Python3基础语法小结与简单编程实操案例
Posted Tr0e
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python3基础语法小结与简单编程实操案例相关的知识,希望对你有一定的参考价值。
文章目录
前言
由于日常工作中需要编写一些脚本进行自动化安全测试,所以接触 Python 也一段时间了,但是习惯性地处于 Ctrl+C/ Ctrl+V 的“改造式编程”模式中,终究是没有灵魂的……从零开始书写一段完整的脚本更是丑态百出……所以本文想着还是脚踏实地学习总结下 Python 的基本语法、并针对一些简单的 Python 编程实操案例进行动手编码练习,从而提升下自己的 Python 语言基础编码能力……
基础语法
先推荐一个线上的 Python3 教程地址:菜鸟教程。
数据类型
| 数据类型 | 数据特性 | 声明方法 | 用法简述 |
|---|---|---|---|
| Number(数字) | 不可变数据 | a, b, c = 20, 5.5, 4+3j | 数值的除法包含两个运算符:/ 返回一个浮点数,// 返回一个整数 |
| String(字符串) | 不可变数据 | str = ‘Tr0e’ 或 str = “Tr0e” | 1)字符串可以用+运算符连接在一起,用*运算符重复;2)字符串有两种索引方式,从左往右以0开始,从右往左以-1开始。 |
| Tuple(元组) | 不可变数据 | tuple = (123, 'runoob',1.01) | 数值的除法包含两个运算符:/ 返回一个浮点数,// 返回一个整数 |
| List(列表) | 可变数据 | list = ['abcd', 786 , 'Tr0e', 70.2] | 列表的数据项不需要具有相同的类型,列表内置 append()、pop() 等函数 |
| Dictionary(字典) | 可变数据 | tinydict = {'name': 'runoob','code':1, 'site': 'www.runoob.com'} | 字典是一种映射类型,字典用 { } 标识,它是一个无序的 键(key) : 值(value) 的集合,关键字必须为不可变类型,且不能重复 |
| Set(集合) | 可变数据 | sites = {'Taobao', 'Zhihu', 'Baidu'} | 可以使用大括号 { } 或者 set() 函数创建集合,空集合必须用 set() 而不是 { } |
1、字符串内置函数
| 函数名 | 作用 |
|---|---|
| find(str, beg=0, end=len(string)) | 检测 str 是否包含在字符串中,如果指定范围 beg 和 end ,则检查是否包含在指定范围内,如果包含返回开始的索引值,否则返回-1 |
| index(str, beg=0, end=len(string)) | 跟find()方法一样,只不过如果str不在字符串中会报一个异常。 |
| len(string) | 返回字符串长度 |
| lower() | 转换字符串中所有大写字符为小写 |
| replace(old, new [, max]) | 把 将字符串中的 old 替换成 new,如果 max 指定,则替换不超过 max 次。 |
| startswith(substr, beg=0,end=len(string)) | 检查字符串是否是以指定子字符串 substr 开头,是则返回 True,否则返回 False。如果beg 和 end 指定值,则在指定范围内检查。 |
2、列表内置函数
| 函数名 | 作用 |
|---|---|
| len(list) | 列表元素个数 |
| max(list) | 返回列表元素最大值 |
| list(seq) | 将元组转换为列表 |
| list.append(obj) | 在列表末尾添加新的对象 |
| list.count(obj) | 统计某个元素在列表中出现的次数 |
| list.extend(seq) | 在列表末尾一次性追加另一个序列中的多个值 |
| list.index(obj) | 从列表中找出某个值第一个匹配项的索引位置 |
| list.insert(index, obj) | 将对象插入列表 |
| list.pop([index=-1]) | 移除列表中的一个元素(默认最后一个元素),并且返回该元素的值 |
| list.remove(obj) | 反向列表中元素 |
| list.sort( key=None, reverse=False) | 对原列表进行排序 |
| list.clear() | 清空列表 |
| list.copy() | 复制列表 |
3、字典内置函数
| 函数名 | 作用 |
|---|---|
| len(dict) | 计算字典元素个数,即键的总数 |
| str(dict) | 输出字典,以可打印的字符串表示 |
| radiansdict.clear() | 删除字典内所有元素 |
| radiansdict.copy() | 返回一个字典的浅复制 |
| radiansdict.get(key, default=None) | 返回指定键的值,如果键不在字典中返回 default 设置的默认值 |
| key in dict | 如果键在字典dict里返回true,否则返回false |
| pop(key[,default]) | 删除字典给定键 key 所对应的值,返回值为被删除的值。key值必须给出。 否则,返回default值 |
4、集合内置函数
| 函数名 | 作用 |
|---|---|
| add() | 为集合添加元素 |
| clear() | 移除集合中的所有元素 |
| copy() | 拷贝一个集合 |
| discard() | 删除集合中指定的元素 |
| intersection() | 返回集合的交集 |
| intersection_update() | 返回集合的交集 |
| remove() | 移除指定元素 |
| union() | 返回两个集合的并集 |
控制语句
1、条件控制—— if 语句
Python 中 if 语句的一般形式如下所示:
if condition_1:
statement_block_1
elif condition_2:
statement_block_2
else:
statement_block_3
以下实例演示了狗的年龄计算判断:
#!/usr/bin/python3
age = int(input("请输入你家狗狗的年龄: "))
print("")
if age <= 0:
print("你是在逗我吧!")
elif age == 1:
print("相当于 14 岁的人。")
elif age == 2:
print("相当于 22 岁的人。")
elif age > 2:
human = 22 + (age -2)*5
print("对应人类年龄: ", human)
### 退出提示
input("点击 enter 键退出")
CMD 运行效果:
$ python3 dog.py
请输入你家狗狗的年龄: 1
相当于 14 岁的人。
点击 enter 键退出
2、循环控制—— for 语句
Python for 循环可以遍历任何可迭代对象,如一个列表或者一个字符串。for循环的一般格式如下:
for <variable> in <sequence>:
<statements>
else:
<statements>
来看一个实例:
#!/usr/bin/python3
sites = ["Baidu", "Google","Runoob","Taobao"]
for site in sites:
if site == "Runoob":
print("菜鸟教程!")
break
print("循环数据 " + site)
else:
print("没有循环数据!")
print("完成循环!")
执行脚本后,在循环到 "Runoob"时会跳出循环体:
循环数据 Baidu
循环数据 Google
菜鸟教程!
完成循环!
如果你需要遍历数字序列,可以使用内置range()函数,它会生成数列,例如:
>>>for i in range(3):
... print(i)
...
0
1
2
你也可以使用 range 指定区间的值:
>>>for i in range(5,9) :
print(i)
5
6
7
8
>>>
3、迭代器
迭代是 Python 最强大的功能之一,是访问集合元素的一种方式。迭代器是一个可以记住遍历的位置的对象。迭代器对象从集合的第一个元素开始访问,直到所有的元素被访问完结束。迭代器只能往前不会后退。迭代器有两个基本的方法:iter() 和 next()。
迭代器对象可以使用常规 for 语句进行遍历:
#!/usr/bin/python3
list=[1,2,3,4]
it = iter(list) # 创建迭代器对象
for x in it:
print (x, end=" ")
执行以上程序,输出结果如下:
1 2 3 4
也可以使用 next() 函数:
#!/usr/bin/python3
import sys # 引入 sys 模块
list=[1,2,3,4]
it = iter(list) # 创建迭代器对象
while True:
try:
print (next(it))
except StopIteration:
sys.exit()
执行以上程序,输出结果如下:
1
2
3
4
4、生成器
在 Python 中,使用了 yield 的函数被称为生成器(generator)。跟普通函数不同的是,生成器是一个返回迭代器的函数,只能用于迭代操作,更简单点理解生成器就是一个迭代器。
在调用生成器运行的过程中,每次遇到 yield 时函数会暂停并保存当前所有的运行信息,返回 yield 的值,并在下一次执行 next() 方法时从当前位置继续运行。调用一个生成器函数,返回的是一个迭代器对象。
以下实例使用 yield 实现斐波那契数列:
#!/usr/bin/python3
import sys
# 生成器函数 - 斐波那契
def fibonacci(n):
a, b, counter = 0, 1, 0
while True:
if (counter > n):
return
yield a
a, b = b, a + b
counter += 1
#f是一个迭代器,由生成器返回生成
f = fibonacci(10)
while True:
try:
print (next(f), end=" ")
except StopIteration:
sys.exit()
执行以上程序,输出结果如下:
0 1 1 2 3 5 8 13 21 34 55
输出格式
Python 支持格式化字符串的输出 。尽管这样可能会用到非常复杂的表达式,但最基本的用法是将一个值插入到一个有字符串格式符 %s 的字符串中。在 Python 中,字符串格式化使用与 C 中 sprintf 函数一样的语法。
#!/usr/bin/python3
print ("我叫 %s 今年 %d 岁!" % ('小明', 10))
以上实例输出结果:
我叫 小明 今年 10 岁!
1、Python 字符串格式化符号:
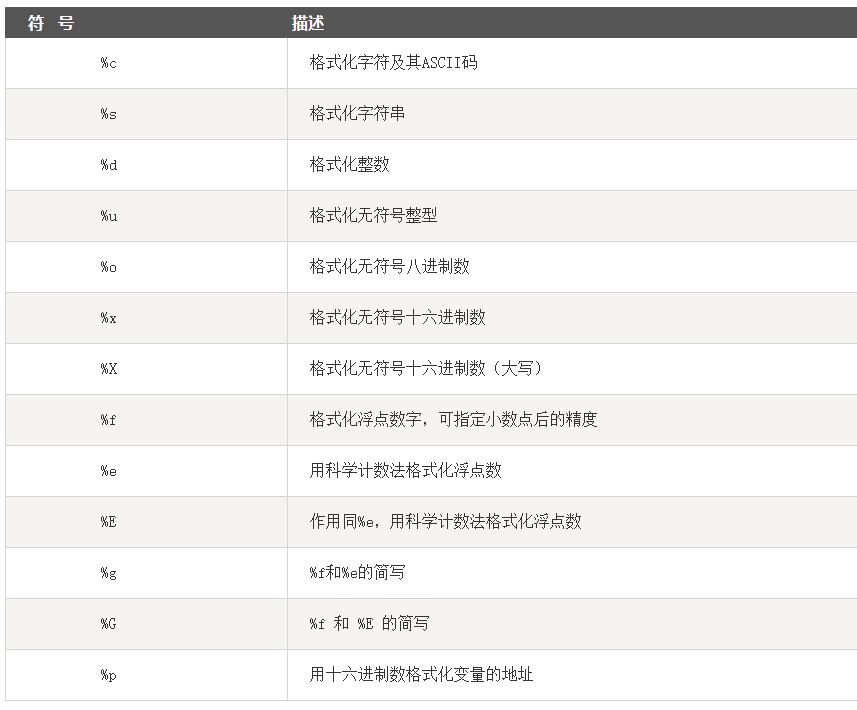
2、字符串索引输出:
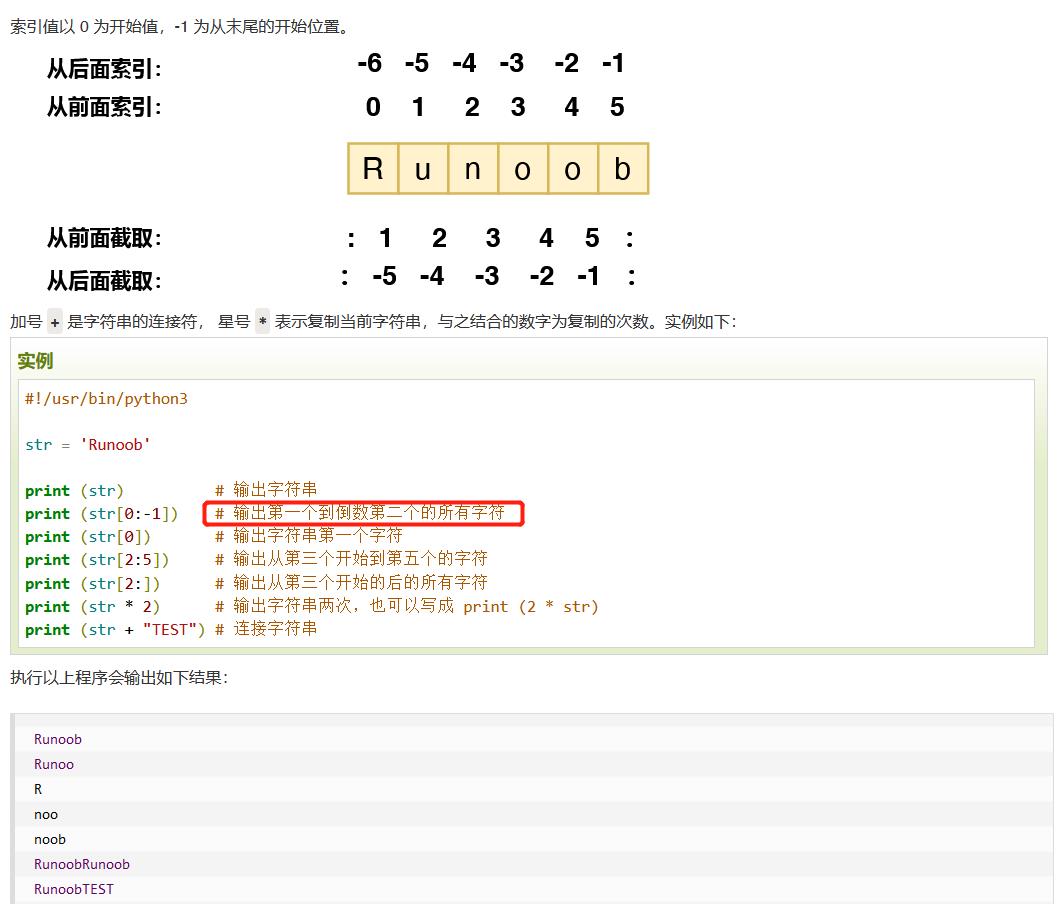
3、字符串运算符
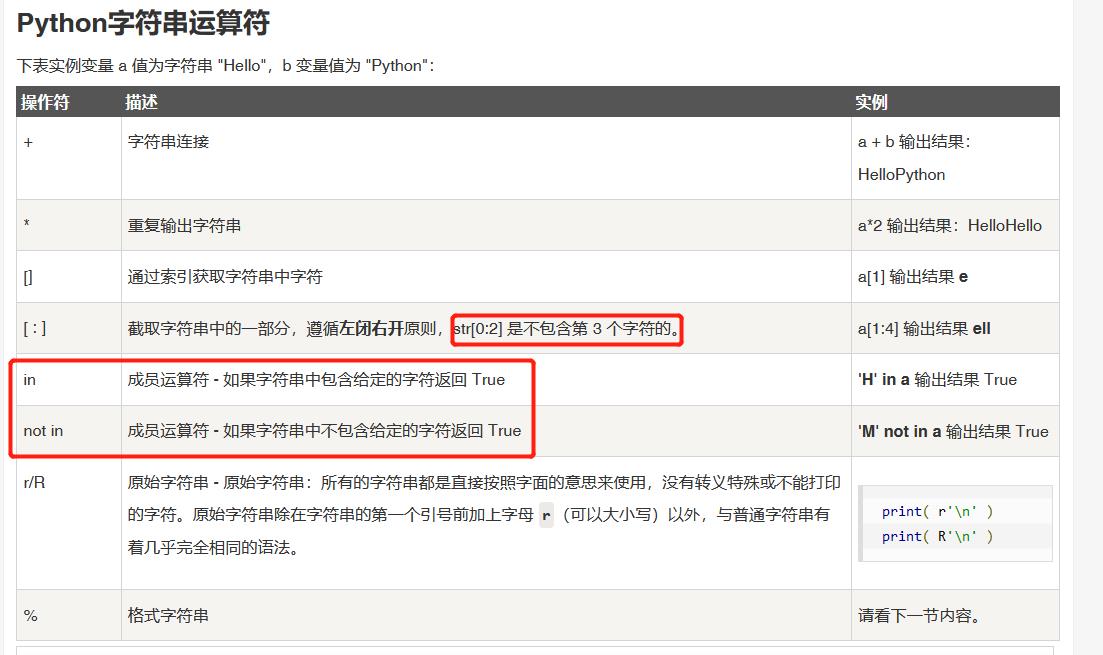
函数与包
1、函数参数传递
 2、函数不定长参数
2、函数不定长参数
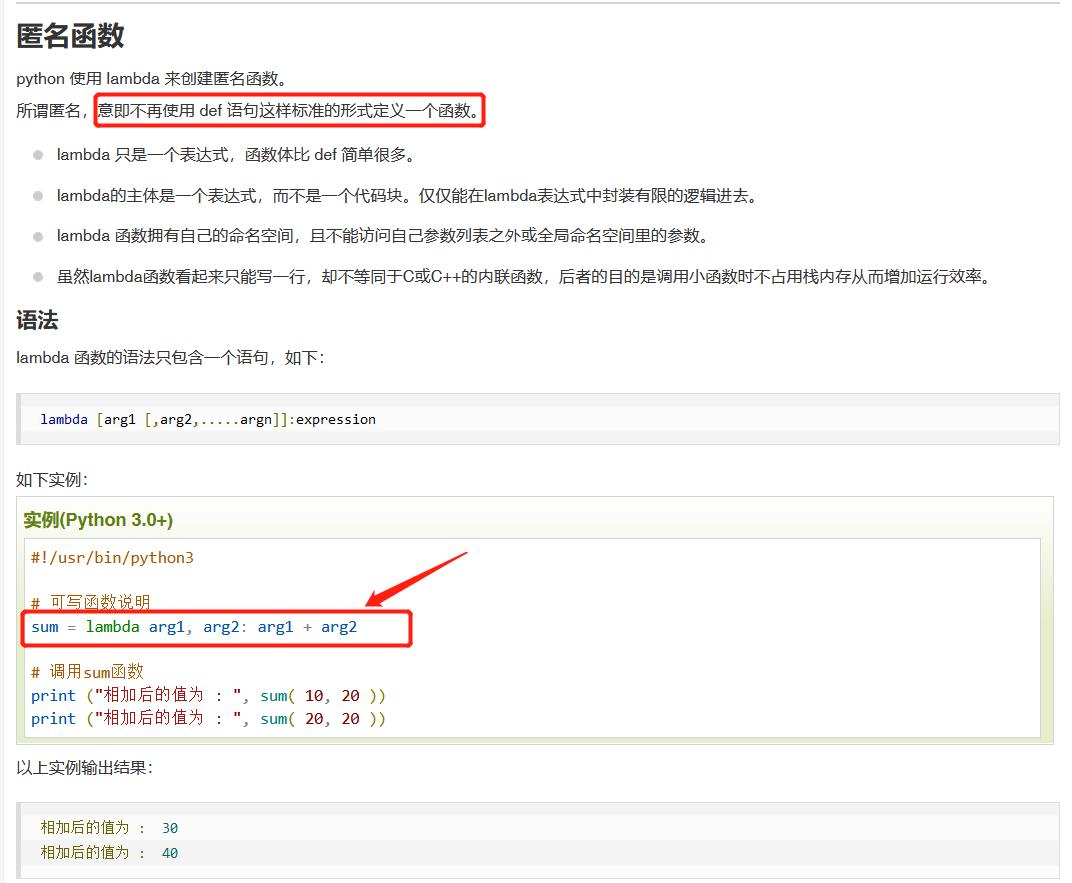
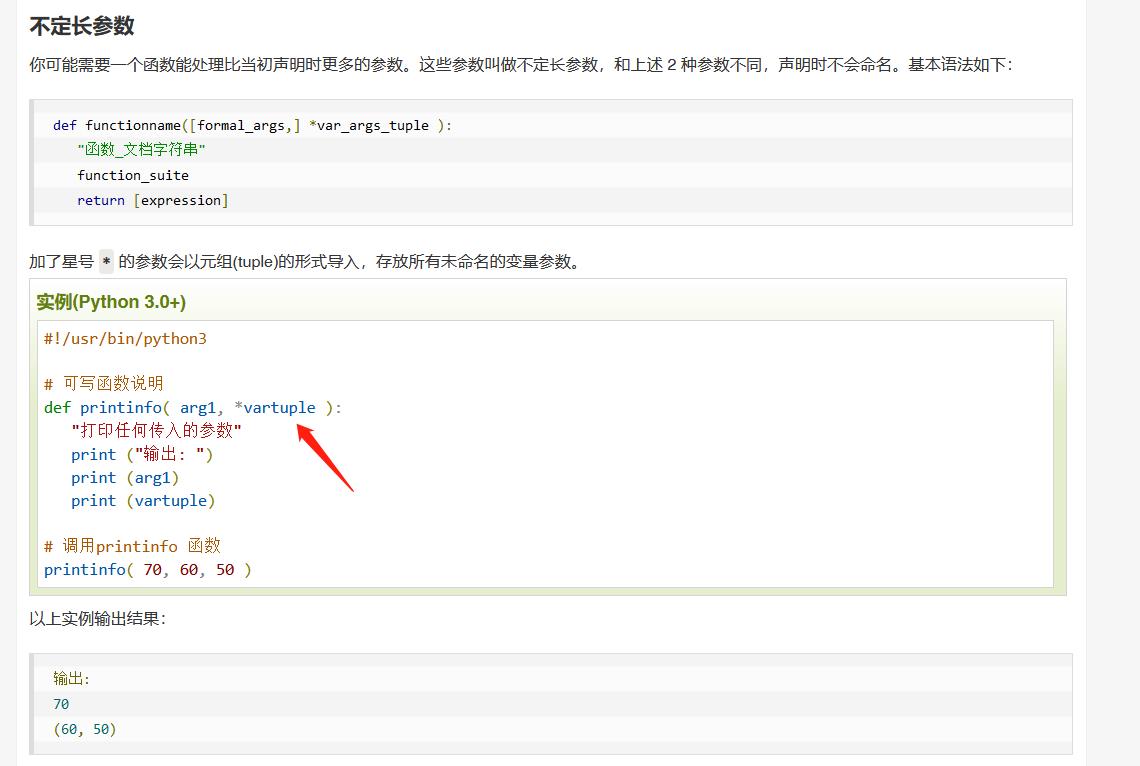 3、匿名函数
3、匿名函数
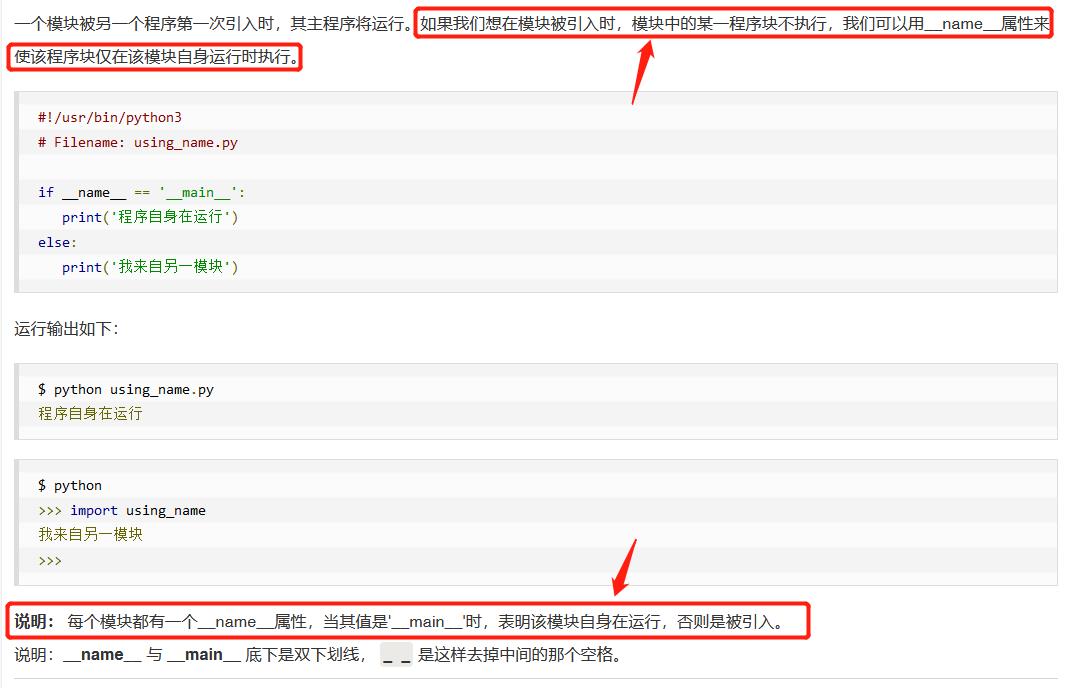
 4、__name__属性
4、__name__属性
5、__init__.py文件
包是一种管理 Python 模块命名空间的形式,采用"点模块名称"。不妨假设你想设计一套统一处理声音文件和数据的模块(或者称之为一个"包")。现存很多种不同的音频文件格式(基本上都是通过后缀名区分的,例如: .wav,:file:.aiff,:file:.au,),所以你需要有一组不断增加的模块,用来在不同的格式之间转换。并且针对这些音频数据,还有很多不同的操作(比如混音,添加回声,增加均衡器功能,创建人造立体声效果),所以你还需要一组怎么也写不完的模块来处理这些操作。
这里给出了一种可能的包结构(在分层的文件系统中):
sound/ 顶层包
__init__.py 初始化 sound 包
formats/ 文件格式转换子包
__init__.py
wavread.py
wavwrite.py
aiffread.py
aiffwrite.py
auread.py
auwrite.py
...
effects/ 声音效果子包
__init__.py
echo.py
surround.py
reverse.py
...
filters/ filters 子包
__init__.py
equalizer.py
vocoder.py
karaoke.py
...
需要注意几点:
- 在导入一个包的时候,Python 会根据 sys.path 中的目录来寻找这个包中包含的子目录;
- 目录只有包含一个叫做
__init__.py的文件才会被认作是一个包,主要是为了避免一些滥俗的名字(比如叫做 string)不小心的影响搜索路径中的有效模块; - 最简单的情况,放一个空的 :file:
__init__.py就可以了。当然这个文件中也可以包含一些初始化代码或者为(将在后面介绍的)__all__变量赋值。
如果我们使用 from sound.effects import * 会发生什么呢?Python 会进入文件系统,找到这个包里面所有的子模块,然后一个一个的把它们都导入进来。但这个方法在 Windows 平台上工作的就不是非常好,因为 Windows 是一个不区分大小写的系统。在 Windows 平台平台上,我们无法确定一个叫做 ECHO.py 的文件导入为模块是 echo 还是 Echo,或者是 ECHO。为了解决这个问题,我们只需要提供一个精确包的索引。
导入语句遵循如下规则:如果包定义文件 __init__.py 存在一个叫做 all 的列表变量,那么在使用 from package import * 的时候就把这个列表中的所有名字作为包内容导入(作为包的作者,可别忘了在更新包之后保证 __all__ 也更新了啊)。
以下实例在 file:sounds/effects/__init__.py 中包含如下代码:
__all__ = ["echo", "surround", "reverse"]
这表示当你使用from sound.effects import *这种用法时,你只会导入包里面这三个子模块。如果 __all__ 真的没有定义,那么使用from sound.effects import *这种语法的时候,就不会导入包 sound.effects 里的任何子模块。他只是把包sound.effects和它里面定义的所有内容导入进来(可能运行__init__.py里定义的初始化代码)。
文件读写
1、函数 open() 将会返回一个 file 对象,基本语法格式如下:
open(filename, mode)
filename:包含了你要访问的文件名称的字符串值。
mode 参数:决定了打开文件的模式:只读,写入,追加等。这个参数是非强制的,默认文件访问模式为只读(r)
2、不同模式打开文件的完全列表:
 以下实例将字符串写入到文件 foo.txt 中:
以下实例将字符串写入到文件 foo.txt 中:
#!/usr/bin/python3
# 打开一个文件
f = open("/tmp/foo.txt", "w")
f.write( "Python 是一个非常好的语言。\\n是的,的确非常好!!\\n" )
# 关闭打开的文件
f.close()
2、假设已经创建了一个称为 f 的文件对象,为了读取一个 f 文件的内容,调用 f.read(), 这将读取一定数目的数据,然后作为字符串或字节对象返回:
#!/usr/bin/python3
# 打开一个文件
f = open("/tmp/foo.txt", "r")
str = f.read()
print(str)
# 关闭打开的文件
f.close()
执行以上程序,输出结果为:
Python 是一个非常好的语言。
是的,的确非常好!!
3、调用函数f.readline() 会从文件中读取单独的一行,换行符为 ‘\\n’。f.readline() 如果返回一个空字符串, 说明已经已经读取到最后一行:
#!/usr/bin/python3
# 打开一个文件
f = open("/tmp/foo.txt", "r")
str = f.readline()
print(str)
# 关闭打开的文件
f.close()
执行以上程序,输出结果为:
Python 是一个非常好的语言。
4、函数 f.write(string) 将 string 写入到文件中, 然后返回写入的字符数:
#!/usr/bin/python3
# 打开一个文件
f = open("/tmp/foo.txt", "w")
num = f.write( "Python 是一个非常好的语言。\\n是的,的确非常好!!\\n" )
print(num)
# 关闭打开的文件
f.close()
执行以上程序,输出结果为:
29
如果要写入一些不是字符串的东西, 那么将需要先进行转换:
#!/usr/bin/python3
# 打开一个文件
f = open("/tmp/foo1.txt", "w")
value = ('www.runoob.com', 14)
s = str(value)
f.write(s)
# 关闭打开的文件
f.close()
执行以上程序,打开 foo1.txt 文件:
$ cat /tmp/foo1.txt
('www.runoob.com', 14)
面向对象
类有一个名为 __init__() 的特殊方法(构造方法),该方法在类实例化时会自动调用,来看看一个具体实例:
#!/usr/bin/python3
#类定义
class people:
#定义基本属性
name = ''
age = 0
#定义私有属性,私有属性在类外部无法直接进行访问
__weight = 0
#定义构造方法
def __init__(self,n,a,w):
self.name = n
self.age = a
self.__weight = w
def speak(self):
print("%s 说: 我 %d 岁。" %(self.name,self.age))
#单继承示例
class student(people):
grade = ''
def __init__(self,n,a,w,g):
#调用父类的构函
people.__init__(self,n,a,w)
self.grade = g
#覆写父类的方法
def speak(self):
print("%s 说: 我 %d 岁了,我在读 %d 年级"%(self.name,self.age,self.grade))
if __name__ == '__main__':
s = student('ken',10,60,3)
s.speak()
执行以上程序输出结果为:
ken 说: 我 10 岁了,我在读 3 年级
类属性与方法:
| 类结构 | 备注 |
|---|---|
类的私有属性_private_attrs | 两个下划线开头,声明该属性为私有,不能在类的外部被使用或直接访问。在类内部的方法中使用时 self.__private_attrs。 |
| 类的方法 | 在类的内部,使用 def 关键字来定义一个方法,与一般函数定义不同,类方法必须包含参数 self,且为第一个参数,self 代表的是类的实例。self 的名字并不是规定死的,也可以使用 this,但是最好还是按照约定使用 self。 |
类的私有方法__private_method | 两个下划线开头,声明该方法为私有方法,只能在类的内部调用 ,不能在类的外部调用。self.__private_methods。 |
编程实例
No.1 计算两数求和
def test(a,b):
sum = a+b
print('数字 {0} 和 {1} 相加结果为:{2}'.format(a, b, sum))
if __name__ == '__main__':
#input() 返回的是一个字符串,所以我们需要使用 float() 方法将字符串转换为数字
num1 = float(input('输入第一个数字:'))
num2 = float(input('输入第二个数字:'))
test(num1,num2)
代码运行效果:
输入第一个数字:>? 1
输入第二个数字:>? 2
数字 1.0 和 2.0 相加结果为: 3.0
No.2 判断是否闰年
闰年分两类:
- 普通闰年:公历年份是4的倍数,且不是100的倍数的,为闰年(如2004年、2020年等就是闰年);
- 世纪闰年:公历年份是整百数的,必须是400的倍数才是闰年(如1900年不是闰年,2000年是闰年)。
Python 编码判断闰年如下:
def test(year):
if (year % 4 == 0):
if (year % 100 == 0):
if (year % 400 == 0):
print("{0}是闰年".format(year))
else:
print("{0}不是闰年".format(year))
else:
print("{0}是闰年".format(year))
else:
print("{0}不是闰年".format(year))
if __name__ == '__main__':
year = int(input("请输入一个年份:"))
test(year)
No.3 判断是否质数
将 num 除以从 2 到 num-1 的整数,如果发现有能被整除的,则不是质数。
def test(num):
for i in range(2,num):
if( num%i == 0):
print("{0}不是质数".format(num))
break
else:
if(i == num-1):
print("{0}是质数".format(num))
if __name__ == '__main__':
while True:
num = int(input("请输入一个整数:"))
test(num)
No.4 判断是否回文
def Test():
a = input("请输入需要判断的字符串:")
b = a[::-1]
if a == b:
print("是回文")
else:
print("不是回文")
if __name__ == '__main__':
while True:
Test()
留意一下字符串切片的基本操作:
line = "abcde"
good = line[:-1]
print(good)
结果为:'abcd'
line = "abcde"
good = line[::-1]
print(good)
结果为:'edcba'
No.5 斐波那契数列
斐波那契数列指的是这样一个数列 0, 1, 1, 2, 3, 5, 8, 13……
特别指出:第0项是0,第1项是第一个1。从第三项开始,每一项都等于前两项之和。
def test(num):
a,b=0,1
c=a
if(num==1):
print("斐波那契数列前1项:%d"%(a))
elif(num>1):
print("斐波那契数列前%d项:0,1,"%(num),end=" ")
for i in range(3,num+1):
c=a+b
a=b
b=c
print("%d" % (c), end=",")
if __name__ == '__main__':
while True:
num=int(input("\\n请输入您想要几项斐波那契数列的值:"))
test(num)
代码运行效果如下:

No.6 打印九九乘法
def test():
for i in range(1, 10):
for j in range(1, i+1):
print('{0}x{1}={2}\\t'.Python基础篇:面向对象案例实操