进程间链表实现
Posted rtoax
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了进程间链表实现相关的知识,希望对你有一定的参考价值。

《老酒馆》
对比起,踩您脚了;
老二两:是我对不起您,耽误您脚落地了。
隔离在家,第四天。2021年8月2日13:13:02。
--共享内存--
在文章《mmap从低向高增长的legacy模式和从高向低增长的modern模式》我介绍过进程地址空间的内存布局,当不同的进程同时映射一个文件到自己的进程地址空间时,就可以实现进程间的共享内存。
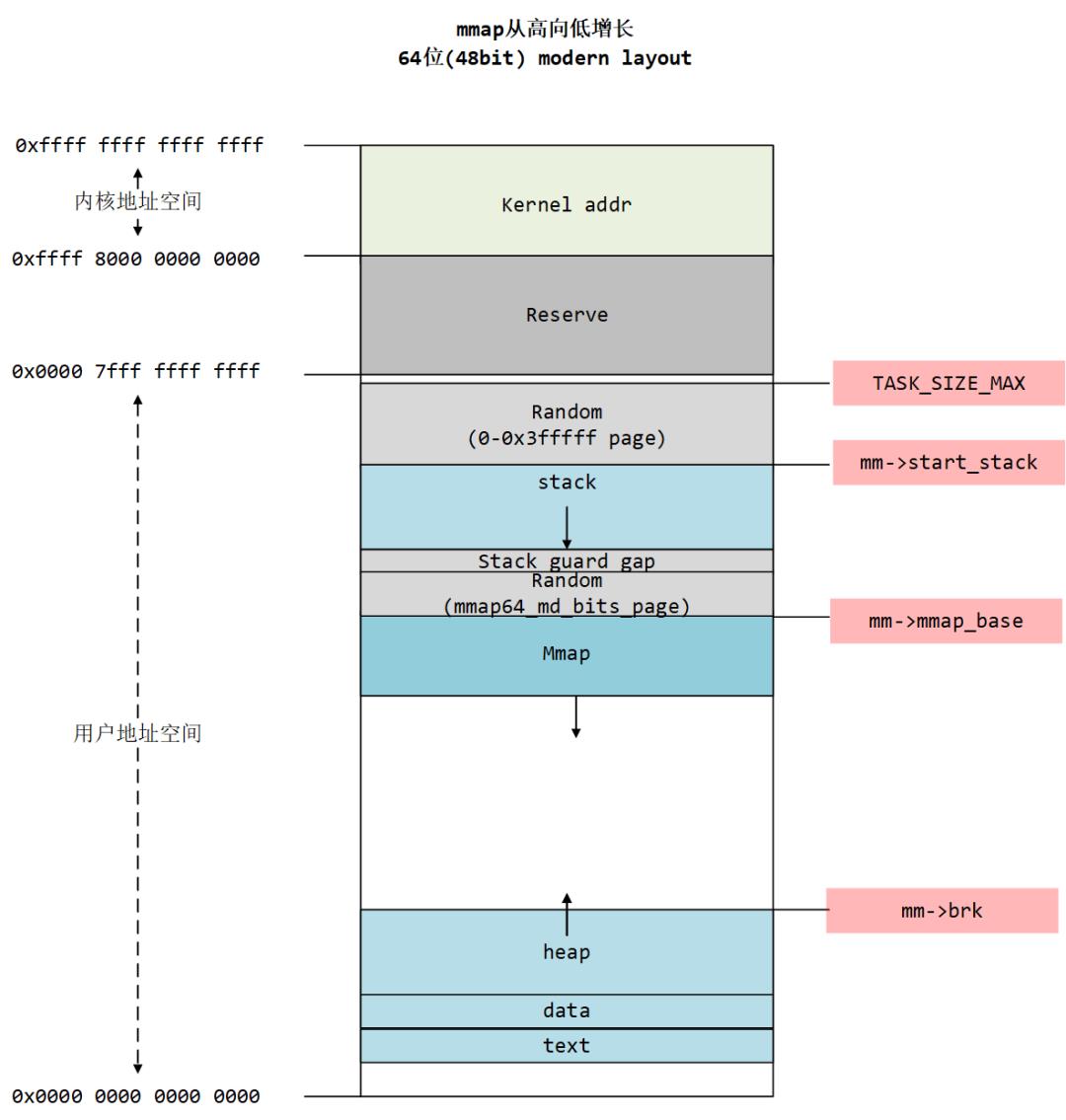
对于内存文件映射的整体架构如下图:
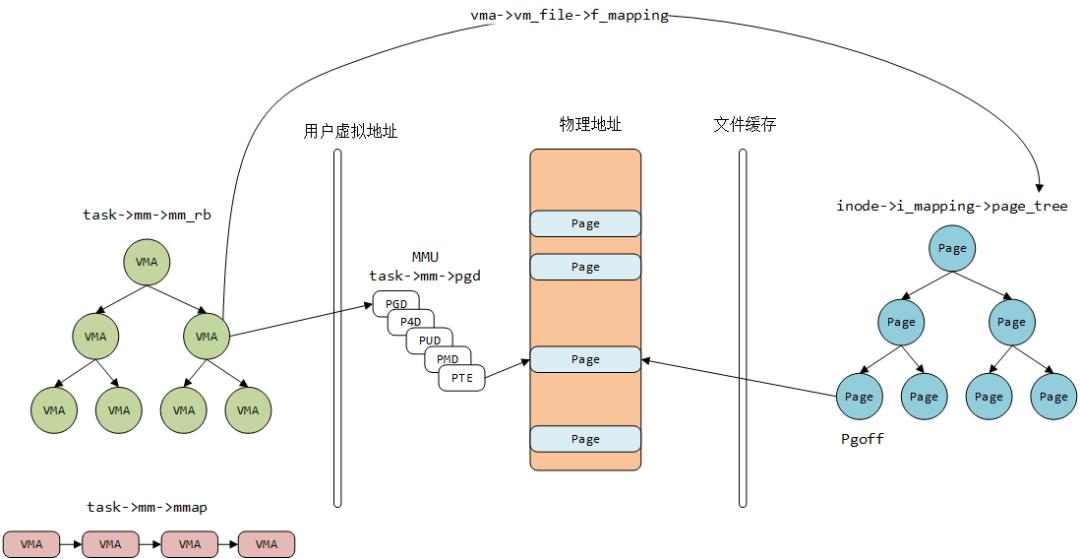
--链表--
拿单链表为例,链表节点的next域保存了链表的下一个节点的虚拟地址,从虚拟地址转化为物理地址为上图中由VMA到page结构的过程。

--进程间共享内存--
共享内存的基本简化结构如下图,那么,如果我们共享了一块物理内存,在进程地址空间中的虚拟地址大概率是不相等的,那么我们如何保证在进程1设置了next域后,在进程2中访问合法呢?
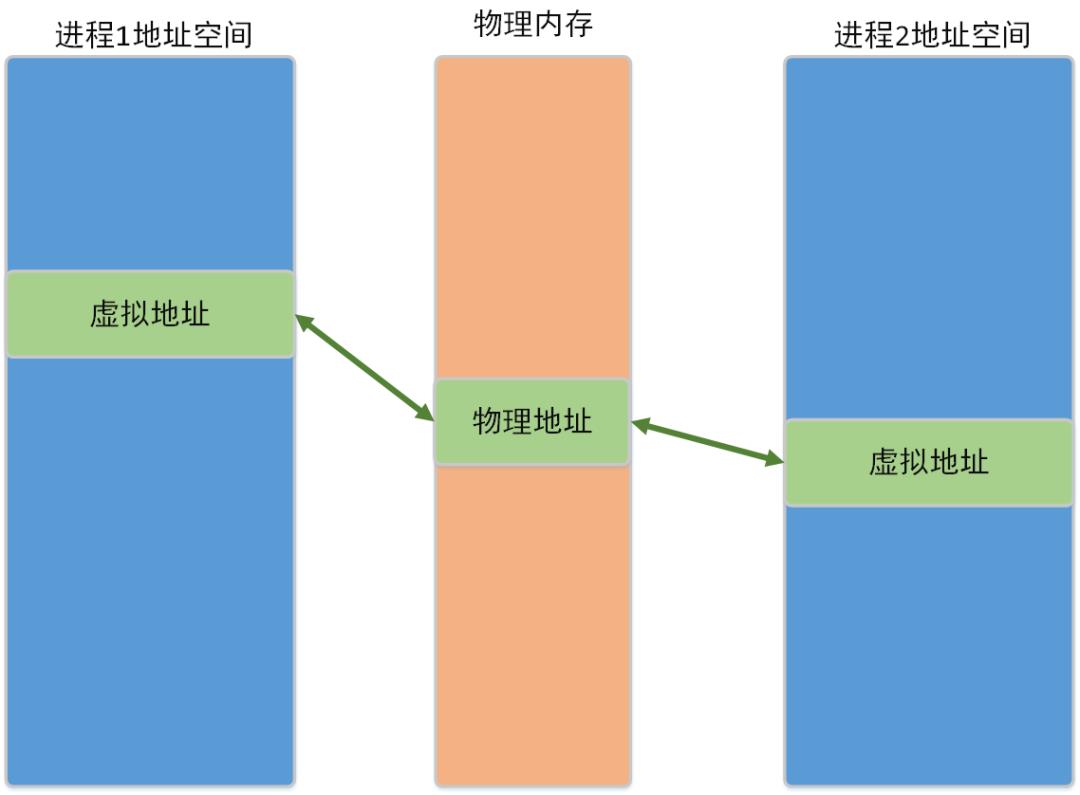
没错,我猜聪明的你一定也想到了,next域不在保存下一个节点的虚拟地址,而是保存相对于共享内存块的首地址的偏移。
--共享内存中的链表--
展开共享内存区域
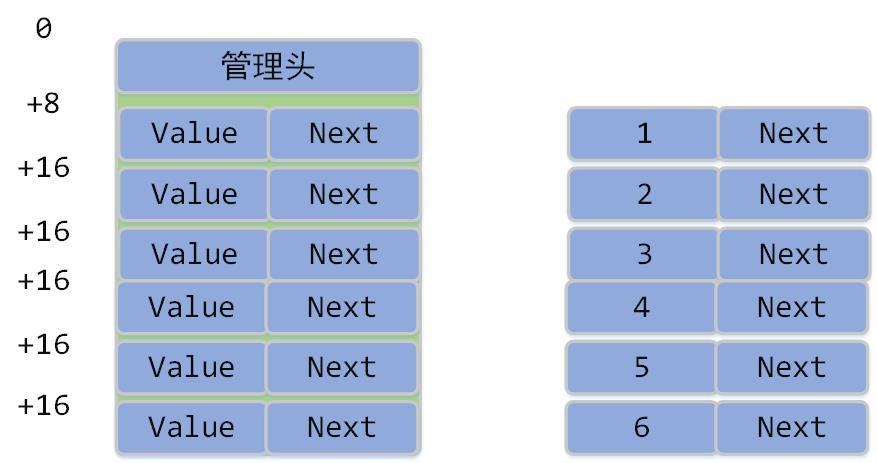
假设我们现在要生成的链表为:

在内存中表现为:
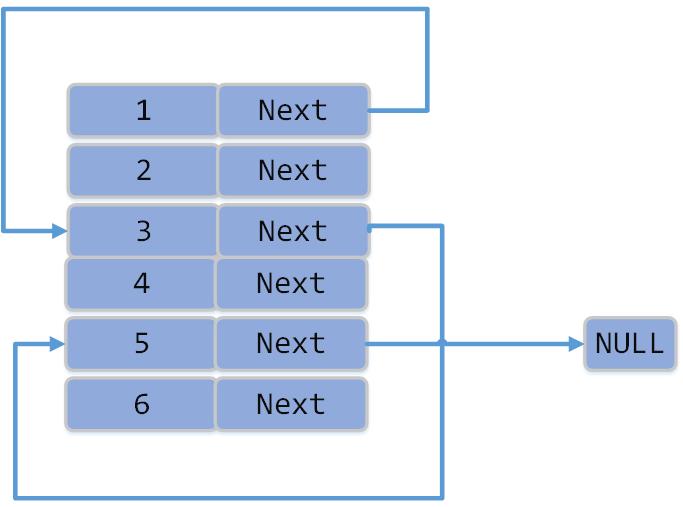
此时的链表节点为([value, next]):

此时内存地址空间中为:
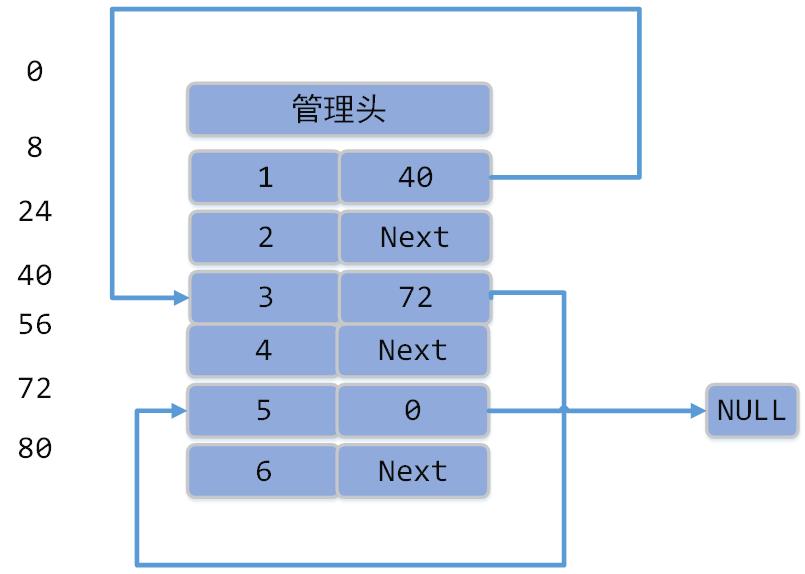
这些数据在进程1和进程2中是相同的,所以进程2通过遍历下面结构
即可遍历链表。
--实现--
上述步骤,实现起来非常简单,具体可参见源码:
<https://gitee.com/rtoax/test/commit/52116f9a074d41e7bf430caa40808d42102e79bb>
这里做简单介绍。
定义了两个数据结构,分别保存共享内存信息,和当前写指针对应的位置偏移:
struct mll_hdr {size_t curr_off;};typedef struct mlinklist_s {char filename[32];int fd;size_t size;char *addr;struct mll_hdr *hdr;}mll_t;
链表节点我将其定义为:
struct ll_node {int i;union {struct ll_node *next;size_t offset;};};
创建共享内存,区分读写:
void create_mll(mll_t * mll, const char *file, size_t size, int write){mll->size = size;strncpy(mll->filename, file, sizeof(mll->filename));int flag;if(write) {flag = O_RDWR|O_CREAT|O_TRUNC;} else {flag = O_RDWR;}mll->fd = open(file, flag, 0644);if(mll->fd == -1) {perror("open\\n");exit(1);}if((ftruncate(mll->fd, mll->size)) == -1) {perror("ftruncate\\n");exit(1);}mll->addr = mmap(NULL, mll->size, PROT_WRITE|PROT_READ, MAP_SHARED, mll->fd, 0);if(mll->addr == MAP_FAILED) {perror("mmap\\n");exit(1);}mll->hdr = (struct mll_hdr*)mll->addr;if(write) {mll->hdr->curr_off = sizeof(struct mll_hdr);}}
这里需要注意的是 flag 的赋值在读写测试不同的。其次,读者会根据写者的偏移决定是否有数据在链表中。
然后,就可以插入链表节点了:
void mll_insert(mll_t * mll, struct ll_node *node){struct ll_node *_node = (struct ll_node *)(mll->addr + mll->hdr->curr_off);_node->i = node->i;if(mll->hdr->curr_off > sizeof(struct mll_hdr)) {struct ll_node *_prev = (struct ll_node *)(mll->addr + mll->hdr->curr_off - sizeof(struct ll_node));_prev->offset = mll->hdr->curr_off;}_node->next = NULL;mll->hdr->curr_off += sizeof(struct ll_node);}
遍历链表节点:
void mll_foreach(mll_t * mll, void (*foreach)(struct ll_node *node)){if(mll->hdr->curr_off <= sizeof(struct mll_hdr)) {return ;}struct ll_node *_node = (struct ll_node *)(mll->addr + sizeof(struct mll_hdr));do {foreach(_node);if(!_node->next) break;_node = (struct ll_node *)(mll->addr + _node->offset);} while(_node);}
下面给出生产者代码:
#include <stdio.h>#include <mlinklist.h>#include <common.h>int main(){int i;mll_t mll;struct ll_node nodes[] = {{1, NULL}, {2, NULL}, {3, NULL}, {4, NULL},};create_mll(&mll, MMAP_FILENAME, sizeof(struct ll_node)*LINKLIST_SIZE, 1);for(i=0; i<sizeof(nodes)/sizeof(nodes[0]) && i < LINKLIST_SIZE; i++) {mll_insert(&mll, &nodes[i]);}}
消费者(读者,并没有实际出队)的代码:
#include <stdio.h>#include <mlinklist.h>#include <common.h>void foreach(struct ll_node *node){printf("foreach: %d %ld.\\n", node->i, node->offset);}int main(){mll_t mll;create_mll(&mll, MMAP_FILENAME, sizeof(struct ll_node)*LINKLIST_SIZE, 0);mll_foreach(&mll, foreach);}
详情请关注公众号 <全波形反演>
--参考--
-
《mmap从低向高增长的legacy模式和从高向低增长的modern模式》
-
https://rtoax.blog.csdn.net/article/details/118602363
-
-
《mmap文件映射与缺页异常》
-
https://rtoax.blog.csdn.net/article/details/118602477
-
以上是关于进程间链表实现的主要内容,如果未能解决你的问题,请参考以下文章
NC41 最长无重复子数组/NC133链表的奇偶重排/NC116把数字翻译成字符串/NC135 股票交易的最大收益/NC126换钱的最少货币数/NC45实现二叉树先序,中序和后序遍历(递归)(代码片段
在 Python 多处理进程中运行较慢的 OpenCV 代码片段
817. Linked List Components - LeetCode
java 简单的代码片段,展示如何将javaagent附加到运行JVM进程
LINUX PID 1和SYSTEMD PID 0 是内核的一部分,主要用于内进换页,内核初始化的最后一步就是启动 init 进程。这个进程是系统的第一个进程,PID 为 1,又叫超级进程(代码片段