模型训练和参数优化
Posted 被褐怀玉888988
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了模型训练和参数优化相关的知识,希望对你有一定的参考价值。
文章目录
一 模型训练
1.基于高层API训练模型
通过Model.prepare接口来对训练进行提前的配置准备工作,包括设置模型优化器,Loss计算方法,精度计算方法等。
#详情查询API文档
2.使用PaddleX训练模型
3.模型训练通用配置基本原则
- 每个输入数据的维度要保持一致,且一定要和模型输入保持一致。
- 配置学习率衰减策略时,训练的上限轮数一定要计算正确。
- BatchSize不宜过大,太大容易内存溢出,且一般为2次幂。
二 超参优化
1.超参优化的基本概念
参数
参数是机器学习算法的关键,是从训练数据中学习到的,属于模型的一部分。
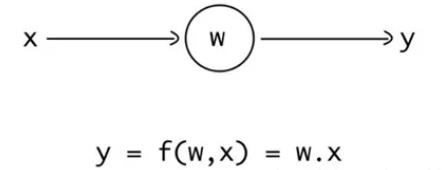
输入一个值(x),乘以权重,结果就是网络的输出值。权重可以随着网络的训练进行更新,从而找到最佳的值,这样网络就能尝试匹配输出值与目标值。
这里的权重其实就是一种参数。
超参数
模型的超参数指的是模型外部的配置变量,是不能通过训练的进行来估计其取值不同的,且不同的训练任务往往需要不同的超参数。
超参数不同,最终得到的模型也是不同的。
一般来说,超参数有:学习率,迭代次数,网络的层数,每层神经元的个数等等。
常见的超参数有以下三类:
- 网络结构,包括神经元之间的连接关系、层数、每层的神经元数量、激活函数的类型等 .
- 优化参数,包括优化方法、学习率、小批量的样本数量等 .
- 正则化系数
实践中,当你使⽤神经⽹络解决问题时,寻找好的超参数其实是一件非常困难的事情,对于刚刚接触的同学来说,都是"佛系调优",这也是一开始就"入土"的原因,没有依据的盲目瞎调肯定是不行的。
2.手动调整超参数的四大方法
我们在使用某一网络时,一般是比较好的论文中出现过的,是证明过的,当然也可以直接套用,然后在这个基础上,调参。
可是如果识别的领域不同,比如同样是LeNet网络,在解决手写数字识别时使用的超参数能得到很好的效果,但是在做眼疾识别时,因为数据集的不同,虽然使用同样的超参数,但是效果可能并不理想。
在<< Neural Network and Deep Learning >>这本书中,作者给出⼀些⽤于设定超参数的启发式想法。⽬的是帮读者发展出⼀套工作流来确保很好地设置超参数。这里我把书上的内容总结一下,再结合自己的思考,与大家共同探讨调整超参数的方法论。
不过呢,目前不存在⼀种通用的关于正确策略的共同认知,这也是超参数调节的"玄学"之处。
1)使用提前停止来确定训练的迭代次数
做法其实很简单,做一个判断,满足条件时退出循环,终止训练:
那么这个if条件判断就十分重要了,这里有两种方案:
- 分类准确率不再提升时
- loss降到一个想要的范围时
分类准确率不再提升时
我们需要再明确⼀下什么叫做分类准确率不再提升,这样方可实现提前停止。
我们知道,分类准确率在整体趋势下降的时候仍旧会抖动或者震荡。如果我们在准确度刚开始下降的时候就停止,那么肯定会错过更好的选择。⼀种不错的解决方案是如果分类准确率在⼀段时间内不再提升的时候终止。
当然这块用loss也是可以的,loss也是一个评判标准。
loss降到一个想要的范围时
这是我经常使用的、更直接的方法。
因为网络有时候会在很长时间内于⼀个特定的分类准确率附近形成平缓的局面,然后才会有提升。如果你想获得相当好的性能,第一种方案(分类准确率不再提升时)的规则可能就会太过激进了 —— 停止得太草率。
而本方案(loss降到一个想要的范围时)能很好地解决这一问题,但随之而来的问题就是不知不觉地又多了一个超参数,实际应用上,这个用于条件判断的loss值的选择也很困难。
2)让学习率从高逐渐降低
我们⼀直都将学习速率设置为常量。但是,通常采用可变的学习速率更加有效。
如果学习率设置的过低,在训练的前期,训练速度会非常慢;而学习率设置地过高,在训练的后期,又会产生震荡,降低模型的精度:
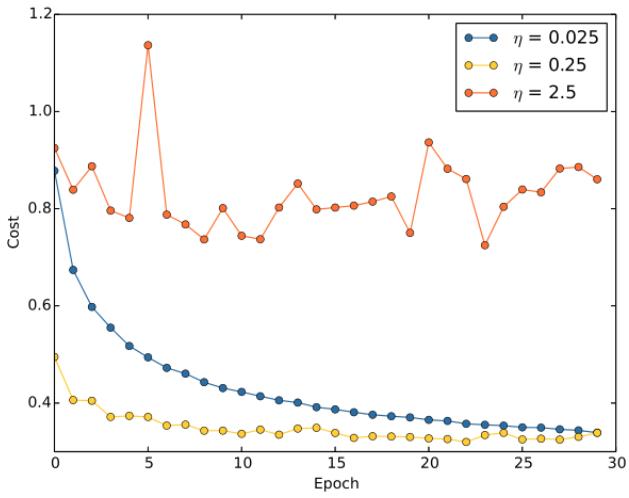
所以最好是在前期使用一个较大的学习速率让权重变化得更快。越往后,我们可以降低学习速率,这样可以作出更加精良的调整。
⼀种自然的观点是使用提前终止的想法。就是保持学习速率为⼀个常量直到验证准确率开始变差,然后按照某个量下降学习速率。我们重复此过程若干次,直到学习速率是初始值的 1/1024(或者1/1000),然后终止训练。
3)宽泛策略
在使用神经网络来解决新的问题时,⼀个挑战就是获得任何⼀种非寻常的学习,也就是说,达到比随机的情况更好的结果。
也许下面的方法能给你带来某些不一样的启发:
通过简化网络来加速实验进行更有意义的学习
通过更加频繁的监控验证准确率来获得反馈
通过简化网络来加速实验进行更有意义的学习
假设,我们第⼀次遇到 MNIST 分类问题。刚开始,你很有激情,但是当模型完全失效时,你会就得有些沮丧。
此时就可以将问题简化,将十分类问题转化成二分类问题。丢开训练和验证集中的那些除了 0 和 1的那些图像,即我们只识别0和1。然后试着训练⼀个网络来区分 0 和 1。
这样一来,不仅仅问题比 10 个分类的情况简化了,同样也会减少 80% 的训练数据,这样就多出了 5 倍的加速。同时也可以保证更快的实验,也能给予你关于如何构建好的网络更快的洞察。
通过更加频繁的监控验证准确率来获得反馈
4)小批量数据(mini-batch)大小不必最优
假设我们使用大小为 1 的小批量数据。而一般来说,使用只有⼀个样本的小批量数据会带来关于梯度的错误估计。
而实际上,误差并不会真的产⽣这个问题。原因在于单⼀的梯度估计不需要绝对精确。我们需要的是确保代价函数保持下降足够精确的估计。
这就好像你现在要去北极点,但是只有⼀个不太精确的指南针。如果你不再频繁地检查指南针,指南针会在平均状况下给出正确的⽅向,所以最后你也能抵达北极点。
不过使用更大的小批量数据看起来还是显著地能够进行训练加速的。
所以,选择最好的小批量数据大小是⼀种折中。小批量数据太小会加长训练时间;而小批量数据太大是不能够足够频繁地更新权重的。你所需要的是选择⼀个折中的值,可以最大化学习的速度。
幸运的是,小批量数据大小的选择其实是相对独立的⼀个超参数(网络整体架构外的参数),所以你不需要优化那些参数来寻找好的小批量数据大小。
因此,可以选择的方式就是使用某些可以接受的值(不需要是最优的)作为其他参数的选择,然后进行不同小批量数据大小的尝试,就像上面调整学习率那样,画出验证准确率的值随时间(非回合)变化的图,选择得到最快性能提升的小批量数据大小。
以上是关于模型训练和参数优化的主要内容,如果未能解决你的问题,请参考以下文章