运维人不得不了解的eBPF入门指南,新手建议收藏~
Posted 代码熬夜敲
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了运维人不得不了解的eBPF入门指南,新手建议收藏~相关的知识,希望对你有一定的参考价值。
 eBPF(Extended Berkeley Packet Filter)的核心是驻留在 kernel 的高效虚拟机。最初的目的是高效网络过滤框架,前身是BPF,所以我们先了解下BPF
eBPF(Extended Berkeley Packet Filter)的核心是驻留在 kernel 的高效虚拟机。最初的目的是高效网络过滤框架,前身是BPF,所以我们先了解下BPF
BPF
框架
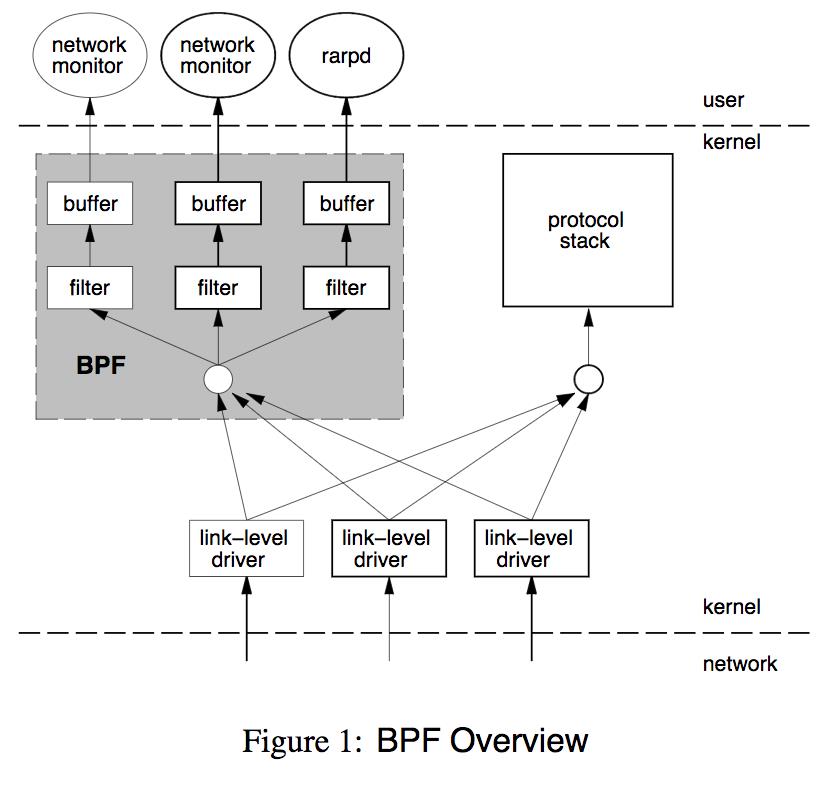
上图是BPF的位置和框架,需要注意的是kernel和user使用了buffer来传输数据,避免频繁上下文切换。BPF虚拟机非常简洁,由累加器、索引寄存器、存储、隐式程序计数器组成。
示例
接下来我们看一下示例,过滤所有ip报文,可以使用 tcpdump -d ip 查看:
(000) ldh [12] // 链路层第12字节的数据加载到寄存器,ethertype字段
(001) jeq #0x800 jt 2 jf 3 // 比较寄存器的ethertype字段是否为IP类型,true跳到2,false跳到3
(002) ret #65535 // 返回true
(003) ret #0 // 返回0
BPF只使用了4条虚拟机指令,就能提供非常有用的IP报文过滤。
tcpdump -d tcp
(000) ldh [12] // 链路层第12字节的数据(2字节)加载到寄存器,ethertype字段
(001) jeq #0x86dd jt 2 jf 7 // 判断是否为IPv6类型,true跳到2,false跳到7
(002) ldb [20] // 链路层第20字节的数据(1字节)加载到寄存器,IPv6的next header字段
(003) jeq #0x6 jt 10 jf 4 // 判断是否为TCP,true跳到10,false跳到4
(004) jeq #0x2c jt 5 jf 11 // 可能是IPv6分片标志,true跳到5,false跳到11
(005) ldb [54] // 我编不下去了...
(006) jeq #0x6 jt 10 jf 11 // 判断是否为TCP,true跳到10,false跳到11
(007) jeq #0x800 jt 8 jf 11 // 判断是否为IP类型,true跳到8,false跳到11
(008) ldb [23] // 链路层第23字节的数据(1字节)加载到寄存器,next proto字段
(009) jeq #0x6 jt 10 jf 11 // 判断是否为TCP,true跳到10,false跳到11
(010) ret #65535 // 返回true
(011) ret #0 // 返回0
以上是freebsd的BPF,Linux中应该不叫这个,叫LSF,自己看吧。
eBPF
eBPF初识
Linux kernel 3.18版本开始包含了eBPF,相对于BPF做了一些重要改进,首先是效率,这要归功于JIB编译eBPF代码;其次是应用范围,从网络报文扩展到一般事件处理;最后不再使用socket,使用map进行高效的数据存储。
根据以上的改进,内核开发人员在不到两年半的事件,做出了包括网络监控、限速和系统监控。
目前eBPF可以分解为三个过程:
-
以字节码的形式创建eBPF的程序。编写C代码,将LLVM编译成驻留在ELF文件中的eBPF字节码。
-
将程序加载到内核中,并创建必要的eBPF-maps。eBPF具有用作socket filter,kprobe处理器,流量控制调度,流量控制操作,tracepoint处理,eXpress Data
Path(XDP),性能监测,cgroup限制,轻量级tunnel的程序类型。 -
将加载的程序attach到系统中。根据不同的程序类型attach到不同的内核系统中。程序运行的时候,启动状态并且开始过滤,分析或者捕获信息。
2016年10月的NetDev 1.2大会上,Netronome的Jakub Kicinski和Nic Viljoen发表了标题为“eBPF / XDP硬件卸载到SmartNIC”。Nic Viljoen在其中介绍了Netronome SmartNIC上每个FPC每秒达到300万个数据包,每个SmartNIC有72到120个FPC,可能最大支持eBPF吞吐量4.3 Tbps!(理论上)
eBPF入口
接下来我们以内核版本4.14版本为例进行查看。
bpf的系统调用
kernel/bpf/syscall.c
bpf系统调用的头文件
include/uapi/linux/bpf.h
入口函数
int bpf(int cmd, union bpf_attr *attr, unsigned int size);
从kernel/bpf/syscall.c中的宏定义展开。
eBPF命令
Linux系统的BPF系统调用有10个命令,其中man page中列出了6个:
BPF_PROG_LOAD验证并且加载eBPF程序,返回一个新的文件描述符。BPF_MAP_CREATE创建map并且返回指向map的文件描述符BPF_MAP_LOOKUP_ELEM通过key从指定的map中查找元素,并且返回value值BPF_MAP_UPDATE_ELEM在指定的map中创建或者更新元素(key/value 配对)BPF_MAP_DELETE_ELEM通过key从指定的map中找到元素并且删除BPF_MAP_GET_NEXT_KEY通过key从指定的map中找到元素,并且返回下个key值
以上的命令可以分为两大类,加载eBPF程序和eBPF-maps操作。eBPF-maps操作有很大的自主性,用于创建eBPF-maps,从中查找、更新和删除元素,遍历eBPF-maps(BPF_MAP_GET_NEXT_KEY)
接下来列一下剩下的4个命令,在代码中可以看到:
- BPF_OBJ_PIN 4.4版本新加的,属于持久性eBPF。有了这个,eBPF-maps和eBPF程序可以放入/sys/fs/bpf
- BPF_OBJ_GET同上,在这之前,没有工具能创建eBPF程序,并且结束,因为会破坏filter,而文件系统可以在创建他们的程序退出后依然保留eBPF-maps和eBPF程序
- BPF_PROG_ATTACH 4.10版本中添加的,将eBPF程序attach到cgroup,这样适用于container
- BPF_PROG_DETACH 同上。
eBPF-map 类型
Linux系统的BPF系统调用有10个命令,其中man page中列出了6个:
BPF_PROG_LOAD 验证并且加载eBPF程序,返回一个新的文件描述符。
BPF_MAP_CREATE 创建map并且返回指向map的文件描述符
BPF_MAP_LOOKUP_ELEM 通过key从指定的map中查找元素,并且返回value值
BPF_MAP_UPDATE_ELEM 在指定的map中创建或者更新元素(key/value 配对)
BPF_MAP_DELETE_ELEM 通过key从指定的map中找到元素并且删除
BPF_MAP_GET_NEXT_KEY 通过key从指定的map中找到元素,并且返回下个key值
以上的命令可以分为两大类,加载eBPF程序和eBPF-maps操作。eBPF-maps操作有很大 的自主性,用于创建eBPF-maps,从中查找、更新和删除元素,遍历eBPF-maps(BPF_MAP_GET_NEXT_KEY)
接下来列一下剩下的4个命令,在代码中可以看到:
-
BPF_OBJ_PIN 4.4版本新加的,属于持久性eBPF。有了这个,eBPF-maps和eBPF程序可以放入/sys/fs/bpf
-
BPF_OBJ_GET同上,在这之前,没有工具能创建eBPF程序,并且结束,因为会破坏filter,而文件系统可以在创建他们的程序退出后依然保留eBPF-maps和eBPF程序
-
BPF_PROG_ATTACH 4.10版本中添加的,将eBPF程序attach到cgroup,这样适用于container
-
BPF_PROG_DETACH 同上。
eBPF-map 类型
BPF_MAP_TYPE_UNSPEC
BPF_MAP_TYPE_HASHeBPF-maps hash表,是主要用的前两种方式之一BPF_MAP_TYPE_ARRAY和上面类似,除了索引像数组一样BPF_MAP_TYPE_PROG_ARRAY将加载的eBPF程序的文件描述符保存其值,常用的是使用数字识别不同的eBPF程序类型,也可以从一个给定key值的eBPF-maps找到eBPF程序,并且跳转到程序中去BPF_MAP_TYPE_PERF_EVENT_ARRAY配合perf工具,CPU性能计数器,tracepoints,kprobes和uprobes。可以查看路径samples/bpf/下的tracex6_kern.c,tracex6_user.c,tracex6_kern.c,tracex6_user.cBPF_MAP_TYPE_PERCPU_HASH和BPF_MAP_TYPE_HASH一样,除了是为每个CPU创建BPF_MAP_TYPE_PERCPU_ARRAY 和BPF_MAP_TYPE_ARRAY一样,除了是为每个CPU创建
BPF_MAP_TYPE_STACK_TRACE 用于存储stack-traces
BPF_MAP_TYPE_CGROUP_ARRAY 检查skb的croup归属
BPF_MAP_TYPE_LRU_HASH
BPF_MAP_TYPE_LRU_PERCPU_HASH
BPF_MAP_TYPE_LPM_TRIE最专业的用法,LPM(Longest Prefix Match)的一种trieBPF_MAP_TYPE_ARRAY_OF_MAPS可能是针对每个port的BPF_MAP_TYPE_HASH_OF_MAPS可能是针对每个port的BPF_MAP_TYPE_DEVMAP可能是定向报文到dev的BPF_MAP_TYPE_SOCKMAP可能是连接socket的

以上是关于运维人不得不了解的eBPF入门指南,新手建议收藏~的主要内容,如果未能解决你的问题,请参考以下文章