Apache Spark启动spark-sql报错
Posted 终回首
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Apache Spark启动spark-sql报错相关的知识,希望对你有一定的参考价值。
目录
一、问题
出现版本:
Apache Spark 2.4.0
Apache Spark 3.0.0
安装好spark后,执行spark-sql报错Exception in thread “main” java.lang.NoSuchFieldError: HIVE_STATS_JDBC_TIMEOUT
命令
./bin/spark-sql
报错日志:
2021-08-02 15:00:04,213 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Exception in thread "main" java.lang.NoSuchFieldError: HIVE_STATS_JDBC_TIMEOUT
at org.apache.spark.sql.hive.HiveUtils$.formatTimeVarsForHiveClient(HiveUtils.scala:204)
at org.apache.spark.sql.hive.thriftserver.SparkSQLCLIDriver$.main(SparkSQLCLIDriver.scala:90)
at org.apache.spark.sql.hive.thriftserver.SparkSQLCLIDriver.main(SparkSQLCLIDriver.scala)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.spark.deploy.JavaMainApplication.start(SparkApplication.scala:52)
at org.apache.spark.deploy.SparkSubmit.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:849)
at org.apache.spark.deploy.SparkSubmit.doRunMain$1(SparkSubmit.scala:167)
at org.apache.spark.deploy.SparkSubmit.submit(SparkSubmit.scala:195)
at org.apache.spark.deploy.SparkSubmit.doSubmit(SparkSubmit.scala:86)
at org.apache.spark.deploy.SparkSubmit$$anon$2.doSubmit(SparkSubmit.scala:924)
at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:933)
at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
2021-08-02 15:00:04,409 INFO util.ShutdownHookManager: Shutdown hook called
2021-08-02 15:00:04,410 INFO util.ShutdownHookManager: Deleting directory /tmp/spark-16fcc4aa-301d-428f-b840-cd29602d253b
二、解决
原因:
1 修改源码
hadoop@company:/opt/os_ws/spark$ pwd
/opt/os_ws/spark
hadoop@company:/opt/os_ws/spark$ vim sql/hive/src/main/scala/org/apache/spark/sql/hive/HiveUtils.scala
搜索HIVE_STATS_JDBC_TIMEOUT
注视掉如下内容

2 重新编译、部署
编译参考
https://blog.csdn.net/qq_39945938/article/details/119236982
部署参考
https://blog.csdn.net/weixin_44449270/article/details/86102461
再次启动spark-sql发现报错变了
root@company:/opt/soft/spark-2.4.0-bin-hadoop3.1.1/bin# spark-sql
21/08/02 15:43:42 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Exception in thread "main" java.lang.ExceptionInInitializerError
at org.apache.spark.sql.hive.HiveUtils$.formatTimeVarsForHiveClient(HiveUtils.scala:192)
at org.apache.spark.sql.hive.thriftserver.SparkSQLCLIDriver$.main(SparkSQLCLIDriver.scala:90)
at org.apache.spark.sql.hive.thriftserver.SparkSQLCLIDriver.main(SparkSQLCLIDriver.scala)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.spark.deploy.JavaMainApplication.start(SparkApplication.scala:52)
at org.apache.spark.deploy.SparkSubmit.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:849)
at org.apache.spark.deploy.SparkSubmit.doRunMain$1(SparkSubmit.scala:167)
at org.apache.spark.deploy.SparkSubmit.submit(SparkSubmit.scala:195)
at org.apache.spark.deploy.SparkSubmit.doSubmit(SparkSubmit.scala:86)
at org.apache.spark.deploy.SparkSubmit$$anon$2.doSubmit(SparkSubmit.scala:924)
at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:933)
at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
Caused by: java.lang.IllegalArgumentException: Unrecognized Hadoop major version number: 3.1.1
at org.apache.hadoop.hive.shims.ShimLoader.getMajorVersion(ShimLoader.java:174)
at org.apache.hadoop.hive.shims.ShimLoader.loadShims(ShimLoader.java:139)
at org.apache.hadoop.hive.shims.ShimLoader.getHadoopShims(ShimLoader.java:100)
at org.apache.hadoop.hive.conf.HiveConf$ConfVars.<clinit>(HiveConf.java:368)
... 15 more
3 解决Unrecognized Hadoop major version number
用$HIVE_HOME/lib/下的jar包拷贝到$SPARK_HOME/jars/,之后备份之前的jar包

替换后的目录如下所示
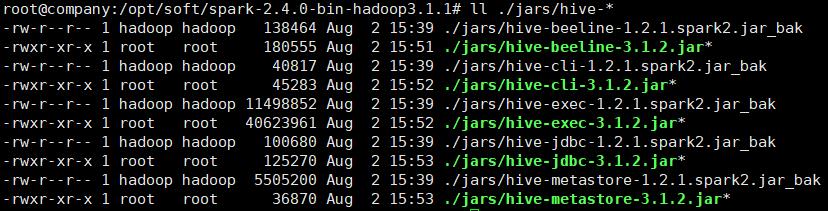
再次启动spark-sql;又报错提示没有写权限
4 解决The dir: /tmp/hive on HDFS should be writable问题
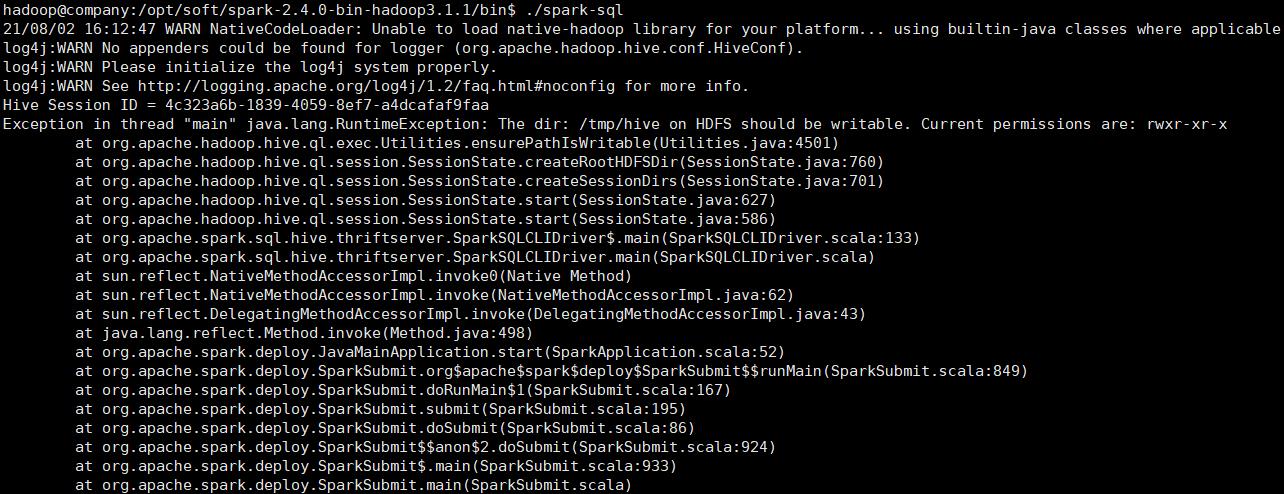
赋予全部权限
hdfs dfs -chmod -R 777 /tmp/hive
权限修改后,这个报错消失;看其他人改完后就可以启动spark-sql,又报了另外的错
hadoop@company:/opt/soft/spark-2.4.0-bin-hadoop3.1.1/bin$ ./spark-sql
2021-08-02 16:43:36,877 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
2021-08-02 16:43:37,066 INFO conf.HiveConf: Found configuration file file:/opt/soft/apache-hive-3.1.2-bin/conf/hive-site.xml
Hive Session ID = c9b1fce5-35e7-4716-a948-e71a69881c54
2021-08-02 16:43:37,161 INFO SessionState: Hive Session ID = c9b1fce5-35e7-4716-a948-e71a69881c54
2021-08-02 16:43:37,657 INFO session.SessionState: Created HDFS directory: /tmp/hive/hadoop/c9b1fce5-35e7-4716-a948-e71a69881c54
2021-08-02 16:43:37,665 INFO session.SessionState: Created local directory: /tmp/hive/tmpdir/hadoop/c9b1fce5-35e7-4716-a948-e71a69881c54
2021-08-02 16:43:37,692 INFO session.SessionState: Created HDFS directory: /tmp/hive/hadoop/c9b1fce5-35e7-4716-a948-e71a69881c54/_tmp_space.db
Exception in thread "main" java.lang.NoSuchMethodError: org.apache.hadoop.hive.ql.session.SessionState$LogHelper.<init>(Lorg/apache/commons/logging/Log;)V
at org.apache.spark.sql.hive.thriftserver.SparkSQLCLIDriver.<init>(SparkSQLCLIDriver.scala:303)
at org.apache.spark.sql.hive.thriftserver.SparkSQLCLIDriver$.main(SparkSQLCLIDriver.scala:166)
at org.apache.spark.sql.hive.thriftserver.SparkSQLCLIDriver.main(SparkSQLCLIDriver.scala)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.spark.deploy.JavaMainApplication.start(SparkApplication.scala:52)
at org.apache.spark.deploy.SparkSubmit.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:849)
at org.apache.spark.deploy.SparkSubmit.doRunMain$1(SparkSubmit.scala:167)
at org.apache.spark.deploy.SparkSubmit.submit(SparkSubmit.scala:195)
at org.apache.spark.deploy.SparkSubmit.doSubmit(SparkSubmit.scala:86)
at org.apache.spark.deploy.SparkSubmit$$anon$2.doSubmit(SparkSubmit.scala:924)
at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:933)
at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
2021-08-02 16:43:37,703 INFO util.ShutdownHookManager: Shutdown hook called
2021-08-02 16:43:37,704 INFO util.ShutdownHookManager: Deleting directory /tmp/spark-9520a36a-9613-4081-b57e-65435736a034
看起来是hive和spark版本冲突问题;
参考资料
以上是关于Apache Spark启动spark-sql报错的主要内容,如果未能解决你的问题,请参考以下文章