Python数据分析
Posted 雨宙
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python数据分析相关的知识,希望对你有一定的参考价值。
Python数据分析(二)
打卡第六天啦!!!
Numpy库(二)
NAN和INF值的认识
import numpy as np
data = np.random.randint(0,10,size=(3,5))
data = data.astype(np.float)
data[0,1] = np.NAN
print(data)
# [[ 0. nan 1. 2. 5.]
# [ 4. 2. 4. 4. 9.]
# [ 9. 4. 5. 9. 1.]]
print(data/0)
# [[nan nan inf inf inf]
# [inf inf inf inf inf]
# [inf inf inf inf nan]]
print(np.nan == np.nan)
# False
NAN和INF值的处理
- NAN: Not A Number的简写,不是一个数字,但是他是属于浮点类型。
- INF:无穷大,在除数为0的情况下会出现INF。
- NAN和所有的值进行计算结果都是等于NAN
- NAN !=NAN
- 可以通过np.isnan来判断某个值是不是NAN。
- 处理值的时候,可以通过删除NAN的形式进行处理,也可以通过值的替换进行处理。
- np.delete比较特殊,他通过axis=0来代表行,而其他大部分函数是通过axis=1来代表行。
# 删除缺失值
print(data)
# [[ 4. nan 9. 1. 8.]
# [ 2. 9. nan 9. 0.]
# [ 0. 2. 1. 6. 8.]]
np.isnan(data)
# array([[False, True, False, False, False],
# [False, False, True, False, False],
# [False, False, False, False, False]])
print(data[~np.isnan(data)])
# [4. 9. 1. 8. 2. 9. 9. 0. 0. 2. 1. 6. 8.]
# 替换缺失值
# 使用0替换缺失值
scores = np.loadtxt("scores.csv",dtype=np.str,delimiter=",",skiprows=1)
scores = scores.astype('U3')
scores[scores == ""] = np.NAN
scores1 = scores.astype(np.float)
scores1[np.isnan(scores1)] = 0
scores1.sum(axis=0)
# 使用平均数替换缺失值
scores2 = scores.astype(np.float)
for x in range(scores2.shape[1]):
col = scores2[:,x]
non_nan_col = col[~np.isnan(col)]
mean = non_nan_col.mean()
col[np.isnan(col)] = mean
pass
print(scores2)
# [[81. 76. ]
# [75.70588235 84. ]
# [90. 72.38888889]
# [72. 50. ]
# [57. 89. ]
# [76. 78. ]
# [67. 77. ]
# [89. 84. ]
# [73. 90. ]
# [76. 59. ]
# [61. 75. ]
# [85. 78. ]
# [83. 72.38888889]
# [81. 91. ]
# [40. 14. ]
# [83. 61. ]
# [75.70588235 98. ]
# [75.70588235 91. ]
# [88. 84. ]
# [85. 24. ]]
random模块
import numpy as np
np.random.seed(1)
np.random.rand()
# 0.417022004702574
np.random.rand(2,3)
# array([[7.20324493e-01, 1.14374817e-04, 3.02332573e-01],
# [1.46755891e-01, 9.23385948e-02, 1.86260211e-01]])
np.random.randn()
# -1.1059350760083153
data = np.arange(5)
np.random.choice(data,size=(3,4))
# array([[2, 0, 4, 1],
# [2, 2, 1, 0],
# [1, 3, 4, 3]])
np.random.choice(5,3)
# array([4, 3, 4])
data1 = np.arange(10)
print(data1)
np.random.shuffle(data1)
print(data1)
# [0 1 2 3 4 5 6 7 8 9]
# [6 2 3 0 1 9 5 8 7 4]
axis轴理解
- 最外面的括号代表着axis=0,依次往里的括号对应的axis的计数就依次加1
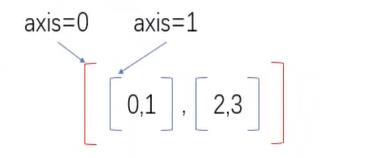
- 操作方式:如果指定轴进行相关的操作,那么他会使用轴下的每个直接子元素的第0个、第1个、第2个…分别进行相关操作,以上图为例,当axis=0时,对应(0,2)和(1,3),当axis=1时,对应(0,1)和(2,3)。
a = np.arange(0,4).reshape(2,2)
print(a)
# [[0 1]
# [2 3]]
print(a.sum(axis=0)) # [2 4]
print(a.sum(axis=1)) # [1 5]
print(a.max(axis=0)) # [2 3]
print(a.max(axis=1)) # [1 3]
y = np.arange(24).reshape(2,2,6)
print(y)
# [[[ 0 1 2 3 4 5]
# [ 6 7 8 9 10 11]]
# [[12 13 14 15 16 17]
# [18 19 20 21 22 23]]]
y.max(axis=0)
# array([[12, 13, 14, 15, 16, 17],
# [18, 19, 20, 21, 22, 23]])
y.max(axis=1)
# array([[ 6, 7, 8, 9, 10, 11],
# [18, 19, 20, 21, 22, 23]])
y.max(axis=2)
# array([[ 5, 11],
# [17, 23]])
- np.delete是直接删除指定轴下的第几个直接子元素
b = np.delete(a,0,axis=0)
print(b)
# [[2 3]]
通用函数
一元函数
a = np.random.uniform(-10,10,size=(3,5))
print(a)
# [[ 1.02649882 -8.59837008 -0.55049924 4.8552966 -6.16087844]
# [-0.71376993 -5.39274383 0.16495075 -5.82863377 -9.0139151 ]
# [ 0.37723752 -6.55443296 -2.07373425 -7.85269394 0.19620556]]
np.abs(a)
# array([[1.02649882, 8.59837008, 0.55049924, 4.8552966 , 6.16087844],
# [0.71376993, 5.39274383, 0.16495075, 5.82863377, 9.0139151 ],
# [0.37723752, 6.55443296, 2.07373425, 7.85269394, 0.19620556]])
np.sqrt(np.abs(a))
# array([[1.01316278, 2.93229775, 0.74195636, 2.20347376, 2.48211169],
# [0.84484906, 2.3222282 , 0.40614129, 2.41425636, 3.00231829],
# [0.61419664, 2.56016268, 1.44004661, 2.80226586, 0.44295097]])
np.square(a)
# array([[1.05369984e+00, 7.39319680e+01, 3.03049413e-01, 2.35739051e+01,
# 3.79564231e+01],
# [5.09467517e-01, 2.90816860e+01, 2.72087504e-02, 3.39729716e+01,
# 8.12506655e+01],
# [1.42308144e-01, 4.29605914e+01, 4.30037374e+00, 6.16648021e+01,
# 3.84966231e-02]])
np.exp(a)
# array([[2.79127596e+00, 1.84406116e-04, 5.76661846e-01, 1.28418775e+02,
# 2.11039861e-03],
# [4.89794221e-01, 4.54947320e-03, 1.17933504e+00, 2.94209382e-03,
# 1.21704436e-04],
# [1.45825063e+00, 1.42378999e-03, 1.25715451e-01, 3.88703412e-04,
# 1.21677700e+00]])
np.log(np.abs(a))
# array([[ 0.02615381, 2.15157266, -0.5969297 , 1.58007019, 1.81821937],
# [-0.33719459, 1.68505432, -1.80210833, 1.76278263, 2.19876951],
# [-0.97488027, 1.88014161, 0.72935097, 2.06085665, -1.62859238]])
np.sign(a)
# array([[ 1., -1., -1., 1., -1.],
# [-1., -1., 1., -1., -1.],
# [ 1., -1., -1., -1., 1.]])
np.ceil(a)
# array([[ 2., -8., -0., 5., -6.],
# [-0., -5., 1., -5., -9.],
# [ 1., -6., -2., -7., 1.]])
np.floor(a)
# array([[ 1., -9., -1., 4., -7.],
# [ -1., -6., 0., -6., -10.],
# [ 0., -7., -3., -8., 0.]])
# 四舍五入
np.rint(a)
# array([[ 1., -9., -1., 5., -6.],
# [-1., -5., 0., -6., -9.],
# [ 0., -7., -2., -8., 0.]])
# 分隔整数和小数部分
np.modf(a)
# (array([[ 0.02649882, -0.59837008, -0.55049924, 0.8552966 , -0.16087844],
# [-0.71376993, -0.39274383, 0.16495075, -0.82863377, -0.0139151 ],
# [ 0.37723752, -0.55443296, -0.07373425, -0.85269394, 0.19620556]]),
# array([[ 1., -8., -0., 4., -6.],
# [-0., -5., 0., -5., -9.],
# [ 0., -6., -2., -7., 0.]]))
np.sin(a)
# array([[ 0.85549127, -0.73550238, -0.52311278, -0.98980607, 0.12200217],
# [-0.65468811, 0.77734954, 0.16420375, 0.43905944, -0.39940052],
# [ 0.36835364, -0.26793368, -0.87617026, -0.99999917, 0.19494911]])
二元函数
np.add(a,np.random.randint(0,5,size=(3,1)))
np.greater(a,0) # 求出所以大于0的数
# array([[ True, False, False, True, False],
# [False, False, True, False, False],
# [ True, False, False, False, True]])
np.logical_and(a>0,a<5)
# array([[ True, False, False, True, False],
# [False, False, True, False, False],
# [ True, False, False, False, True]])
np.logical_or(a>5,a<0)
# array([[False, True, True, False, True],
# [ True, True, False, True, True],
# [False, True, True, True, False]])
聚合函数
# 计算元素的和
np.sum(a,axis=0)
# array([ 0.68996641, -20.54554687, -2.45928274, -8.82603111,
# -14.97858798])
# 计算元素的积
np.prod(a,axis=0)
# array([-2.76395892e-01, -3.03921238e+02, 1.88305984e-01, 2.22229242e+02,
# 1.08960082e+01])
# 计算元素的平均值
np.mean(a,axis=0)
# array([ 0.2299888 , -6.84851562, -0.81976091, -2.94201037, -4.99286266])
# 计算元素的标准差
np.std(a,axis=0)
# array([0.71805082, 1.32510965, 0.93356093, 5.57510549, 3.84965594])
# 计算元素的方差
np.var(a,axis=0)
# array([ 0.51559698, 1.75591558, 0.87153601, 31.08180126, 14.81985088])
# 计算元素的最小值
np.min(a,axis=0)
# array([-0.71376993, -8.59837008, -2.07373425, -7.85269394, -9.0139151 ])
# 找出最小值的索引
np.argmin(a,axis=0)
# array([1, 0, 2, 2, 1], dtype=int64)
布尔判断函数
只要有一个元素为0,则all方法就返回False,只要有一个元素不为0,则any方法就返回True
b = np.arange(0,10)
b.all() #False
b.any() #True
排序
np.sort(a)
# array([[-8.59837008, -6.16087844, -0.55049924, 1.02649882, 4.8552966 ],
# [-9.0139151 , -5.82863377, -5.39274383, -0.71376993, 0.16495075],
# [-7.85269394, -6.55443296, -2.07373425, 0.19620556, 0.37723752]])
np.sort(a,axis=0)
# array([[-0.71376993, -8.59837008, -2.07373425, -7.85269394, -9.0139151 ],
# [ 0.37723752, -6.55443296, -0.55049924, -5.82863377, -6.16087844],
# [ 1.02649882, -5.39274383, 0.16495075, 4.8552966 , 0.19620556]])
np.argsort(a)
# array([[1, 4, 2, 0, 3],
# [4, 3, 1, 0, 2],
# [3, 1, 2, 4, 0]], dtype=int64)
np.argsort(a,axis=0)
# array([[1, 0, 2, 2, 1],
# [2, 2, 0, 1, 0],
# [0, 1, 1, 0, 2]], dtype=int64)
# 降序排序
-np.sort(-a)
# array([[ 4.8552966 , 1.02649882, -0.55049924, -6.16087844, -8.59837008],
# [ 0.16495075, -0.71376993, -5.39274383, -5.82863377, -9.0139151 ],
# [ 0.37723752, 0.19620556, -2.07373425, -6.55443296, -7.85269394]])
indexes = np.argsort(-a)
np.take(a,indexes)
# array([[ 4.8552966 , 1.02649882, -0.55049924, -6.16087844, -8.59837008],
# [-0.55049924, 1.02649882, -8.59837008, 4.8552966 , -6.16087844],
# [ 1.02649882, -6.16087844, -0.55049924, -8.59837008, 4.8552966 ]])
其他函数
c = np.random.randint(0,100,size=(3,20))
np.apply_along_axis(lambda x:x[np.logical_and(x!=x.max(),x!=x.min())].mean(),axis=1,arr=c)
# array([52.61111111, 47.5 , 52.61111111])
np.linspace(0,10,9)
# array([ 0. , 1.25, 2.5 , 3.75, 5. , 6.25, 7.5 , 8.75, 10. ])
d = np.random.randint(0,10,size=(3,5))
np.unique(d)
# array([0, 2, 3, 4, 5, 6, 7, 8, 9])
np.unique(d,return_counts=True)
# (array([0, 2, 3, 4, 5, 6, 7, 8, 9]),
# array([1, 1, 1, 1, 4, 1, 2, 2, 2], dtype=int64))
pandas库(一)
介绍
- 强大的分析结构化数据的工具集
- 基础是Numpy,提供了高性能矩阵的运算
- 应用于数据挖掘,数据分析
- 提供数据清洗功能
# 导入
import pandas as pd
Series
Series介绍
- 一维标记的数组型对象
- 由数据和索引组成
Series创建
- 通过list创建
# 通过list创建
s1 = pd.Series([1,2,3,4,5])
print(s1)
# 0 1
# 1 2
# 2 3
# 3 4
# 4 5
# dtype: int64
print(type(s1))
# <class 'pandas.core.series.Series'>
- 通过数组创建
# 通过数组创建
import numpy as np
arr1 = np.arange(1,6)
s2 = pd.Series(arr1)
print(s2)
# 0 1
# 1 2
# 2 3
# 3 4
# 4 5
# dtype: int32
# 指定索引
s3 = pd.Series(arr1,index=['a','b','c','d','e'])
print(s3)
# a 1
# b 2
# c 3
# d 4
# e 5
# dtype: int32
- 通过字典创建
# 通过字典创建
dict = {'name':'潘小雷','age':20}
s4 = pd.Series(dict,index=['name','age'])
print(s4)
# name 潘小雷
# age 20
# dtype: object
Series基本用法
- isnull和notnull检查缺失值
s4.isnull() # 判断是否为空,如果为空则为True
# name False
# age False
# sex True
# dtype: bool
s4.notnull() # 判断是否不为空,非空状态为True
# name True
# age True
# sex False
# dtype: bool
- 通过索引获取数据
print(s4.index)
# Index(['name', 'age', 'sex'], dtype='object')
print(s4.values)
# ['潘小雷' 20 nan]
print(s4[0])
# 潘小雷
print(s4['name'])
# 潘小雷
print(s4[[0,2]])
# name 潘小雷
# sex NaN
# dtype: object
print(s4[0:1])
# name 潘小雷
# dtype: object
print(s4['name':'age']) # 与索引切片不同的是,标签切片包含末端数据,在此例子中表现为包含name
# name 潘小雷
# age 20
# dtype: object
# 布尔索引
print(s2[s2>3])
# 3 4
# 4 5
# dtype: int32
- 索引与数据的对应关系不被运算结果所影响
print(s2*2)
# 0 2
# 1 4
# 2 6
# 3 8
# 4 10
# dtype: int32
- name属性
s2.name = 'temp'
s2.index.name = 'year'
print(s2)
# year
# 0 1
# 1 2
# 2 3
# 3 4
# 4 5
# Name: temp, dtype: int32
- head方法和tail方法截取其中数据
s2.head(3) # 不传参数默认5,显示前5行
# year
# 0 1
# 1 2
# 2 3
# Name: temp, dtype: int32
s2.tail(3) # 不传参数默认5,显示后5行
# year
# 2 3
# 3 4
# 4 5
# Name: temp, dtype: int32
DataFrame
DataFrame介绍
- 表格型的数据结构
- 含有一组有序的列,每列可以是不同类型的值
- 既有行索引,也有列索引
- 可以看作是由Series组成的字典(并且共用一个索引)
DataFrame构建
- 字典类
(1)数组、列表或元组组成的字典构造DataFrame
data = {'a':[1,2,3,4],
'b':(5,6,7,8),
'c':np.arange(9,13)}
frame = pd.DataFrame(data)
print(frame)
# a b c
# 0 1 5 9
# 1 2 6 10
# 2 3 7 11
# 3 4 8 12
# index属性查看行索引
print(frame.index)
# RangeIndex(start=0, stop=4, step=1)
# columns属性查看列索引
print(frame.columns)
# Index(['a', 'b', 'c'], dtype='object')
# values查看值
print(frame.values)
# [[ 1 5 9]
# [ 2 6 10]
# [ 3 7 11]
# [ 4 8 12]]
# 指定行索引和列索引
frame = pd.DataFrame(data,index=['A','B','C','D'],columns=['a','b','c','d'])
print(frame)
# a b c d
# A 1 5 9 NaN
# B 2 6 10 NaN
# C 3 7 11 NaN
# D 4 8 12 NaN
(2)Series构成的字典构造DataFrame
# Series构成的字典构造DataFrame
pd1 = pd.DataFrame({'a':pd.Series(np.arange(3)),
'b':pd.Series(np.arange(3,5))})
print(pd1)
# a b
# 0 0 3.0
# 1 1 4.0
# 2 2 NaN
(3)字典构成的字典构造DataFrame
# 字典构成的字典构造DataFrame
# 字典嵌套
data1 = {'a':{'name':'潘小雷','age':20},
'b':{'name':'鲸鱼','age':20}}
pd2 = pd.DataFrame(data1)
print(pd2)
# a b
# name 潘小雷 鲸鱼
# age 20 20
- 列表类
(1)2D ndarray构造DataFrame
arr1 = np.arange(12).reshape(4,3)
frame1 = pd.DataFrame(arr1)
print(frame1)
# 0 1 2
# 0 0 1 2
# 1 3 4 5
# 2 6 7 8
# 3 9 10 11
(2)字典构成的列表构造DataFrame
li = [{'name':'潘小雷','age':20},
{'name':'鲸鱼','age':20}]
frame2 = pd.DataFrame(li)
print(frame2)
# name age
# 0 潘小雷 20
# 1 鲸鱼 20
(3)Series构成的列表构造DataFrame
list1 = [pd.Series([1,2,3]),pd.Series(np.random.rand(3))]
frame3 = pd.DataFrame(list1)
print(frame3)
以上是关于Python数据分析的主要内容,如果未能解决你的问题,请参考以下文章