压力测试 JMeter 性能监控 jvisualvm 性能调优
Posted 澄清石灰水t
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了压力测试 JMeter 性能监控 jvisualvm 性能调优相关的知识,希望对你有一定的参考价值。
1、压力测试
1.1 基本概念
压力测试考察当前软硬件环境下系统(项目)所能承受的最大负荷并帮助找出系统瓶颈所在。压测都 是为了系统(项目)在线上的处理能力和稳定性维持在一个标准范围内,做到心中有数。
使用压力测试,我们有希望找到很多种用其他测试方法更难发现的错误。有两种错误类型是: 内存泄漏,并发与同步。
有效的压力测试系统将应用以下这些关键条件:重复,并发,量级,随机变化。
1.2 性能指标
(1)响应时间(Response Time: RT)
响应时间指用户从客户端发起一个请求开始,到客户端接收到从服务器端返回的响应结束,整个过程所耗费的时间。
(2)最大响应时间(Max Response Time)
指用户发出请求或者指令到系统做出反应(响应)的最大时间。
(3)最少响应时间(Mininum ResponseTime)
指用户发出请求或者指令到系统做出反应(响应)的最少时间。
(4)90%响应时间(90% Response Time)
是指所有用户的响应时间进行排序,第 90%的响 应时间。
(5)HPS(Hits Per Second)
每秒点击次数,单位是次/秒。
(6)TPS(Transaction per Second) 吞吐量
系统每秒处理交易数,单位是笔/秒。
根据经验,一般情况下:
金融行业:1000TPS~50000TPS,不包括互联网化的活动
保险行业:100TPS~100000TPS,不包括互联网化的活动
制造行业:10TPS~5000TPS
互联网电子商务:10000TPS~1000000TPS
互联网中型网站:1000TPS~50000TPS
互联网小型网站:500TPS~10000TPS
(7)QPS(Query per Second)
系统每秒处理查询次数,单位是次/秒。
小结:TPS、QPS、HPS
对于互联网业务中,如果某些业务有且仅有一个请求连接,那么 TPS=QPS=HPS,一 般情况下用 TPS 来衡量整个业务流程,用 QPS 来衡量接口查询次数,用 HPS 来表示对服务器单击请求。
无论 TPS、QPS、HPS,此指标是衡量系统处理能力非常重要的指标,越大越好
总结:
从外部看,性能测试主要关注如下三个指标
吞吐量:每秒钟系统能够处理的请求数、任务数。
响应时间:服务处理一个请求或一个任务的耗时。
错误率:一批请求中结果出错的请求所占比例。
2、压力测试工具—JMeter
Apache JMeter是Apache组织开发的基于Java的压力测试工具。能够对HTTP和FTP服务器进行压力和性能测试, 也可以对任何数据库进行同样的测试(通过JDBC)。
2.1 JMeter安装
Apache JMeter - Download Apache JMeter
直接官网下载下来解压后,进入bin/jmeter.bat 即可运行
2.2 JMeter使用介绍 及 案例
2.2.1 使用介绍
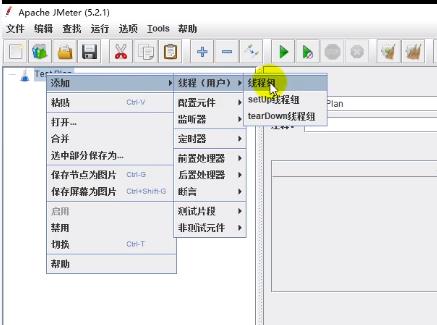
(1)添加线程组
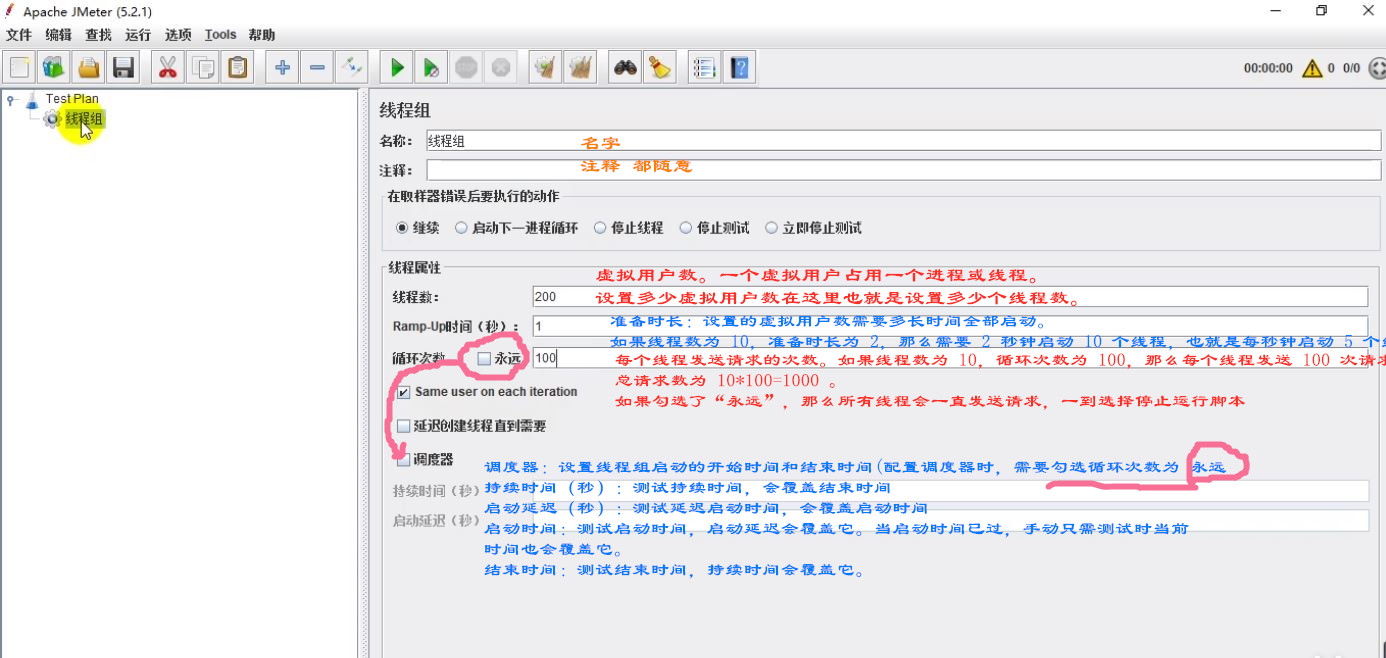
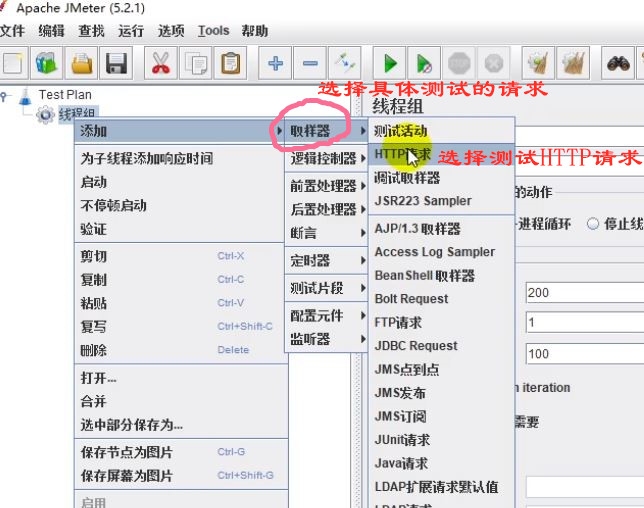
(2)选择测试HTTP请求(一般web项目,就是测这个)
(3)添加监听器
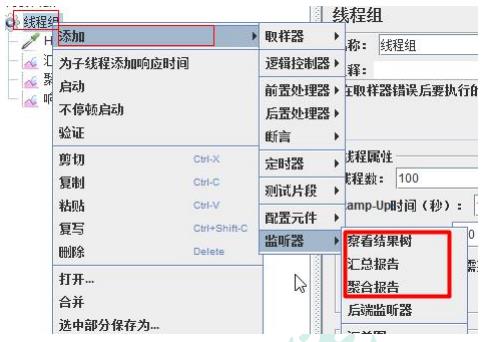
具体监听内容很难用语言描述,具体去2.2.2(3)去看测试结果
2.2.2 示例—测试百度
(1)按照前面的教程配置好 线程组 和 HTTP请求
(2)配置好线程组和HTTP请求以后,点击启动,便可开始测试
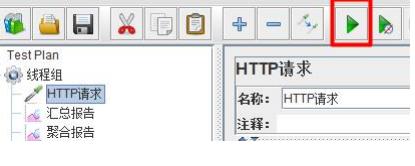
(3)查看测试结果
(3.1)查看结果树
结果树中,很容易看到各个HTTP请求的异常报告,便于快速找到异常原因
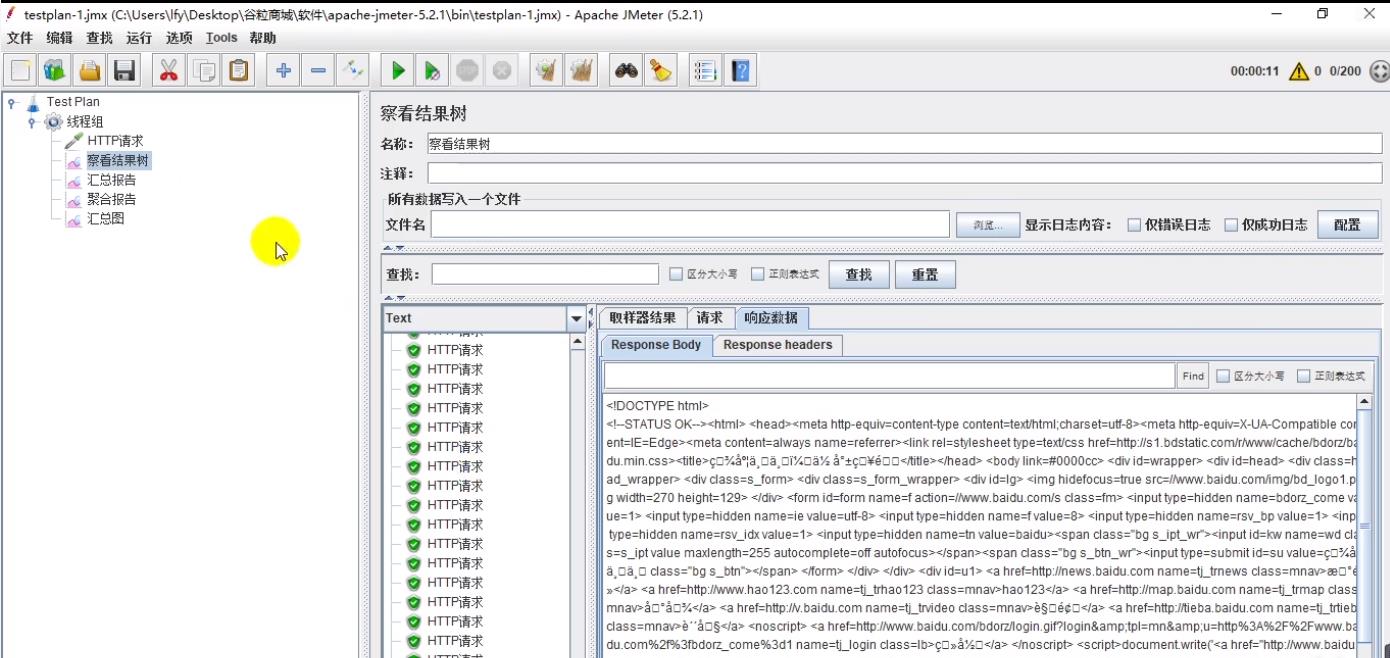
(3.2)查看汇总报告
汇总报告,可以直观看到 吞吐量,异常数(可去结果树找异常原因) 等关键指标,快速评估系统性能好坏。
(3.3)聚合报告
聚合报告,主要是用于看90%,95% 百分位,进阶评估系统性能
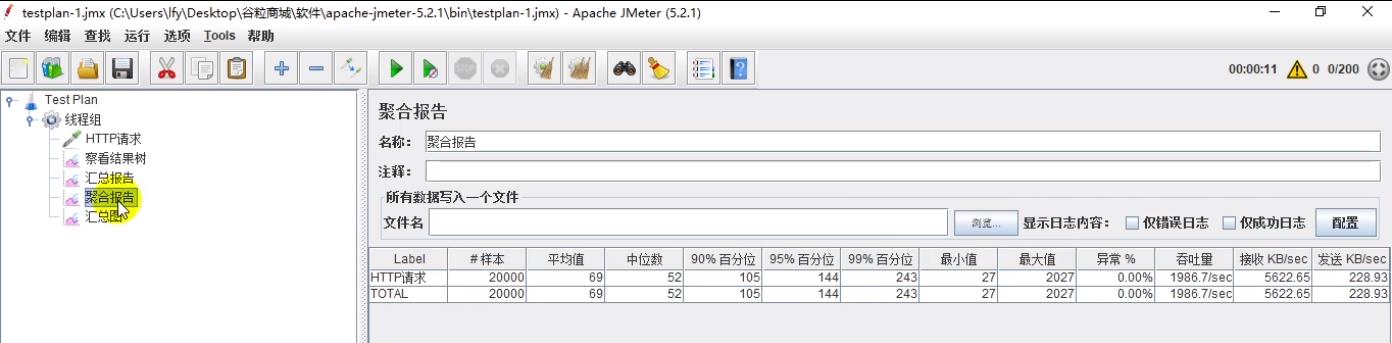
(3.4)汇总图
通过图像更直观观察系统性能
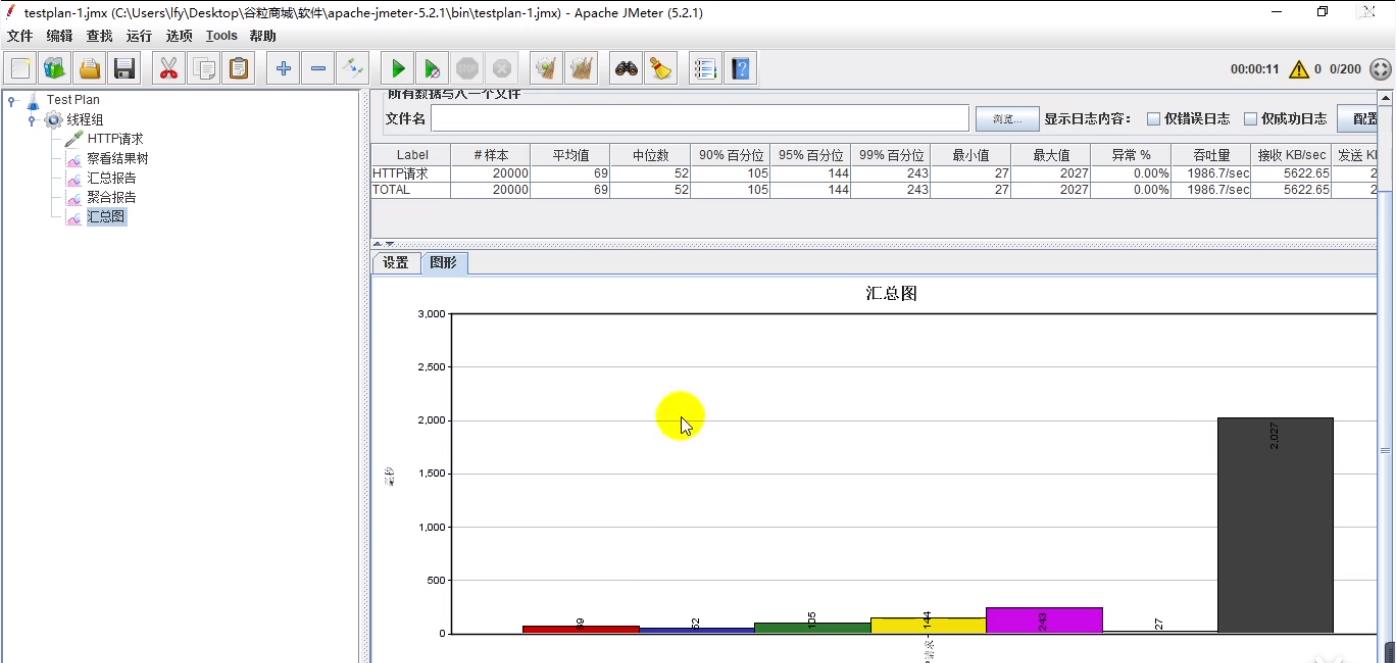
(4)结论:
百度性能简直完美啊!
2.2.3 测试自己写的接口(自然比百度性能差得多—后续会引申出调优)
(1)改HTTP请求(线程组设置不用改,所有测试项目都可以用同样的设置)
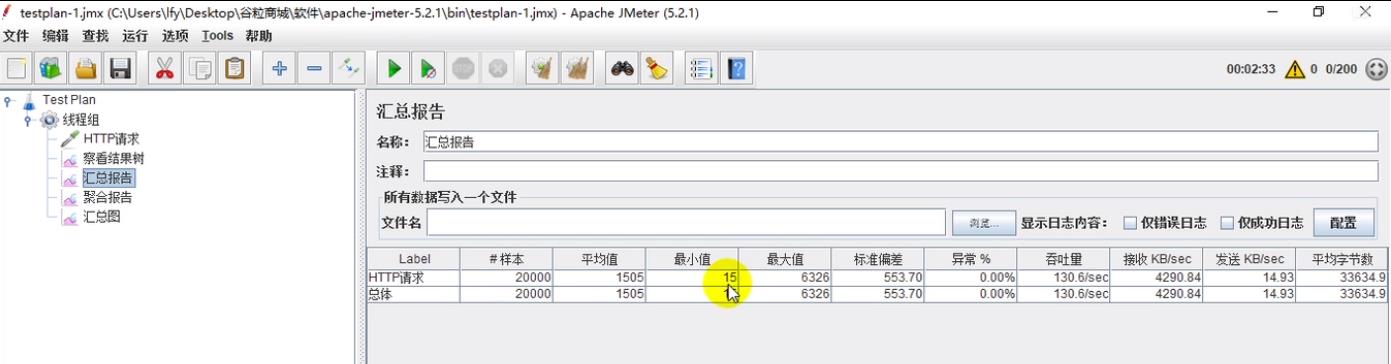
(2)查看测试结果(各项指标都不好)
(2.1)汇总报告
(2.2) 聚合报告
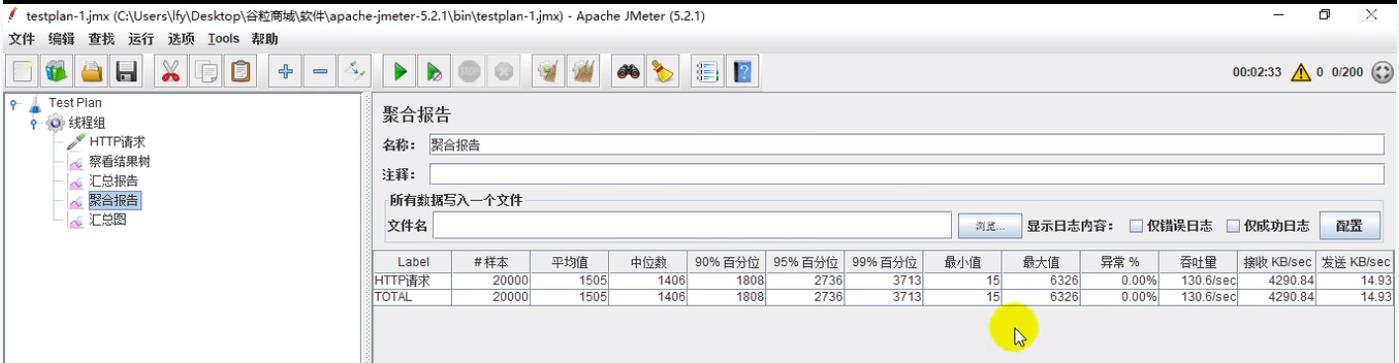
(3)结论
吞吐量等各个性能指标都比百度差太多了。
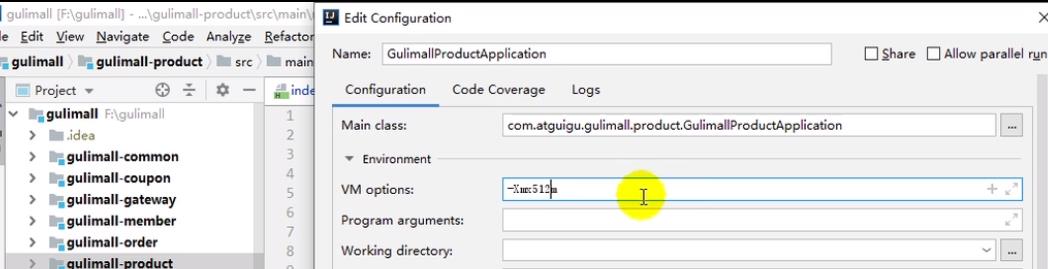
(4)简单调优
通过IDEA增大虚拟机堆内存 Xms,调高以后,明显吞吐量提高
2.4 一个windows系统引起的错误:JMeter Address Already in use
2.4.1 错误现象
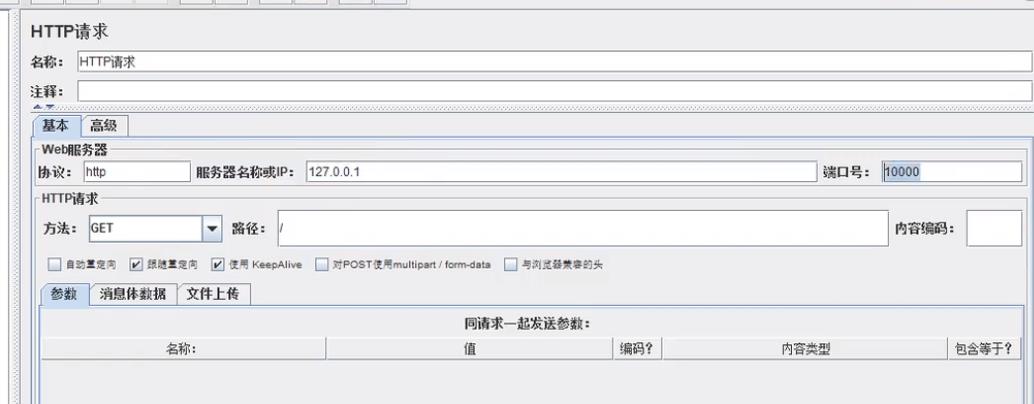
如果测试本机的某个服务并且设置的压力太大,就会发生JMeter Address Already in use 异常
比如:在线程组设置了10000个线程来压 127.0.0.1的10000端口
随后出现JMeter Address Already in use异常
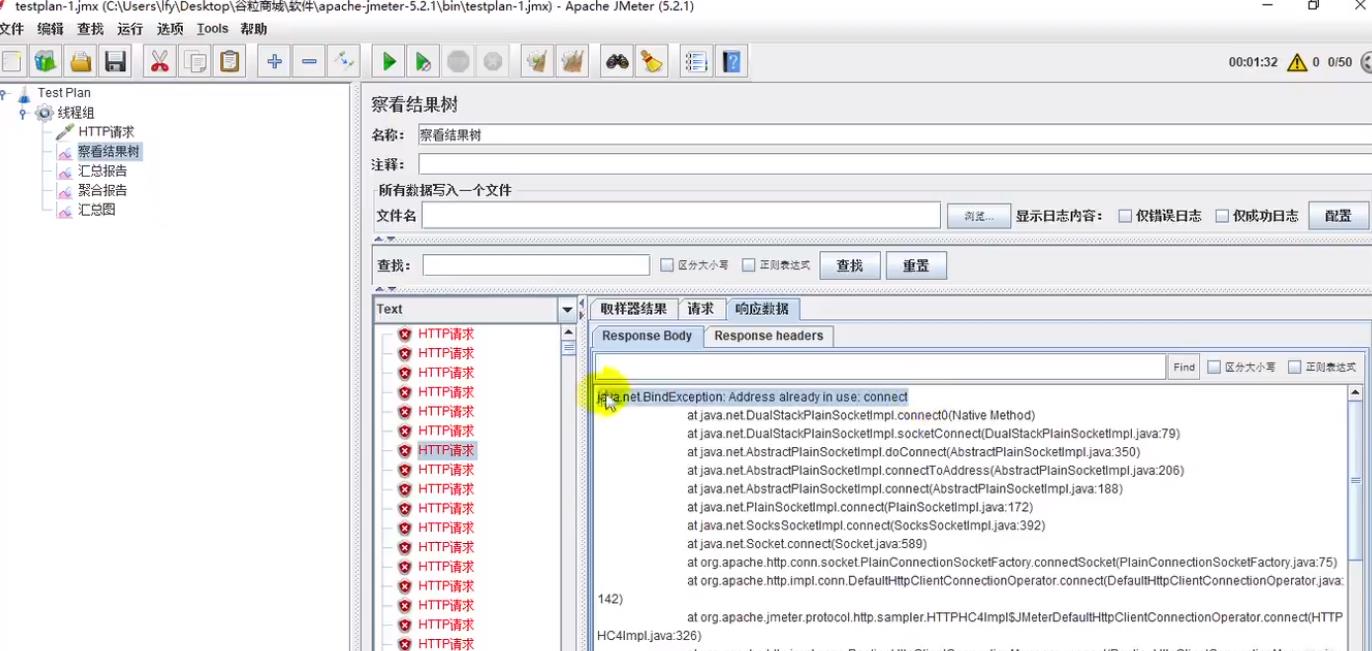
2.4.2 错误原因分析
Jmeter模拟并发请求,会使用一个端口来建立连接,windows默认只给了5000个,并且4分钟回收一次,10000个线程打过来,一会就饱和了,就没端口可用,自然就会爆出JMeter Address Already in use异常
2.4.3 解决办法
因此解决办法就是增大临时端口,并且缩短回收时间
(1)增大临时端口
进入注册表,按照下图方式调整。一下子就多了几万个端口,给Jmeter临时用。
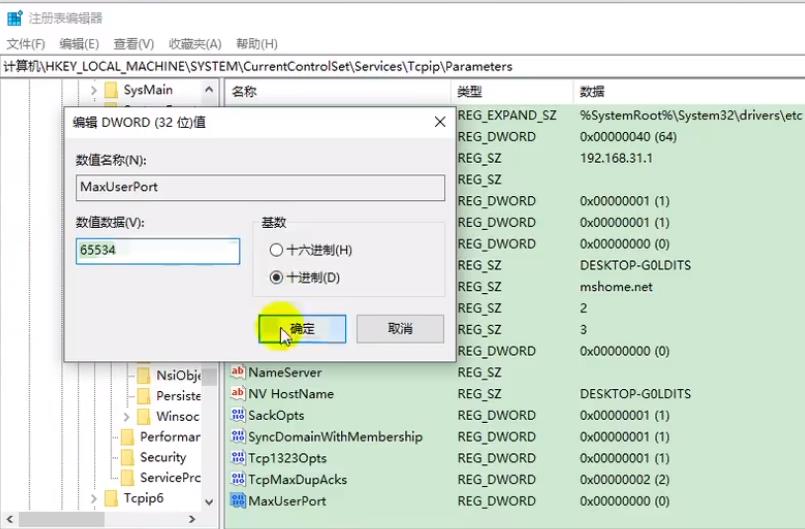
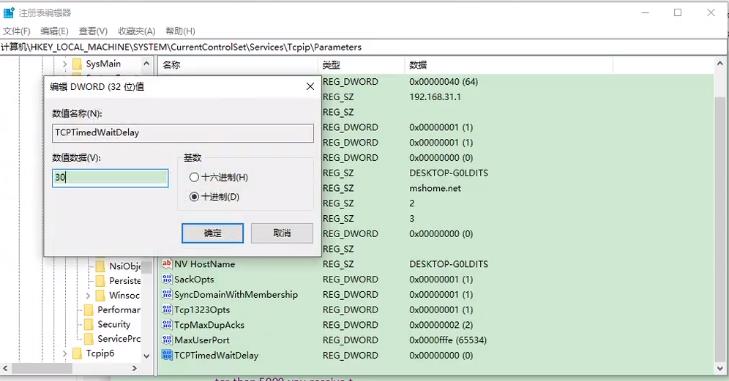
(2)缩短回收时间
还是通过注册表修改,默认4分钟回收一次端口,改成30s回收一次端口,自然这个效率大大提高
3、性能监控
就理解成windows中的任务管理器打开,然后监控cpu、内存,gpu,磁盘读写等性能参数
在普通web项目中(跟业务逻辑相关,跟图像无关的项目),最关注的就是cpu占用率,和IO性能(内存读写,和磁盘读写)
3.1 jdk自带性能监控工具—jvisualvm(用于监控自己写的代码性能)
可监控本地和远程应用(远程应用需要配置,一般不用),主要用于监控内存泄露,跟踪垃圾回收,执行时内存、cpu 分析,线程分析

运行:正在运行的
休眠:sleep
等待:wait
驻留:线程池里面的空闲线程
监视:阻塞的线程,正在等待锁
3.1.1 启动jvisualvm并添加功能插件
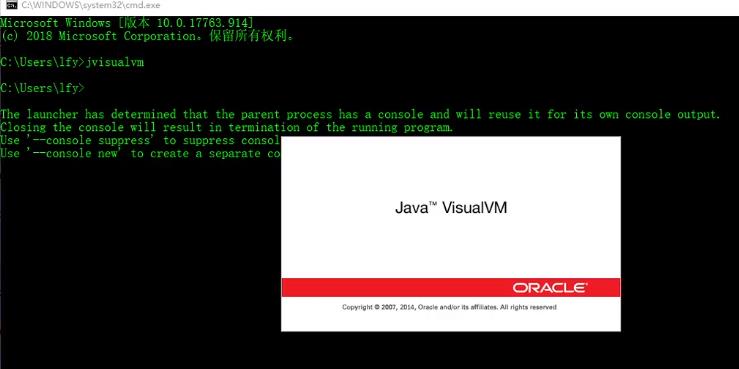
(1)启动
由于是jdk自带的,因此可以直接通过命令行启动
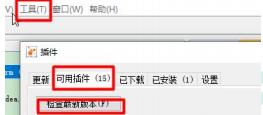
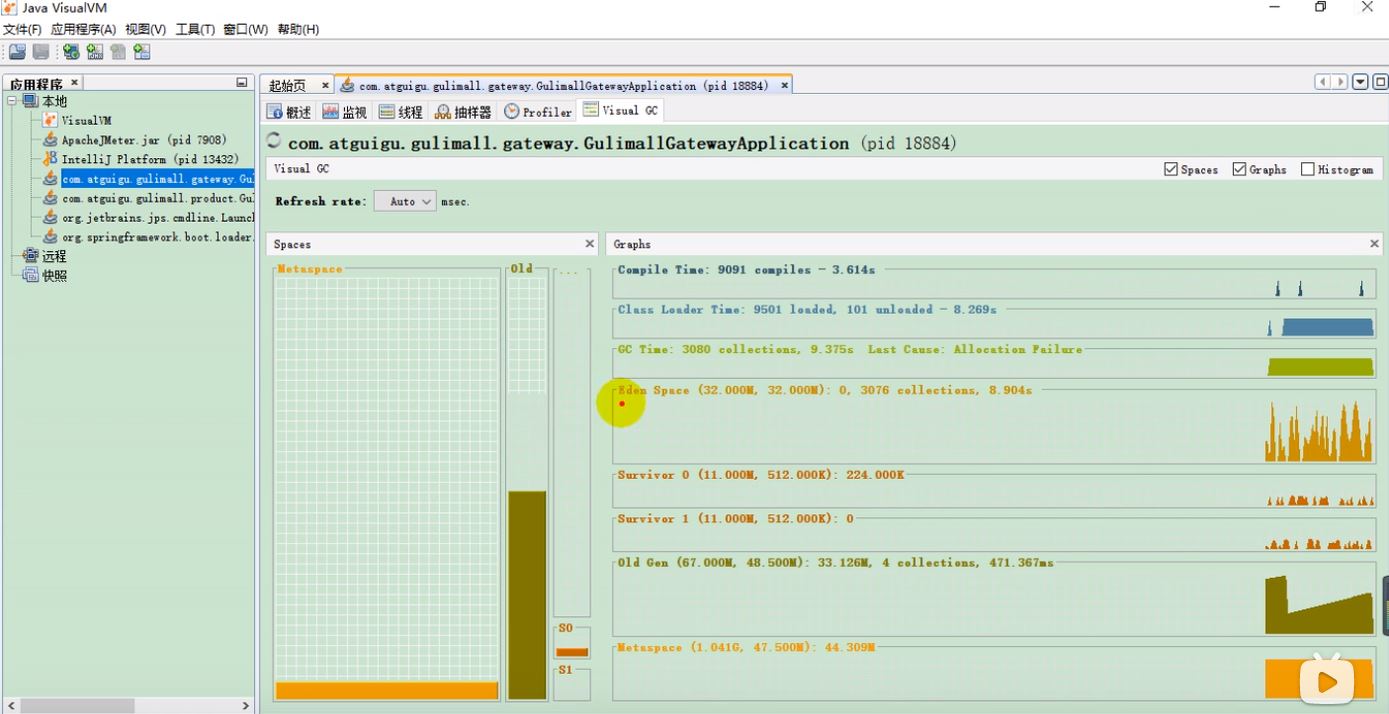
(2)安装加强插件Visual GC
点击工具—>插件
注意:有可能会遇到503错误,如果报错的话,是由于镜像地址出了问题,修改镜像地址的办法:
Step1:找到正确镜像链接:
打开网址:https://visualvm.github.io/pluginscenters.html
找到自己jdk版本对应的链接
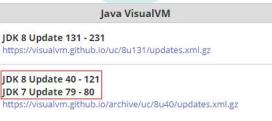
Step2:复制对应的链接
重新设置进jvisualvm
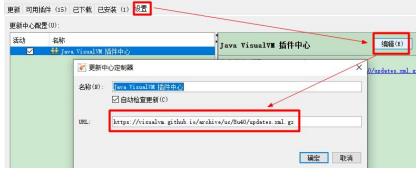
修改好镜像后,再重新安装Visual GC 即可
3.1.2 示例—监控自己写的网关(cpu和IO)
(1)Step1:用100个线程去压测自己写的网关
(2)通过jvisualvm 的 GC 可以直观看到CPU 以及 IO情况
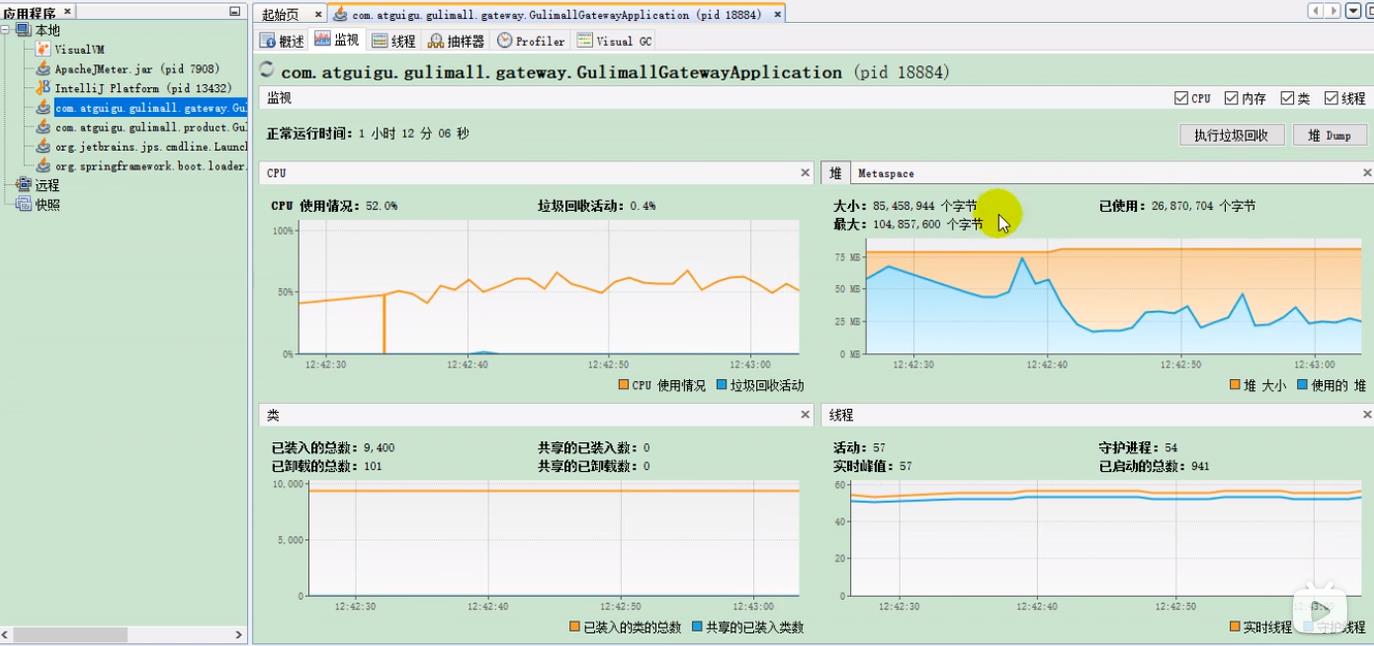
可以看到也是费cpu,不怎么费内存
3.2 Docker性能测试工具(用于监控容器中的应用性能)
由于springcloud项目,会使用很多第三方工具,比如nginx,mysql,nacos,redis等等,这些第三方工具一般放在linux服务器的docker中,如何监控这些工具的性能(主要针对CPU和IO),就需要使用Docker自带的方法。
命令:docker stats
说明:如果对docker不够了解,可先快速学习docker:https://blog.csdn.net/chengqingshihuishui/article/details/119192809
3.1.1 演示:测试nginx性能
(1)首先:用压力测试软件JMETER,配置好100个线程,去压测nginx
监控nginx性能, 访问根路径即可
(2)查看nginx性能
通过cmd,进入docker
然后 docker stats
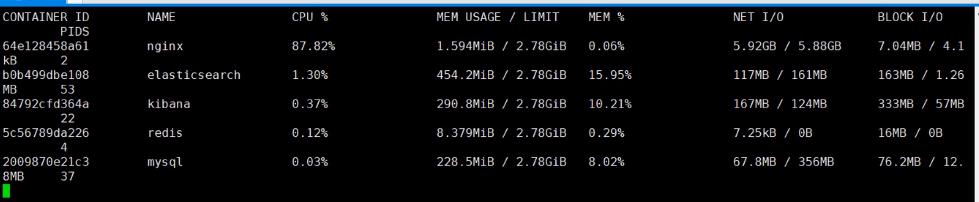
通过docker自带监控装置看到nginx某些指标,显然,nginx比较费cpu
3.3 监控应用
3.3.1 小案例引入
假设:已经完成了一个项目,项目架构如下:
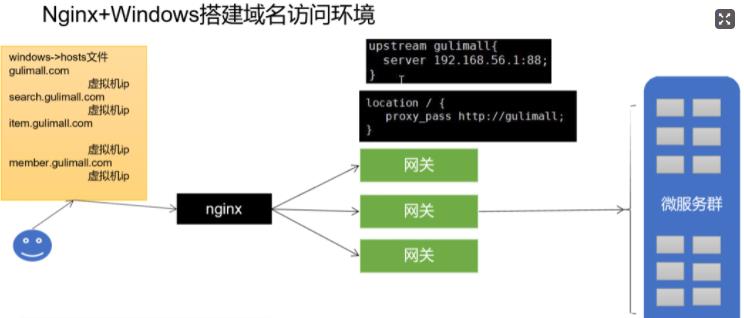
- 我们分别用JVM压测以下项目:
(1)直接压测Nginx
(2)直接压测GateWay
(3)直接压测某个简单微服务(比如就return一个 hello)
(4)直接压测首页index(首页会去微服务拿到数据后再渲染)
(5)压测调优后首页(开启thymeleaf 缓存)
(6)压测进一步调优后首页(开缓存,优化服务端数据库,降低打印日志级别)
(7)压测微服务三级分类获取
(8)压测微服务优化后三级分类获取(调优mysql)
(9)压测微服务进一步优化后三级分类获取(再加redis缓存)
(10)首页全量数据获取:包括各种静态资源(css,和图片)
(11)压测 Nginx+Gateway
(12)压测GateWay+简单服务
(13)压测全链路(nginx+gateway+微服务)
- 压测结果如下:
| 压测内容 | 压测线程数 | 吞吐量/s | 90%响应时间 | 99%响应时间 |
| Nginx | 50 | 2335 | 11 | 944 |
| Gateway | 50 | 10367 | 8 | 31 |
| 简单服务 | 50 | 11341 | 8 | 17 |
| 首页一级菜单渲染 | 50 | 270(db,thymeleaf) | 267 | 365 |
| 首页渲染(开缓存) | 50 | 290 | 251 | 365 |
| 首页渲染(开缓存、 优化数据库、关日志、JVM内存优化) | 50 | 700 | 105 | 183 |
| 三级分类数据获取 | 50 | 2(db)/8(加索引) | 太久了 | 太久了 |
| 三级分类(优化业务) | 50 | 111 | 571 | 896 |
| 三级分类(使用redis作为缓存) | 50 | 411 | 153 | 217 |
| 首页全量数据获取 | 50 | 7(静态资源) | ||
| Nginx+Gateway | 50 | |||
| Gateway+简单服务 | 50 | 3126 | 30 | 125 |
| 全链路(nginx+gateway+微服务) | 50 | 800 | 88 | 310 |
3.3.2 结论与优化方向(重点)
(1)中间件越多,性能损失越大,大多损失在网络交互了
直接压测微服务效率最高,但是加入nginx,GateWay以后效率大大降低
(2)数据库优化的越好,性能越好。尽量一次查询好需要的数据,避免多次查询。
优化方向:一次从数据库查询所有有用数据,避免多次查询数据库,同时,数据库频繁查询字段加索引
(3)和数据库交互越少,性能越好
如果每次都要从数据库去取数据,就算数据库优化到极致,也会损失很多性能,想不去数据库取数据,就得把这些数据放入缓存,下次模板直接从缓存中取数据
优化方向:加缓存挡在数据库前面,对于用户请求的数据,先从缓存中找,缓存没有再查数据库。如何使用缓存,请查看本链接
(4)首页渲染情况
jvisualvm监控到伊甸园区内存频繁gc,把伊甸园区内存调大,效率明显提高
优化方向:JVM内存调优(后文就会讲)
(5)如果不访问首页的静态资源(图片、css等),性能越好
首页的静态资源,如果也要通过请求微服务来获取,速度就太慢了。因此可以将静态资源放入nginx,静态资源直接从nginx访问,去掉中间环节。可以大大提高性能。
优化方向:Nginx动静分离(本链接文章Nginx的第9章)
4、JVM调优内存调优
JVM调优应该很复杂,这里的JVM调优,只是简单的JVM内存调优
4.1 jvm内存模型
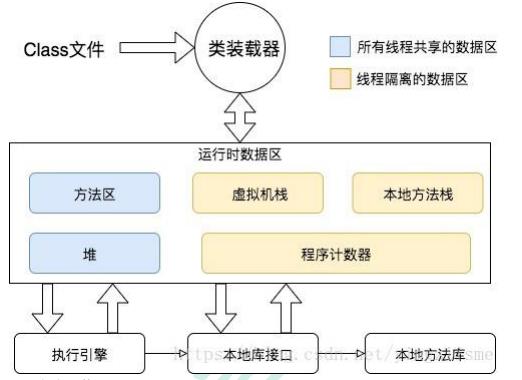
黄色部分是每个线程自己独立拥有的。
蓝色部分是线程共享的。
- 本案例涉及的内存调优,主要是在堆Heap上干活,因此本文重点讲堆。
4.2 堆
4.2.1 堆简介
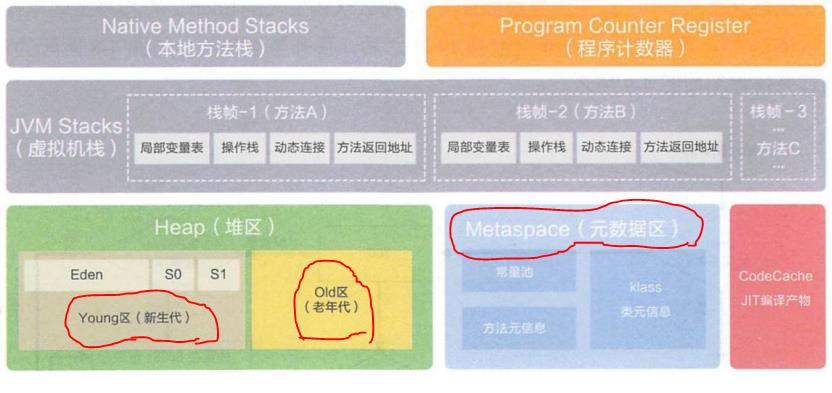 所有的对象实例以及数组都要在堆上分配。堆是垃圾收集器管理的主要区域,也被称为“GC 堆”;也是我们优化最多考虑的地方。 堆可以细分为
所有的对象实例以及数组都要在堆上分配。堆是垃圾收集器管理的主要区域,也被称为“GC 堆”;也是我们优化最多考虑的地方。 堆可以细分为
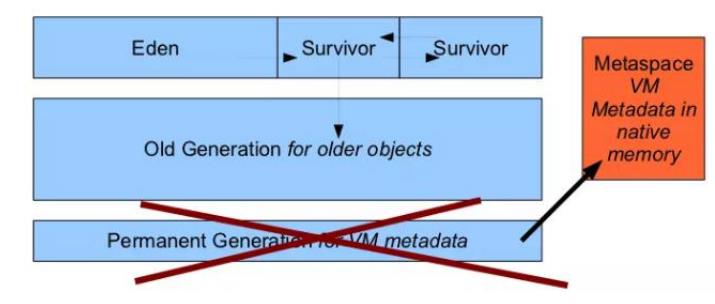
(1)新生代
伊甸园空间(Eden空间)、幸存者空间(From Survivor)、幸存者空间(To Survivor)
(2)老年代
(3)永久代/元空间
Java8 以前永久代,受 jvm 管理,java8 以后元空间,直接使用物理内存。因此, 默认情况下,元空间的大小仅受本地内存限制。
4.2.2 垃圾回收机制(GC)
当对系统进行压力测试的时候,随着访问的线程越来越多(新对象越来越多),内存就会占用会越来越多,总有内存占满的时候,此时jvm就会进行垃圾回收(GC),垃圾回收过程中,一方面给新对象找位置,另一方面会对旧的还有用的类对象进行移动。
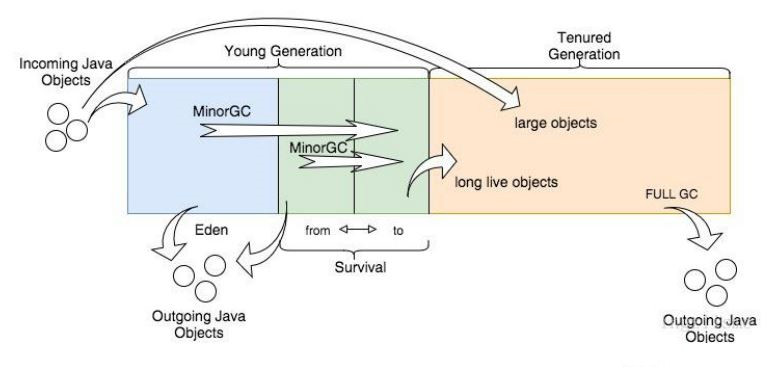
类新建的对象,先放在伊甸园区(Eden),如果伊甸园区放得下,就直接分配内存,放不下,就做一次YGC(简单内存回收,耗费资源少,速度快)... ... 具体过程见如下流程图:
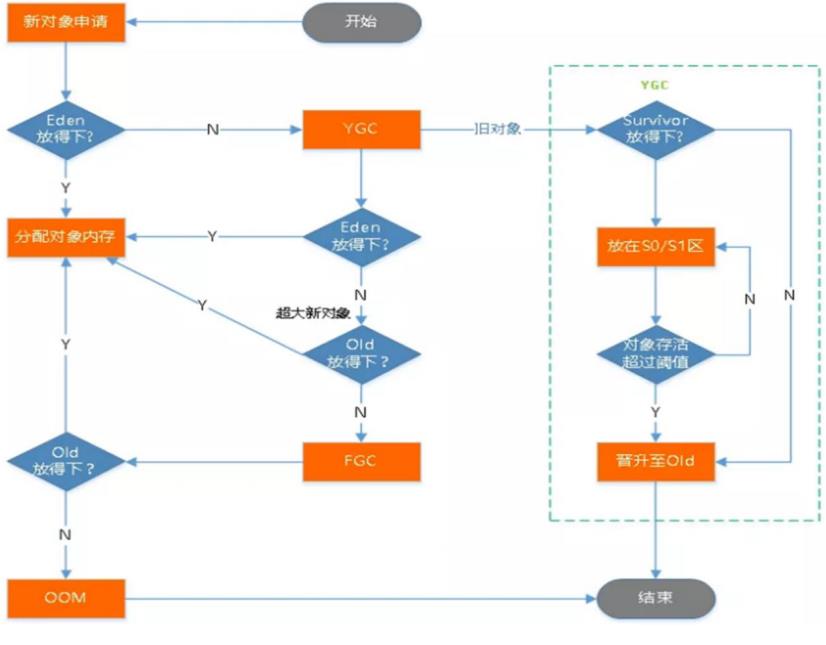
- 特别说明:
(1)YGC:简易垃圾回收,耗费资源少,速度快,但YGC太频繁也会影响系统效率。YGC过程见上图虚线框中。
(2)FGC:全面垃圾回收,耗费资源大,非常影响系统性能。尽量避免频繁FGC
(3)从 Java8 开始,HotSpot 已经完全将永久代(Permanent Generation)移除,取而代之的是一 个新的区域—元空间(MetaSpace)
4.3 重点监控指标参考
4.3.1 系统常用中间件指标
系统常用中间件包括Tomcat(每个微服务就是一个Tomcat)等指标主要包括JVM,ThreadPool(线程池),JDBC等,具体性能指标如下:(只关注GC就是了,其他太麻烦)
| 一级指标 | 二级指标 | 单位 | 解释 |
| GC(本节重点) | GC频率 | 每秒多少次 | java虚拟机垃圾部分回收频率 |
| Full GC频率 | 每小时多少次 | java虚拟机垃圾完全回收频率 | |
| Full GC平均时长 | 秒 | 用于垃圾完全回收的平均时长 | |
| Full GC最大时长 | 秒 | 用于垃圾完全回收的最大时长 | |
| 堆使用率 | 百分比 | 堆使用率 | |
| ThreadPool | Active Thread Count | 个 | 活动的线程数 |
| PendingUser Request | 个 | 处于排队的用户请求个数 | |
| JDBC | JDBC Active Connection | 个 | JDBC活动连接数 |
(1)GC(重点):GC频率不能频繁,特别是 FULL GC 更不能频繁,一般情况下系统性能较好的情况下, JVM 最小堆大小和最大堆大小分别设置 1024M 比较合,设置方法见第五章调优部分。
(2)ThreadPool:当前正在运行的线程数不能超过设定的最大值。一般情况下系统性能较好的情况下,线 程数最小值设置 50 和最大值设置 200 比较合适。
(3)JDBC:当前运行的 JDBC 连接数不能超过设定的最大值。一般情况下系统性能较好的情况下, JDBC 最小值设置 50 和最大值设置 200 比较合适。
4.3.2 数据库指标
常用的数据库例如MySQL指标主要包括SQL、吞吐量、缓存命中率、连接数等,具体如下:
| 一级指标 | 二级指标 | 单位 | 解释 |
| SQL | 耗时 | 微秒 | 执行SQL耗时 |
| 吞吐量 | QPS | 个 | 每秒查询次数 |
| TPS | 个 | 每秒事务次数 | |
| 命中率 | KeyBuffer命中率 | 百分比 | 索引缓冲区命中率 |
| InnoDB Buffer命中率 | 百分比 | InnoDB缓冲区命中率 | |
| QueryCache命中率 | 百分比 | 查询缓存命中率 | |
| TableCache命中率 | 百分比 | 表缓存命中率 | |
| ThreadCache命中率 | 百分比 | 线程缓存命中率 | |
| ThreadPool | Active Thread Count | 个 | 活动的线程数 |
| PendingUser Request | 个 | 处于排队的用户请求个数 |
(1) SQL 耗时越小越好,一般情况下微秒级别。
(2)命中率越高越好,一般情况下不能低于 95%。
(3)锁等待次数越低越好,等待时间越短越好。
5、JVM内存调优(更合理分配内存)
关于项目的业务代码优化方向,在前文3.3.2中已经写得很明确了,可以分别通过nginx实现动静分离,mysql关键查询字段加索引,给数据库前面挡一个Redis缓存等来优化业务,详情可以回去查3.3.2
本节主要写JVM内存分配来调优的方法。
5.1 IDEA设置JVM虚拟内存—Xmx、Xms、Xmn
5.1.1 Xmx、Xms、Xmn
Xmn、Xms、Xmx、Xss 都是JVM对内存的配置参数,我们可以根据不同需要区修改这些参数,以达到运行程序的最好效果。
-Xms 堆内存的初始大小,默认为物理内存的1/64
-Xmx 堆内存的最大大小,默认为物理内存的1/4
-Xmn 堆内新生代的大小。通过这个值也可以得到老生代的大小:-Xmx减去-Xmn
-Xss(先不管) 设置每个线程可使用的内存大小,即栈的大小。在相同物理内存下,减小这个值能生成更多的线程,当然操作系统对一个进程内的线程数还是有限制的,不能无限生成。线程栈的大小是个双刃剑,如果设置过小,可能会出现栈溢出,特别是在该线程内有递归、大的循环时出现溢出的可能性更大,如果该值设置过大,就有影响到创建栈的数量,如果是多线程的应用,就会出现内存溢出的错误。
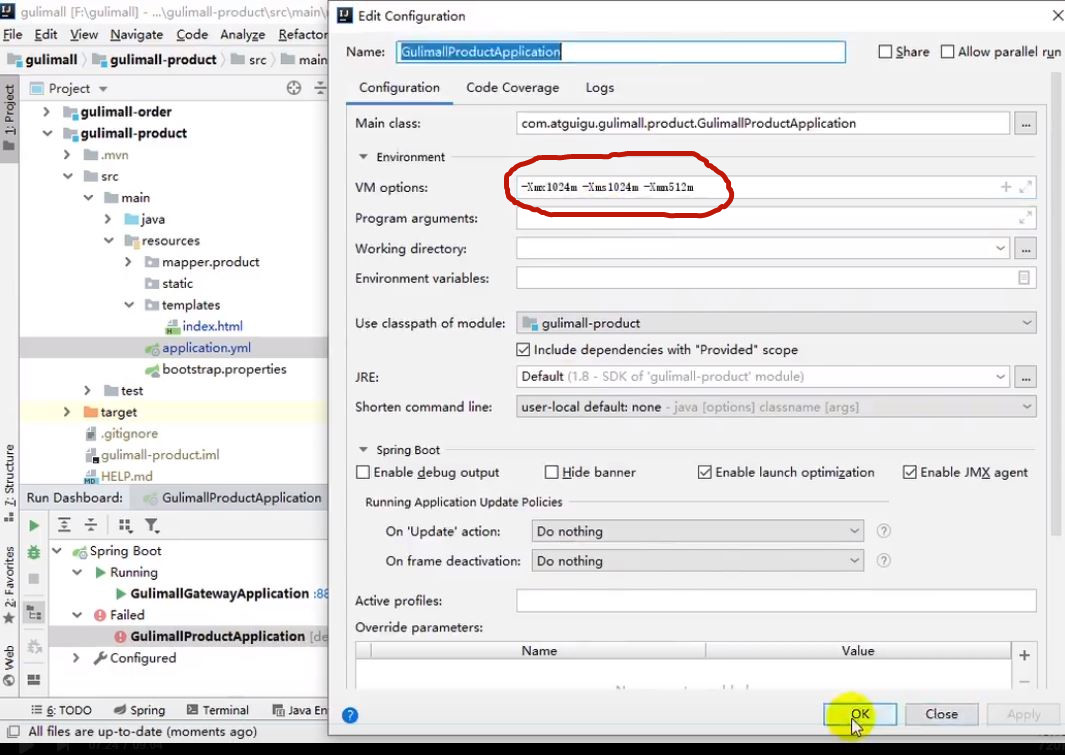
5.1.2 IDEA中设置Xmx、Xms、Xmn
进入微服务的 Configuration(如下图所示),在红圈处设置各项JVM内存
5.2 调优案例—任意网站首页内存调优
5.2.1 调优前——JMETER压力测试
为了演示调优效果,假设情况稍微极端一点,假装首页所在的微服务Xms只分配了100m
(1)根据2.2节内容,用JMETER进行压力测试,50个线程访问该项目首页。
(2)根据3.1.1用jvisualvm监控性能
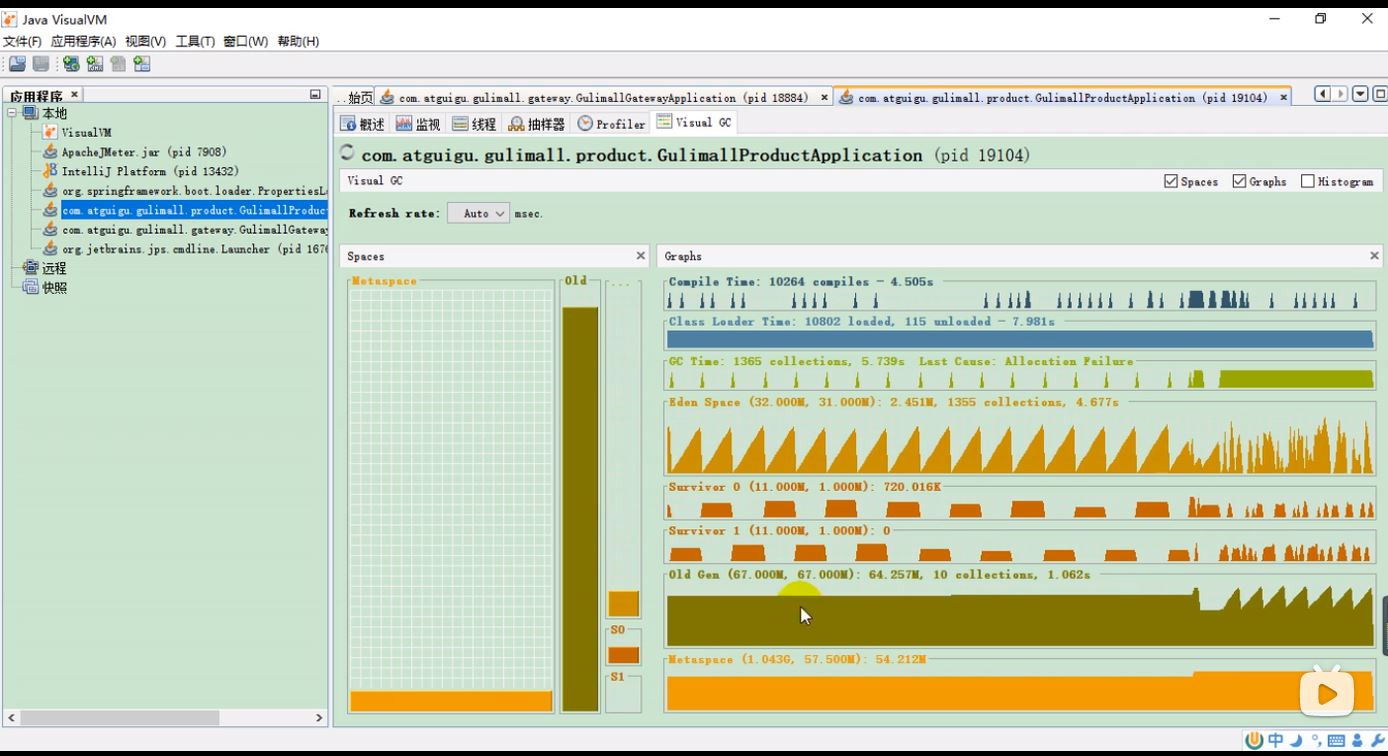
如图可见:堆内存太小,导致频繁GC,最终内存溢出
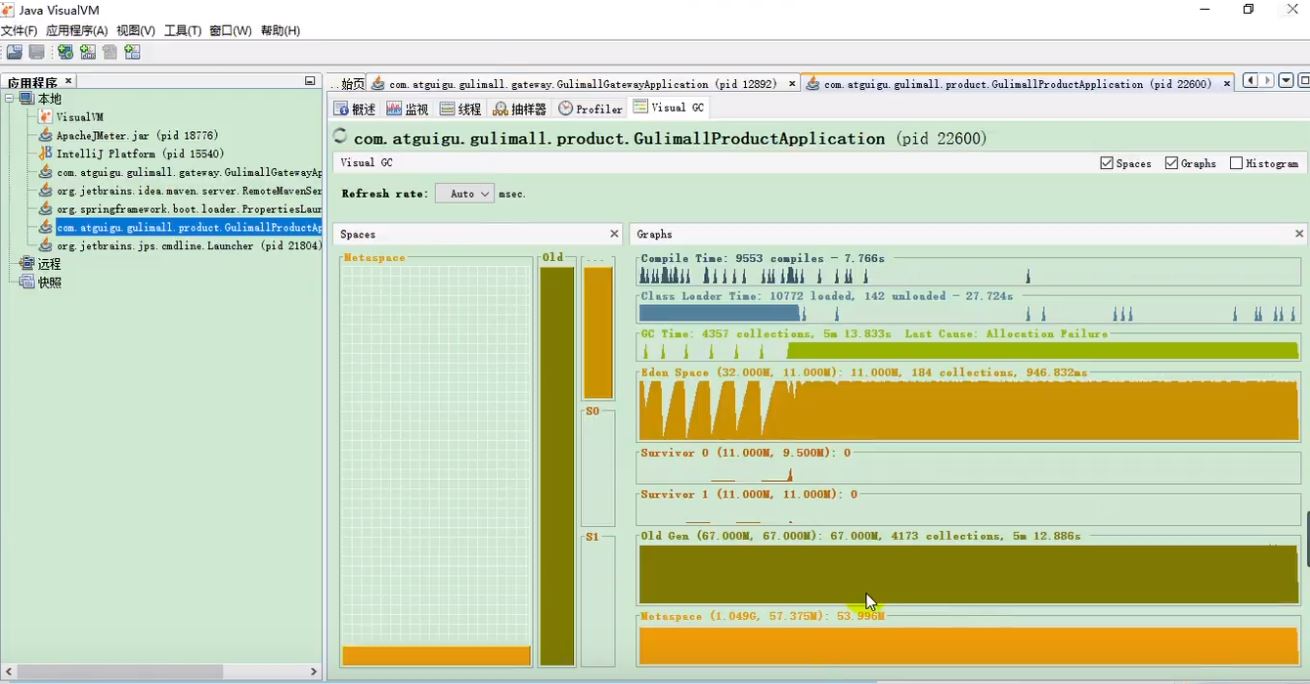
5.2.2 调优后JVM内存情况
(1)按照4.3.1 GC指标,将Xmx,Xms,Xmn分别调整为1024m,1024m,512m
(2)再次用jvisualvm监控性能
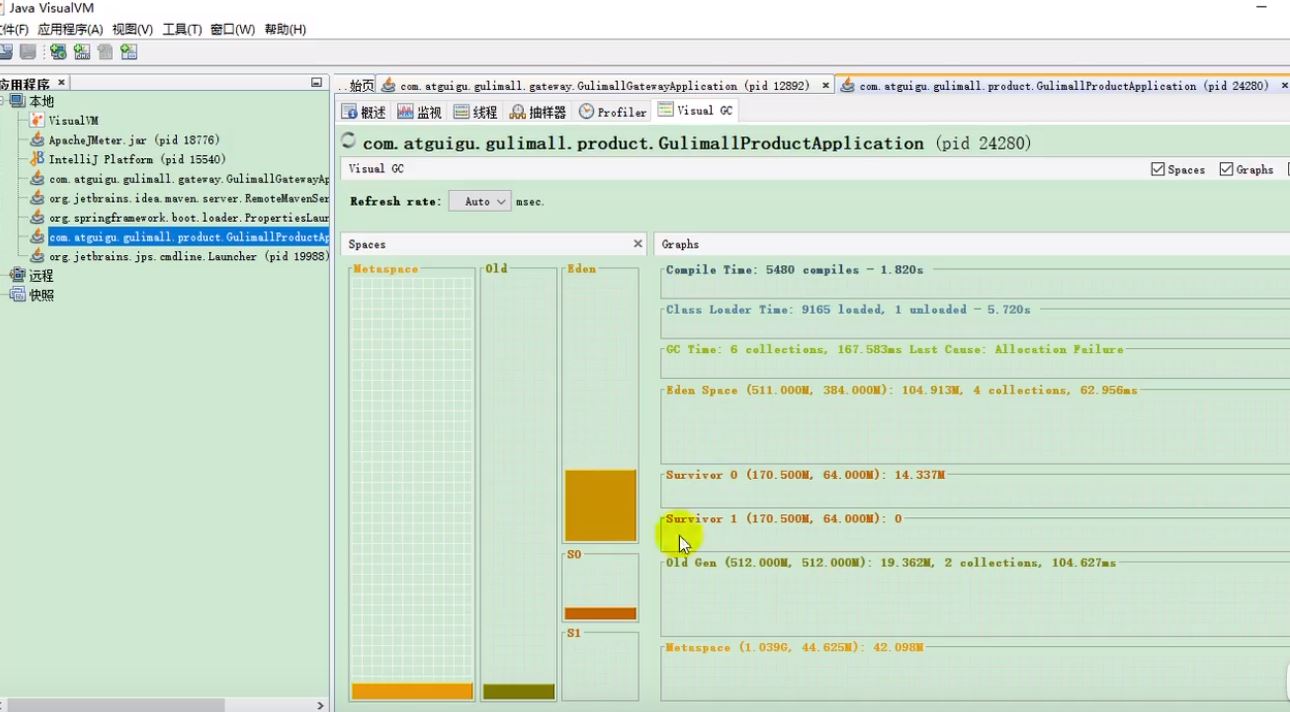
4.3.1表格中的各项GC指标(GC频率,GC时长,堆使用率)都明显好转。
以上是关于压力测试 JMeter 性能监控 jvisualvm 性能调优的主要内容,如果未能解决你的问题,请参考以下文章
(十九)从零开始搭建k8s集群——使用KubeSphere管理平台搭建一套微服务的压力测试性能监控平台(Grafana8.5.2+influxdb2.2.0+Jmeter5.4.1)