高性能并发队列Disruptor
Posted 攻城狮Chova
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了高性能并发队列Disruptor相关的知识,希望对你有一定的参考价值。
Disruptor
基本概念
- Disruptor是一个高性能的异步处理框架,是一个轻量的Java消息服务JMS, 能够在无锁的情况下实现队列的并发操作
- Disruptor使用环形数组实现了类似队列的功能,并且是一个有界队列.通常应用于生产者-消费者的场景
- Disruptor是一个观察者模式的实现
- Disruptor通过以下三种设计方案解决性能问题:
- 环形数组结构:
- 为了避免垃圾回收,使用数组代替链表
- 数组对处理器的缓存机制更加友好
- 元素位置定位:
- 数组长度为2n, 可以通过位运算,提升定位的速度
- 数组中元素下标采用递增的形式
- index采用long类型,不用担心索引index溢出问题
- 无锁设计:
- 每个生产者或者消费者线程,会首先申请可以操作的元素在数组中的位置,如果申请成功,直接在申请到的位置上写入数据或者读取数据
- 环形数组结构:
- Disruptor和BlockingQueue比较:
- BlockingQueue: FIFO队列.生产者Producer向队列中发布publish一个事件时,消费者Consumer能够获取到通知.如果队列中没有消费的事件,消费者就会被阻塞,直到生产者发布新的事件
- Disruptor可以比BlockingQueue做到更多:
- Disruptor队列中同一个事件可以有多个消费者,消费者之间既可以并行处理,也可以形成依赖图相互依赖,按照先后次序进行处理
- Disruptor可以预分配用于存储事件内容的内存空间
- Disruptor使用极度优化和无锁的设计实现极高性能的目标
- 通常情况下,如果存在两个独立的处理过程的线程时,就可以使用高性能的并发队列Disruptor来实现
- Disruptor的优点:
- 使用无锁的队列实现并发操作,性能非常高
- 所有访问者都记录自身序号的实现方式,允许多个生产者和多个消费者共享相同的数据结构
- 在每个对象,包括RingBuffer,WaitStrategy, 生产者Producer和消费者Consumer中都能跟踪序列号,使用了缓存行填充cache line padding, 这样就没有伪共享和非预期的竞争
Disruptor应用
定义事件
- Event: 事件 .Disruptor队列中进行交换的数据类型
定义事件工厂
- Event Factory: 定义事件Event实例化方法,用来实例化一个事件Event. 需要实现接口com.lmax.disruptor.EventFactory< T >
- Disruptor通过事件工厂EventFactory在RingBuffer中预创建事件Event的实例
- 一个事件实例Event类似于一个数据槽
- 生产者Producer发布Publish之前,先从Ringbuffer中获取一个事件Event实例
- 然后生产者Producer向事件Event实例中填充数据,然后再发布到RingBuffer中
- 最后由消费者Consumer获取事件Event实例并读取实例中的数据
定义事件处理实现
- 通过实现接口com.lmax.disruptor.EventHandler< T > 定义事件处理的具体实现
定义事件处理的线程池
- Disruptor通过java.util.concurrent.ExecutorService提供的线程来触发消费者Consumer的事件处理
指定等待策略
- Disruptor中使用策略模式定义消费者Consumer处理事件的等待策略,通过com.lmax.disruptor.WaitStrategy接口实现
- WaitStrategy等待策略有三种常用的实现: 每种策略具有不同的性能和优缺点.根据实际运行环境的CPU的硬件特点选择恰当的策略,并且使用特定的JVM配置启动参数,能够实现不同的性能提升
- BlockingWaitStrategy:
- 性能最低
- 对CPU的消耗最小
- 能够在不同的部署环境中提供更加一致的性能
- SleepingWaitStrategy:
- 性能以及对CPU的消耗和BlockingWaitStrategy差不多
- 对生产者线程影响最小
- 适合应用于异步日志等场景
- YieldingWaitStrategy:
- 性能最高
- 适合应用于低延迟的系统
- 在要求极高的性能并且事件处理线程个数小于CPU逻辑核心个数的场景中,推荐使用这个等待策略
- 比如CPU开启超线程的特性
- BlockingWaitStrategy:
启动Disruptor
EventFactory<Event> eventFactory = new EventFactory();
int ringBufferSize = 1024*1024;
Disruptor<Event> disruptor = new Disruptor<Event>(eventFactory, ringBufferSize, executor, ProcedureType.SINGLE, blockingWaitStrategy);
EventHandler<Event> eventHandler = new EventHandle();
disruptor.handleEventsWith(eventHandler);
disruptor.start();
发布事件
- Disruptor的事件Event的发布Publish过程是一个两阶段提交过程:
- 第一步: 先从RingBuffer获取下一个可以写入事件的序号
- 第二步: 获取对应的事件Event对象,将数据写入事件对象
- 第三步: 将事件提交到RingBuffer
- Disruptor中要求RingBuffer.publish()方法必须要被调用.也就是说,即使发生异常,也要执行publish()方法,这就要求调用者Producer在事件处理的实现上要判断携带的数据的正确性和完整性
关闭Disruptor
- disruptor.shutdown() : 关闭Disruptor. 方法会阻塞,直至所有的事件都得到处理
- executor.shutdown() : 关闭Disruptor使用的线程池. 如果线程池需要关闭,必须进行手动关闭 ,Disruptor在shutdown时不会自动关闭使用的线程池
Disruptor原理
核心概念
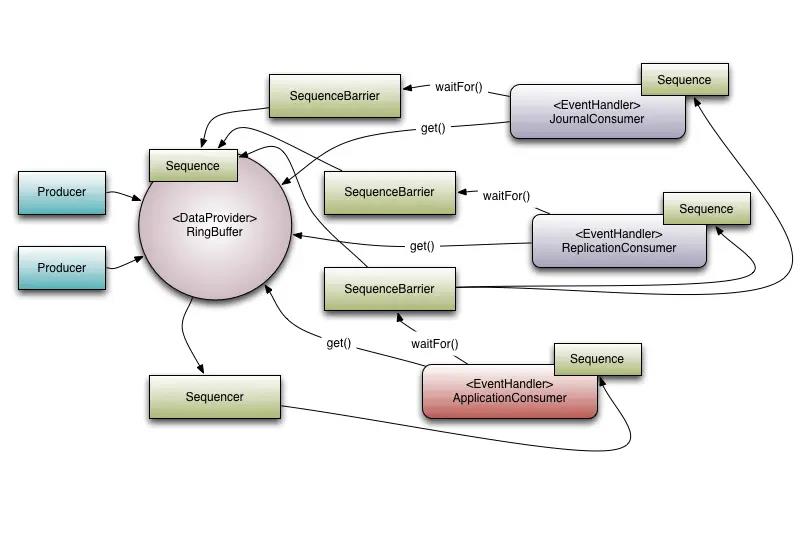
RingBuffer
- RingBuffer: 环形缓冲区
- RingBuffer从3.0开始,仅仅负责对通过Disruptor进行交换的事件数据进行存储和更新
- 在Disruptor的高级应用场景中 ,RingBuffer可以使用用户自定义的实现来替代
Sequence Disruptor
- 使用顺序递增的序号来编号管理通过Sequence Disruptor进行交换的事件数据,对事件的处理总是按着序号逐个递增进行处理
- 使用Sequence用于跟踪标识某个特定的事件处理者,包括RingBuffer和Consumer的处理进度
- 使用Sequence来标识进度可以防止不同的Sequence之间的CPU的缓存间的伪共享Flase Sharing问题
Sequencer
- Sequencer是Disruptor的核心
- Sequencer接口有两个实现类:
- SingleProducerSequencer
- MultiProducerSequencer
- 这是定义在生产者和消费者之间快速,正确传递数据的并发算法
Sequence Barrier
- 用于保持对RingBuffer的published Sequence和Consumer依赖的其余的Consumer的Sequence引用
- Sequence Barrier中定义了Consumer是否还有可处理的事件的逻辑
WaitStrategy
- WaitStrategy定义Consumer等待事件的策略
Event
- Disruptor中生产者Producer和消费者Consumer之间进行交换的数据叫做事件Event
- Event类型不是Disruptor定义的,而是由Disruptor的使用者来自定义指定
EventProcessor
- EventProcessor持有指定的消费者Consumer的Sequence, 并且提供用于调用事件处理实现的事件循环EventLoop
EventHandler
- Disruptor中定义的事件处理接口,由使用者实现,用于事件的具体处理,是消费者Consumer的真正实现
Producer
- Producer: 生产者. 泛指Disruptor发布事件的调用方.没有在Disruptor中定义特定的接口或者类型
内存预分配
- RingBuffer使用数组Object[] entries来存储元素:
- 初始化RingBuffer时,会将所有数组元素entries的指定为特定的事件Event参数,此时Event中的detail属性为null
- 生产者向RingBuffer写入消息时 ,RingBuffer不是直接将数组元素entries指向Event对象,而是先获取Event对象,更改Event对象中的detail属性
- 消费者在消费时,也是从RingBuffer中读取Event, 读取Event对象中的detail属性
- 由此可见,在生产和消费过程中 ,RingBuffer中的数组元素entries没有发生任何变化,没有产生临时对象,数组中的元素一直存活,直到RingBuffer消亡
- 通过以上方式,可以最小化JVM中的垃圾回收GC的频率,提升性能
private void fill(EventFactory<E> eventFactory) {
for (int i = 0; i < bufferSize; i++) {
// 使用工厂方法初始化数组中的entries元素
entries[BUFFER_PAD + i] = eventFactory.newInstance();
}
}
消除伪共享
- Disruptor中的伪共享: 如果两个相互独立的并发变量位于同一个缓存行时,在并发的情况下,会相互影响彼此的缓存有效性,进而影响并发操作的性能
- Disruptor中消除伪共享:
- Sequence.java中使用多个long变量填充,确保一个序号独占一个缓存行
private static class Padding {
public long nextValue = Sequence.INITIAL_VALUE, cachedValue = Sequence.INITIAL_VALUE, p2, p3, p4, p5, p6, p7;
}
消除锁和CAS操作
- Disruptor中,通过联合使用SequenceBarrier和Sequence, 协调和管理消费者和生产者之间的处理关系,避免了锁和CAS操作
- Disruptor中的各个消费者和生产者持有自己的序号Sequence, 序号Sequence需要满足以下条件:
- 条件一: 消费者的序号Sequence的数值必须小于生产者的序号Sequence的数值
- 条件二: 消费者的序号Sequence的数值必须小于依赖关系中前置的消费者的序号Sequence的数值
- 条件三: 生产者的序号Sequence的数值不能大于消费者正在消费的序号Sequence的数值,防止生产者速度过快,将还没有来得及消费的事件消息覆盖
- 条件一和条件二在SequenceBarrier中的waitFor() 方法中实现:
/**
* 等待给定的序号值可以供消费者使用
*
* @param sequence 消费者期望获取的下一个序号值
* @return long 可供消费者使用的序号的值
*/
public long waitFor(final long sequence) throws AlertException, InterruptedException, TimeoutException {
checkALert();
/**
* 根据指定的waitStrategy策略,等待期望的下一序号值可供使用
* 这里不一定能保证返回值availableSequence一定和给定的参数sequence的值相等,两者的大小关系取决于使用的等待策略waitStrategy
* - YieldingWaitStrategy : 自旋100次后,会直接返回dependentSequence中最小的序号sequence,这是不能保证返回的值大于等于给定的序号值
* - BlockingWaitStrategy : 阻塞等待给定的序号sequence值可用为止,可用不是返回的值就等于给定的序号值,而是返回的值大于等于给定的序号值
*/
long availableSequence = waitStrategy.waitFor(sequence, cursorSequence, dependentSequence, this);
// 如果当前可用的序号值小于给定的序号值,就返回当前可用的序号值,此时调用者EventProcessor会继续等待wait
if (availableSequence < sequence) {
return sequence;
}
// 批处理
return sequencer.getHighestPublishedSequence(sequence, availableSequence);
}
- 条件三是针对生产者建立的SequenceBarrier,逻辑判定发生在生产者从RingBuffer获取下一个可用的entry时,RingBuffer会将获取下一个可用的entry委托给Sequencer处理:
@Override
public long next() {
if (n < 1) {
throw new IllegalArgumentException("n must be > 0");
}
long nextValue = this.nextValue;
// 下一个序号值等于当前序号值加上期望获取的序号数量
long nextSequence = nextValue + n;
// 使用下一个序号值减掉RingBuffer中的总量值bufferSize,来判断是否会发生覆盖
long wrapPoint = nextSequence - bufferSize;
/*
* cachedValue就是缓存的消费者中的最小序号值
* cachedValue不是当前最新的消费者中最小序号值,而是上一次方法调用时进入到下面if条件判断时,被赋值的消费者中最小序号值
*
* 这样做可以在判定是否出现覆盖的时候,不需要每次都调用getMinimumSequence计算消费者中的最小序号值,从而节省开销。只要确保
* 当生产者的值大于了缓存cachedGatingSequence一个bufferSize时,重新获取一下getMinimumSequence()即可
*/
long cachedGatingSequence = this.cachedValue;
/*
* wrapPoint > cachedGatingSequence : 当生产者已经超过上一次缓存的消费者中的最小序号值cachedGatingSequence一个bufferSize大小时,需要重新获取cachedGatingSequence,防止生产者一直生产,消费者没有来得及消费时,发生覆盖的情况
* cachedGatingSequence > nextValue : 生产者和消费者的序号值都是顺序递增的,并且生产者的序号Sequence是先于消费者Sequence,这里是先于而不是大于。对于nextValue的值大于了LONG.MAXVALUE时,此时nextValue + 1就会变为负数,wrapPoint值也会变为负数,此时必然cachedGatingSequence > nextValue。 getMinimumSequence()获取的是消费者中最小序号值,但不代表是走在最后的一个消费者
*/
if (wrapPoint > cachedGatingSequence || cachedGatingSequence > nextValue) {
cursor.setVolatile(nextValue);
long minSequence;
while (wrapPoint > (minSequence = Util.getMinimumSequence(gatingSequences, nextValue))) {
// 生产者阻塞,等待消费者消费,直到不会发生覆盖的情况继续向下执行
LockSupport.parkNanos(1L);
}
this.cacheValue = minSequence;
}
this.nextValue = nextSequence;
return nextSequence;
}
批处理效应
- 当出现生产者比消费者过快时,消费者可以通过批处理效应来追赶生产者进度
- 消费者一次性从RingBuffer中获取多个已经准好的数组事件元素进行消费处理,从而提高消费效率
/**
* 等待给定的序号值可以供消费者使用
*
* @param sequence 消费者期望获取的下一个序号值
* @return long 可供消费者使用的序号的值
*/
public long waitFor(final long sequence) throws AlertException, InterruptedException, TimeoutException {
checkALert();
long availableSequence = waitStrategy.waitFor(sequence, cursorSequence, dependentSequence, this);
if (availableSequence < sequence) {
return sequence;
}
/*
* 获取消费者可以消费的最大序列号,通过批处理来提升效率:
* - 当availableSequence > sequence时,需要遍历序号sequence到序号availableSequence,获取到最前面一个准备就绪,可以进行消费的事件Event对应的序号sequence
* - 最小值为sequence - 1
*/
return sequencer.getHighestPublishedSequence(sequence, availableSequence);
}
以上是关于高性能并发队列Disruptor的主要内容,如果未能解决你的问题,请参考以下文章
Day859.高性能队列Disruptor -Java 并发编程实战
Day859.高性能队列Disruptor -Java 并发编程实战