Playwright入门
Posted 凌空摘星
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Playwright入门相关的知识,希望对你有一定的参考价值。
简介
Playwright是微软开源的一个UI自动化测试工具。添加了默认等待时间增加脚本稳定性,并提供视频录制、网络请求支持、自定义的定位器、自带调试器等新特性。
安装
pip install playwright # 安装playwright的python版本
playwright install # 安装playwright自带的浏览器和ffmepg,此步骤耗时较长
开始录制
在命令行执行以下代码
playwright codegen
自动打开浏览器和录制界面
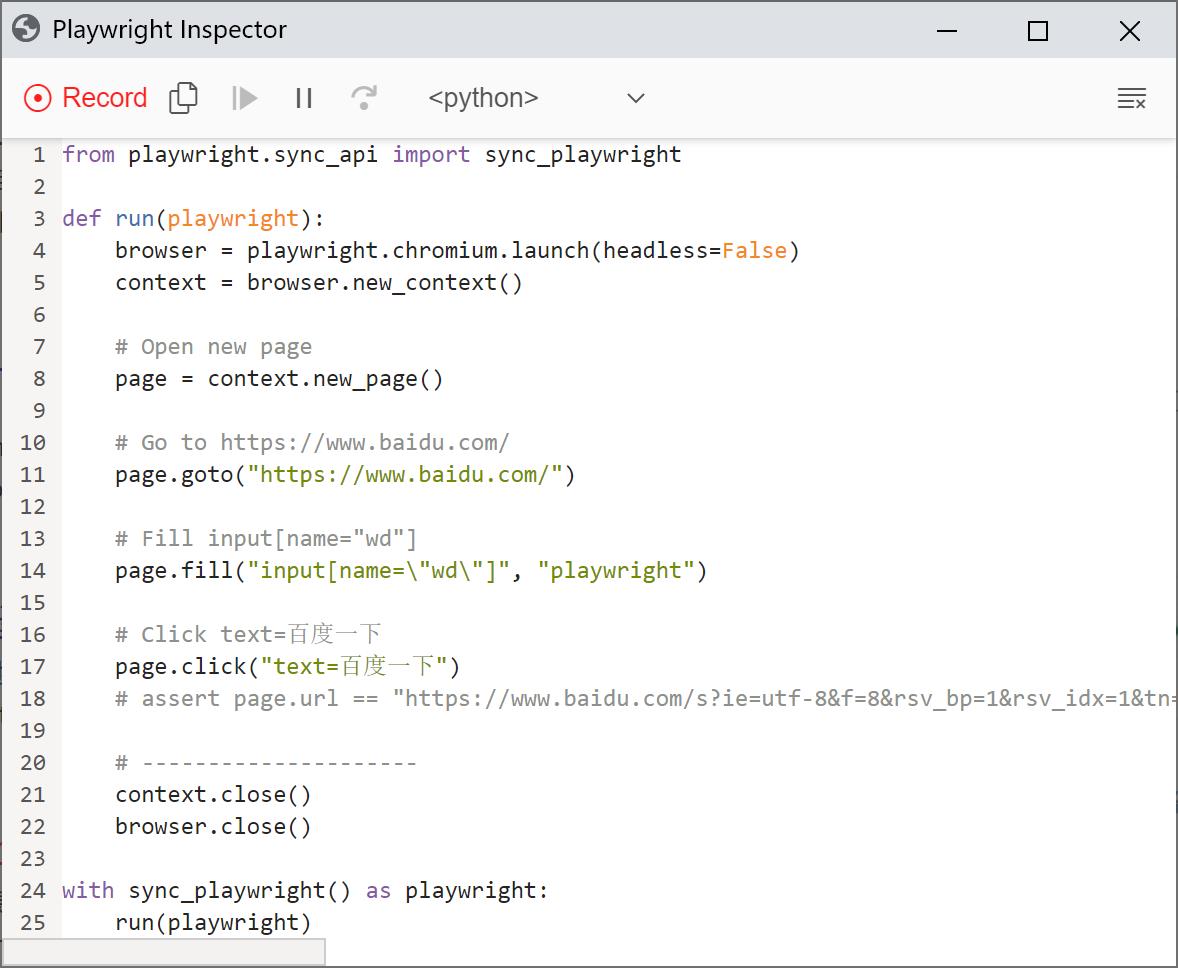
以百度为例,输入百度网址打开百度页面,搜索框中输入“playwright”,点击“百度一下”按钮,录制代码如下
from playwright.sync_api import sync_playwright
def run(playwright):
browser = playwright.chromium.launch(headless=False)
context = browser.new_context()
# Open new page
page = context.new_page()
# Go to https://www.baidu.com/
page.goto("https://www.baidu.com/")
# Click input[name="wd"]
page.click("input[name=\\"wd\\"]")
# Fill input[name="wd"]
page.fill("input[name=\\"wd\\"]", "playwright")
# Click text=百度一下
page.click("text=百度一下")
# assert page.url == "https://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&rsv_idx=1&tn=baidu&wd=playwright&fenlei=256&oq=playwright&rsv_pq=bf1abd6c000029f7&rsv_t=1937PYyfHvfyS6fay57V1zS1iCIiYC4%2B8I6srjLqYYkXrf8H9kce%2BLQKVzA&rqlang=cn&rsv_dl=tb&rsv_enter=0&rsv_btype=t&prefixsug=playwright&rsp=5"
# Click text=百度一下
# with page.expect_navigation(url="https://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&rsv_idx=1&tn=baidu&wd=playwright&fenlei=256&oq=playwright&rsv_pq=a03207ba00008498&rsv_t=ecf2ko5wPyHrjSHwUBLAZZwxkyObcfsg5ge7apN1BeAdigW%2BzzxD%2F3CJI7k&rqlang=cn&rsv_dl=tb&rsv_enter=0&rsv_btype=t&prefixsug=playwright&rsp=5"):
with page.expect_navigation():
page.click("text=百度一下")
# Click text=百度一下
page.click("text=百度一下")
# assert page.url == "https://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&rsv_idx=1&tn=baidu&wd=playwright&fenlei=256&oq=playwright&rsv_pq=bf1abd6c000029f7&rsv_t=1937PYyfHvfyS6fay57V1zS1iCIiYC4%2B8I6srjLqYYkXrf8H9kce%2BLQKVzA&rqlang=cn&rsv_dl=tb&rsv_enter=0&rsv_btype=t&prefixsug=playwright&rsp=5"
# ---------------------
context.close()
browser.close()
with sync_playwright() as playwright:
run(playwright)
删除不必要的代码,简化后如下
from playwright.sync_api import sync_playwright # 导入playwright同步api
def run(playwright): # 定义run方法
browser = playwright.chromium.launch(headless=False) # 创建chromium的browser对象,当前使用的是playwright安装的自带的chromium
context = browser.new_context() # 创建context对象,context之间是相互隔离的,可以理解为轻量级的浏览器实例
page = context.new_page() # 创建page对象,真正打开浏览器界面
page.goto("https://www.baidu.com/") # 跳转到百度url
page.fill("input[name=\\"wd\\"]", "playwright") # 通过css定位在搜索框中输入"playwright"
with page.expect_navigation(): # 预期结果,点击"百度一下"按钮后会发生页面导航
page.click("text=百度一下") # 通过playwright自定义的文字定位器定位"百度一下"按钮并点击
# ---------------------
context.close() # 关闭context
browser.close() # 关闭browser
with sync_playwright() as playwright: # playwright使用入口,通过上下文方式
run(playwright) # 调用run方法,将playwright实例传入
通过以上代码可以了解到:
- playwright支持同步和异步两种使用方法
- 不需要为每个浏览器下载webdriver
- 相比selenium多了一层context抽象
- 支持无头浏览器,且较为推荐(headless默认值为True)
- 可以使用传统定位方式(CSS,XPATH等),也有自定义的新的定位方式(如文字定位)
- 没有使用selenium的先定位元素,再进行操作的方式,而是在操作方法中传入了元素定位,定位和操作同时进行(其实也playwright也提供了单独的定位方法,作为可选)
- 很多方法使用了with的上下文语法
基本概念
browser
浏览器:支持多种浏览器:Chromium(chrome、edge)、Firefox、WebKit(Safari),一般每一种浏览器只需要创建一个browser实例。示例:
browser = playwright.chromium.launch()
browser = playwright.firefox.launch()
context
上下文:一个浏览器实例下可以有多个context,将浏览器分割成不同的上下文,以实现会话的分离,如需要不同用户登录同一个网页,不需要创建多个浏览器实例,只需要创建多个context即可。示例:
context1 = browser.new_context()
context2 = browser.new_context()
page
页面:一个context下可以有多个page,一个page就代表一个浏览器的标签页或弹出窗口,用于进行页面操作。示例:
page = context.new_page()
# 显式导航,类似于在浏览器中输入URL
page.goto('http://example.com')
# 在输入框中输入字符
page.fill('#search', 'query')
# 点击提交按钮
page.click('#submit')
# 打印当前url
print(page.url)
frame
一个页面至少包含一个主frame,新的frame通过iframe标签定义,frame之间可以进行嵌套,只有先定位到frame才能对frame里面的元素进行定位和操作。playwright默认使用page进行的元素操作会重定向到主frame上。示例:
# 通过名称获得frame
frame = page.frame('frame-login')
# 通过frame的url获得frame
frame = page.frame(url=r'.*domain.*')
# 通过选择器获得frame
frame_element_handle = page.query_selector('.frame-class')
frame = frame_element_handle.content_frame()
# 操作frame中的元素
frame.fill('#username-input', 'John')
选择器
所有元素操作都需要使用选择器定位到要操作的元素,playwright同时支持css、xpath和自定义的选择器,使用时无需指定类型,playwright会自动进行判断。示例:
# Using data-test-id= selector engine
page.click('data-test-id=foo')
# CSS and XPath selector engines are automatically detected
page.click('div')
page.click('//html/body/div')
# Find node by text substring
page.click('text=Hello w')
# Explicit CSS and XPath notation
page.click('css=div')
page.click('xpath=//html/body/div')
# Click an element with text 'Sign Up' inside of a #free-month-promo.
page.click('#free-month-promo >> text=Sign Up')
# Capture textContent of a section that contains an element with text 'Selectors'.
section_text = page.eval_on_selector('*css=section >> text=Selectors', 'e => e.textContent')
自动等待
像page.click(selector)、page.fill(selector, value)之类的元素操作会自动等待元素可见且可操作。
# Playwright 会等待 #search 元素出现在 DOM 中
page.fill('#search', 'query')
# Playwright 会等待元素停止动画并接受点击
page.click('#search')
# 等待 #search 出现在 DOM 中
page.wait_for_selector('#search', state='attached')
# 等待 #promo 可见, 例如具有 `visibility:visible`
page.wait_for_selector('#promo')
# 等待 #details 变得不可见, 例如通过 `display:none`.
page.wait_for_selector('#details', state='hidden')
# 等待 #promo 从 DOM 中移除
page.wait_for_selector('#promo', state='detached')
以上是关于Playwright入门的主要内容,如果未能解决你的问题,请参考以下文章
微软开源最强Python自动化神器Playwright!不用写一行代码!