如何设计一个高性能CPU?
Posted AI科技大本营
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何设计一个高性能CPU?相关的知识,希望对你有一定的参考价值。

任何一种技术都会经历从阳春白雪到下里巴人的过程,就像我们对计算机的理解从“戴着鞋套才能进的机房”变成了随处可见的智能手机。在前面20年中,大数据技术也经历了这样的过程,从曾经高高在上的 “火箭科技(rocket science)”,成为了人人普惠的技术。
在所有的芯片品类中,中央处理器CPU一直是最核心的类型,可能没有之一。它驱动着各种各样的电子设备,小到我们的手机、电脑,大到数据中心里成千上万台服务器,它们的控制中枢和大脑都是CPU。
CPU最主要的优势就是通用性,它必须适应各种不同的应用场景,同时尽可能保持高性能和低功耗,这其实是一件非常复杂的事情。常看我文章的朋友肯定都知道我是个吃货,我们就拿吃来举个例子。如果我们把设计芯片比作开饭店,那么设计那些针对特定应用的专用芯片就好比是开个火锅店,或者拉面馆,只需要专注于做好几道看家菜就可以了。而设计CPU就好比是开个大酒楼,各大菜系都得整明白,煎炒烹炸也得样样精通,甚至西餐甜点也得配齐。相比于开火锅店来说,这个难度就大多了。
所以为了实现和完善这种通用性,现代CPU的设计思路也在不断进化。除了不断升级微架构,做到性能和功耗的迭代优化外,CPU还在不断集成一些专用的加速单元,用来处理像人工智能这样非常重要或者流行度越来越高的应用。这种以通用性能升级为主,并兼顾部分专用应用加速技术的思路,就成为了现代CPU设计的主旋律。
在之前的文章里,我们专门介绍过英特尔至强可扩展处理器对人工智能应用提供的优化支持。今年四月,英特尔发布了最新的面向单路和双路服务器的第三代至强可扩展处理器,代号为Ice Lake。这篇文章我就想以Ice Lake为例,和大家一起来看下现代CPU的这种通用+专用的整体设计思路,包括微架构、系统架构、IO和存储这些单元模块的设计方法,以及如何围绕CPU来构建整体的生态系统。


Ice Lake概述
Ice Lake是英特尔第一个采用10纳米工艺打造的至强CPU,单芯片最多集成40个核心,和上一代Cascade Lake相比提升了近43%。它采用了最新的Sunny Cove微架构,每时钟周期指令数(IPC)提升了20%。它的DDR4内存通道的数量从6个提升到了8个,首次支持了PCIe4.0,并且每路支持高达64个通道。总而言之,Ice Lake无论是架构还是性能,都比前代产品取得了明显的提升。

在特定应用的加速方面,它继承了很多前代产品的重要特性,比如之前文章里介绍过的深度学习加速技术,同时也有升级和新增,比如引入更多与安全相关的硬件支持,还有能灵活进行频率调配的SST技术等等。这些我们接下来就结合CPU架构设计方面的知识,一个一个仔细说。

Sunny Cove内核架构
首先值得一说的,就是Ice Lake里采用的全新内核架构Sunny Cove。内核是CPU最重要的组成部分,在现代CPU里一般都有少则几个,多则几十个内核,它们和存储器还有IO单元一起组成了完整的CPU片上系统。通常我们也把内核架构称为CPU的微架构。
CPU微架构的本质,其实是对某种指令集架构的具体实现,常见的指令集架构包括x86、ARM、RISC-V等。不过即便是相同的指令集架构,不同公司的实现方式也不尽相同。但是通常来说,CPU微架构都需要实现四个主要的操作,分别是取指、解码、执行和写回。
也就是说,CPU会从内存中取出一条指令,然后通过解码器把它分解成若干个部分,并识别出来这条指令的功能,比如算术运算、跳转、比较等等。解码分解之后的指令和数据就会被送到执行阶段。执行完的结果被写回到寄存器或者存储器里。这个过程周而复始,直到整个程序执行完毕。
再深入一些,我们通常把这四个操作分成两部分,实现“取指”和“解码”这两个操作的电路在CPU微架构里叫做前端,实现“执行”和“写回”的结构叫做后端。比如在Sunny Cove微架构示意图里,上面的这些绿色的部分都属于前端,下面蓝色的部分则属于后端。
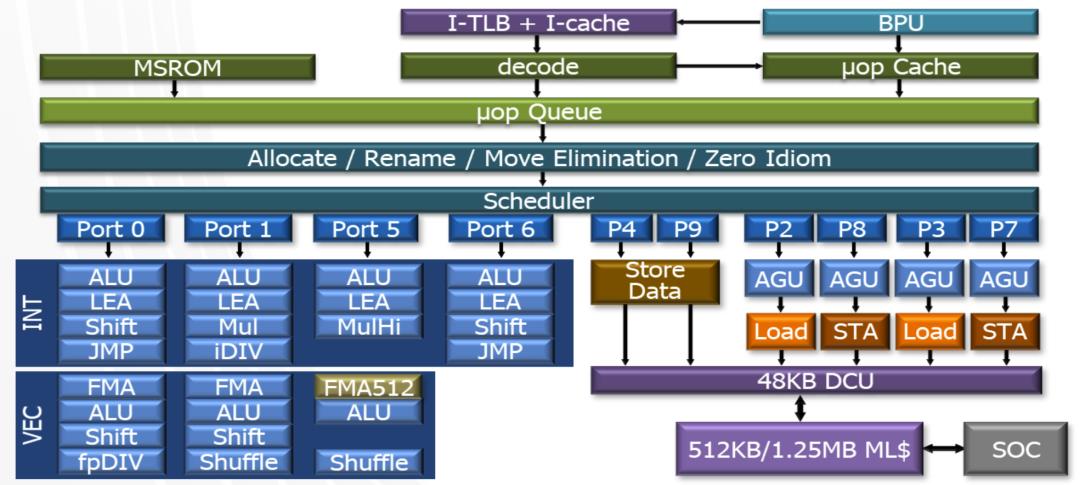
Sunny Cove架构图

CPU内核的“前端”
前端最主要的作用就是尽全力给后端提供充足的弹药,让后端的执行单元尽量保持满负荷运转,从而减少空转造成的性能和功耗浪费。因此前端就需要尽可能多地从内存中获取指令,然后把它们解码成后端能够直接执行的微操作。
由于CPU运行的速度远远高于从内存中读取指令和数据的速度,所以在前端中我们有指令缓存,它的读取速度非常快,可以一次性把很多指令都取过来缓存起来,然后直接进行解码,这样就减少了数据从内存传输到CPU的等待时间。
前端另一个非常重要的功能就是分支预测。上图里的BPU,就是专门做分支预测的单元(Branch Prediction Unit)。当程序出现分支的时候,我们需要提前预判程序大概率会走哪个分支,然后提前取到与这个分支对应的指令和数据。现代CPU中的分支预测可以做到非常准确,比如它采用了很多类似机器学习和神经网络的方法,可以自己学习并预测分支的结果。对于Sunny Cove来说,它提升了前端的容量,并且进一步改进了分支预测的性能,这对内核整体性能的提升都有很大的帮助。

CPU内核的“后端”
CPU微架构的后端有很多ALU,也就是算术逻辑单元(Arithmetic Logic Unit),它们是执行算术和逻辑运算的核心结构。这些ALU可以并行执行前端发送过来的微指令,这就是所谓的超标量结构。这些微指令先通过调度器进行调度,然后发送给不同的ALU去执行。它们可以是按顺序的,也可以是乱序的。这就需要后端去仔细分配这些微指令的执行单元,并且在执行之后再把结果按顺序组合起来。通常来说,能够支持乱序执行的数量越多,内核性能就越高。
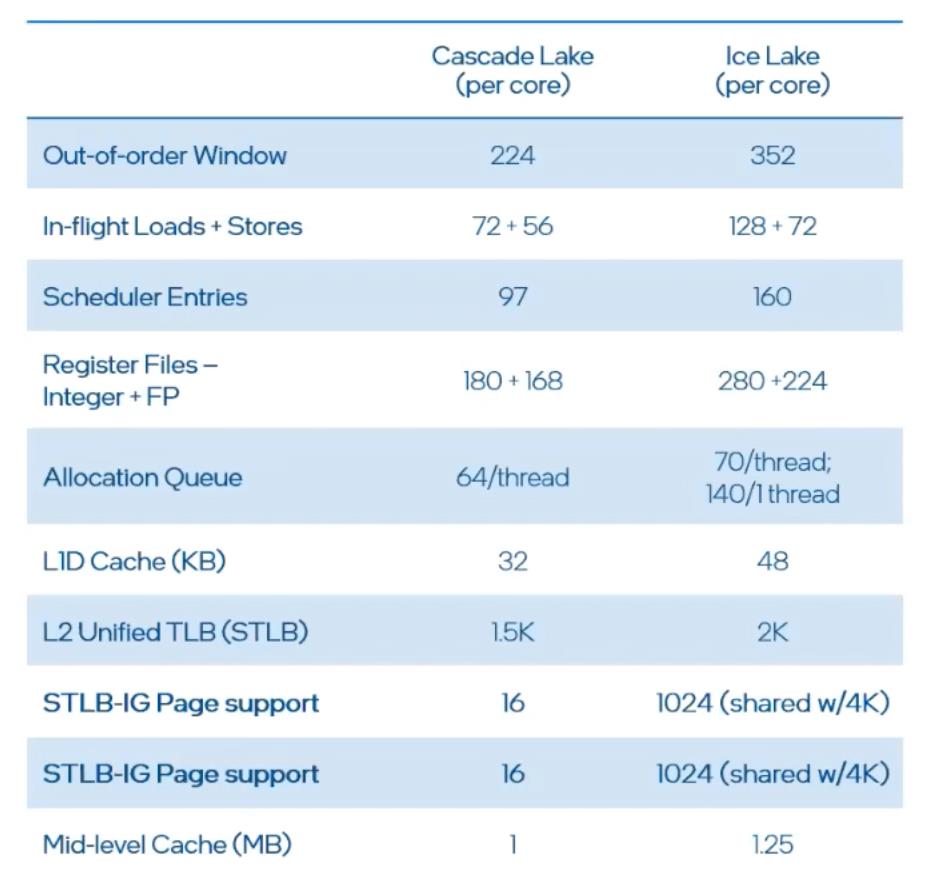
以Sunny Cove为例,它的乱序执行的窗口数量就从上一代的224个增加到了352个,也就是说内核变得更宽了,同时它的调度器和分配单元也都进行了大幅改进,内核上的缓存容量也有增加。所有这些更新升级,都帮助Sunny Cove微架构显著提升了性能。也使得Ice Lake在整数、浮点数、Stream Triad和LINPACK上的平均性能提升到了上一代的1.46倍。
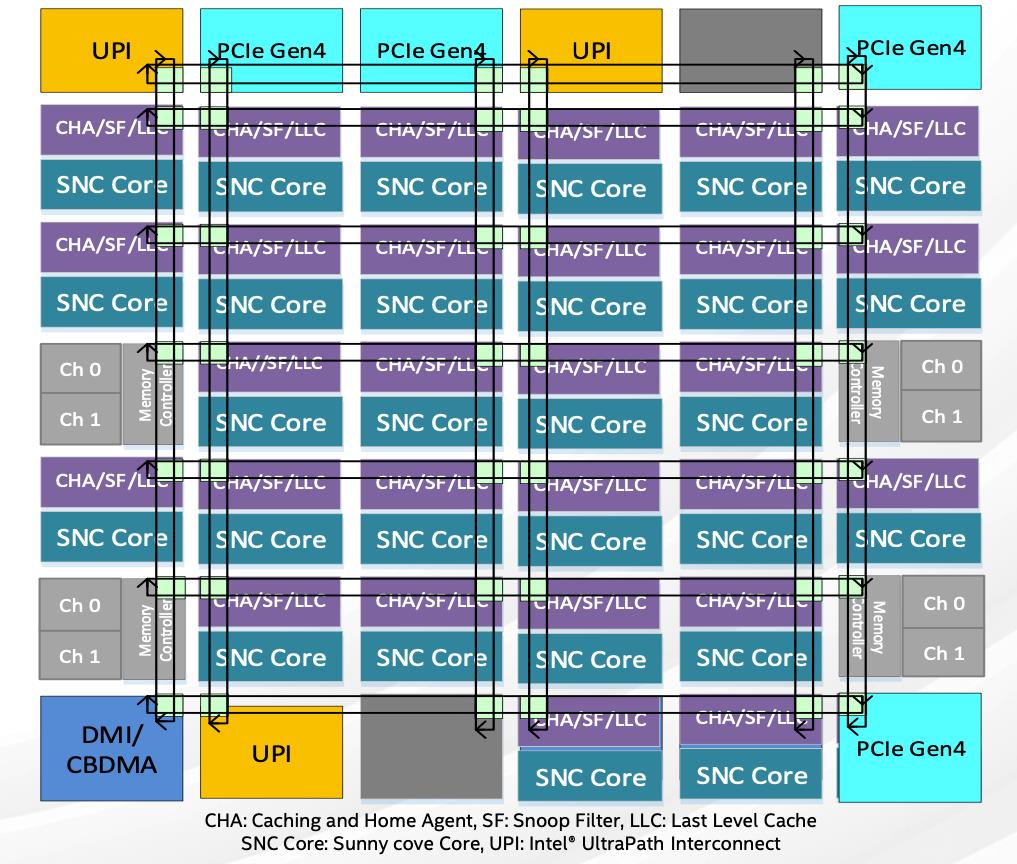
CPU芯片整体架构设计
CPU芯片的整体架构包括内核的排列、以及同样至关重要的存储和I/O子系统。和前一代产品相比,Ice Lake的芯片整体架构也有了不少变化,其中一个最主要的区别就是把I/O单元放在了芯片的南北两侧,这样能够更加充分地利用整个芯片的面积,提升芯片的集成度。
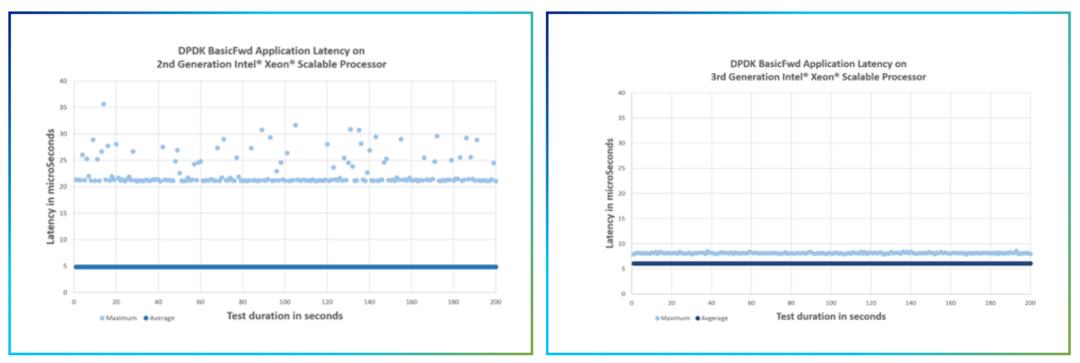
对于缓存架构,Ice Lake采用了分布式的三级缓存LLC,总容量相当于Cascade Lake的1.5倍。这种结构让每个内核都可以访问片上的三级缓存,从而能实现比较均衡的访问时延。这对于数据中心的很多应用场景来说非常重要,因为它们需要的不仅是时延的平均值要低,同时对时延的抖动也非常敏感。这个和“木桶效应”相似,也就是木桶能装的水取决于最短的木条,这就要求每个木条都不能太拉胯。从下图可以看到,Ice Lake在执行网络转发任务的时候(下图右),不仅时延平均值远低于前一代产品(下图左),而且也非常稳定,没有太大波动。
在内存和I/O接口方面,Ice Lake也提升了内存通道的数量和性能,从上一代支持6通道的DDR4 2933,升级到8通道的DDR4 3200,这使得它的内存容量和内存带宽可分别提升到上一代的2.66倍和1.6倍。Ice Lake还支持3个UPI、也就是超级通道互联,这使得双路服务器CPU的通信带宽可以达到11.2GT/s。此外,它还支持64通道的PCIe 4.0,这就使得它能与性能更优的存储和网络设备协同工作。

通用 vs 专用:现代CPU的设计思路演进
就像前面说的,现代CPU的设计思路是通用性能提升+特定场景优化。在特定应用优化上,Ice Lake依然集成有英特尔的深度学习加速技术DL Boost,主攻INT8加速,能将推理性能提升到上一代产品的1.74倍。
Ice Lake另一个重要的性能优化叫做频率选择技术(Speed Select Technology,SST)。它能灵活调整CPU单个和多个核心的基频和睿频,既可以作用于单个核心,也可以对多个核心组成的不同组合进行精细化的调控,从而针对不同的应用场景更好地平衡CPU的性能和功耗。
比如运行在线游戏这类性能要求高、或对于时延比较敏感的业务的时候,就可以把CPU调整到高主频、低核心数的模式,以满足对实时性和响应速度的需求。同样的,对于很多云业务来说,就可以把CPU切换成频率不那么高,但是有更多核心数同时工作的模式,这样就能提升计算的吞吐量,并且带来更高的性价比。
和前一代相比,Ice Lake对SST技术进行了升级,可以借助软件实时修改CPU核心的频率调配方案,不再需要重启服务器,这就让频率的调配更加灵活和便利。
接下来说一下和安全相关的技术支持,这对数据中心和企业级的应用非常关键,特别是在数据敏感型应用和关键业务的领域,我们都需要尽量保证代码和用户数据不被盗取或篡改。
Ice Lake进一步扩展了AVX-512指令集,从而在硬件层面上支持那些常见的密码操作算法的并行执行,从而大幅提升密码操作应用的性能和吞吐量,这就是密码操作硬件加速技术(Crypto Acceleration)。它特别适合于5G基础设施、VPN、还有SSL网络服务器这些需要进行大量密码操作运算的应用场景。据了解IPSec公司就使用了这种加速技术,将VPN数据包的处理速度提升到了原来的1.94倍。
除了密码操作加速之外,Ice Lake还集成了另外一种和安全相关的指令集扩展,叫做软件防护扩展技术SGX。它的本质就是通过指令请求CPU在内存中分配出一块受CPU保护的区域,也叫做“飞地”。这个很像是疫情期间,人们建的封闭的隔离区,只不过这个隔离区里都是没有被感染的人。
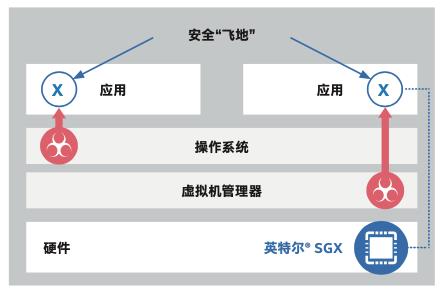
英特尔SGX技术示意图
飞地中受保护的代码和数据不受操作系统或者VMM的影响,即便操作系统、Bios、或者VMM这些比客户软件更为底层的基础软件在黑客攻击或高权限软件攻击中沦陷,通过SGX技术生成的飞地也能更有效地阻断这些攻击,尽力避免其中应用程序和数据被非法复制或篡改。
Ice Lake双路服务器能支持最高达1TB的飞地空间,这就为很多企业推进更大数据量的隐私计算打下了基础。比如蚂蚁集团就利用SGX技术搭建了一个隐私保护机器学习平台,并且基于之前文章介绍过的Analytics Zoo,提出了一个更加安全的分布式端到端推理服务流水线。百度在他们的深度学习平台飞桨中,也通过SGX技术引入了机密计算的能力,这样可以通过更加安全可信的方式,为深度学习模型提供更为多源的数据。
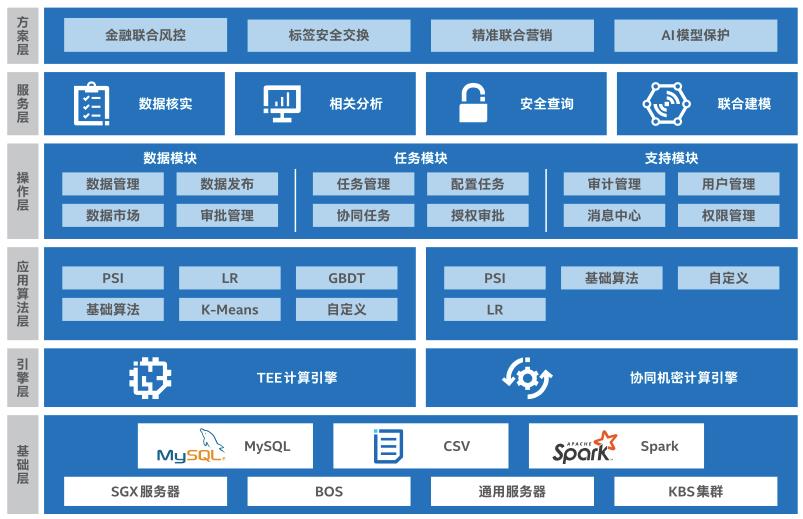
百度MesaTEE整体架构

CPU平台设计
除了CPU本身的算力之外,围绕CPU搭建的计算平台的性能也非常重要。特别是现代服务器和数据中心设计中要兼顾计算、存储、网络这些硬件,同时还有软件和系统的优化。这些软硬件配合使用,不仅能对CPU进行针对性的补强,还可以起到1+1>2效果,最终实现一个高性能、低功耗的系统级解决方案。这个也是现代CPU系统设计的趋势。
在存储方面,Ice Lake可以搭配傲腾持久内存,它能兼顾高性能、低时延,以及大容量和数据的持久性。由于Ice Lake相比上一代产品提升了内存通道的数量和速度,搭配傲腾持久内存200系列时,理论内存带宽平均提升幅度可达32%;单个Ice Lake搭配使用DRAM和傲腾持久内存的时候,内存总容量能达到6TB。

英特尔还发布了全新的、支持PCIe4.0的傲腾固态盘P5800X系列。相比同样支持PCIe4.0的NAND固态盘,它的时延可降低达13倍,QoS提升达66倍,每GB的IOPS提升达26倍,耐用性提升也达33倍以上。

网络方面,Ice Lake搭配了英特尔800系列的以太网卡,它支持数据中心常用的网络端口以及RDMA协议,还能通过ADQ等技术为高优先级网络工作负载提供加速,特别适合于数据中心里的高速网络应用,比如网络功能虚拟化NFV里关于数据转发的加速。

结语
我们以英特尔最新发布的代号为Ice Lake的第三代至强可扩展处理器为例,梳理了现代CPU设计的一些关键理念,包括微架构设计、芯片的内存、接口子系统,还有针对不同应用场景提供的特定加速能力。另外非常重要的就是CPU平台的概念,也就计算、存储和网络这些关键组件如何相互配合、并且实现系统级的平台方案。
(注:本文仅代表作者个人观点,与任职单位无关。)


以上是关于如何设计一个高性能CPU?的主要内容,如果未能解决你的问题,请参考以下文章