[机器学习] Coursera ML笔记 - 神经网络(Learning) - 标准梯度下降
Posted WangBo_NLPR
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[机器学习] Coursera ML笔记 - 神经网络(Learning) - 标准梯度下降相关的知识,希望对你有一定的参考价值。
前言
本文是Neural network - Learning笔记的补充,给出了神经网络的标准梯度下降算法,欢迎大家讨论。
我在学习神经网络过程中的笔记共分为以下几个部分:
Neural network - Representation:神经网络的模型描述 ;
Neural network - Learning:神经网络的模型训练;
Neural network - Learning:标准梯度下降法;
Neural network - Code:神经网络的代码实现。
在阅读这部分笔记之前,请先阅读《[机器学习] Coursera ML笔记 - 神经网络(Representation)》和《[机器学习] Coursera ML笔记 - 神经网络(Learning)》这两篇笔记,以了解神经网络的模型描述,激活函数,前向传播、反向传播、参数优化等基础知识。
神经网络的标准梯度下降法
神经网络的关键是如何训练权重模型,在基于sgd的优化策略中,训练的关键是如何计算梯度。利用反向传播算法可以证明,无论损失函数(loss function)和激励函数(activation function)是什么,神经网络的梯度下降法在数学抽象形式上都是一致的。
下面给出我总结的标准梯度下降计算规则。
1. Deign network structure
2. Randomly initialize weights
Repeat
3. Perform forward propagation to compute a^((l))
4. Perform back propagation to compute δ^((l))
For each unit i in layer =L , set:
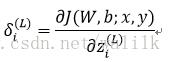
For each unit i in layer =L-1,L-2,L-2,…,2 , set:
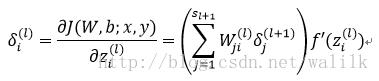
5. Compute gradient:
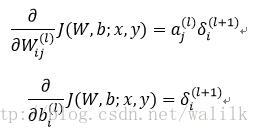
6. Update weight:
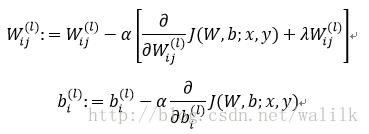
7. Check: convergence? Or max iterations?
向量化计算版本:
1. Deign network structure
2. Randomly initialize weights
Repeat
3. Perform forward propagation to compute a^((l))
4. Perform back propagation to compute δ^((l))
For each unit i in layer =L , set:
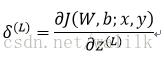
For each unit i in layer =L-1,L-2,L-2,…,2 , set:
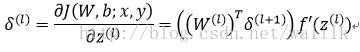
5. Compute gradient:
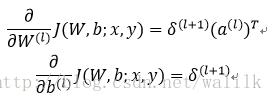
6. Update weight:
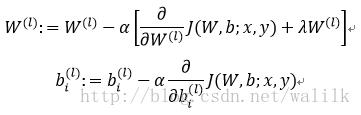
7. Check: convergence? Or max iterations?
供大家参考,欢迎批评指正交流!
后续文章会整理UFLDL-反向传播算法的笔记,会给出在不同loss function情况下的偏导数推导,可以看到,神经网络是很神奇的,可以看作是一种计算规则,无论损失函数(loss function)和激励函数(activation function)是什么,都可以归纳到一个统一的计算规则下!十分方便!也许这也是很多人批评深度学习缺少数学的原因吧!
以上是关于[机器学习] Coursera ML笔记 - 神经网络(Learning) - 标准梯度下降的主要内容,如果未能解决你的问题,请参考以下文章