计算机视觉PyTorch - 数据处理(库数据和训练自己的数据)
Posted Follwer
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了计算机视觉PyTorch - 数据处理(库数据和训练自己的数据)相关的知识,希望对你有一定的参考价值。
pytorch实现图像分类数据处理
1. pytorch库自带数据
为了更好的理解,这里以CIFAR10数据集作为训练和测试数据集。
我们将使用CIFAR10数据集,它包含十个类别:
[‘airplane’, ‘automobile’, ‘bird’, ‘cat’, ‘deer’, ‘dog’, ‘frog’, ‘horse’, ‘ship’, ‘truck’]。
CIFAR-10 中的图像尺寸为3x32x32,也就是RGB的3层颜色
通道,每层通道内的尺寸为32x32。

数据预处理
😃CIFAR10数据集的输出是范围在[0,1]之间的 PILImage,即对每个类别的概率分布情况。所以我们需要通过ToTensor()把图像灰度范围从(0-255)变换到(0-1)之间,并通过transform.Normalize()把(0-1)变换到(-1,1)
import torch
import torchvision
import torchvision.transforms as transforms
#定义三个通道的像素值 均值(mean)为0.5,方差(std)为0.5
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5,0.5,0.5),(0.5,0.5,0.5))])
数据生成
torchvision.datasets中包含了以下数据集
- MNIST
- COCO(用于图像标注和目标检测)(Captioning and Detection)
- LSUN Classification
- ImageFolder
- Imagenet-12
- CIFAR10 and CIFAR100
- STL10
数据生成函数:
class torchvision.datasets.CIFAR10(root='./data', train=True,
download=True, transform=transform)
参数说明:
- root:保存数据集的目录
- train:True= 训练集, False = 测试集
- download:True = 从互联网上下载数据集,并把数据集放在root目录下. 如果数据集之前下载过,就不用再重复下载。
- transform:对数据集预处理的函数
trainset = torchvision.datasets.CIFAR10(root='./data',train=True,download=True, transform=transform)
testset = torchvision.datasets.CIFAR10(root='./data',train=False,download=True, transform=transform)
数据加载
数据加载函数:
class torch.utils.data.DataLoader(dataset, batch_size=1, shuffle=False, sampler=None, num_workers=0, collate_fn=<function default_collate>, pin_memory=False, drop_last=False)
参数说明:
- dataset (Dataset):加载数据的数据集。
- batch_size (int, optional):每个batch加载多少个样本(默认: 1)。
- shuffle (bool, optional):设置为True时会在每个epoch重新打乱数据(默认: False).
- sampler (Sampler, optional):定义从数据集中提取样本的策略。如果指定,则忽略shuffle参数。
- num_workers (int, optional):用多少个子进程加载数据。0表示数据将在主进程中加载(默认: 0)
trainloader = torch.utils.data.DataLoader(trainset,batch_size=4,shuffle=True, num_workers=2)
testloader = torch.utils.data.DataLoader(testset,batch_size=4,shuffle=False, num_workers=2)
2. 训练自己的数据
由于pytorch库中的数据集包含的种类比较匮乏,我们在实际的应用中往往还会对其他的事物做图像分类,因此需要自己的数据集图像来训练,实现图像分类。
生成数据集
要想用自己的数据集进行图像分类或者其他计算机视觉应用,不是之前下载好图片,进行训练就行了🤣
首先第一步需要自己的图像数据集进行标注
标注图像需要用到标注工具,这里介绍一种最方便的:labelimg
安装labelimg,只需要在终端运行
pip install labelimg
之后在终端运行如下代码,即可开始对图像进行标注
(base) MacBook-Air ~ % labelimg
进行批量标注:
点击打开文件按钮可以打开需要被标注的图片的文件夹。
点击改变存放目录按钮可以打开标注文件存放的文件夹。
点击w快捷键可以开始标注,标注完后需要保存
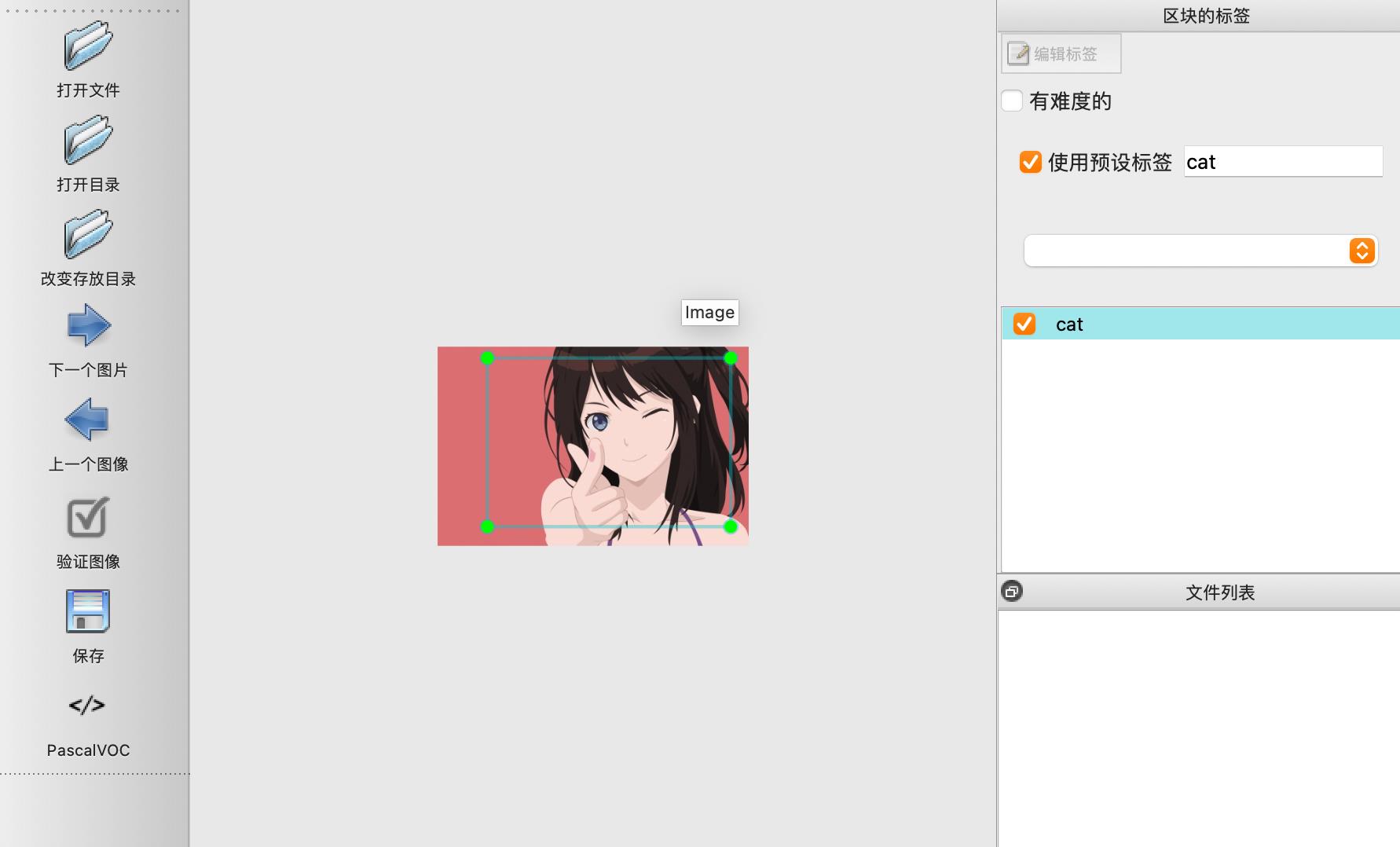
最后标注完成的图像,会生成一个标注文件xml格式。
数据预处理
接下来就是对标注后的图像进行预处理。
首先创建一个文件夹(这里按照官方的文件夹名字命名😂)
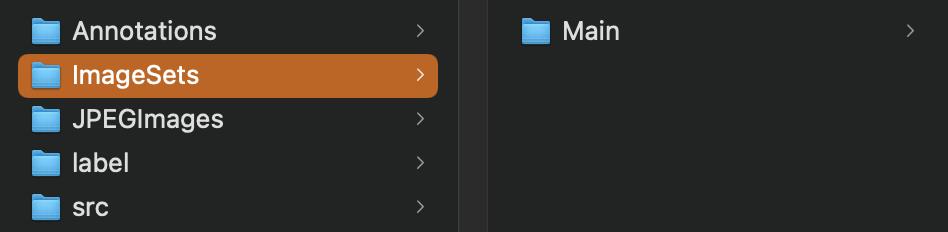
- Annotations:存放标注xml文件
- JPEGImages:存放图片
- ImageSets:存放一个名为Main文件夹,Main文件夹用来存放后续生成的train.txt,val.txt,test.txt、trainval.txt(也可以只有train.txt和test.txt,根据个人需求看是否需要验证集),这些文件保存的内容为图片的名字(没有后缀格式)
- src:存放后续生成的train.txt,val.txt,test.txt、trainval.txt,但这里的的文件内容是,对应每个图片的绝对路径+类别
- label:存放不同图像的标注文件(感觉这个文件没有用😂)
生成Main里的文件:
import os
import random
random.seed(0)
xmlfilepath='Annotations'
saveBasePath="ImageSets/Main/"
trainval_percent=1
train_percent=1
temp_xml = os.listdir(xmlfilepath)
total_xml = []
for xml in temp_xml:
if xml.endswith(".xml"):
total_xml.append(xml)
num=len(total_xml)
list=range(num)
tv=int(num*trainval_percent)
tr=int(tv*train_percent)
trainval= random.sample(list,tv)
train=random.sample(trainval,tr)
print("train and val size",tv)
print("traub suze",tr)
ftrainval = open(os.path.join(saveBasePath,'trainval.txt'), 'w')
ftest = open(os.path.join(saveBasePath,'test.txt'), 'w')
ftrain = open(os.path.join(saveBasePath,'train.txt'), 'w')
fval = open(os.path.join(saveBasePath,'val.txt'), 'w')
for i in list:
name=total_xml[i][:-4]+'\\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftrain.write(name)
else:
fval.write(name)
else:
ftest.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest .close()
生成src里的文件:
import xml.etree.ElementTree as ET
from os import getcwd
sets=['train','val','test','trainval']
classes = ['plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck']
def convert_annotation(image_id, list_file):
in_file = open('Annotations/%s.xml'%(image_id), encoding='utf-8')
tree=ET.parse(in_file)
root = tree.getroot()
for obj in root.iter('object'):
difficult = 0
if obj.find('difficult')!=None:
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult)==1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (int(float(xmlbox.find('xmin').text)), int(float(xmlbox.find('ymin').text)), int(float(xmlbox.find('xmax').text)), int(float(xmlbox.find('ymax').text)))
list_file.write(" " + ",".join([str(a) for a in b]) + ',' + str(cls_id))
wd = getcwd()
for image_set in sets:
image_ids = open('ImageSets/Main/%s.txt'%(image_set), encoding='utf-8').read().strip().split()
list_file = open('src/%s.txt'%(image_set), 'w', encoding='utf-8')
for image_id in image_ids:
list_file.write('JPEGImages/%s.jpg'%(image_id))
#这里写入的是图片的绝对路径
convert_annotation(image_id, list_file)
list_file.write('\\n')
list_file.close()
数据加载
from PIL import Image
import torch
import torchvision.transforms as transforms
class MyDataset(torch.utils.data.Dataset): # 创类:MyDataset,继承torch.utils.data.Dataset
def __init__(self, datatxt, transform=None):
super(MyDataset, self).__init__()
fh = open(datatxt, 'r') # 打开src中的txt文件,读取内容
imgs = []
for line in fh: # 按行循环txt文本中的内容
line = line.rstrip() # 删除本行string字符串末尾的指定字符
words = line.split() # 通过指定分隔符对字符串进行切片,默认为所有的空字符,包括空格、换行、制表符等
imgs.append((words[0], int(words[1]))) # 把txt里的内容读入imgs列表保存,words[0]是图片信息,words[1]是label
self.imgs = imgs
self.transform = transform
def __getitem__(self, index): # 按照索引读取每个元素的具体内容
fn, label = self.imgs[index] # fn是图片path
img = Image.open(fn).convert('RGB') # from PIL import Image
if self.transform is not None: # 是否进行transform
img = self.transform(img)
return img, label # return回哪些内容,在训练时循环读取每个batch,就能获得哪些内容
def __len__(self): # 它返回的是数据集的长度,必须有
return len(self.imgs)
'''标准化、图片变换'''
mean = [0.5071, 0.4867, 0.4408]
stdv = [0.2675, 0.2565, 0.2761]
train_transforms = transforms.Compose([
transforms.RandomCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize(mean=mean, std=stdv)])
train_data = MyDataset(datatxt='train.txt', transform=train_transforms)
train_loader = torch.utils.data.DataLoader(dataset=train_data, batch_size=64, shuffle=True)
以上是关于计算机视觉PyTorch - 数据处理(库数据和训练自己的数据)的主要内容,如果未能解决你的问题,请参考以下文章