.jianshu.com/p/d13ae1055302
以上是关于目标检测yolo系列-yolo v3(2018年)的主要内容,如果未能解决你的问题,请参考以下文章