大数据(8n)图解Spark行转列pivot数据透视表
Posted 小基基o_O
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据(8n)图解Spark行转列pivot数据透视表相关的知识,希望对你有一定的参考价值。
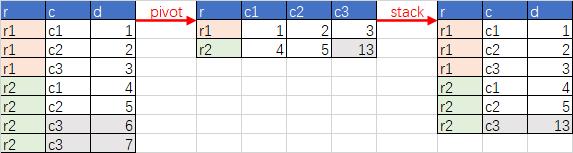
1、透视
1.1、SQL
SELECT * FROM t
PIVOT (SUM(d) FOR c IN ('c1' as c1,'c2'as c2,'c3' as c3));
1.2、Spark
import org.apache.spark.sql.SparkSession
import org.apache.spark.{SparkConf, SparkContext}
//创建SparkContext对象
val c0: SparkConf = new SparkConf().setAppName("a0").setMaster("local")
val sc: SparkContext = new SparkContext(c0)
//创建SparkSession对象
val c1: SparkConf = new SparkConf().setAppName("a1").setMaster("local")
val spark: SparkSession = SparkSession.builder().config(c1).getOrCreate()
//隐式转换支持
import spark.implicits._
//建多个表
sc.makeRDD(Seq(
("r1", "c1", 1),
("r1", "c2", 2),
("r1", "c3", 3),
("r2", "c1", 4),
("r2", "c2", 5),
("r2", "c3", 6),
("r2", "c3", 7),
)).toDF("r", "c", "d").createTempView("t")
//结果展示
spark.sql(
"""
|SELECT * FROM t
|PIVOT (SUM(d) FOR c IN ('c1' as c1,'c2'as c2,'c3' as c3));
|""".stripMargin).show()
2、逆透视
2.1、SQL
SELECT
r,
STACK(
3,
'c1',c1,
'c2',c2,
'c3',c3
) AS (c,d)
FROM t;
2.2、Spark
import org.apache.spark.sql.SparkSession
import org.apache.spark.{SparkConf, SparkContext}
//创建SparkContext对象
val c0: SparkConf = new SparkConf().setAppName("a0").setMaster("local")
val sc: SparkContext = new SparkContext(c0)
//创建SparkSession对象
val c1: SparkConf = new SparkConf().setAppName("a1").setMaster("local")
val spark: SparkSession = SparkSession.builder().config(c1).getOrCreate()
//隐式转换支持
import spark.implicits._
//建多个表
sc.makeRDD(Seq(
("r1", 1, 2, 3),
("r2", 4, 5, 13),
)).toDF("r", "c1", "c2", "c3").createTempView("t")
//结果展示
spark.sql(
"""
|SELECT
| r,
| STACK(
| 3,
| 'c1',c1,
| 'c2',c2,
| 'c3',c3
| ) AS (c,d)
|FROM t;
|""".stripMargin).show()
3、Appendix
| en | 🔉 | cn |
|---|---|---|
| pivot | ˈpɪvət | n. 枢轴;中心点;中心;旋转运动;中锋;(篮球)持球转身策应 v. 以……为中心旋转;在枢轴上转动 |
| stack | stæk | n. (整齐的)一堆;(尤指工厂的)大烟囱;堆栈; v. (使)放成整齐的一叠 |
以上是关于大数据(8n)图解Spark行转列pivot数据透视表的主要内容,如果未能解决你的问题,请参考以下文章