写了篇爬虫文章,收到律师函,怎么办
Posted AI科技大本营
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了写了篇爬虫文章,收到律师函,怎么办相关的知识,希望对你有一定的参考价值。

大家好,我是早起。
从写公众号开始,不论是私信还是交流群,常常都会有粉丝会问出类似下面的问题
xx网站能不能爬?
爬xx数据有没有风险?
其实我并不是爬虫从业人员,充其量算爬虫爱好者,去年也转载过一篇相对理性的文章《请不要污名化爬虫!》,今年初还因为在公众号分享某网站的反爬破解收到了律师函,算是在作死的边缘徘徊了一波
今天就简单聊一下爬虫那些事儿。

当我们谈论爬虫
在这里,其实我想吐槽一下,对于大多数非爬虫从业者或者说大部分 Python 爱好者来说,我们写的“爬虫”和大家谈论的爬虫并不是一个东西。
因为基本上也就requests.get或者selenium折腾几下,就算你加个请求头、cookies什么的拿到数据,对方网站也有n种方式识别出来你,同时也不会涉及复杂的反爬、逆向、验证码处理、分布式、爬虫调度等技术,这样的程序在我看来根本算不上爬虫,顶多算是频率高点的模拟请求。
所以保持对爬虫的敬畏之心是好的,但requests或者selenium捣鼓两下,返回了一点数据分析一下,这样的程序和我要讨论的不是同一个爬虫,你随意折腾,一般情况下对方网站懒得理你,也不会有什么法律风险,但也要注意以下几点。

robots协议
其次要说的就是robots协议,相信如果对爬虫有进一步研究的读者都会知道,每个网站都有robots协议这么个玩意,且有些非技术类自媒体常说一定要遵守robots协议之类的文字!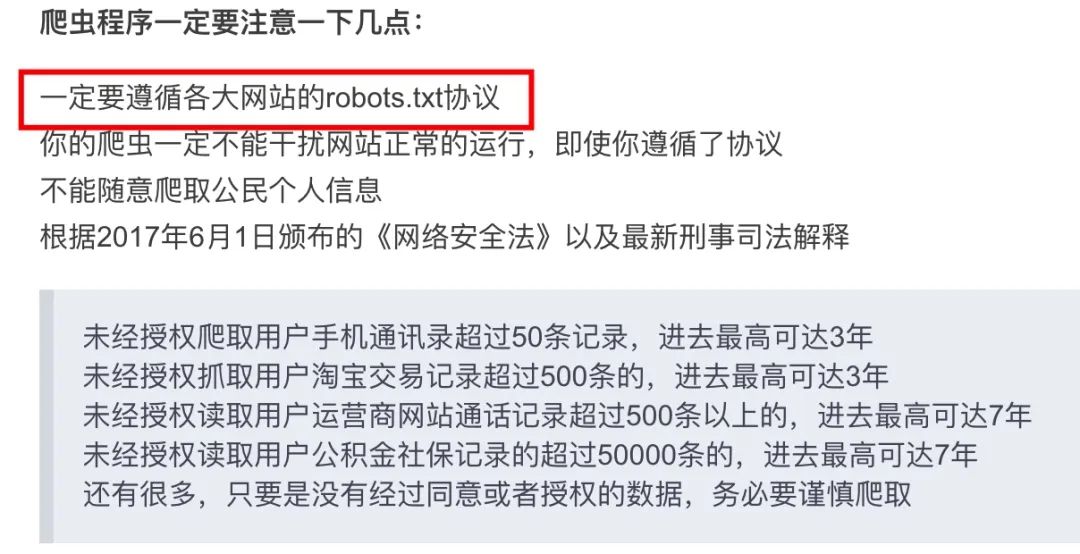
但正如本文开头提到的文章所说,这个协议是一个君子协议,换句话说不论这个网站实际上是否允许你爬,在robots协议上都会限制你爬!
拿很多教程用来讲解Python爬虫入门的 「豆瓣250」 来说,查看豆瓣的robots协议如下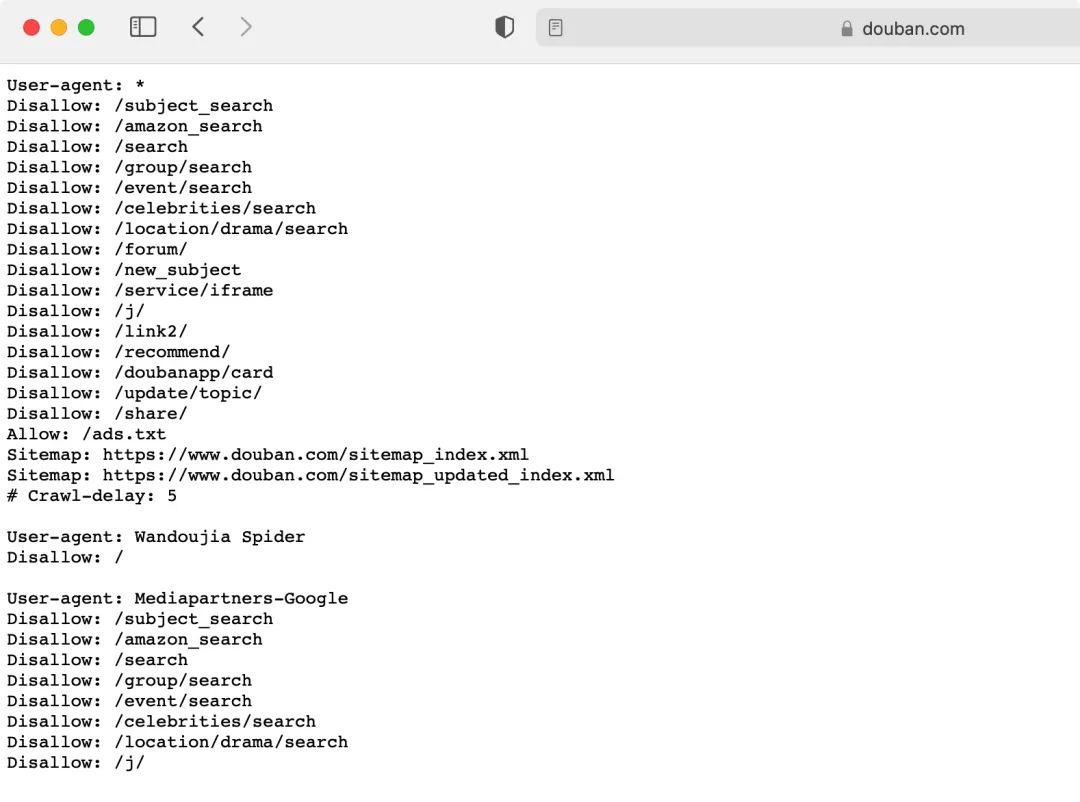
可以看到也是禁止了所有的请求头User-agent: *以及大部分路径下的页面,其中就包括搜索电影信息的Disallow: /search,如果完全遵循该协议,基本什么都玩不了。
其实不仅是robots协议,大部分网站基本上都会在用户服务协议上限制你使用任何爬虫,例如养活了很多技术博主的某团和某点评,在服务条款上就给出了明确的说明

但之所以基本见不到类似的案件主要就像前文所述,大部分人的爬虫程序都是小打小闹,人家懒得理你,但要知道对方是保留了起诉你的权利。
所以对于robots协议,我们应该是带着尊重进行谨慎合理的数据爬取。

数据
为什么说「涉及数据要小心」?因为大部分爬虫把自己爬进去了的案例都是在数据上翻车,不是用来盈利就是涉及隐私数据。
1. 别拿来搞钱
首先要申明的也是最重要的一点 「你爬人家数据想干嘛」,爬点公开数据自己玩一下基本是没有问题的,但若你把人家数据爬下来出售/盈利是绝对不行的。
打个比方说你爬美团数据做了个丑团来竞争,爬大众点评数据做个了付费的小众点评来出售等这都是不可以的,换句话说这和爬虫程序本身没关系,而是你非法使用对方的数据,目前因为爬虫喜提牢饭的案件也或多或少和盈利性活动有关
所以要明白就算你爬下来到本地的数据也是别人的,千万不要用于任何盈利活动!
2. 隐私数据别碰
其次关于数据还有一点需要注意的是,我们都知道公开的数据大部分可以采集,但如果数据涉及到隐私,尤其是公民信息相关数据,如第二小节里面的文章提到的手机号、身份证、公积金社保等数据,千万不要碰。
就算是公开的数据,也尽量不要使用爬虫程序来大批量、无限制的获取,不然小日子会越来越有判头 。至于非公开数据,例如
。至于非公开数据,例如
后台数据
需要一定权限才能获得的数据
付费后才能获得的数据
这类明面上都不让你拿的数据,更别说用爬虫手段获取了。

克制
克制,意思就是当对方网站识别出来你的爬虫行为,例如一些非常规的反爬措施,或者因为较高频率的请求而ban掉你的ip等情况时,我们就需要有所克制,例如合理的绕过反爬、降低请求速度等,尤其注意不要对对方的正常业务造成影响。
并且这个 「正常业务」是否受到影响的解释权完全在对方网站,就算你1秒请求1次,理论上他也能告你影响其正常业务开展。
其次要克制的就是在成功对某网站成功进行了反爬/逆向等操作后,不要太得瑟,不要指名道姓的说出对方网站,就像我一样,仅仅发了篇反爬绕过讲解文章,就光速收到律师函(发文后第二天),当我问到「为什么那么多人发,就给我发律师函」,对方表示看到你就要处理你
结果就像前面说的,对方有多种方式来告你,更别说反爬绕过了,我只能配合删除相关文章。
所以在反爬、频率控制等操作上,一定要克制+谨慎,尤其注意在分享反爬技术上不要太明目张胆,一个好的做法是自己复制一个类似的案例网站(可惜我不会),然后就可以为所欲为的进行技术拆解。

补充
需要额外注意的是,如果是基于别人的需求去开发爬虫程序,比如帮别人写个爬虫程序赚点零花钱、完成boss的任务等,就需要明确需求本身是否有侵权行为,以及需求方基于你的爬虫程序是否用于侵权活动。
例如老板让你用爬虫爬点某网站公开评论数据,然后简单分析下数据写个报告,我认为这是不会有太大风险的,而如果是让你爬取某付费数据或爬数据用于自己公司的商业行为,那完全可以拒绝并拉黑,员工被老板坑的案例实在太多了,希望大家在遇到此种情况下可以正确判断。

小结
以上仅是从我一个非爬虫从业人员角度的一些看法,其实核心就是爬虫无罪,大多数翻车的案例与爬虫本质上没有太大关系,在写爬虫程序时需要保持尊重、谨慎的心态,尊重对方网站的反爬、数据,谨慎、合理去写代码。同时爬虫的水很深,要学的知识很多,绝对不只是 requests 请求两下就算爬虫,基本上涉及到计算、编程开发的方方面面,希望大家可以一起学习、进步。


以上是关于写了篇爬虫文章,收到律师函,怎么办的主要内容,如果未能解决你的问题,请参考以下文章