分布式机器学习——模型并行训练
Posted Alex Hub
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分布式机器学习——模型并行训练相关的知识,希望对你有一定的参考价值。
首先还是来介绍一下分布式系统中的并行方式,分为数据并行和模型并行,其实还有一种并行方式:Pipeline并行。
Pipeline并行方式有的时候会单独存在,有的时候又归为模型并行。这篇文章重点就介绍一下模型并行,关于Pipeline并行也会简单介绍一下。
MXNet框架的创始人李沐在知乎上举了一个例子:假设我们准备盖这么一个双子楼,有两个工程队,我有两个选择,① 两个工程队各盖一栋,从建造到装修全部完成,最后把两栋楼连起来;② 第一个工程队先把两栋楼都盖好,第二个工程队负责装修。

第一个方案的好处是并行度高,但是要求两个工程队既要懂建筑又要懂装修,第二个方案要求低,一个会建筑一个会装修就行了,但是坏处是存在第一个工程队在干活的时候第二个工程队在摸鱼。
对应到数据并行和模型并行的概念的话,第一种方案就是数据并行,每个CPU既要加载数据又要训练模型,第二种方案就是模型并行,技能要求可以简单看成是对内存的需求,当模型很大不能装进单机内存或者单GPU显存的时候,一般就得用模型并行,不然用数据并行,因为通常会更快一些。
不过模型并行的并行程度并没有第二种方案中说的那么低,比如对于深度神经网络来说,可以把每一层楼都理解为神经网络的一层,这时候就可以理解Pipeline并行了,也就是流水线盖楼:
第1天:1队盖第1层
第2天:1队盖第2层,2队装修第1层
第3天:1队盖第3层,2队装修第2层
……
数据并行回顾
然后我们来简单回顾一下数据并行,数据并行一般最常用,只要模型能装到CPU或者GPU就可行,因为数据并行基本上都是通过minibatch,所有的节点算一个平均的梯度。
从数学的角度来讲,数据并行就是有效的,我们要通过损失Loss对参数w求梯度,xi和yi表示样本i的特征和标签,f(xi, yi)就是通过前向传播计算的样本i的预测值和真实值的损失,一共有n个数据,就把损失累加求一个平均,然后通过梯度更新模型参数就可以了。

如果我们要把数据分配到k个节点上,每个节点分配的数据量为mk,其就是在每个worker上计算相应的梯度,当每个worker上的分配的数量相等的时候,最后提取的就是k个机器上的梯度平均和。

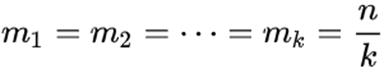
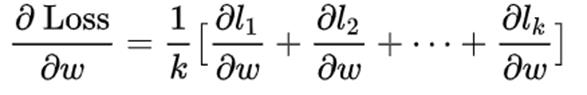
数据并行比较简单,容易实现,需要解决的主要问题就是参数同步和信息过期的问题。
模型并行
简介
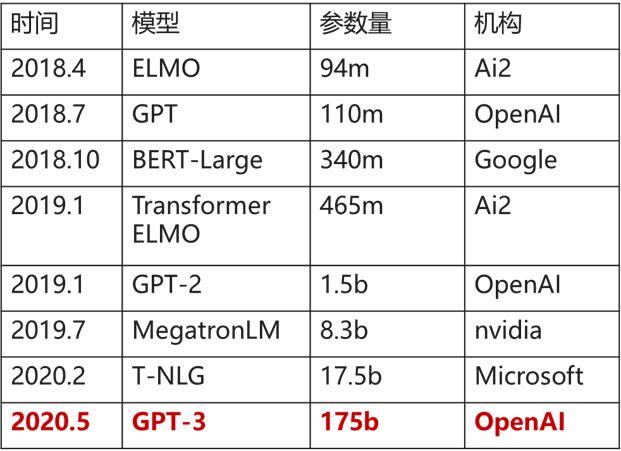
接下来介绍模型并行,因为现在的深度学习模型越来越大,从18年的ELMO有94M参数,到20年的GPT3有175b参数,差不多1750亿参数量,也就是说一个模型就700G,(我电脑都没有700G),所以一台机器根本训练不了,必须用分布式模型训练。
关于模型并行一篇比较经典的论文就是《Large Scale Distributed Deep Networks》,这是Google在2012年的时候就已经发的论文了,这篇论文里提出了一个DistBelief框架,这个框架也是TensorFlow的前身,Google Brain的第一代机器学习系统,主要解决的就是怎么通过数万个CPU核训练具有数十亿参数的深度网络的问题。
因为深度学习的计算其实主要就是矩阵计算,计算的时候矩阵都是保存在内存里的,但是有的时候矩阵会非常大。比如在CNN中如果num_classes达到千万级别的话,那一个FC层用到的矩阵对于普通的电脑来说可能就会大到塞不下,这时候就可以把超大矩阵拆分到不同的卡或者不同的机器上计算,从计算的过程来说是把矩阵做了分块处理,从模型的角度来说就是把网络结构做切分。
切分的方式就分为两种了,一种是水平切分,另一种是垂直切分,模型并行和Pipeline并行的区别就在这,有的人认为不管是水平切还是垂直切都是模型并行,有的人认为水平切才叫模型并行,垂直切叫Pipeline并行,因为垂直切分模型的时候,中间的某一层计算需要上一层所有的数据都计算完才能开始自己的计算,如果有数据未完成,整个计算都会延迟。

分布式并行训练需要着重考虑的一个问题就是通信开销,模型并行带来的通信开销和同步消耗会远超过数据并行,因为数据并行只需要不同设备之间传递一个梯度就可以了,但是模型并行需要在不同设备之间传递feature map,这俩都不是一个量级的,所以模型并行一般只用于单机内存无法容纳的大模型使用,并且具有局部连接结构的模型比全连接结构更适合模型并行,因为通信需求比较低。比如AlexNet只在最后全连接的时候有交互,Wide&Deep、DeepFM、ESMM都是类似双塔模型,只在最后有交互。
AlexNet
有的时候数据并行和模型并行会被同时用上,比如在AlexNet中,就是用了两个GPU,只不过当初是因为硬件设备不达标,所以不得以做了模型并行,上下两个网络卷积层的结构是一样的,数据并行进行计算,GPU只在全连接层进行通信。

所以我在想后面如果Wide&Deep的参数维度很大并且要调整全连接层的时候,能不能也采取这种方式,Wide侧和Deep侧分别放在不同的卡上,加速训练。因为单机双卡模型并行还是比较简单的,我这就提供了一个简单的用pytorch演示的模型并行,定义了两个线性层,只需要用to(device)就可以把两个线性层放在不同的GPU上,并且在调用损失函数的时候只需要确保标签和输出在同一个设备上就可以。
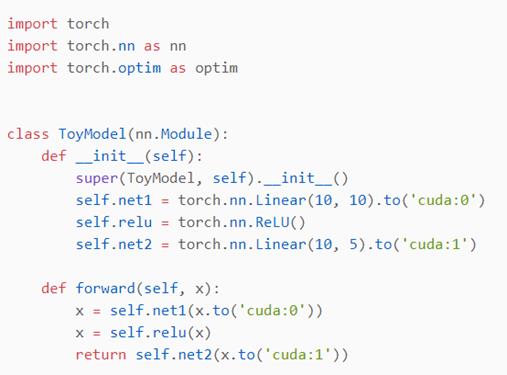

因为是单机,所以模型之间采用共享内存进行通信,如果是分布在通过网络连接的多台机器上,那么就需要考虑延迟、带宽和消息速率,这个就很复杂了,也是分布式训练着重要解决的问题。
模型并行要解决的一个问题就是神经网络中的每一层都对它前面一层具有数据依赖性,也就是说,仅仅把一些层放在不同的设备中并不意味着它们可以并行计算,甚至还有可能会起到相反的效果,当设备2等待设备1的数据的时候,设备2就处于空闲状态。
所以真正的模型并行,意味着把模型按照一种方式拆分之后,每个部分都可以同时进行计算,顺序无关紧要。
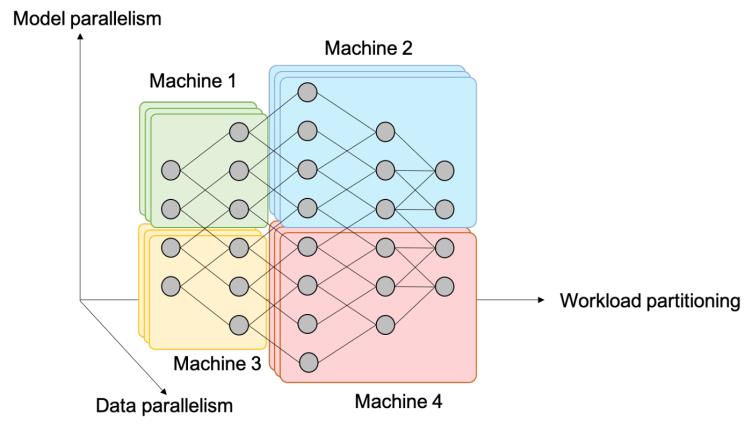
比如我们看这个图,Machine 1和Machine 3相当于把网络拆分成两层,它们两个大部分节点是可以并行计算的,Machine 2和Machine 4必须等待来自Machine 1和Machine 3的数据才能继续进行计算,反之亦然。
所以模型并行其实就是分配计算机资源的本能,涉及到的就是不同worker之间的消息传递,它不像数据并行那样把数据划分之后需要证明损失对参数求导依然有效,不过它的实现思想还是很有意思的,接下来就介绍一篇论文。
这是Google14年的时候就放在arXiv上的,作者就是AlexNet的作者,也就是他在12年提出了AlexNet之后,14年又提出了多GPU并行训练AlexNet的方法,搞了一波我优化我自己。
One weird trick for parallelizing convolutional neural networks
这篇论文主要是为了解决什么问题呢?他们发现,现代神经网络主要由两种层组成:
第一个是卷积层,卷积层包含了整个模型90-95%的计算量,但是只占有5%的参数量;
第二个是全连接层,全连接层包含整个模型5-10%的计算量,但是却占有95%的参数量;
我们可以看一下卷积层和全连接层的计算量和参数量的公式。计算量是通过FLOPs指标,表示浮点运算次数。

卷积层参数量:Co表示输出通道数,Ci表示输入通道数,kw表示卷积核宽,kh表示卷积核高,kw×kh×Ci表示一个卷积核的权重数量,+1表示bias
卷积层计算量:Ci×kw×kh表示一次卷积操作中乘法运算量,Ci×kw×kh-1表示一次卷积操作中加法运算量,+1表示偏置,Co×W×H表示feature map的所有元素数
全连接层参数量:I表示输入tensor的维度,O表示输出tensor的维度,对于第一个全连接层来说,它的输入tensor就是上一个卷积层flatten得到的向量,再加一个O表示bias
全连接层计算量:第一个I表示乘法运算量,第二个I-1表示加法运算量,第三个+1表示bias,×O表示计算O个神经元的值
卷积层的参数量少也就代表这部分模型比较小,占不了多少内存,所以可以做数据并行;
全连接层的参数量大也就表示这部分模型比较大,占的内存被较多,所以适合做模型并行;

所以作者就提出了一种混合并行训练卷积神经网络的方式,在卷积层采用数据并行,在全连接层采用模型并行。
假如我们有K个worker,模型由三个卷积层和两个全连接层组成。
每个worker在不同的batch data上训练相同的卷积层,但是全连接层会在相同的batch data上训练。
它具体是怎么做的呢?我们来看一下它的前向传播和反向传播的过程。


假如说我们有两个worker,在训练卷积层的时候,两个worker采用数据并行的策略,在训练全连接层的时候,两个worker采用模型并行的策略,它的大致步骤就分为6步:
- 卷积层数据并行前向传播
- Worker 1把卷积层的数据传递给全连接层,全连接层模型并行前向传播,2个全连接层是顺序执行的,FC11和FC12模型并行执行,FC21和FC22模型并行执行
- 全连接层反向传播,将梯度数据传回worker1卷积层
- Worker 2把卷积层的数据传递给全连接层前向传播
- 全连接层再反向传播,梯度数据传回worker2卷积层
- 卷积层反向传播
论文着重设计了卷积层向全连接层传播feature map的过程。
对于前向传播算法:
- K个worker中的每一个都提供不同的data batch,假如batch size=128,也就是说每个worker的数据是不一样的
- 每个worker都在data batch上计算卷积层,worker内卷积层是按照顺序执行的
- 卷积层向全连接层传递参数时,有三种方式:
- 每个worker把最后一个卷积层的输出通过激活函数之后传递给其它的worker,全连接层等待所有的worker,然后把128K个样本拼接成一个大的batch,最后在这个batch上计算全连接层。这种方式在计算全连接层的时候所有的worker都要暂停并且等待,而且把128K个样本拼成一个大batch也会消耗大量的显存;
- 每个worker把最后一个卷积层的输出通过激活函数之后传递给其它的worker,卷积层拿到这128个样本之后就直接计算全连接层,然后进行反向传播,与此同时可能下一个worker也把它的计算结果传递给全连接层,并行的进行计算。这种方式所有的worker轮流把卷积层的输出传播到所有的worker的全连接层,这样可以隐藏K-1次通信时间,做到pipeline并行的效果;
- 所有的worker发送128/K个卷积层的输出结果到其它的worker,然后计算方式同第2种。
对于反向传播算法:
- Worker按照正常的逻辑在全连接层计算梯度
- 按照前向传播中不同的实现方案,反向传播也有对应的3种方案:
- 每个worker都为128*K个样本组成的大batch计算梯度,然后每一个worker都将一个样本的梯度传递给前向传播中生成这个样本的worker上,然后卷积层继续反向传播
- 每个worker为一个data batch计算梯度,然后只把这个梯度传递给生成这个data batch的worker进行反向传播
- 也是跟第2种方案类似,每个worker计算128 个样本的梯度,这128个样本来自每一个worker的128/K,同样是按照从哪来回哪去的方式传播
我在看这篇论文的时候比较难理解的就是第三种方案,不太理解它这个128/K是怎么分隔传播的,论文里也没有具体的讲,直到后面我看另外的教程的时候发现了Ring All-Reduce算法。
Ring All-Reduce
举个例子,这种方法只有两个worker的时候不好演示,假设我们有4个worker,每个worker都算出各自的梯度,记为向量g,然后把每个梯度再切成四块,用abcd来表示。

最开始的时候每个worker都只知道自己的abcd切分向量,不知道别的worker的梯度向量。
我们的目的是在每个GPU上计算这些梯度的加和,也就是a0+a1+a2+a3+b0+b1+b2+b3+c0+c1+c2+c3+d0+d1+d2+d3

然后我们构建一个环形的通信,GPU0向GPU1传播,GPU1向GPU2传播,GPU2向GPU3传播,GPU3向GPU0传播,四个worker同时传输自己计算出来的梯度的一部分。

第一轮通信之后,每个worker可以得到一个其它worker的梯度数据。
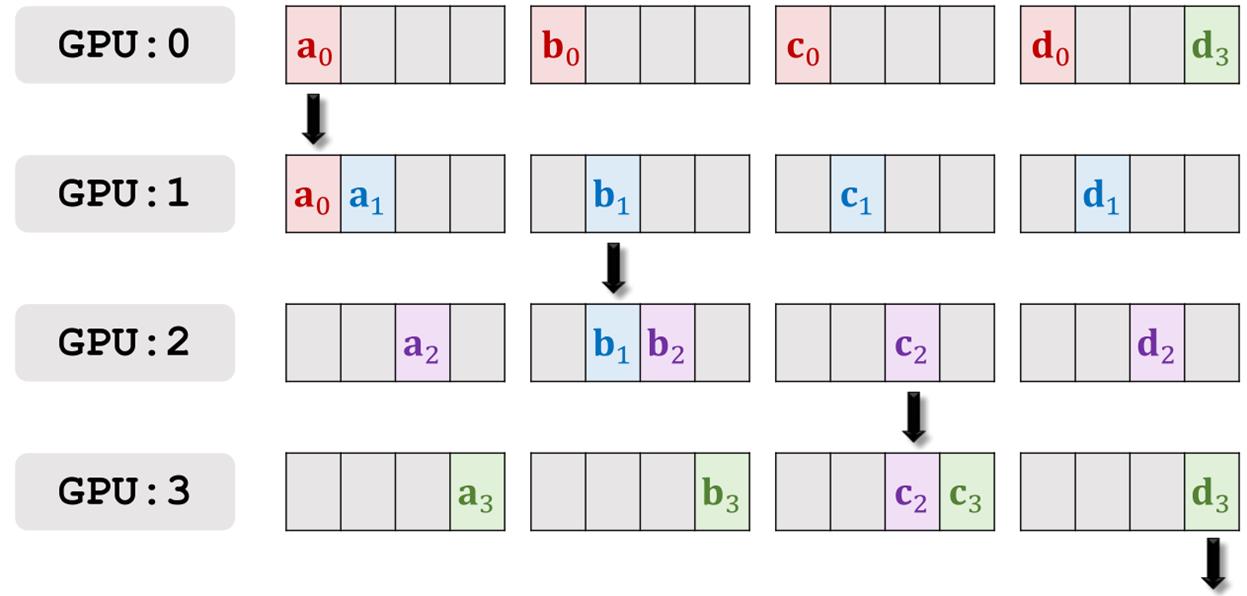
然后进行第二轮通信。
GPU1发送a0和a1的加和,只与GPU2通信一次,而不是a0和a1发送两次,以此类推,其它的GPU做的也是类似的操作。

第二轮通信结束后,每个worker可以得到三个其它worker的梯度数据。
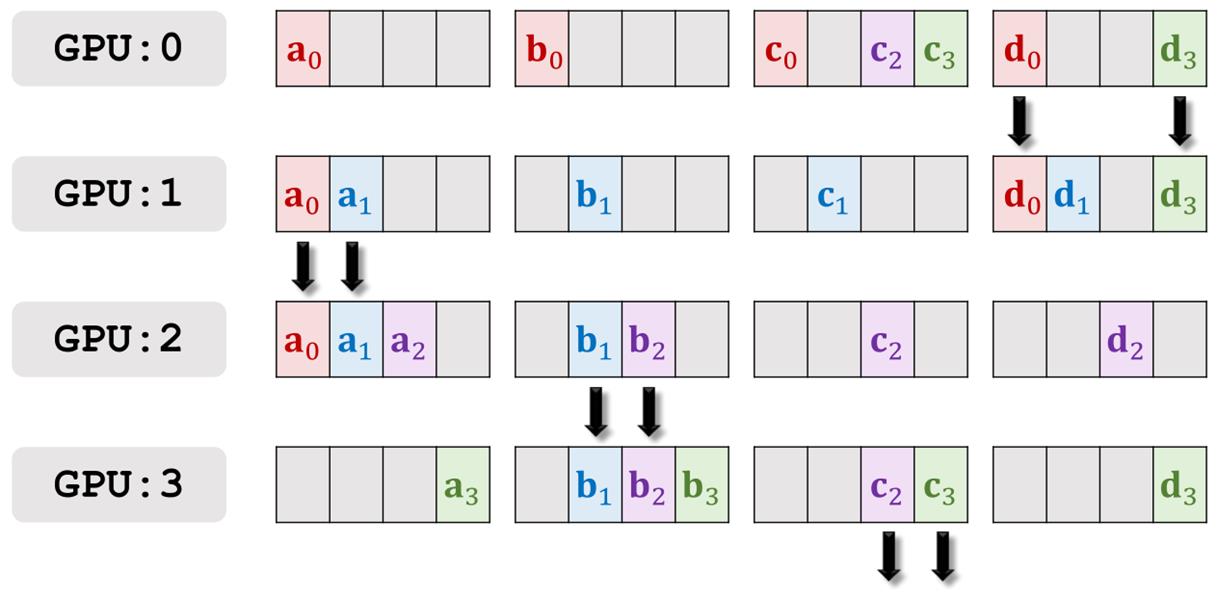
然后用同样的方法进行第三轮通信。

第三轮通信结束后,GPU3拥有了所有a的加和,GPU0拥有了所有b的加和,GPU1拥有了所有c的加和,GPU2拥有了所有d的加和。

然后进行第四轮通信,把所有拥有abcd四个加和的向量广播出去。

第四轮通信的结果。
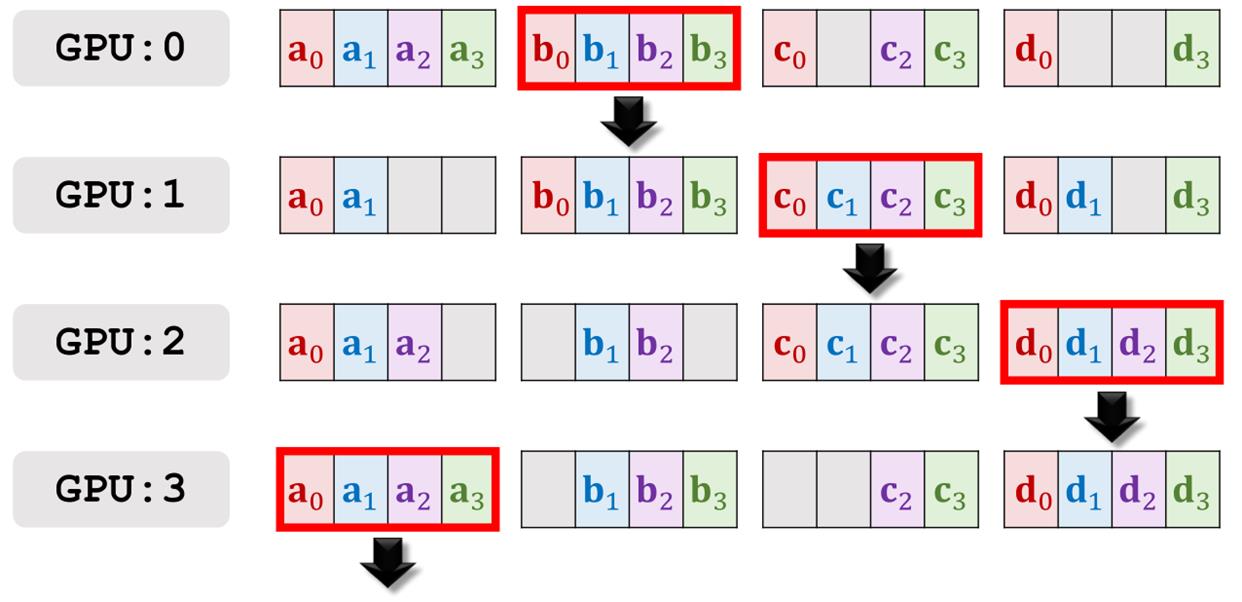
第五轮通信。
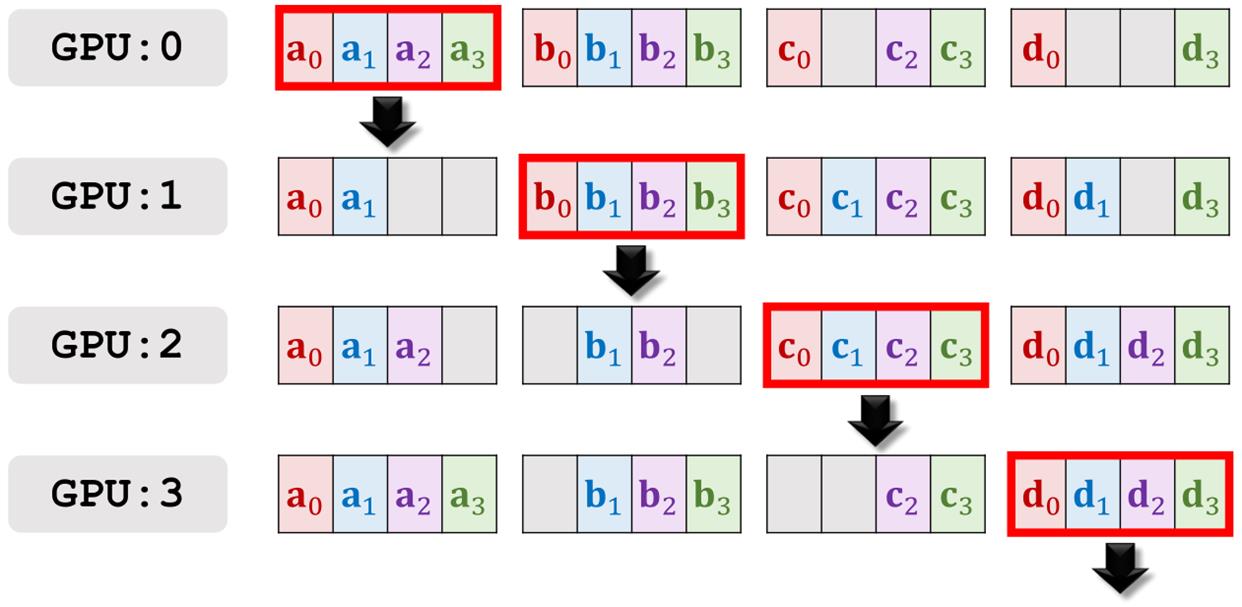
第五轮通信的结果。
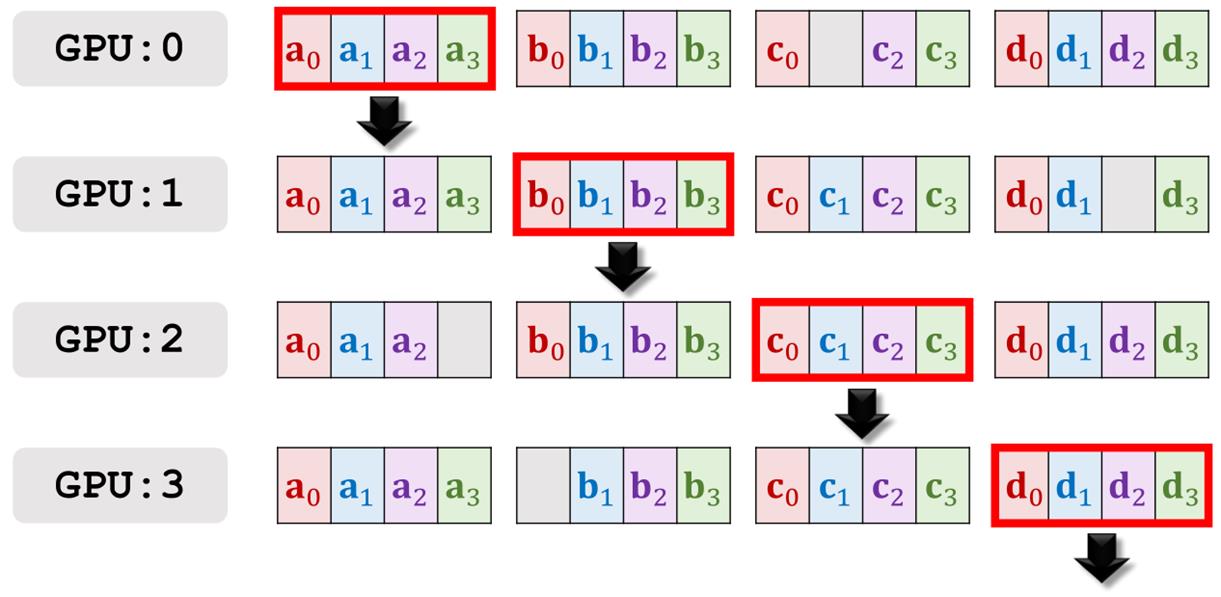
第六轮通信。
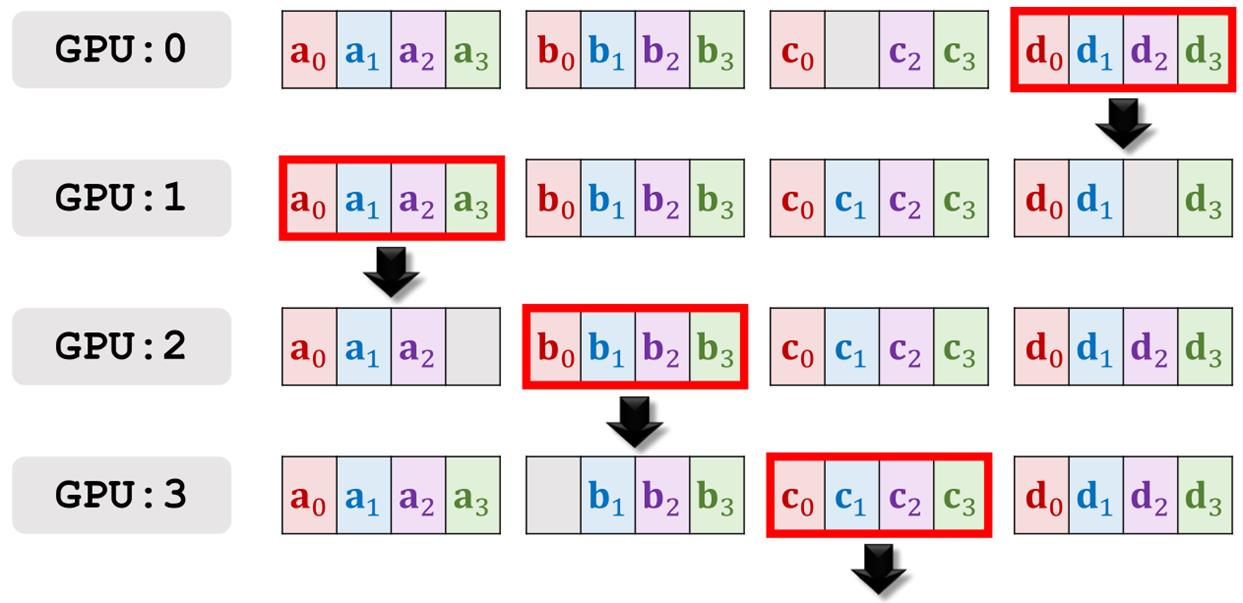
第六轮通信的结果。所有的GPU都拥有了四个梯度的加和,接下来分别做梯度下降来更新模型参数就可以了。
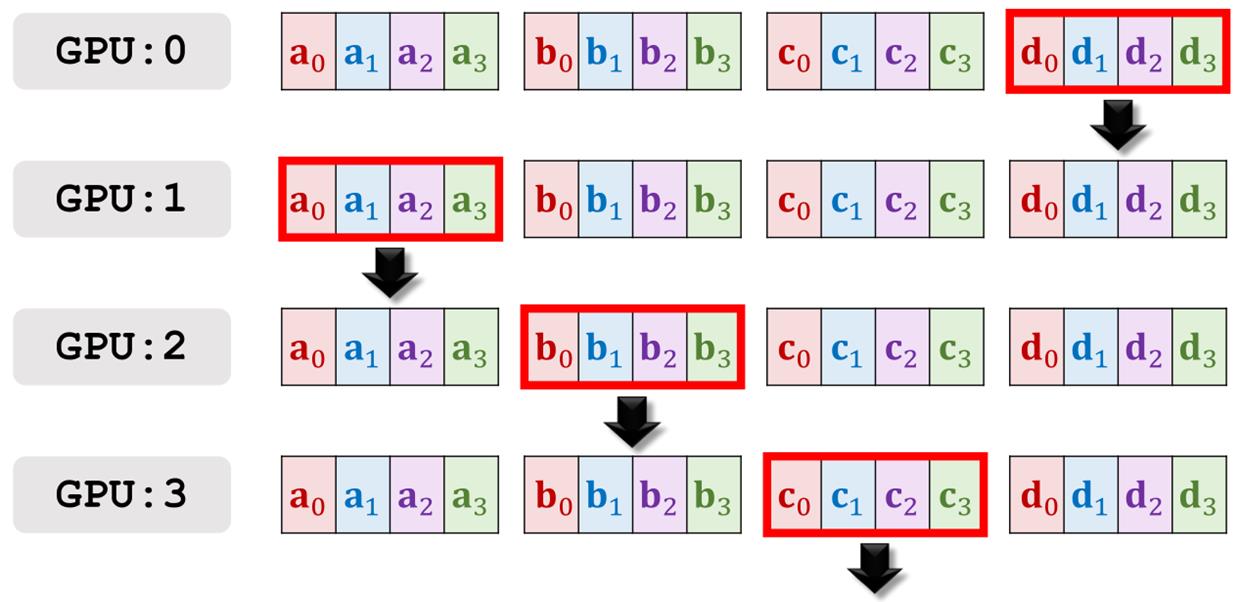
我猜测方式3采用的就是Ring All-Reduce这种方法进行通信的,这种方式跟第1种、第2种的一个优势就是通信和计算的比例是常数K,对于1和2来说通信和计算的比例与K成正比,这是因为方案1和2经常会受到每一个worker的输出带宽的限制,第3种方案可以利用所有的worker来完成传播任务。
感觉这种通信方式还是比较精妙的。
Variable Batch Size
我们回过来再来看一下第2种和第3种方案,虽然是对标准的前向传播和后向传播做了一些小小的修改,不过从根本上来说效果还是等同于batch size等于128*K的同步随机梯度下降的。
作者后面又研究了其它的改进方案,在全连接层进行前向传播和反向传播的时候,每次都是使用不同批次的128个样本,也就是说,其实可以没必要非得等K个批次全部完成前向传播和反向传播之后才更新权重,完全可以每完成一次前向传播和反向传播之后就更新,这样就不需要增加一些额外的计算成本了。
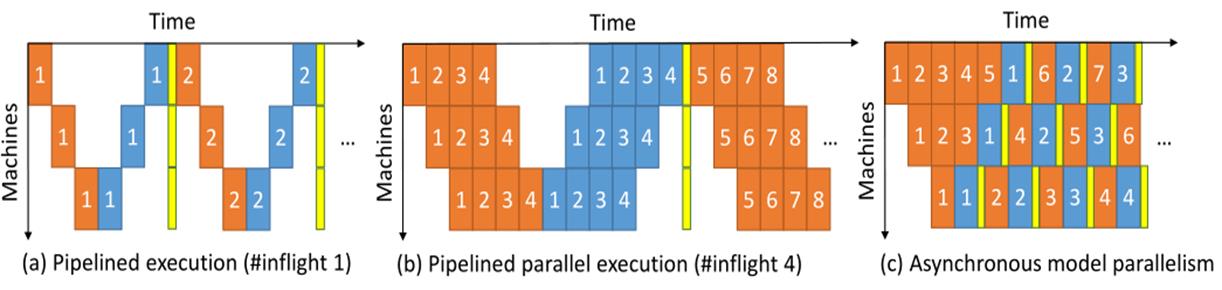
比如说我们看这个示意图,a表示我们把不同的层放在不同的机器上,然后让它们顺序执行,橙色表示前向传播,蓝色表示反向传播,黄色表示参数更新。
b图表示我们把不同的层放在不同的机器上之后采用pipeline并行,也就是我们一开始举的例子,两个工程队,第1天:1队盖第1层,第2天:1队盖第2层,2队装修第1层。
这两种并行方式我们可以发现还有大片的留白,这也就表示有机器处于空闲状态,并不能完全的利用机器资源。
c图表示的就是异步模型并行,在每个worker上执行完了一次反向传播之后就立即更新该worker上的模型参数,通过示意图我们可以发现,这种方式可以很充分的利用机器资源。
所以作者后来也采用了这种异步模型并行的方式,并且定义了一种叫可变batch size的方法,在全连接层使用的batch size为128,在卷积层使用的batch size为128*K。
下面这张图就是通过这种并行训练的方式训练AlexNet在ImageNet验证集上的错误率,作者测试了各种不同的batch size组合,前面的是卷积层的batch size,后面的是全连接层的batch size,对比试验损失值和错误率达到相同水平花费的时间和加速比。
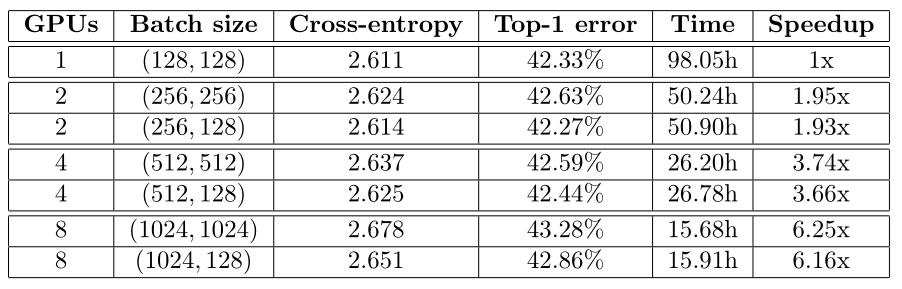
它的baseline是第1组,也就是采用1个GPU,batch size为(128, 128),训练花了90+小时。
第二组试验采用2块GPU,卷积层的batch size扩大了一倍,全连接层的batch size一个也扩大了一倍一个没变,首先可以发现使用增大了一倍的batch size是差不多加速了一倍的训练时间,其次可以发现全连接层的batch size虽然增大了一倍但是它的加速效果并没有卷积层batch size增大一倍带来的提升大。
后面的两组实验也是同样的结果,增加了GPU然后增大了batch size的大小,但是可以发现GPU也不是越多越好,本来我们用2块GPU的时候加速效果应该是1块GPU的两倍,考虑到通信成本之后可以发现其实也差不多能达到预期,4块GPU的时候预期加速效果应该是4被,但实际只有3.6-3.7倍,8块GPU的时候预期加速效果应该是8倍,但实际效果连7倍都没有,6.1-6.2倍,所以对于模型并行来说并不是GPU越多越好,通信成本太大了。
总结
总结一下
首先回顾了一下数据并行和模型并行的基本概念,并且知道模型并行根据是横着切还是竖着切可以分为模型并行和Pipeline并行。
然后介绍了一下DistBlief框架,这是谷歌最开始做的分布式训练框架,不过它重点介绍的也是数据并行的两种解决方案。
最后详细介绍了一下模型并行,原生的AlexNet其实就是模型并行,它的作者自己把它优化了一下,优化的思路其实很简单,就是在卷积层上采用数据并行,在全连接层上采用模型并行,这种方案比较适合双塔结构的模型,但是考虑到模型并行的通信成本,其实并不建议用太多机器。
以上是关于分布式机器学习——模型并行训练的主要内容,如果未能解决你的问题,请参考以下文章