Video Action Recognition浅析
Posted 等待破茧
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Video Action Recognition浅析相关的知识,希望对你有一定的参考价值。
转载自https://zhuanlan.zhihu.com/p/340011359
一篇比较经典的综述,可能会花几篇来分别说明:
A Comprehensive Study of Deep Video Action Recognition
将来有可能入坑video方向,就简单把最新的相关论文学习一下,主要是做的事情多了,之前看的论文就老忘:

A Comprehensive Study of Deep Video Action Recognition
本文的书写具有明确的脉络
1、对当前的VAR数据集进行了介绍
2、对200多篇VAR领域的论文进行了分析和汇总
3、分析当前VAR领域的挑战和机遇
因为具有一些深度学习背景,所以我们不通篇逐字的进行翻译学习,只整体按照其行文思路,中间主要记录一些经典研究以及之后值得展开的点:
背景:
VAR任务是理解video中人的行为,其中涉及识别、定位、和预测人的行为的任务。具有很多真实场景下的应用:behavior analysis, video retrieval, human-robot interaction, gaming, and entertainment.
该领域的发展也是近几年被大力关注,至于为什么,不用说肯定是其他的坑没什么可填的了,数据集从11年到15年公布的3个,到现在16年到20年就13个了。俗话说:预先灌其水,必先利其数据集。另外听说对行为分类任务和对imagenet图像分类任务类似,都比较硬核,需要大量的资源是肯定的,但是觉得视频行为分析的可延展性要比图像分类大一些,毕竟考虑的模态多了,研究的方法也相应的比较多,这样应用和可挖的点也会多一些,尽管万物皆深度了,硬核就硬核把!!!

发展趋势:
1、双流网络:光流+RGB流,其中RGB流就是连续帧的图像,用来捕获其中的位置、特征等信息,而光流反应的是连续运动帧中运动物体的运动趋势,是行为识别中的运动信息。这类方法就是结合RGB特征和运动特征的双流网络来进行行为识别。(光流好像需要预先计算,需要大量的预置存储空间,因此本质上不太实用;另外光流是分析运动情况的,那么如果针对摄像头也是运动的视频场景不知道是不是也有相对改进的方法) 这部分看论文作者好像是南大的Limin Wang老师做的比较多也比较好(毕竟汤晓鸥的弟子。。。)
双流网络开篇:Karen Simonyan and Andrew Zisserman. Two-Stream Convolutional Networks for Action Recognition in Videos. In Advances in Neural Information Processing Systems (NeurIPS), 2014.
TDD: Limin Wang, Yu Qiao, and Xiaoou Tang. Action Recogni- tion With Trajectory-Pooled Deep-Convolutional Descrip- tors. In The IEEE Conference on Computer Vision and Pat- tern Recognition (CVPR), 2015.
LRCN: Jeff Donahue, Lisa Anne Hendricks, Marcus Rohrbach, Subhashini Venugopalan, Sergio Guadarrama, Kate Saenko, and Trevor Darrell. Long-term Recurrent Convo- lutional Networks for Visual Recognition and Description. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2015.
Fusion: Christoph Feichtenhofer, Axel Pinz, and Andrew Zisser- man. Convolutional Two-Stream Network Fusion for Video Action Recognition. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016.
TSN:Limin Wang, Yuanjun Xiong, Zhe Wang, Yu Qiao, Dahua Lin, Xiaoou Tang, and Luc Van Gool. Temporal Seg- ment Networks: Towards Good Practices for Deep Action Recognition. In The European Conference on Computer Vision (ECCV), 2016.
2、3D卷积:既然需要结合图像特征与运动信息,那不如就直接塞到3D卷积黑盒里面去,给个监督标签自己让它学,虽然道理是这么个道理,但是不用细看就知道,肯定有很多需要额外考虑的地方,比如运动行为在我看来是一个更low-level的特征,全都混到卷积去不一定会好吧,另外3D卷积的具体实现中,虽然代码中只是简单的多了个depth维度,但是固定深度输入总时要比固定size输入麻烦?反正我是没听说过channel上的内插。。。此外,最近一些研究都在将3D卷积进行优化,就是嫌弃它的计算量过大……
I3D: Joao Carreira and Andrew Zisserman. Quo Vadis, Ac- tion Recognition? A New Model and the Kinetics Dataset. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017.
R3D: Kensho Hara, Hirokatsu Kataoka, and Yutaka Satoh. Can Spatiotemporal 3D CNNs Retrace the History of 2D CNNs and ImageNet? In The IEEE Conference on Computer Vi- sion and Pattern Recognition (CVPR), 2018.
S3D: Saining Xie, Chen Sun, Jonathan Huang, Zhuowen Tu, and Kevin Murphy. Rethinking Spatiotemporal Feature Learn- ing: Speed-Accuracy Trade-offs in Video Classification. In The European Conference on Computer Vision (ECCV), 2018.
Non-local: Xiaolong Wang, Ross Girshick, Abhinav Gupta, and Kaim- ing He. Non-Local Neural Networks. In The IEEE Confer- ence on Computer Vision and Pattern Recognition (CVPR), 2018.
SlowFast: Christoph Feichtenhofer, Haoqi Fan, Jitendra Malik, and Kaiming He. SlowFast Networks for Video Recognition. In The IEEE International Conference on Computer Vision (ICCV), 2019.
3、围绕计算效率上展开,使之在更大size的数据集上训练,适用于真实世界场景
Hidden TSN: Yi Zhu, Zhenzhong Lan, Shawn Newsam, and Alexan- der G. Hauptmann. Hidden Two-Stream Convolutional Networks for Action Recognition. In The Asian Conference on Computer Vision (ACCV), 2018.
TSM: Ji Lin, Chuang Gan, and Song Han. TSM: Temporal Shift Module for Efficient Video Understanding. In The IEEE In- ternational Conference on Computer Vision (ICCV), 2019.
X3D: Christoph Feichtenhofer. X3D: Expanding Architectures for Efficient Video Recognition. In The IEEE Confer- ence on Computer Vision and Pattern Recognition (CVPR), 2020.
TVN: AJ Piergiovanni, Anelia Angelova, and Michael S. Ryoo. Tiny Video Networks. arXiv preprint arXiv:1910.06961, 2019.
上面只列举了一些典型的论文,后面应该都会看,下面来具体分析每一部分。
数据集:
数据集如今也开源了不少,具体比较常用的应该是Kinetics和something系列了,
简述一下构建数据集的步骤,可能会对后面训练理解标签含义有帮助:
1、定义action list,此部分通过组合之前数据集中的定义,以及添加新的action类别定义得到
2、通过匹配网上各种小视频的title和subtitle来爬取相关action list中定义的类别
3、手动标注一个具体action类别的起始与结束时间,用以后面的训练
4、数据清洗,删除重复数据以及无关噪音数据
论文中列出的现开源的数据集
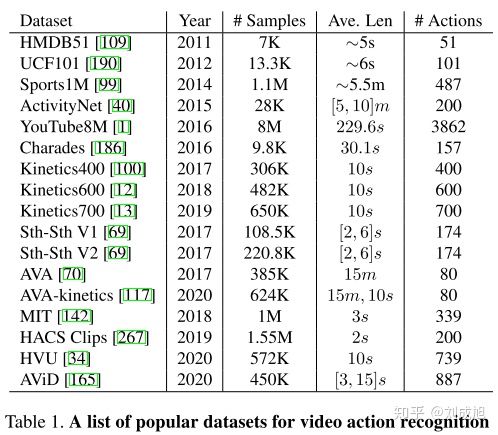
仅仅列出当前数据集的size还不够直观,为了明确我们之后要解决对应数据的那些问题,作者使用一张图对数据中的特点进行了分析,个人觉得这部分是数据集分析的highlight:

从上到下,我们可以逐个去看:
1、顶部,对于一些video中的行为,我们通过单帧中的context和scene就可以进行判断,比如骑自行车,此时运动时序信息是否就变得没那么重要?video的行为识别可以退化成2D分类或者图像理解(human+bike+human on bike=riding a bike)或者踢足球,足球场的场景又起到了决定性作用
2、中间,对于一些video中的行为,需要连续几帧的长时建模去判断其整个行为,比如扔东西,此时就不能用简单的图像分类或理解进行(pen + hand + pen in hand可能等于dropping pen out,也可能等于picking pen up),此时扔的东西的时序的运动信息就需要被考虑
3、底部,对于一些行为也具有很大的类内差异,比如climbing这个行为,主体可以从人延申到动物,其场景也可以多种多样,爬山、爬楼、怕树,这样就类似细粒度分类中的问题,类间差异小,类内差异大的问题,同时强行学习该类行为也不容易稳定。
挑战:
VAR的挑战也从两部分描述:
1、数据集部分:
1)标签定义不明确:人的行为一般都是复合性质的,仅用单一标签定义其行为不够明确
2)annotation不明确:标注费时费力,且不易明确标记行为的起始和结束时间节点
3)数据集不统一:Kinetics数据只提供下载链接,容易发生不同数据的评估问题,因此不宜客观比较
2、模型部分:
1)人类动作行为类内差异大,类间差异小:类内因拍摄视角、执行行为的速度等因素等影响而导致同一类动作差异大,类间因为相同的场景,或者类似的运动模式,导致类间差异小,不易区分
2)行为识别设计多角度问题、多模态问题、时许长短依赖问题,每一块都有可以深挖和研究的点,能够同时使用单个模型适应各种问题很困难
3)video本身参数量比较大,所以训练和推理起来也耗时耗力,如何结合当前CV图像中的问题分析方法,以及NLP中长短时序的分析方法,减少资源消耗才能真正实际应用

对这个领域大致有一些了解后,之后会花大量篇幅梳理一下具体每个主线和支线的论文和可研究发掘的点……
以上是关于Video Action Recognition浅析的主要内容,如果未能解决你的问题,请参考以下文章