Java中的并发计数器LongAdder
Posted 攻城狮Chova
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Java中的并发计数器LongAdder相关的知识,希望对你有一定的参考价值。
并发计数器LongAdder
基本概念
- 位于java.util.concurrent.atomic包.是高并发下计数功能最好的数据结构,低并发下效率也非常高
- LongAdder和DoubleAdder数据结构类似
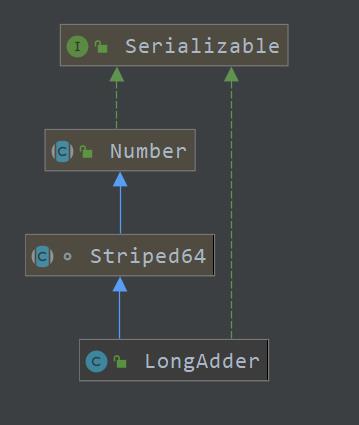
- LongAdder继承Striped64类,实现累加功能
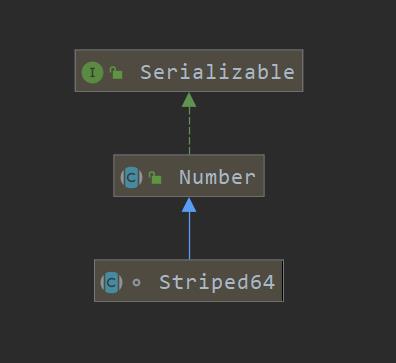
Striped64
- Striped64是一个高并发累加的工具类
- Striped64设计的核心思路: 通过内部的分散计算来实现避免竞争
- Striped64中包含一个base和一个cells数组
- 在没有竞争的情况下,累加的数通过CAS累加到base上
- 在竞争的情况下,累加的数累加到数组cells中的某个cell元素上
- 这样整个Striped64的值为: s u m = b a s e + ∑ 0 n c e l l sum=base+\\sum_0^ncell sum=base+∑0ncell
Striped64重要成员变量
- Striped64中有三个重要的成员变量
/**
* 存放元素cell的Hash表,大小为2的整数次幂
*/
transient volatile Cell[] cells;
/**
* 基础值:
* - 在没有竞争的情况下,累加的数通过CAS累加到base上
* - 在数组cells初始化过程时,数组中的元素cell不可用。此时累加的数会尝试通过CAS累加到base上
*/
transient volatile long base;
/**
* 自旋锁,通过CAS加锁
* 用于创建和扩容数组cells的Hash表
*/
transient volatile int cellsBusy;
cells
- 数组cells是LongAdder实现高性能的关键
- 在AtomicLong中只有一个计数的值value, 所有线程的累加操作都要通过CAS锁竞争变量value来实现累加,处于高并发情况下,线程的竞争非常高
- LongAdder中有两个计数的值:
- base:
- 在没有竞争或者初始化的情况下使用
- 作用和AtomicLong中的value变量类似
- cells:
- 在没有竞争的情况下,不会使用cells数组,值为null
- 在竞争的情况下,就使用到cells数组:
- 初始化时长度为2
- 每次扩容长度都增加1倍,长度变为原来的2倍
- 直到数组cells的长度大于等于当前服务器CPU的数量就不再扩容
- 每个线程通过对cells[threadLocalRandomProbe%cells.length] 位置上的cell元素中的value值做累加,这样相当于将线程绑定到数组cells中的某个cell元素对象上
- base:
cellsBusy
- cellsBusy是自旋锁,通过CAS加锁.用于创建和扩展数组cells的Hash表
- cellsBusy的值包括无锁0和加锁1, 作用是修改数组cells时进行加锁,防止多线程同时修改cells数组
- cellsBusy加锁的情况有三种:
- 数组cells初始化
- 数组cells扩容
- 数组cells中某个位置的为null, 在这个位置创建新的Cell对象
base
- base主要有两个作用:
- 在没有竞争的情况下,将累加的数通过CAS累加到base上
- 在数组cells初始化过程时,数组中的元素cell不可用.此时累加的数会尝试通过CAS累加到base上
内部类Cell
- 内部类Cell的类的注解是 @jdk.internal.vm.annotation.Contended
- 内部类Cell是一个静态final类型的内部类,内部有一个value值,使用CAS来更新value的值
CPU缓存架构

- 缓存越靠近CPU, 缓存运行速度就越快,容量也越小:
- 一级缓存L1紧靠着CPU内核,只能被一个单独的CPU内核使用. 尽管容量很小,但是运行速度很快
- 二级缓存L2容量大一些运行速度也慢一些,只能被一个单独的CPU内核使用
- 三级缓存L3容量更大一些运行速度也更慢一些,可以被单个插槽上的所有CPU内核共享
- 主内存中保存着应用运行的所有数据,也是容量最大,运行速度最慢的,可以被全部插槽上的所有CPU内核共享
- CPU执行运算时,会首先从一级缓存L1中寻找数据,如果没有再去二级缓存L2中寻找数据,如果没有再去三级缓存L3中寻找数据.如果这些缓存中都没有数据,就去主内存中寻找数据
- 因为CPU执行运算,寻找数据走得越远,执行耗费的时间就越长.所以对于一些需要频繁运算的数据,需要确保在一级缓存L1中
缓存行cache line
- CPU的缓存系统是以缓存行cache line为单位存储的:
- 缓存行cache line是2的整数幂次方个连续字节.通常情况下为32~256个字节
- 常见的缓存行cache line的大小为64个字节
- 缓存行cache line是缓存cache和内存memory之间数据传输的最小单元
- Java中一个long类型的长度是8个字节,通常一个缓存行中可以存放8个long类型的变量

- 程序运行时,缓存每次更新都会从主内存中加载连续的64个字节.如果访问的是一个long类型的数组时,当数组中一个值被加载到缓存中时,同时另外7个元素的值也会被加载到缓存中
- 如果数据结构中各项的值在内存中不是连续相邻的,比如链表.就无法获得这种同时加载数据到缓存中的这种好处
- 这种同时加载存在缺点:
- 如果一个long类型的变量A, 不是数组的一部分,而是一个单独的变量.并且有另外一个long类型的变量B紧挨着这个变量,那么当这个变量A被加载到缓存中时,另一个变量B也会被加载到缓存中
- 此时如果一个CPU线程正在对这个变量A进行修改,另外一个CPU线程正在对另一个变量B进行读取
- 对这个变量A修改的CPU线程修改变量A时,会将变量A和变量B同时加载到缓存行中,修改变量A后,因为其余缓存行中的变量A已经不是最新值,所以其余所有包含变量A的缓存行都将失效
- 对另一个变量B读取的CPU线程读取变量B时,发现这个缓存行已经失效,就需要从主内存中重新加载数据到缓存行中
- CPU中的缓存都是以缓存行作为一个最小单位进行数据处理的,只要缓存行中有一个值失效,那么整个缓存行都会失效

- 由此会导致伪共享问题: 变量B和变量B两个完全不相干的变量,每次变量B都要因为变量A的更新重主内存中重新读取变量B, 这样变量B就会因为变量A造成被缓存未命中而拖慢运行速度
伪共享
- 伪共享: 当多线程中修改相互独立的变量时,如果这些变量共享同一个缓存行,就会无意中影响彼此的性能
- CPU中使用了L1 cache和L2 cache:
- L1 cache中数据处理方式是直写模式write through
- write-through: 直写模式. 数据更新时,同时写入缓存Cache和后端存储
- 优点: 操作简单
- 缺点: 数据修改后同时需要写入缓存和存储,写入的速度较慢
- write-through: 直写模式. 数据更新时,同时写入缓存Cache和后端存储
- L2 cache中数据处理方式是回写模式write back
- write-back: 回写模式. 数据更新时只写入缓存,只有在数据被替换出缓存时,修改的数据才会被写到后端存储中
- 优点: 因为不需要写存储,所以数据的写入速度很快
- 缺点: 如果更新后的数据没有被及时写入到存储中,此时系统出现异常,会导致修改后的数据无法找回
- write-back: 回写模式. 数据更新时只写入缓存,只有在数据被替换出缓存时,修改的数据才会被写到后端存储中
- L1 cache中的数据会及时写入缓存和存储中,而L2 cache中的数据只会写入缓存,而不会立即写回到内存存储中,这样就导致cache和memory中的数据不一致的情况
- 对于多处理器multiprocessors的情况,由于cache是CPU内核私有的,不同的CPU内核的cache内容也会存在不一致的问题
- 因此,在很多多处理器multiprocessor的计算机架构中,比如ccnuma和smp中,都实现了cache coherence机制,即不同的CPU内核的cache一致性机制
- cache coherence: 缓存一致性. 通过cache-snooping协议,每个CPU内核通过对总线bus的窥探snoop实现对CPU内核读写缓存cache的监控
- 某个CPU内核写缓存cache时:
- 其余的CPU会检查自身的缓存cahce中的缓存行cache line
- 如果状态为dirty(CPU更新数据,写入缓存没有写入存储), 就将数据回写到存储中,并且将写缓存cache的CPU的相关cache line刷新
- 如果状态不是dirty(CPU更新数据,写入缓存没有写入存储),就将cache line使用invalidate使得缓存行失效
- 某个CPU内核读缓存cache时:
- 其余的CPU会将自身的缓存cache中的缓存行cache line中标记为dirty(CPU更新数据,写入缓存没有写入存储)的部分的数据回写到存储中,并且将读缓存cache的CPU的相关cache line刷新
- 某个CPU内核写缓存cache时:
- 提高CPU的缓存命中率cache hit rate, 减少cache和memory之间的数据传输,将会提高系统性能
- L1 cache中数据处理方式是直写模式write through
- 在程序和二进制对象的内存分配中保持缓存行对齐cache line aligned就十分重要. 否则会出现多个CPU内核中并行运行的进程或者线程同时读写同一个缓存行cache line的情况.这时候就会导致CPU内核的cache和memory之间反复出现write back和refresh的情况,这种情况称作cache thrashing
- 避免cache thrashing有以下两种途径:
- 对于heap的分配,在malloc调用中实现了强制的对齐alignment
- 对于stack的分配,编译器提供了stack aligned的选项
- 注意: 对于在编译器中指定stack aligned, 程序的会变得臃肿,会占用更多的内存,一定要做好取舍
- CPU中使用了L1 cache和L2 cache:
- 伪共享的原理: 一个缓存行通常使用64个字节,缓存每次更新时都会从主内存中加载连续的64个字节的数据,如果访问的是一个8个字节的long类型的数组时,当数组中一个值被加载到缓存中,同时另外7个相邻的long类型的数组也会被加载到缓存中,进而引发伪共享的问题
- 避免伪共享的几种方式:
- 在两个原本相邻的不相干的long类型的变量之间添加7个额外的long类型的变量
- 自定义long类型而不是使用Java自带的long类型
- 使得自定义的long类型数据可以占满64个字节
- 通常也就是单独的long类型变量中添加7个额外的long类型的变量
- 使用@Contended注解. 推荐使用这种方式
- 如果使用这个注解无效的话,需要配置JVM启动参数后重新运行
-XX:-RestrictContended
- Java中避免伪共享的示例:
- ConcurrentHashMap
- ConcurrentHashMap中的size() 方法是使用分段的思想来构造的
- 每个段使用的类是CounterCell
- 类CounterCell上就使用了 @Contended的注解
- LongAdder
- ConcurrentHashMap
Striped64重要方法
longAccumulate
/**
* 处理涉及初始化,扩容,创建新的Cell对象和竞争的更新情况
*
* @param x 需要累加的值
* @param fn 更新函数,可以为null。用于累加操作
* @param wasUncontended 如果CAS操作在调用前执行失败则返回false。表明调用方法之前的add()方法是否没有发生争用
*/
final void longAccumulate(long x, LongBinaryOperator fn, boolean wasUncontended);
LongAdder
LongAdder重要方法
add
/**
* 对指定的值累加
*
* @param x 需要累加的值
*/
public void add(long x);
总结
hash的值生成
- hash的值: LongAdder中用来定位当前线程应该将值累加到数组cells的哪一个索引位置上
- Thread类中的成员变量threadLocalRandomProbe:
@jdk.internal.vm.annotation.Contended("tlr")
int threadLocalRandomProbe;
- threadLocalRandomProbe变量的值就是LongAdder用来确定hash的值来定位数组cells中的位置的 .threadLocalRandomProbe的初始值为0
- 在LongAdder的父类Striped64中,通过getProbe() 方法获取当前线程的threadLocalRandomProbe的值:
/**
* 返回当前线程的probe值
* 由于包装的限制,从ThreadLocalRandom中复制
*/
static final int getProbe() {
return (int) THREAD_PROBE.get(Thread.currentThread());
}
- probe值是threadLocalRandomProbe变量在Thread类中的偏移量
threadLocalRandomProbe初始化
if ((h = getProbe()) == 0) {
// ThreadLocalRandom类强制初始化
ThreadLocalRandom.current(); // force initialization
// 设置h的值为0x9e3779b9
h = getProbe();
// 将没有争用的标识设置为true
wasUncontended = true;
}
- 当前线程使用LongAdder中的add() 方法执行累加操作,在没有进入longAccumulate() 方法之前 ,threadLocalRandomProbe的值一直为0
- 当执行累加操作发生争用后进入longAccumulate() 方法,第一次进入longAccumulate() 方法就判断threadLocalRandomProbe的值是否为0, 如果值为0, 则将hash的值设置为0x9e3779b9
- ThreadLocalRandom.current() 方法:
/**
* 返回当前线程的ThreadLocalRandom
*/
public static ThreadLocalRandom current() {
if (UNSAFE.getInt(Thread.currentThread(), PROBE) == 0)
localInit();
return instance;
}
- 在current() 方法中,判断probe的值是否为0, 如果probe的值为0, 就执行localInit() 方法,将当前的probe设置为非0的值:
/**
* 为当前线程初始化线程字段
*/
static final void localInit() {
int p = probeGenerator.addAndGet(PROBE_INCREMENT);
// 跳过p为0的值
int probe = (p == 0) ? 1 : p; // skip 0
long seed = mix64(seeder.getAndAdd(SEEDER_INCREMENT));
// 获取当前线程
Thread t = Thread.currentThread();
U.putLong(t, SEED, seed);
// 将probe的值更新为probeGenerator的值
U.putInt(t, PROBE, probe);
}
- probeGenerator是static类型的AtomicInteger类的对象,每执行一次localInit() 方法,都会将probeGenerator累加一次值0x9e3779b9
- 0x9e3779b9是由232 除以黄金比例常数1.6180339887确定的
- 如果probeGenerator值为0, 就将当前线程的threadLocalRandomProbe的值设置为1. 否则就将当前线程的threadLocalRandomProbe的值设置为probeGenerator的值
threadLocalRandomProbe重新生成
- 将probe的值进行3次左右移位和异或操作:
static final int advanceProbe(int probe) {
probe ^= probe << 13; // xorshift
probe ^= probe >>> 17;
probe ^= probe << 5;
THREAD_PROBE.set(Thread.currentThread(), probe);
return probe;
}
以上是关于Java中的并发计数器LongAdder的主要内容,如果未能解决你的问题,请参考以下文章