学习笔记李宏毅2021春机器学习课程第7.2节:自监督学习
Posted Harryline-lx
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了学习笔记李宏毅2021春机器学习课程第7.2节:自监督学习相关的知识,希望对你有一定的参考价值。
1 为什么BERT有用?
最常见的解释是,当输入一串文本时,每个文本都有一个对应的向量。对于这个向量,我们称之为embedding。
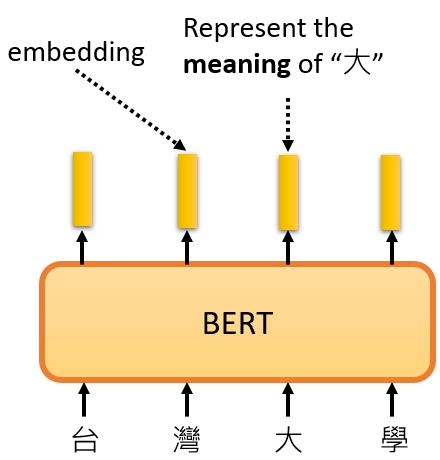
它的特别之处在于,这些向量代表了输入词的含义。例如,模型输入 “台湾大学”,输出4个向量。这4个向量分别代表 “台”、“湾”、"大 "和 “学”。
更具体地说,如果你把这些词所对应的向量画出来,或者计算它们之间的距离,你会发现,意思比较相似的词,它们的向量比较接近。例如,"鸟 "和 "鱼 "是动物,所以它们可能更接近。

你可能会问,中文有歧义,其实不仅是中文,很多语言都有歧义。BERT可以考虑上下文,所以,同一个词,比如说 “苹果”,它的上下文和另一个 "苹果 "不同,它们的向量也不会相同。
水果 "苹果 "和手机 "苹果 "都是 “苹果”,但根据上下文,它们的含义是不同的。所以,它的向量和相应的embedding会有很大不同。水果 "苹果 "可能更接近于 “草”,手机 "苹果 "可能更接近于 “电”。
现在我们看一个真实的例子。假设我们现在考虑 "苹果 "这个词,我们会收集很多有 "苹果 "这个词的句子,比如 “喝苹果汁”、"苹果MacBook "等等。然后,我们把这些句子放入BERT中。
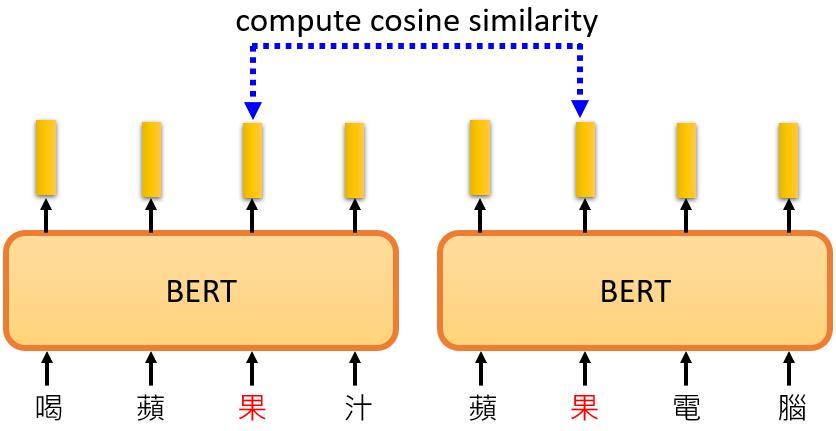
接下来,我们将计算"苹果"一词的相应embedding。输入"喝苹果汁",得到一个"苹果"的向量;输入"苹果MacBook",又得到这个”苹果“的向量。那事实上我们可以看到这两个向量离得比较远,这是因为在Encoder中存在Self-Attention,根据 "苹果"一词的不同语境得到的向量会有所不同。接下来,我们计算这些结果之间的cosine similarity,即计算它们的相似度,结果是这样的:
-
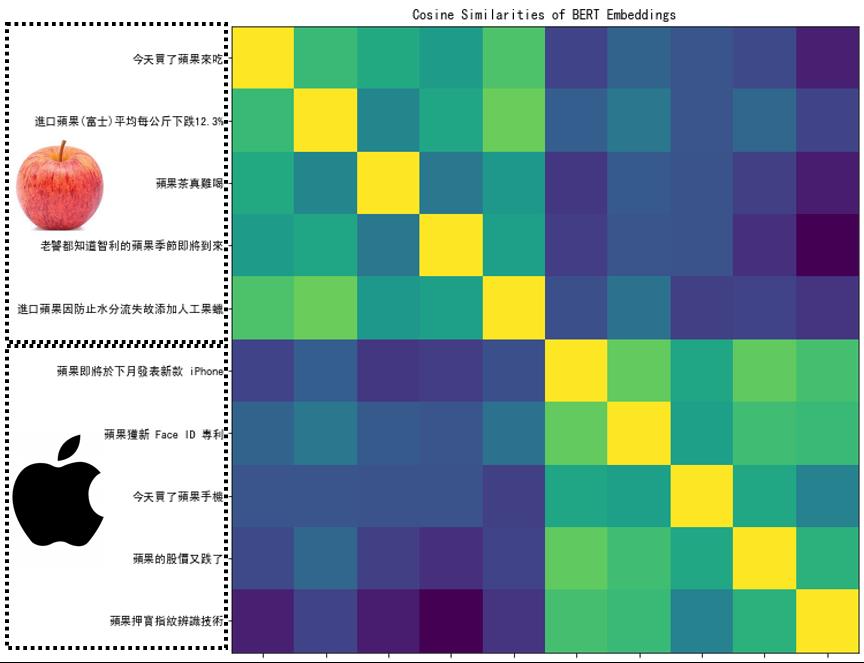
前5个句子中的 "苹果"代表可食用的苹果。例如,第一句是 “我今天买了苹果吃”,第二句是 “进口富士苹果平均每公斤多少钱”,第三句是 “苹果茶很难喝”,第四句是 “智利苹果的季节来了”,第五句是 “关于进口苹果的事情”,这五个句子里的"苹果 "意思就比较接近。
-
后面五个句子也有 "苹果 "一词,但提到的是苹果公司的苹果。例如,“苹果即将在下个月发布新款iPhone”,“苹果获得新专利”,“我今天买了一部苹果手机”,“苹果股价下跌”,“苹果押注指纹识别技术”。
计算每一对之间的相似度,得到一个10×10的矩阵。相似度越高,这个颜色就越浅。因为自己和自己之间的相似度一定是最大的,所以对角线位置的颜色是最浅的。但前五个 "苹果 "和后五个 "苹果 "之间的相似度相对较低
按这个结果看来,BERT在填空的过程中已经学会了每个汉字的意思。也许它真的理解了中文,对它来说,汉字不再是毫无关联的,既然它理解了中文,它就可以在接下来的任务中做得更好。
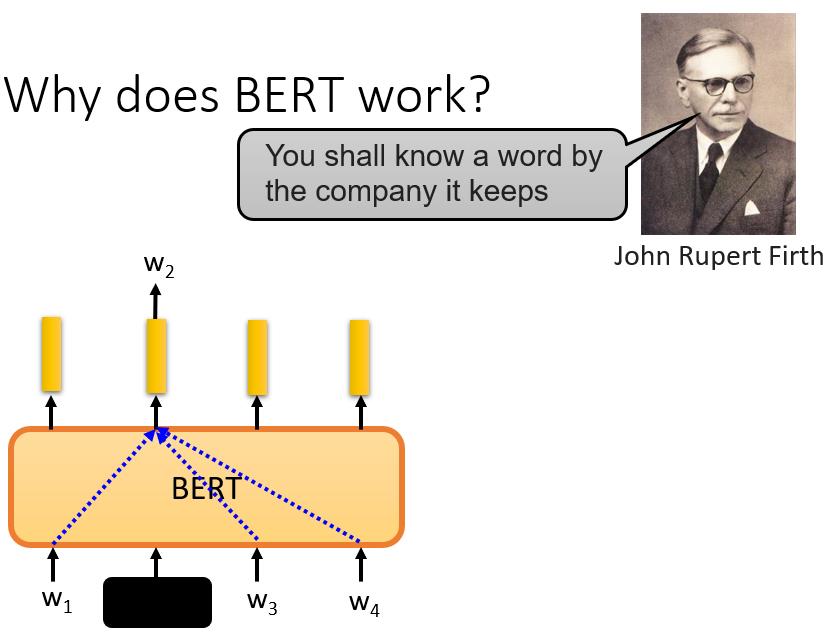
那么接下来你可能会问,"为什么BERT有如此神奇的能力?约翰-鲁伯特-弗斯,一位60年代的语言学家,提出了一个假说。他说,要知道一个词的意思,我们需要看它的 “Company”,也就是经常和它一起出现的词汇,也就是它的上下文。
-
所以以苹果(apple)中的果字为例。如果它经常与 “吃”、"树 "等一起出现,那么它可能指的是可食用的苹果。
-
如果它经常与电子、专利、股票价格等一起出现,那么它可能指的是苹果公司。
当我们训练BERT时,我们给它w1、w2、w3和w4,我们覆盖w2,并告诉它预测w2,而它就是从上下文中提取信息来预测w2。所以这个向量是其上下文信息的精华,可以用来预测w2是什么。
这样的想法在BERT之前已经存在了。在word embedding中,有一种技术叫做CBOW。
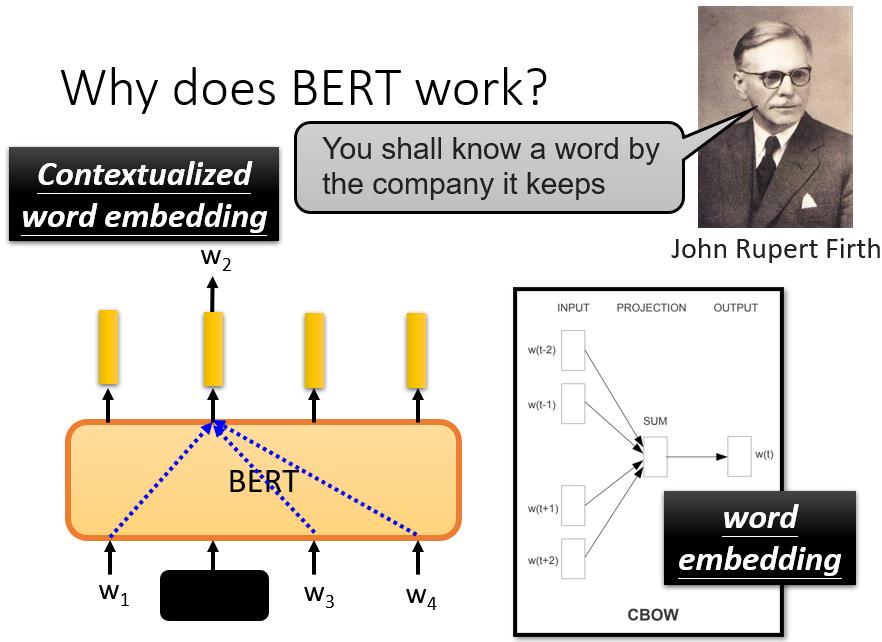
CBOW所做的,与BERT完全一样。一句话中有一个空白,并要求它预测空白处的内容。这个CBOW,这个word embedding技术,可以给每个词汇一个向量,代表这个词汇的意义。
今天,当你使用BERT的时候,就相当于一个深度版本的CBOW,你可以做更复杂的事情,而且BERT还可以根据不同的语境,从同一个词汇产生不同的embedding。因为它是一个考虑到语境的高级版本的词embedding,BERT也被称为Contextualized embedding,这些由BERT提取的向量或embedding被称为Contextualized embedding。
2 多语言的BERT
接下来要讲的是一种叫做Multi-lingual BERT的BERT。Multi-lingual BERT有什么神奇之处?
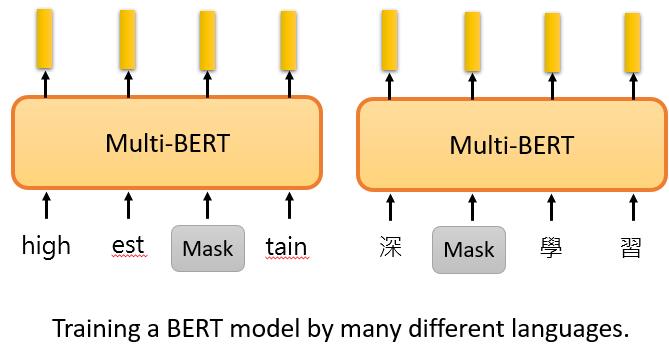
它是由很多语言来训练的,比如中文、英文、德文、法文等等,用填空题来训练BERT,这就是Multi-lingual BERT的训练方式。
2.1 跨语言的阅读理解
google训练了一个Multi-lingual BERT,它能够做104种语言的填空题。神奇的地方来了,如果你用英文问答数据训练它,它就会自动学习如何做中文问答
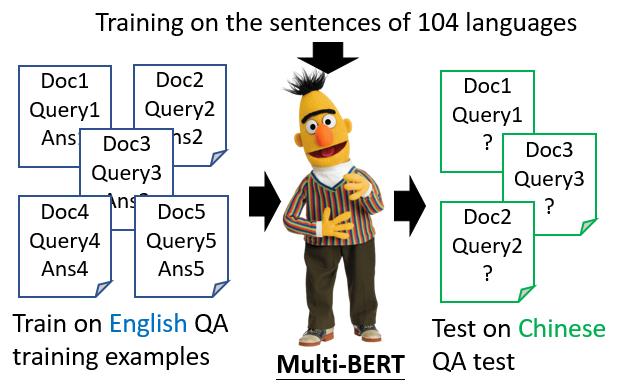
所以这里有一个真实的实验例子,这是一些训练数据。他们用SQuAD进行fine-tune。这是一个英文Q&A数据集。中文数据集是由台达电发布的,叫DRCD。
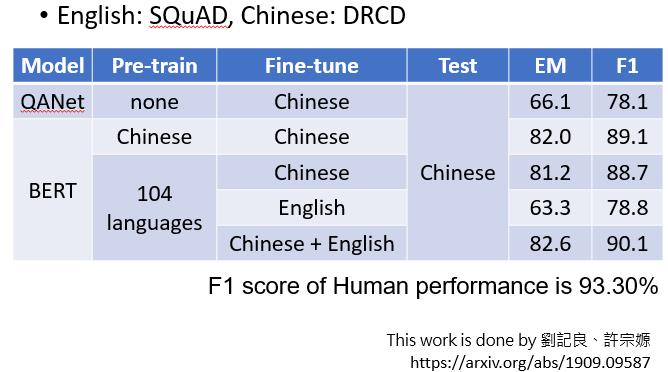
在BERT提出之前,效果并不好。在BERT之前,最强的模型是QANet。它的F1得分只有78.1,这个F1得分事实上并不是准确率,但你可以暂时把它看成是准确率或正确率。
如果我们允许用中文填空题进行预训练,然后用中文Q&A数据进行微调,那么它在中文Q&A测试集上的正确率达到89%。因此,其表现是相当令人印象深刻的。
神奇的是,如果我们把一个Multi-lingual的BERT,用英文Q&A数据进行微调,它仍然可以回答中文Q&A问题,并且有78%的正确率,这几乎与QANet的准确性相同。它从未接受过中文和英文之间的翻译训练,也从未阅读过中文Q&A的数据集。它在没有任何准备的情况下参加了这个中文Q&A测试,尽管它从未见过中文测试,但不知为何,它能回答这些问题。
2.2 跨语言对齐
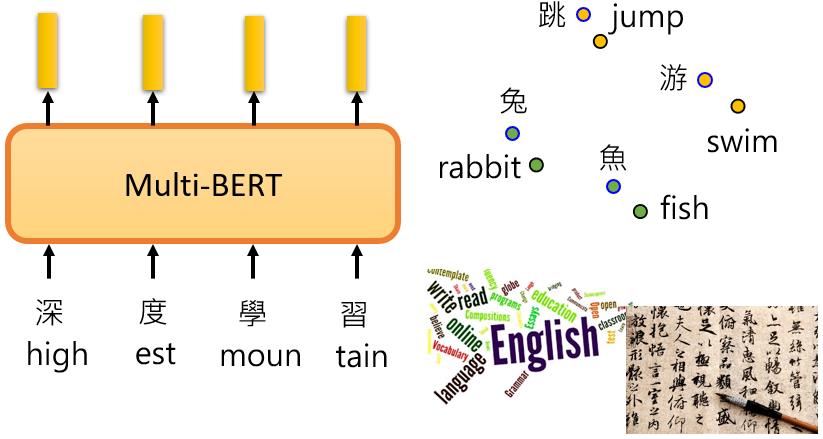
那么BERT是怎么做到跨语言问答的呢?一个简单的解释是:也许对于多语言的BERT来说,不同的语言并没有那么大的差异。无论你用中文还是英文显示,对于具有相同含义的单词,它们的embedding都很接近。汉语的"跳"与英语中的 "jump"接近,汉语中的 "鱼"与英语中的 "fish"接近,汉语中的 "游"与英语中的 "swim"接近,也许在学习过程中它已经自动学会了。
这是可以被验证的。验证的标准被称为Mean Reciprocal Rank,缩写为MRR。我们在这里不做详细说明。你只需要知道,MRR的值越高,不同embedding之间的Alignment就越好。
更好的Alignment意味着,具有相同含义但来自不同语言的词将被转化为更接近的向量。如果MRR高,那么具有相同含义但来自不同语言的词的向量就更接近。
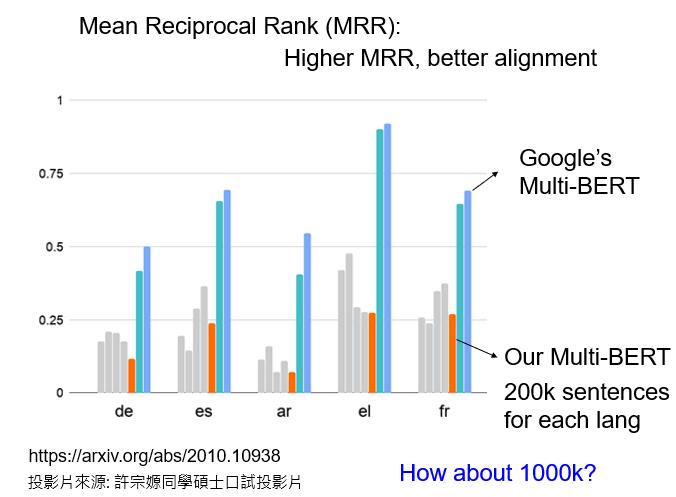
这条深蓝色的线是谷歌发布的104种语言的Multi-lingual BERT的MRR,它的值非常高,这说明不同语言之间没有太大的差别。Multi-lingual BERT只看意思,不同语言对它没有太大的差别。
那这里还会有一个疑问,你说BERT可以把不同语言中含义相同的符号放在一起,使它们的向量接近。但是,当训练多语言的BERT时,如果给它英语,它可以用英语填空,如果给它中文,它可以用中文填空,它不会混在一起。
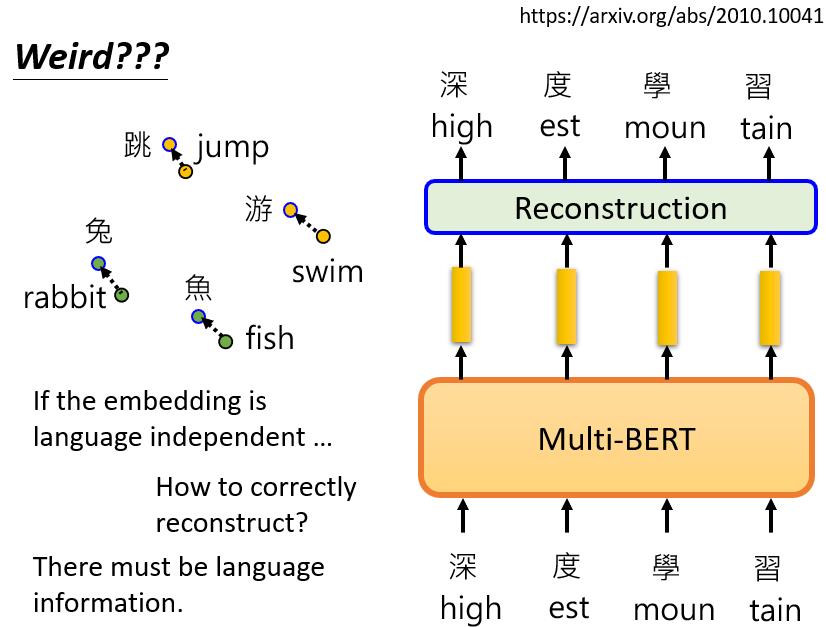
那么,如果不同语言之间没有区别,怎么可能只用英语标记来填英语句子呢?为什么它不会用中文符号填空呢?这说明它知道语言的信息也是不同的,那些不同语言的符号毕竟还是不同的,它并没有完全抹去语言信息。
后来我们发现,语言信息并没有隐藏得很深。一个学生发现,我们把所有英语单词的embedding,放到多语言的BERT中,取embedding的平均值,我们对中文单词也做同样的事情。在这里,我们给Multi-lingual BERT一个英语句子,并得到它的embedding。我们在embedding中加上这个蓝色的向量,这就是英语和汉语之间的差距。
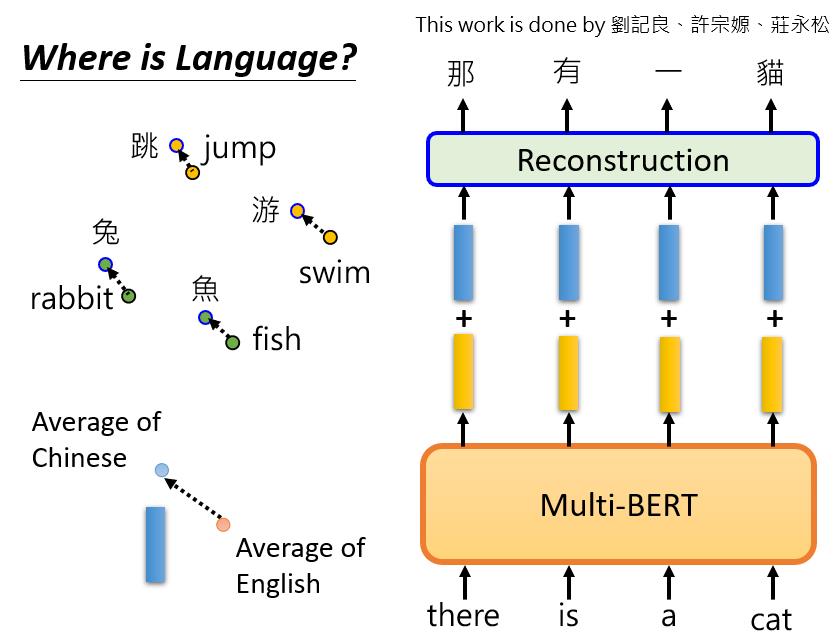
这些向量,从Multi-lingual BERT的角度来看,变成了汉语。有了这个神奇的东西,你可以做一个奇妙的无监督翻译。例如,你给BERT看这个中文句子:“能帮助我的小女孩在小镇的另一边,没人能够帮助我”,现在我们把这个句子扔到Multi-lingual BERT中。
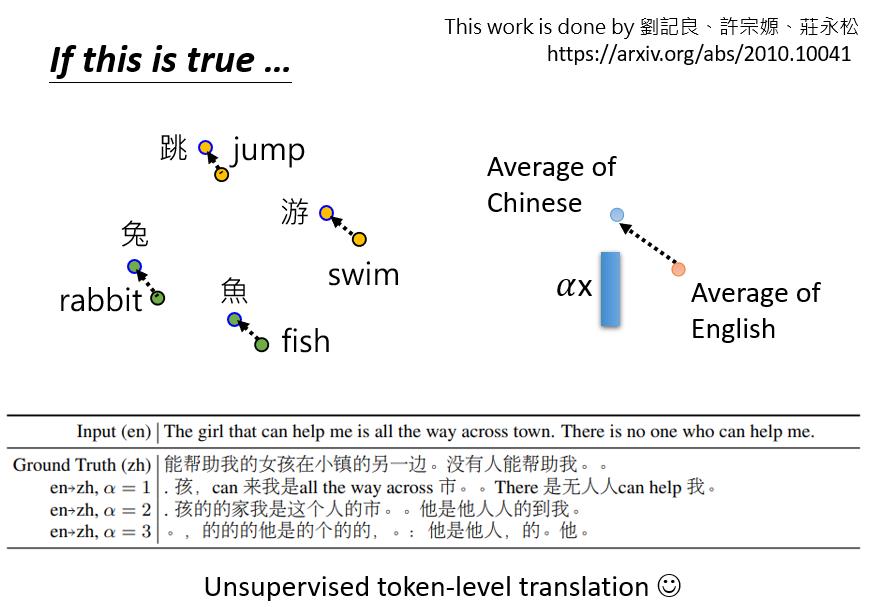
然后我们取出Multi-lingual BERT中的一个层,它不需要是最后一层,可以是任何一层。我们拿出某一层,给它一个embedding,加上这个蓝色的向量。对它来说,这个句子马上就从中文变成了英文。所以它在某种程度上可以做无监督的标记级翻译,尽管它并不完美,神奇的是,Multi-lingual的BERT仍然保留了语义信息。
以上是关于学习笔记李宏毅2021春机器学习课程第7.2节:自监督学习的主要内容,如果未能解决你的问题,请参考以下文章