JAVA并发基石——CAS
Posted Code_BinBin
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了JAVA并发基石——CAS相关的知识,希望对你有一定的参考价值。
引言
我们知道,锁分为乐观锁,悲观锁
- 独占锁是一种悲观锁,而 synchronized 就是一种独占锁,synchronized会导致其它所有未持有锁的线程阻塞,而等待持有锁的线程释放锁。
- 所谓乐观锁就是,每次不加锁而是假设没有冲突而去完成某项操作,如果因为冲突失败就重试,直到成功为止。而乐观锁用到的机制就是CAS。
下面我们来写一段代码
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.TimeUnit;
public class Demo {
static int count=0;
public static void request() throws InterruptedException {
TimeUnit.MICROSECONDS.sleep(5);
count++;
}
public static void main(String[] args) throws InterruptedException {
long startIime=System.currentTimeMillis();
int threadSize=100;
CountDownLatch countDownLatch=new CountDownLatch(threadSize);
for (int i=0;i<threadSize;i++){
Thread thread=new Thread(new Runnable() {
@Override
public void run() {
try {
for (int j=0;j<10;j++){
request();
}
}catch (InterruptedException e){
e.printStackTrace();
}finally {
countDownLatch.countDown();
}
}
});
thread.start();
}
countDownLatch.await();
long endTime=System.currentTimeMillis();
System.out.println(Thread.currentThread().getName()+"耗时:"+(endTime-startIime+" count:"+count));
}
}
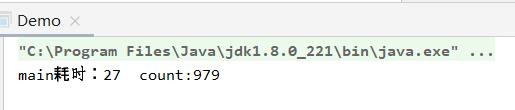
我们可以看到,代码中总共有一千次的循环,按理来说,最后的count应该是1000,但是,最后的答案却不是1000,这是为什么呢?
其实count++ 这一行代码一共有三步操作:
- 1.获取count的值,记做A : A=count
- 2.将A值+1,得到B :B=A+1
- 3.将B值赋值给count
那么,如果有A.B两个线程同时执行count++,他们通知执行到上面步骤的第一步,得到的count是一样的,3步操作结束后,count只加了1,导致count结果不正确,那么,我们是否可以在A=count这里一步把它锁住呢?
我们来写下一段代码
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.TimeUnit;
public class Demo2 {
static int count=0;
public synchronized static void request() throws InterruptedException {
TimeUnit.MICROSECONDS.sleep(5);
count++;
}
public static void main(String[] args) throws InterruptedException {
long startIime=System.currentTimeMillis();
int threadSize=100;
CountDownLatch countDownLatch=new CountDownLatch(threadSize);
for (int i=0;i<threadSize;i++){
Thread thread=new Thread(new Runnable() {
@Override
public void run() {
try {
for (int j=0;j<10;j++){
request();
}
}catch (InterruptedException e){
e.printStackTrace();
}finally {
countDownLatch.countDown();
}
}
});
thread.start();
}
countDownLatch.await();
long endTime=System.currentTimeMillis();
System.out.println(Thread.currentThread().getName()+"耗时:"+(endTime-startIime+" count:"+count));
}
}
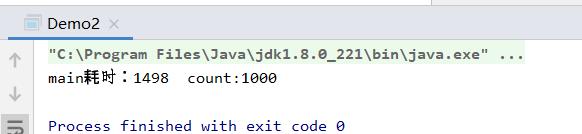
在这里我们用**synchronized 修饰了方法,但是,我们发现修饰后需要的时间大大上升,这是因为被synchronized **修饰后,synchronized关键字会让没有得到锁资源的线程进入BLOCKED状态,而后在争夺到锁资源后恢复为RUNNABLE状态,这个过程中涉及到操作系统用户模式和内核模式的转换,代价比较高。
尽管JAVA 1.6为synchronized做了优化,增加了从偏向锁到轻量级锁再到重量级锁的过过度,但是在最终转变为重量级锁之后,性能仍然比较低。所以面对这种情况,我们就可以使用java中的“原子操作类”。
我们来再写一段代码
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.TimeUnit;
public class Demo3 {
static int count=0;
public static void request() throws InterruptedException {
TimeUnit.MICROSECONDS.sleep(5);
int expectCount;
while(!compareAndSwap(expectCount=getCount(),expectCount+1)){
}
}
public static synchronized boolean compareAndSwap(int expectCount,int newCount){
if(getCount()==expectCount){
count=newCount;
return true;
}
return false;
}
public static int getCount(){return count;}
public static void main(String[] args) throws InterruptedException {
long startIime=System.currentTimeMillis();
int threadSize=100;
CountDownLatch countDownLatch=new CountDownLatch(threadSize);
for (int i=0;i<threadSize;i++){
Thread thread=new Thread(new Runnable() {
@Override
public void run() {
try {
for (int j=0;j<10;j++){
request();
}
}catch (InterruptedException e){
e.printStackTrace();
}finally {
countDownLatch.countDown();
}
}
});
thread.start();
}
countDownLatch.await();
long endTime=System.currentTimeMillis();
System.out.println(Thread.currentThread().getName()+"耗时:"+(endTime-startIime+" count:"+count));
}
}
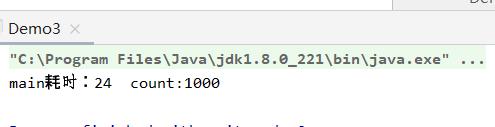
可以看到,这里消耗的时间很少,而且结果也是我们想要的1000
CAS机制
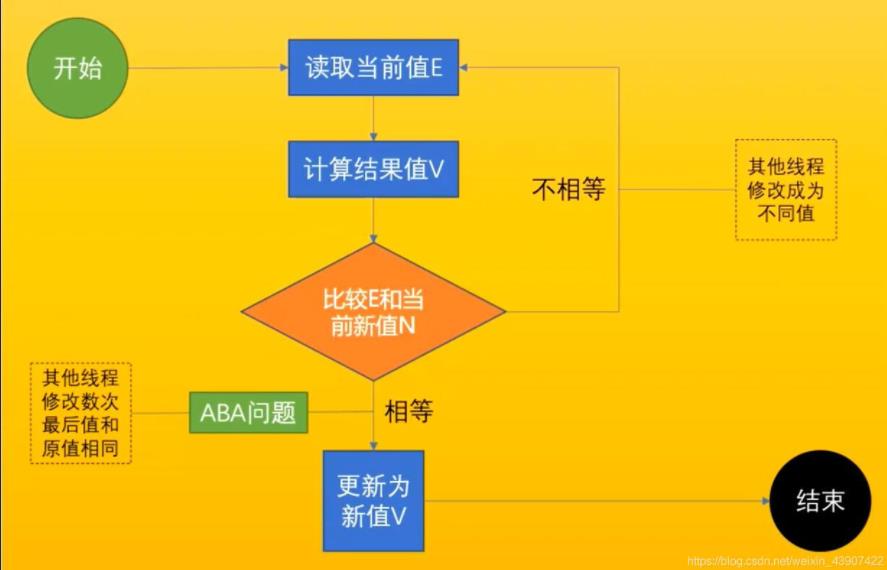
CAS机制全称compare and swap,翻译为比较并交换,是一种有名的无锁(lock-free)算法。也是一种现代 CPU 广泛支持的CPU指令级的操作,只有一步原子操作,所以非常快。而且CAS避免了请求操作系统来裁定锁的问题,直接在CPU内部就完成了,CAS机制当中使用了3个基本操作数:内存地址V,旧的预期值A,要修改的新值B。更新一个变量的时候,只有当变量的预期值A和内存地址V当中的实际值相同时,才会将内存地址V对应的值修改为B,这样说或许有些抽象,我们来看一个例子:
在内存地址V当中,存储着值为10的变量。

此时线程1想要把变量的值增加1。对线程1来说,旧的预期值A=10,要修改的新值B=11。
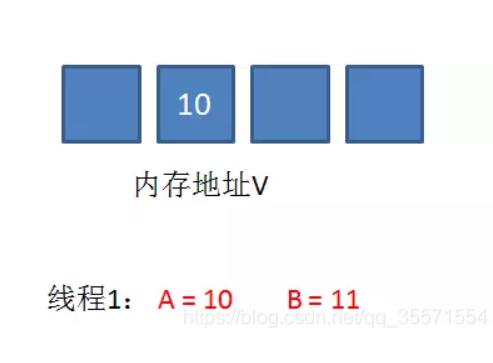
在线程1要提交更新之前,另一个线程2抢先一步,把内存地址V中的变量值率先更新成了11。
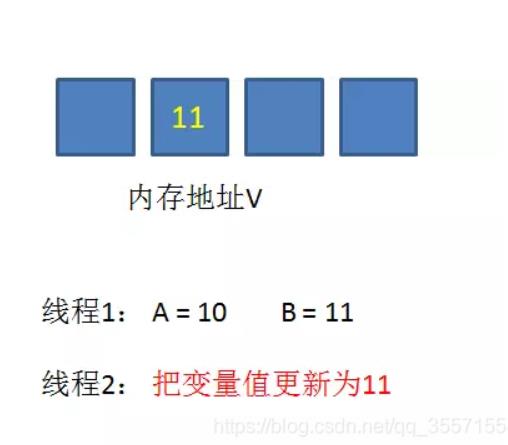
线程1开始提交更新,首先进行A和地址V的实际值比较(Compare),发现A不等于V的实际值,提交失败。

线程1重新获取内存地址V的当前值,并重新计算想要修改的新值。此时对线程1来说,A=11,B=12。这个重新尝试的过程被称为自旋。
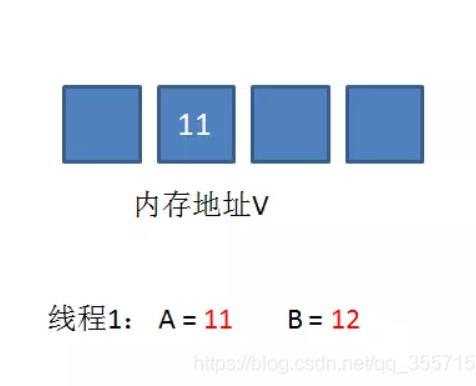
这一次比较幸运,没有其他线程改变地址V的值。线程1进行Compare,发现A和地址V的实际值是相等的。
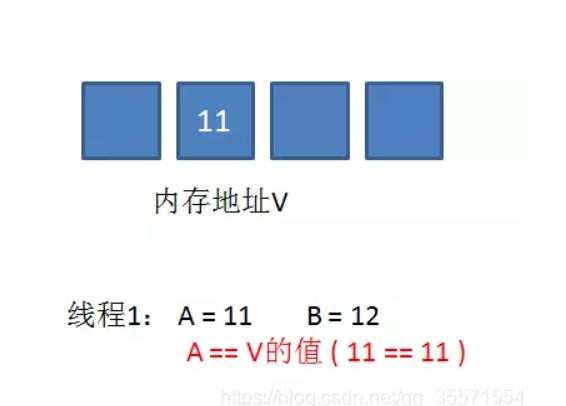
线程1进行SWAP,把地址V的值替换为B,也就是12。

CAS的缺点
1.CPU开销较大
在并发量比较高的情况下,如果许多线程反复尝试更新某一个变量,却又一直更新不成功,循环往复,会给CPU带来很大的压力。
2.不能保证代码块的原子性
CAS机制所保证的只是一个变量的原子性操作,而不能保证整个代码块的原子性。比如需要保证3个变量共同进行原子性的更新,就不得不使用Synchronized了。
因为它本身就只是一个锁住总线的原子交换操作啊。两个CAS操作之间并不能保证没有重入现象。
3.ABA问题
这是CAS机制最大的问题所在,什么是ABA呢?就是A变成了B又变成了A,我们来举个例子
假设内存中有一个值为A的变量,存储在地址V当中。
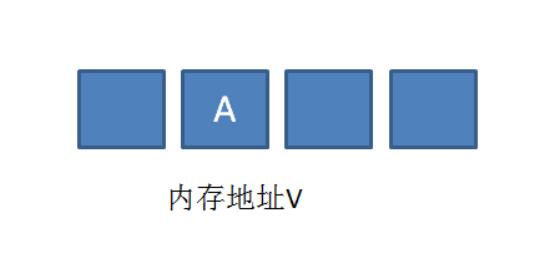
此时有三个线程想使用CAS的方式更新这个变量值,每个线程的执行时间有略微的偏差。线程1和线程2已经获得当前值,线程3还未获得当前值。

接下来,线程1先一步执行成功,把当前值成功从A更新为B;同时线程2因为某种原因被阻塞住,没有做更新操作;线程3在线程1更新之后,获得了当前值B。
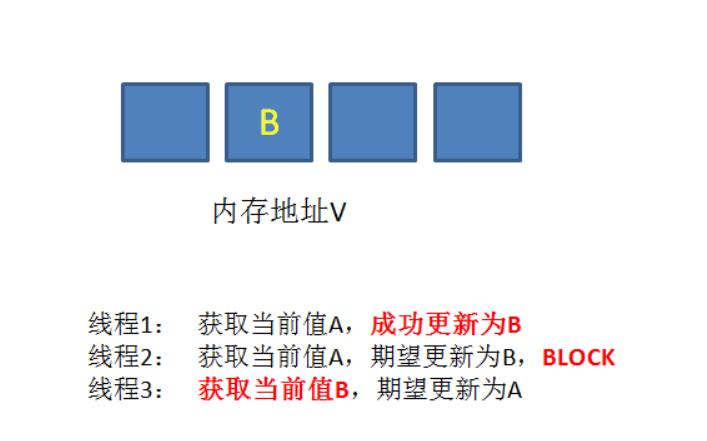
再之后,线程2仍然处于阻塞状态,线程3继续执行,成功把当前值从B更新成了A。

最后,线程2终于恢复了运行状态,由于阻塞之前已经获得了“当前值”A,并且经过compare检测,内存地址V中的实际值也是A,所以成功把变量值A更新成了B。

这样子看着好像也没有什么问题,那我们用一个实际的业务来举一个例子
- 小明的卡上有5000元,他去银行取2000块钱
- 这个时候因为某种故障,取钱的请求发出了两次
- 这个时候,小明的妈妈给他寄过去2000块钱
我们来分析一下结果
按照我们的想法,应该是第一个请求发出去,卡上就只有3000元了,这个时候另一个请求发过来,卡上变成5000元,然后被阻塞的请求失败,卡上还有5000元,但是事实不是这样的,结果是第三次请求又会扣除卡里2000元,这样,就出现了一个很大的问题。
如何应对ABA问题
其实也不是什么很难的问题,我们加一个版本号就行了,我们仍然以最初的例子来说明一下,假设地址V中存储着变量值A,当前版本号是01。线程1获得了当前值A和版本号01,想要更新为B,但是被阻塞了。
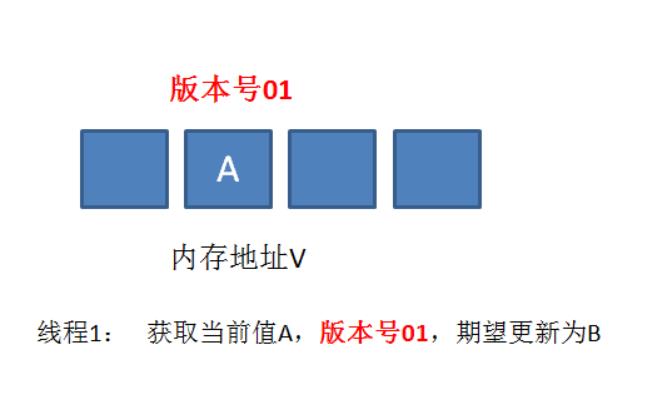
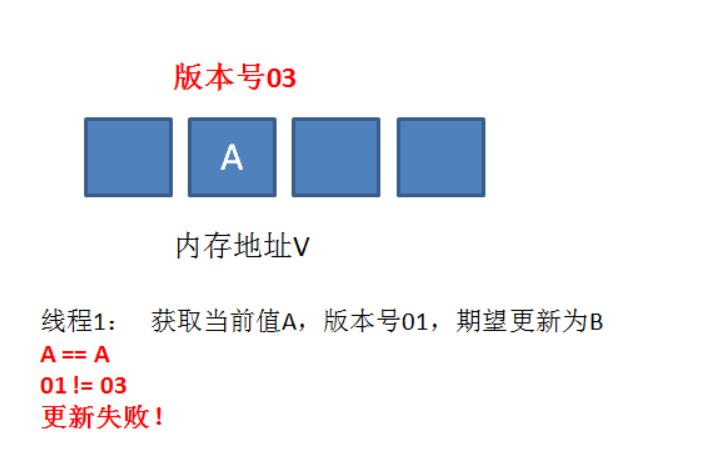
这时候,内存地址V中的变量发生了多次改变,版本号提升为03,但是变量值仍然是A。

随后线程1恢复运行,进行Compare操作。经过比较,线程1所获得的值和地址V的实际值都是A,但是版本号不相等,所以这一次更新失败。
在Java当中,AtomicStampedReference类就实现了用版本号做比较的CAS机制。
以上是关于JAVA并发基石——CAS的主要内容,如果未能解决你的问题,请参考以下文章